Chapter 13. Performance Optimization
THE PERFORMANCE OPTIMIZATION PATTERNS IMPROVE THROUGHPUT AS WELL AS APPLY SOME USER-centered techniques to ease the pain of waiting for the server. Browser-Side Cache talks about implementing a custom cache within the application and explains why it’s sometimes more suitable than the standard web browser cache. Predictive Fetch extends the cache concept by proposing that likely actions be anticipated, so that required data is already sitting in the browser by the time it’s required. Another very different way to achieve zero network delay is to simply take a stab at the required value, the idea behind Guesstimate.
Multi-Stage Download proposes parallel or scheduled downloads so as to reduce bottlenecks and grab the most critical details as early as possible.
Fat Client is one of several possible Ajax architectural styles that helps optimize performance by pushing as much logic as possible—and potentially storage—over to the browser side.
Browser-Side Cache
⊙ Auto-Update, Memoise, Memoize, Sync, Synchronise, Sychronize, Real-Time
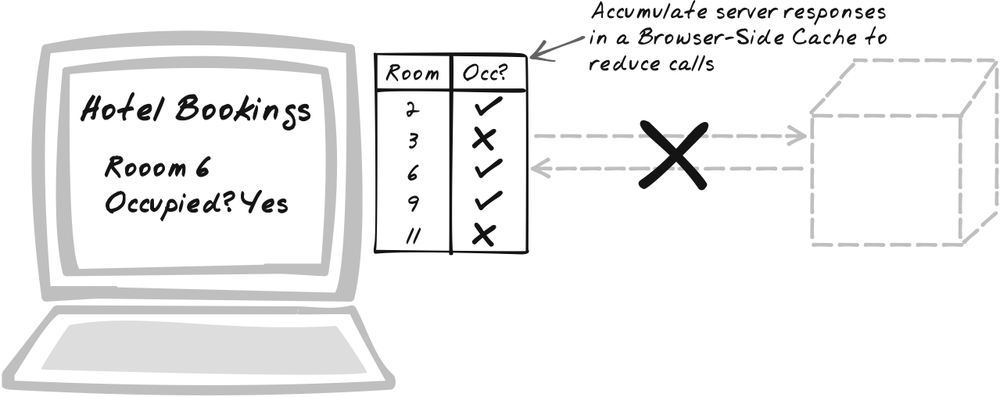
Developer Story
Devi’s produced a physics simulation and, though it’s functional, she’s disappointed that it keeps pausing to request calculations from the server. To speed it up, she sets up a cache that will retain the calculations locally.
Problem
How can you make the system respond quickly to user activity?
Forces
The application should respond to user actions quickly—ideally, instantaneously.
Many user actions require a response from the server.
Responses from the server can be noticeably latent due to data transfer and server processing overheads.
Solution
Retain server results in a Browser-Side Cache. The cache is a JavaScript map-style object that holds query-result pairs; the queries are cache keys and the server results are server results. So whenever the browser needs to query the server, first check the cache. If the query is held as a key in the cache, the corresponding value is used as the result, and there’s no need to access the server. Caching like this is performed in many systems, but there are some interesting Ajax-specific issues, such as the relationship with the browser’s built-in cache and the asynchronous nature of calls.
XMLHttpRequest Call (Chapter 6) explains that call results can already be cached by the browser, so you might wonder why this pattern exists. After all, the browser not only handles caching for you, but can cache huge quantities of data using the filesystem, and, unlike a Browser-Side Cache, this data will usually live beyond the current session. The reason you’d use a Browser-Side Cache is to exert more control over caching. You get to choose how much data is cached and how long it lasts, whereas those things are set by the user in a web browser cache. Moreover, you bypass the notorious portability issues associated with cache control, choosing exactly what will be and what will not be cached. Another advantage of a Browser-Side Cache over the web browser’s cache is that you can save JavaScript objects you’ve built up, thus saving the effort of reconstructing them later on (a process known as “memoisation”).
