September 2025
Intermediate to advanced
136 pages
3h 14m
Portuguese (Portugal, Brazil)
Este trabalho foi traduzido com recurso a IA. Agradecemos o teu feedback e comentários: translation-feedback@oreilly.com
Até agora, você aprendeu a configurar o Coalesce e explorou os principais componentes e conceitos da plataforma, como projetos, espaços de trabalho, tipos de nós, locais e mapeamentos de armazenamento e arquitetura com reconhecimento de coluna. Neste capítulo, você colocará esse conhecimento em prática e aprenderá a criar pipelines de dados no Coalesce.
Você aprenderá a adicionar fontes de dados, criar nós e escrever SQL para transformar dados diretamente em qualquer nó. Você também dominará funcionalidades como criação de junções, edição em massa de colunas e criação de filtros. Além disso, você descobrirá como o Coalesce Marketplace aprimora seu pipeline com extensões poderosas.
Vamos começar!
No Capítulo 1, você teve uma breve introdução à interface de compilação, que é onde você passará o seu tempo neste capítulo. A interface de compilação é onde você desenvolverá seus produtos de dados e criará gráficos e pipelines de nós. Você pode acessá-la iniciando qualquer espaço de trabalho na página de projetos, conforme mostrado na Figura 3-1.
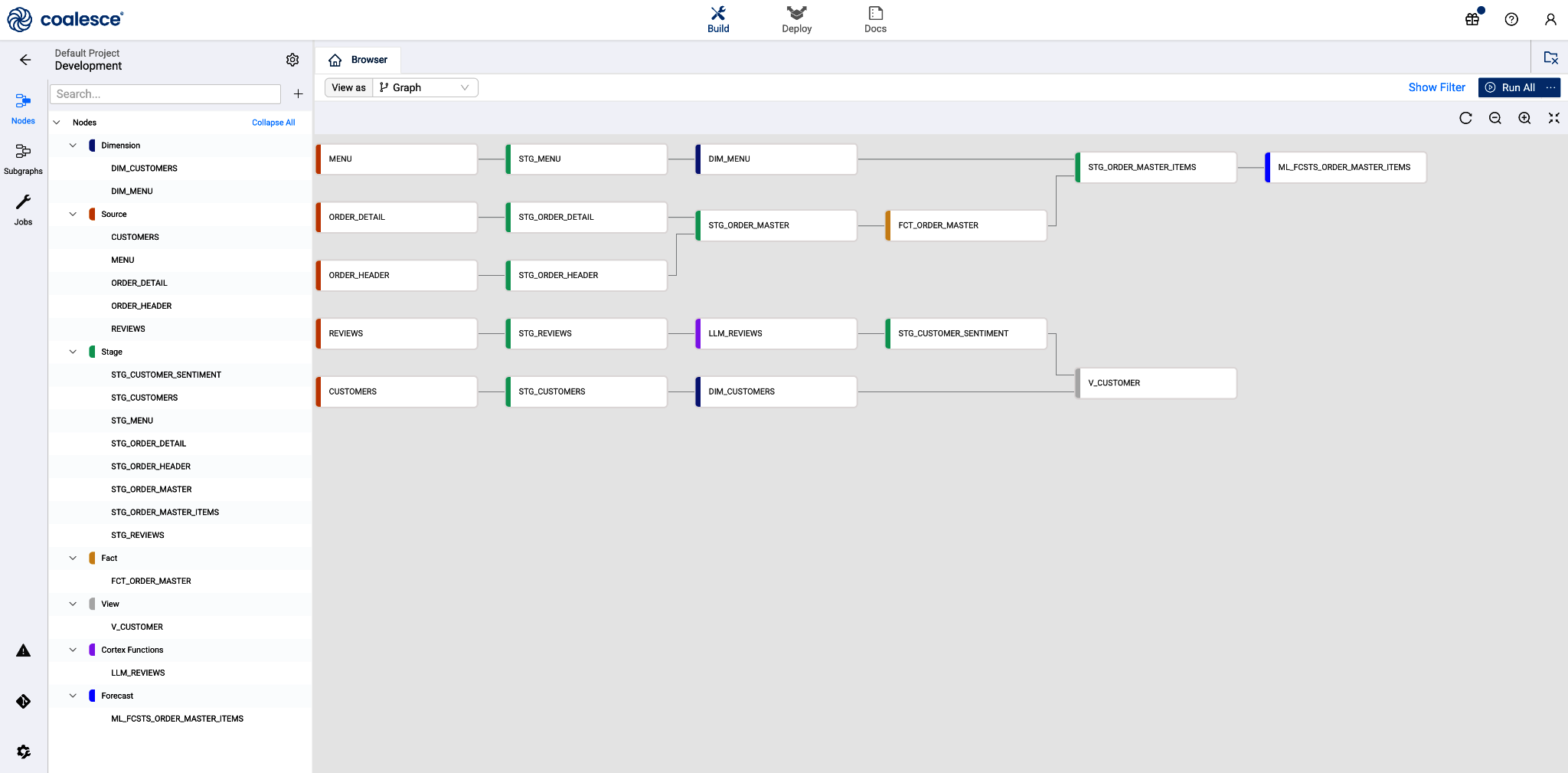
A interface de compilação contém todos ...
Read now
Unlock full access






