September 2025
Intermediate to advanced
136 pages
3h 14m
Portuguese (Portugal, Brazil)
Este trabalho foi traduzido com recurso a IA. Agradecemos o teu feedback e comentários: translation-feedback@oreilly.com
No capítulo anterior, você usou o Coalesce para criar transformações e pipelines de dados. Mas gerenciar os pipelines existentes é tão importante quanto criar novos. Este capítulo aborda ambos: como criar qualquer produto de dados no Coalesce e como gerenciar pipelines de qualquer tamanho de forma eficaz.
Você aprenderá a inspecionar objetos para entender seu conteúdo e onde eles foram criados. Você também usará a linhagem em nível de coluna para realizar análises de impacto e aproveitará o Scanner de Problemas para identificar e resolver problemas com eficiência. Este capítulo também explora os principais recursos de gerenciamento, incluindo controle de versão, macros e parâmetros, testes, subgráficos, trabalhos e ambientes.
Primeiro, você navegará pelos nós do pipeline para estabelecer uma base sólida para gerenciar os fluxos de trabalho de dados.
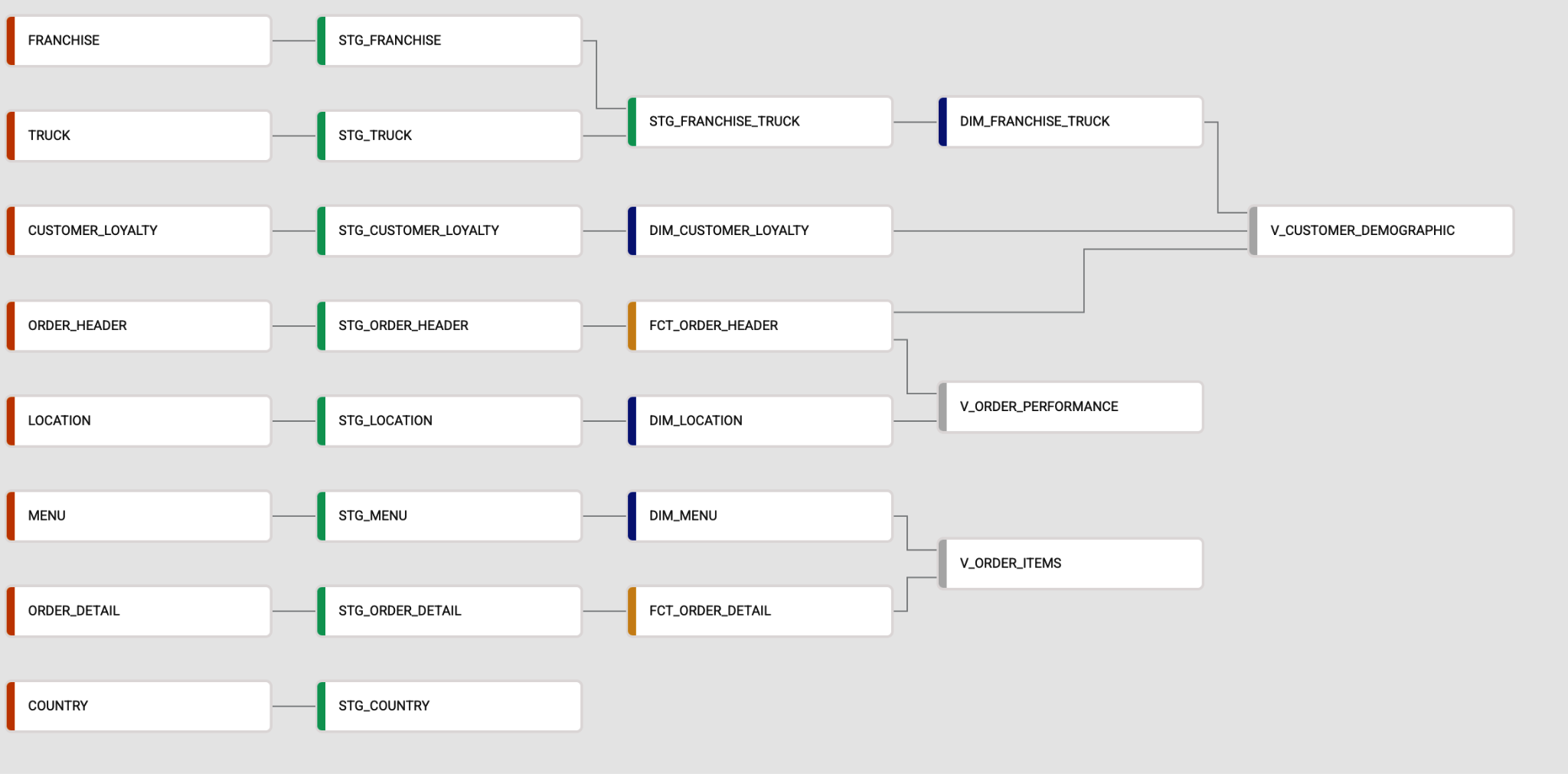
À medida que você constrói nós no Coalesce, obter o contexto completo sobre eles costuma ser essencial para as decisões de desenvolvimento. Felizmente, o Coalesce torna esse processo simples. Por padrão, ele exibe o desenvolvimento do pipeline como um gráfico, conforme mostrado na Figura 4-1.
Read now
Unlock full access