What exactly is the format of the key and value? In the simplest case, the query would just be the URL, and the result would be the response body. However, that’s not so useful because if you make calls correctly, as discussed in XMLHttpRequest Call (Chapter 6) and RESTful Service (Chapter 9), the browser will handle caching on your behalf, and as it’s backed by the filesystem, it can cache much greater quantities of data. However, more useful are caches that hold high-level semantic content—typically the results of processing server responses.
A cache data structure requires some way to access the key-value pairs “randomly”—that is, directly, without having to traverse the entire data structure until the desired key-value pair is found. In JavaScript, a cache can be created using an associative array (in JavaScript, this is the same as an object). So an empty array is created at startup and gradually accumulates server results. Of course, an Ajax App lives indefinitely, so the array could continue growing if not controlled. There are a few ways to handle this, as discussed later in "Decisions.”
It’s common in many systems to treat the cache as a Proxy, as shown in Figure 13-2 (see Gamma et al.’s [1995] Proxy pattern). That is, clients retrieve results from an object called something like “ResultFetcher,” which encapsulates anything to do with fetching of results. From their perspective, the ResultFetcher just provides results. It doesn’t matter to the client whether all results are directly pulled from the server or whether some of them are cached inside ResultFetcher.
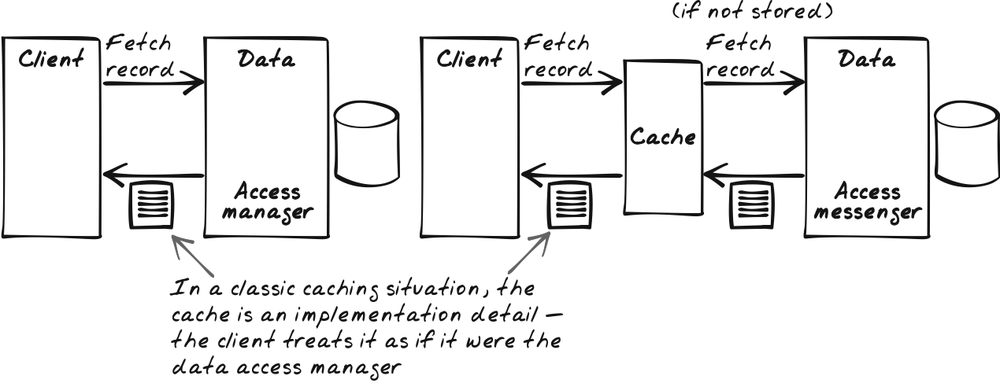
Here’s where the asynchronous nature of XMLHttpRequest adds a slight complication.
Under normal circumstances, a caching ResultFetcher always returns
the desired value synchronously, whether the result was in the cache
or not. But with Ajax, it can only do this if the result was indeed
found in the cache. Otherwise, the server response will come back
some time later, after the fetching function has already returned.
To deal with this, you might consider having the requester pass a
callback function to the fetching procedure. So the fetching
procedure never returns anything directly, but instead ensures the
callback function is eventually called with the desired value. If it
knows the value immediately, the callback function will be called
straightaway, and if not, it will be called later on. In other
words, the ResultFetcher has roughly the same interface and external
behavior as XMLHttpRequest (or a
suitable wrapper).
Decisions
What will be stored as keys? For values?
The solution mentioned a couple of possibilities for keys and values. In the first instance, they might simply be URLs and response bodies. Using the entire URL and response body does come at a cost, however. Both contain a lot of useless information, which limits how many items can be stored in the cache. An alternative is to use semantically related values. For example, the key might be customer names, and the values might be customer objects. Semantic values also lets you incorporate other data, such as results from calculations.
How will cache size be kept under control?
You typically keep the cache size under control by deciding on its capacity and on some way to remove elements when that size has been reached. Each new element usually results in an older element being discarded. For efficiency, you might discard a large batch at once, and then let the cache gradually build up again.
