November 2025
Intermediate to advanced
1062 pages
34h 20m
English
In Chapter 13, we discussed multiple ways to optimize and tune PyTorch-based training and inference workloads. We touched on the PyTorch compiler and how it automates kernel fusion and other kernel-level techniques to improve performance with very little changes to your code.
In this chapter, we dive deeper into the dynamic PyTorch compilation stack, including components like TorchDynamo, Ahead-of-Time Autograd (AOT Autograd), and PrimTorch Intermediate Representation (IR) (aka Prims or Prims IR)—as well as compiler backends like TorchInductor, Accelerated Linear Algebra (XLA), and OpenAI’s Triton ecosystem. The PyTorch compiler stack is shown in Figure 14-1.
We also cover tools for debugging the compilation pipeline as well as libraries for scaling PyTorch across multi-GPU and multinode clusters. We will then explore how torch.compile works under the hood and how to handle dynamic shapes and variable sequence lengths efficiently.
We will also examine the PyTorch compiler’s integration with the OpenAI Triton ecosystem. Our goal is to accelerate and scale our PyTorch models and applications without sacrificing the flexible, eager-execution development experience of PyTorch.
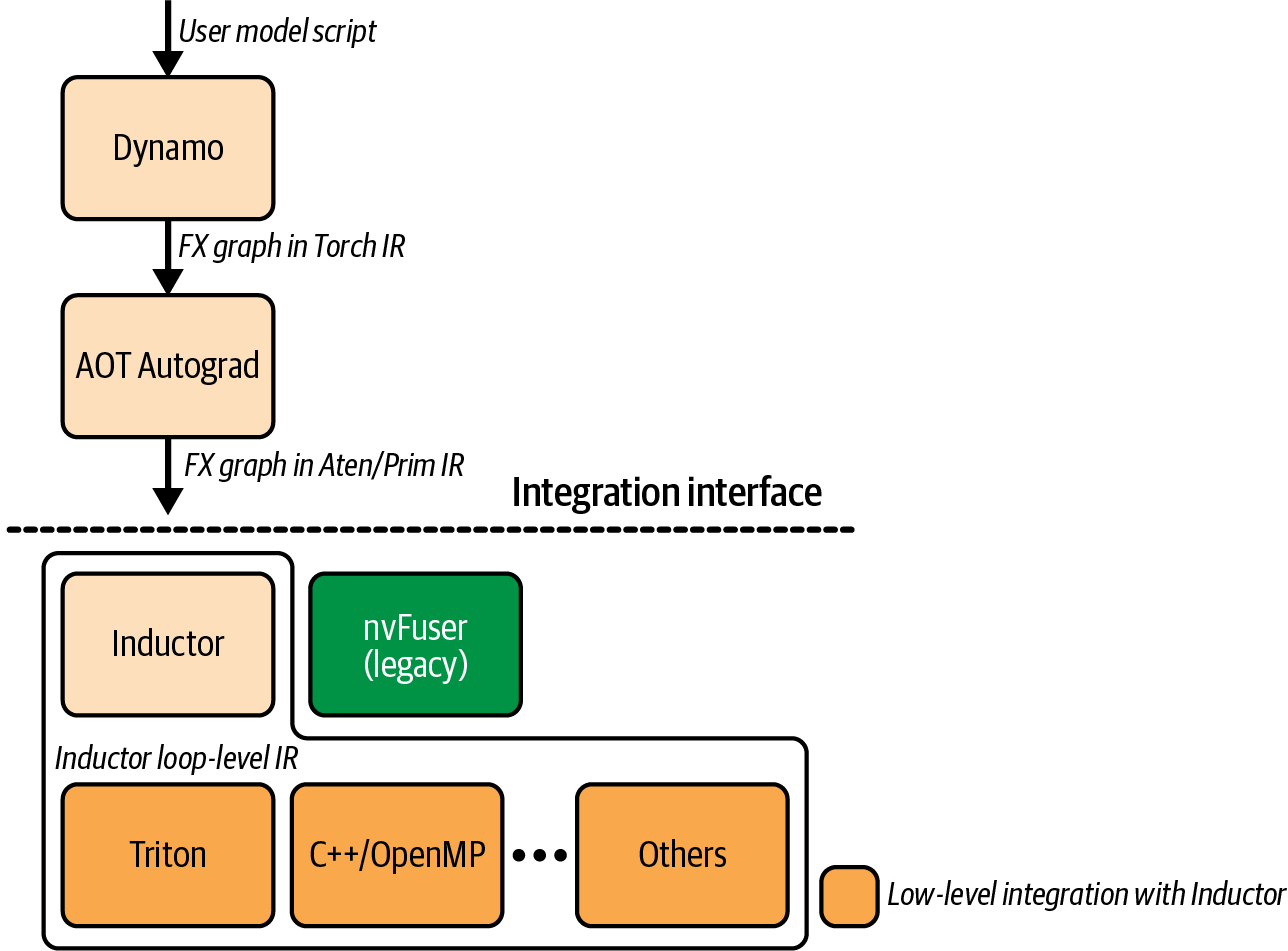
As described in Chapter 13, PyTorch’s torch.compile will compile your ...
Read now
Unlock full access