Two common algorithms are (http://en.wikipedia.org/wiki/Cache_algorithms):
- Least Recently Used (LRU)
The discarded item is the one with the longest time since it was last retrieved.
- Least Frequently Used (LFU)
The discarded item is the one that has been retrieved the least.
Both algorithms are feasible in JavaScript, provided you use the right data structure. "Code Example: Cached Sum Demo,” later, illustrates LRU.
How will you protect against stale data?
Regarding stale data, the first question to ask is, “How recent does the data have to be?” If it’s real-time stats being used by a nurse to monitor a patient’s health, it probably needs to be pretty recent. So much so, that a cache might even be out of the question. If it’s a student perusing a 50-year old article on ancient Athenian literature, a 12-hour cache will do fine.
There are several ways to enforce this decision:
Attach a timestamp to each item that goes into the cache. Whenever you retrieve an item, inspect the timestamp to determine if the result is recent enough.
As a variant on the above, schedule a periodic loop to actively delete stale items.
Implement a browser-server protocol that allows the browser to determine if items are stale. So the browser might keep a timestamp for each item, and the server exposes a service to accept a timestamp. The server only needs to send the whole response if the value has changed since that time. An alternative to timestamps would be a hash function—a function that the browser runs against the cached value that can then be compared by the server against the item’s most recent hash value, to see if a change has occurred.
Implement a service on the server that announces changes that have occurred. Use Periodic Refresh (Chapter 10) to actively listen for such changes and to delete from the cache any items that have changed.
Real-World Examples
This section contains a XMLHttpRequest Call library with caching support. "Real-World Examples" in Predictive Fetch includes several other systems with Browser-Side Caches.
libXmlRequest library
Stephen W. Cote’s libXmlRequest (http://www.whitefrost.com/servlet/connector?file=reference/2003/06/17/libXmlRequest.html)
was one of the earlier wrappers of the XMLHttpRequest object. A typical
asynchronous request looks like this:
getXml(path, callbackFunction, 1, requestId);
To make the request cached, simply add an extra argument at the end:
getXml(path, callbackFunction, 1, requestId, 1);
The approach shows how cache functionality can be made orthogonal to core application functionality.
Code Example: Cached Sum Demo
The Basic Sum Demo (http://ajaxify.com/run/sum/) has to resort to the server each time the cache is reached. This refactoring adds caching functionality to reduce server calls and is implemented in three stages.
Including the query in the response
The asynchronous nature of XMLHttpRequest Call separates the initial query from the response, so it’s not always clear when a request comes in what the corresponding request was. One way to achieve this is to include the original query as part of the response. That’s the first refactoring here. The refactoring is detailed in XML Message (Chapter 9), and the net effect is a response like the one that is shown next (http://ajaxify.com/run/sum/xml/sumXML.php?figure1=4&figure2=8&figure3=).
<sum>
<inputs>
<figure id="1">4</figure>
<figure id="2">8</figure>
<figure id="3"></figure>
</inputs>
<outputs>12</outputs>
</sum>Previously, the response was just 12. The resulting value is extracted
from the XML in a slightly different way, but the inputs are not
used until the next iteration.
An infinite cache
The next refactoring creates a very basic cache—one
that has no regard for the laws of physics—it just keeps growing
indefinitely. That’s a bad thing, but a useful stepping stone to
the final iteration. The cache holds the sum against a figuresString, simply a comma-separated
list of the three figures.
First, the cache is created by a global variable and
initialized from the onload
method:
var sumByFigures;
...
function restartCache(html) {
sumByFigures = new Array( );
...
}Each time a sum is submitted, figuresString is calculated to form a
key for the cache. The cache is then interrogated to see if it
already contains that sum. If not, an asynchronous call is set up.
Either way, the ultimate consequence is that repaintSum( ) will eventually be called with the new sum. If the
result is already cached, it will be called straightaway. If not,
it will be called after the server has returned.
function submitSum( ) {
...
var figuresString =
figures.figure1 + "," + figures.figure2 + "," + figures.figure3;
var cachedSum = sumByFigures[figuresString];
if (cachedSum) {
repaintSum(cachedSum);
} else {
repaintSum("---");
ajaxCaller.get("sumXML.php", figures, onSumResponse, true, null);
}
}onSumResponse not only
calls repaintSum( ) with the
value in the response, but also pushes the result onto the
cache:
function onSumResponse(xml, headers, callingContext) {
var sum = xml.getElementsByTagName("output")[0].firstChild.nodeValue;
repaintSum(sum);
var figures = xml.getElementsByTagName("figure");
var figuresString = figures[0].firstChild.nodeValue + ","
+ figures[1].firstChild.nodeValue + ","
+ figures[2].firstChild.nodeValue;
sumByFigures[figuresString] = sum;
}Finally, repaintSum is
the function that detects a change—either way—and simply morphs
the display:
function repaintSum(html) {
self.$("sum").innerHTML = html;
}A finite cache
The final cache (http://www.ajaxify.com/run/sum/xml/cached/expiry/) enhances the previous version by introducing a least-recently used disposal algorithm. Each time a new item is added to the cache, the least recently used item is discarded from the cache. It would be inefficient to trawl through the entire cache each time that happens, comparing usage times. So, in addition to the associative array, a parallel data structure is composed. It’s a queue, where each new item is pushed to the tail of the queue and gradually approaches the head as further items are pushed on. When the queue is full and an item is pushed on to the tail, each item moves down one, and the head item “falls off” the queue, so it is deleted from both the queue and the associative array. Whenever an item is retrieved, it’s sent back to the tail of the queue. That’s what ensures the least recently used item is always at the head.
The queue itself is a class with the following functions:
enqueue( ), dequeue( ), and sendToTail(
). It works by tracking the head, the tail, and the
size, and by keeping the items in a doubly linked list. For
example, enqueue( ) is defined
like this:
Queue.prototype.enqueue = function(obj) {
newEntry = {
value: obj,
next: this.tail
}
if (this.tail) {
this.tail.prev = newEntry;
} else { // Empty queue
this.head = newEntry;
}
this.tail = newEntry;
this.size++;
}Back to the sum application, which now declares a queue as well as the associative array:
var figuresQueue, sumByFigures;
Each time a new element arrives from the server, it’s sent
to encache( ). encache will lop the least recently used
item off both data structures if the queue is full. Then it will
add the new item to both.
function encache(figuresString, sum) {
// Add to both cache and queue.
// Before adding to queue, take out queue head and
// also remove it from the cache.
if (figuresQueue.size == cacheSize) {
removedFigures = figuresQueue.dequeue(figuresString);
delete figuresString[removedFigures];
}
figuresQueue.enqueue(figuresString);
sumByFigures[figuresString] = sum;
$("queueSummary").innerHTML = figuresQueue.describe( );
}Whenever the cache is queried, the queried value is not only returned, but is also sent back to the tail of the queue to mark it as having been recently used:
function queryCache(figuresString) {
// Recently used, so move corresponding entry back to tail of queue
// if it exists.
figuresQueue.sendToTail(figuresString);
$("queueSummary").innerHTML = figuresQueue.describe( );
return sumByFigures[figuresString];
}With these abstractions in place, there is not much change
to the core part of the sum script. submitSum( ) queries the cache and calls
the server if the result is not found. And the server response
handler ensures new results are added to the cache:
function submitSum( ) {
...
var cachedSum = queryCache(figuresString);
if (cachedSum) {
repaintSum(cachedSum);
} else {
repaintSum("---");
ajaxCaller.get("sumXML.php", figures, onSumResponse, true, null);
}
}
...
function onSumResponse(xml, headers, callingContext) {
...
encache(figuresString, sum);
}Alternatives
Built-in browser cache
As explained in the solution, the built-in browser cache is an alternative form of cache. It’s better suited for larger data HTML, but is more difficult to control than a Browser-Side Cache.
Server-side cache
Caching data on the server cuts down on processing, especially when the data is shared by multiple users. However, that’s mainly a benefit if the server processing is the bottleneck. Bandwidth is more often the chief constraint, and the server-side cache won’t reduce browser-server traffic. The best option is often a combination of browser-side and server-side caching.
Related Patterns
Submission Throttling
Browser-Side Cache focuses on “read caching,” in which responses from the server are held in the cache. Another flavor of caching is “write caching,” where output is held in a buffer to defer outputting to its true destination. Submission Throttling (Chapter 10) is a form of write-caching.
Predictive Fetch
⊙ Anticipate, Fetch, Guess, Prefetch, Preload, Prepare, Ready
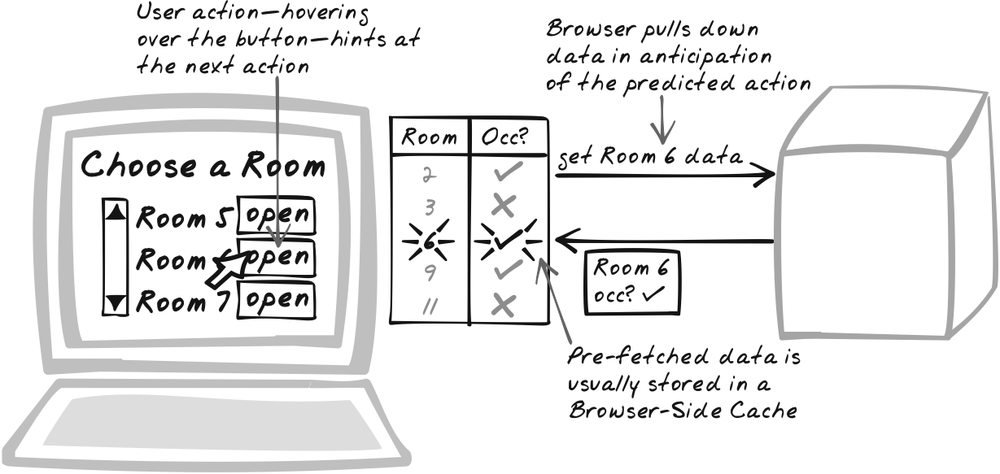
Developer Story
Dave’s tuning a music web site and the logs tell him that users who listen to a song for more than a minute are quite likely to click the Purchase button. So he introduces a new timer—at the one-minute mark of each song, the browser will quietly download pricing data just in case the user wants to buy it later on.
Problem
How can you make the system respond quickly to user activity?
Forces
The application should respond to user actions quickly; ideally, it should feel instantaneous.
Many user actions require a response from the server.
Responses from the server can be noticeably latent due to data transfer and server processing overheads.
Solution
Pre-fetch content in anticipation of likely user actions. Pre-fetching attempts to remove the delay altogether for certain user actions.
The obvious motivation for instantaneous feedback is efficiency: the things can happen faster because the user’s not sitting around waiting for results. In reality, though, the proportion of overall time waiting might actually be quite small. The more severe problem is distraction, because delays will break the user’s concentration, along with the sense of frustration at not being in control. The other problem is that for real-time applications, the user is slower to respond to state conveyed by the server. A chat session will be more strained, and a remote device under browser control will be more erratic.
Here are some occasions when Predictive Fetch might be used:
The user’s navigating a Virtual Workspace (Chapter 15) such as a large table. Pre-fetch the results of moving in each direction.
The user’s converting between two currencies. Pre-fetch the major currency rates.
The user’s reading some articles. Pre-fetch all stories in her favorite category.
Predictive Fetch usually requires a Browser-Side
Cache (earlier in this chapter) in order to accumulate the
pre-fetched content. In addition, you can exploit the web browser’s
built-in cache in a couple of ways—see Browser-Side
Cache , earlier, for a comparison of these
techniques. To get something in the web browser’s built-in cache,
one technique is to issue XMLHttpRequest Calls
for content you’ll need later on, using the techniques mentioned in
that pattern to encourage the content to be cached. The response
handler does nothing here—the point is simply to bring the content
into the browser, where it will be cached for later on. The other
technique is for images: create a dummy image (document.createElement("img")) object and
set its src property to whatever
image URL you want to preload. Again, we’re only doing this to
ensure the image goes in the cache, so the image isn’t actually
attached to the page.
It’s rarely possible to pre-fetch for all actions, so the designer has to be smart about anticipating which actions are most likely. Higher priority will be given to content that is more important or more likely to be used.
One problem with pre-fetching is the application will be a bit erratic. The user might be surprised that some commands respond instantaneously, while similar commands take a long time. While some variation is always expected on the Web, the main problem comes when the data arrives immediately. The user will reasonably question whether the app was really taking their action into account (http://www.baekdal.com/articles/Usability/usable-XMLHttpRequest/). For that reason, a useful but counter-intuitive trick is to actually fake a small delay and use a visual effect like One-Second Spotlight (Chapter 16) to hint that the server really was involved.
Decisions
How much information will be pre-fetched?
Pre-fetching comes at a cost. Anticipating the user’s actions is a guessing game, and for each guess that goes wrong, some resources have been wasted. Designers must make a trade-off involving the likelihood that pre-fetched data will be used, the user benefit if it is used, and the overhead if it’s not used. This could involve some fairly heavy user analysis combined with statistical methods.
In practice, it’s feasible to use some initial rules of thumb and proceed on a more empirical basis. With the right design, it should be easy enough to discriminately turn pre-fetching on and off. Thus, by studying logs and comparing the effects of pre-fetching different aspects, it’s possible to evolve the algorithms being used.
Will it be the server or the browser that anticipates user actions?
The request for information will always come from the browser, but it’s feasible for either the server or the browser to anticipate what the user will need next. If the browser is to decide, it can simply issue a request for that information. If the server is to decide, the browser can, for example, issue a periodic request for general information—perhaps with some indication of current state—and the server can then push down whatever information it decides might come in handy for the browser.
What information can be used to anticipate user actions?
It’s likely you’ll use some information about the present and the past to help predict the future. There’s a lot of data you could potentially use to help decide what the user will do next:
- User’s profile
The user’s profile and history should provide strong cues. If the user always visits the Books area as soon as they log on, then the homepage should pull down Books content.
- User’s current activity
It’s often possible to predict what the user will do next from their current activity. If a user has just added an item to his shopping cart, he will likely be conducting a purchase in the not-too-distant future; consider downloading his most recent delivery address.
- Activity of other users
Sometimes, a rush of users will do the same thing at once. If the user has just logged into a news portal while a major news event is in progress, system-wide statistics will inform the server that this user is probably about to click on a particular article.
- Collaborative filtering
As an extension of the previous point, a more sophisticated technique is to correlate users based on information such as their profile and history. People are likely to behave similarly to those whose details are highly correlated. So if a user tends to look at “Sport” followed by “Weather,” then the system should start pre-fetching “Weather” while the user’s looking at “Sport.”
Real-World Examples
Google Maps
Some experimentation with Google Maps (http://maps.google.com) suggests Predictive Fetch is used while navigating the map (Figure 13-4). The evidence is that you can slowly move along the map in any direction, and you won’t see any part of the page going blank and refreshing itself. If you move quickly, you’ll see the refresh behavior. Based on that observation, the map is apparently fetching content beyond the viewable area, in anticipation of further navigation.

map.search.ch
map.search.ch (http://map.search.ch) includes familiar buttons for zooming and panning. The difference is that at as soon as a mouse pointer hovers over a button, a call is made to anticipate the user clicking on it. This is a good compromise between downloading in every possible direction and zoom level or doing nothing at all.
Firefox “Prefetch”
This is not entirely an Ajax example, but it’s worthwhile noting a particular Firefox (and Mozilla) feature called “prefetching.” The HTTP protocol allows for new link types to be defined, and Firefox happens to define a “Prefetch” link type (http://www.mozilla.org/projects/netlib/Link_Prefetching_FAQ.html#What_is_link_prefetching). A “prefetch” link looks like this:
<link rel="prefetch" href="/images/big.jpeg">
When Firefox sees such a link appear, it will generally fetch the associated content, which is ready to be shown immediately. An application can exploit that feature by including links to content that is likely soon to be requested.
Google Search, for example, slaps a prefetch directive around the first
search result, but states that this occurs for “some searches”
only. I am guessing, based on some experimentation, that this
means searches where Google is highly confident the top search
will be chosen. So a search for the highly ambiguous term
“anything,” results in no prefetch directive. Meanwhile, a search
for IBM, where it’s obvious what most users seek, will direct
Firefox to prefetch the first
result:
<link rel="prefetch" href="http://www.ibm.com/">
International Herald Tribune
Another example is The International Herald Tribune (http://www.iht.com/), which caches entire articles to provide instant gratification when you click on Next Page.[*]
Code Refactoring: AjaxPatterns Predictive Fetch Sum
The Basic Sum Demo (http://ajaxify.com/run/sum/) allows the user to enter a set of figures, but he must wait for the server in order to see the sum. The Cached Sum Demo (http://ajaxify.com/run/sum/xml/cached/) improves on the situation a bit, by ensuring recent sums do not need to be re-fetched. However, there is still no anticipation of user behavior. In this refactoring (http://ajaxify.com/run/sum/predictive/), a new sum is fetched each time the user types something. By the time he has pressed the Add button, the browser should hopefully have the result waiting in the cache, ready to be displayed immediately. Each time a new sum is anticipated, the browser fetches the result, and a callback pushes it into the cache.
The code change is actually fairly straightforward. As before,
clicking on the Add button causes a server sum request. This time,
though, a flag is set to indicate its a real user submission as
opposed to a pre-fetch. The call will “remember” the flag; i.e.,
using ajaxCaller’s callingContext, the flag will be passed to
the callback function when the response is issued:
$("addButton").onclick = function( ) {
submitSum(true);
}For Predictive Fetch, each release of a key triggers a sum
submission, with the callback false to indicate this was
not a user submission.
$("figure1").onkeyup = function( ) { submitSum(false); }
$("figure2").onkeyup = function( ) { submitSum(false); }
$("figure3").onkeyup = function( ) { submitSum(false); }submitSum( ) will perform
the same request as before, but this time passes in the flag as a
calling context:
ajaxCaller.get("sumXML.php", figures, onSumResponse, true, isUserSubmitted);The isUserSubmitted flag is
then retrieved by the callback function, which will only change the
display if the corresponding query was user-submitted. Either way,
the result is then pushed into the cache for later retrieval:
function onSumResponse(xml, headers, callingContext) {
var isUserSubmitted = callingContext;
...
if (isUserSubmitted) {
repaintSum(sum);
}
...
}Alternatives
Fat Client
Sometimes, the server is invoked to perform some logical processing, rather than to access server-side data. If that’s the case, it may be possible to process in JavaScript instead, as suggested by Fat Client (see later).
Server priming
In some cases, the reverse may be more appropriate: it might make sense for the browser to hint to the server what the user is working on, without the server actually responding. How is this useful? It allows the server to get started on processing, so that the required information can be cached server side but not actually pushed into the browser’s own cache.
Guesstimate
⊙ Approximate, Estimate, Extrapolate, Fuzzy, Guess, Guesstimate, Interpolate, Predict, Probabilistic, Sloppy, Trend
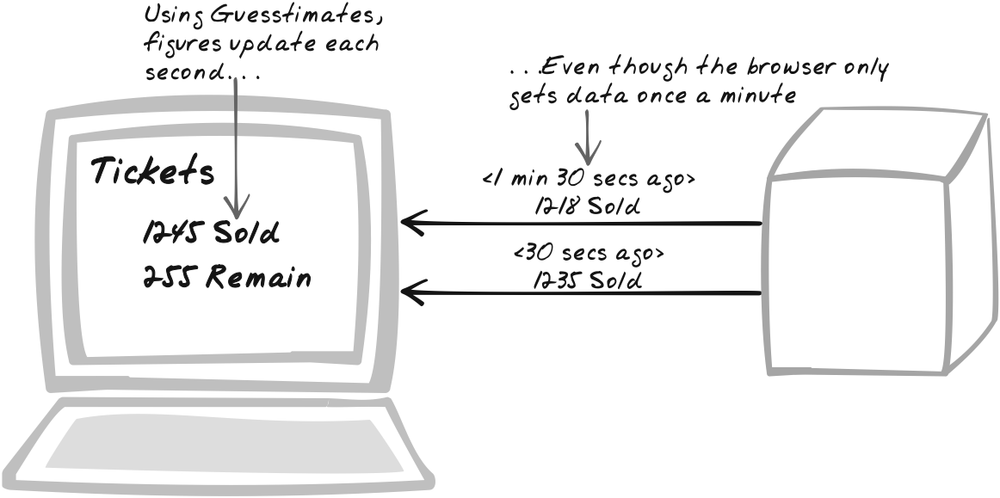
Developer Story
Devi’s producing a taxi tracker so the head office knows where its fleet is at any time. The taxis only transmit their location every 10 seconds, which would ordinarily lead to jerky movements on the map. However, Devi wants the motion to be smooth, so she uses interpolation to guess the taxi’s location between updates.
Problem
How can you cut down on calls to the server?
Forces
To comprehend system activity and predict what might happen next, it’s useful to have frequent updates from the server.
It’s expensive to keep updating from the server.
Solution
Instead of requesting information from the server, make a reasonable guess. There are times when it’s better to provide a good guess than nothing at all. Typically, this pattern relates to dynamic situations where the browser periodically grabs new information, using Periodic Refresh. The aim is help the user spot general trends, which are often more important than precise figures. It’s a performance optimization because it allows you to give almost the same benefit as if the data was really arriving instantaneously, but without the bandwidth overhead. For this reason, it makes more sense when using Periodic Refresh than HTTP Streaming, because the latter doesn’t incur as much overhead in sending frequent messages.
One type of Guesstimate is based on historical data. There are several ways the browser might have access to such data:
The browser application can capture recent data by accumulating any significant observations into variables that last as long as the Ajax App is open.
The browser application can capture long-term data in cookies, so it’s available in subsequent sessions.
The server can expose historical data for interrogation by the browser application.
Equipped with historical data, it’s possible to extrapolate future events, albeit imprecisely. Imagine a collaborative environment where multiple users can drag-and-drop objects in a common space, something like the Magnetic Poetry Ajax App (http://www.broken-notebook.com/magnetic/). Using a Periodic Refresh of one second, users might see an erratic drag motion, with the object appearing to leap across space, then stay still for a second, then leap again. A Guesstimate would exploit the fact that the motion of the next second is probably in the same direction and speed as that of the previous section. Thus, the application can, for that second, animate the object as if it were being dragged in the same direction the whole time. Then, when the real position becomes apparent a second later, the object need not leap to that position, but a new estimate can be taken as to where the object’s moving, and the object can instead move smoothly toward the predicted location. In other words, the object is always moving in the prediction of its current predicted location. Dragging motion is an example where users would likely favor a smooth flow at the expense of some accuracy, over an erratic display that is technically correct.
How about long-term historical data, stretching over weeks and months instead of seconds and minutes? Long-term data can also be used for a Guesstimate. Imagine showing weather on a world map. The technically correct approach would be not to show any weather initially, and then to gradually populate the map as weather data is received from the server. But the philosophy here would suggest relying on historical data for a first-cut map, at least for a few indicative icons. In the worst case, the Guesstimate could be based on the previous day’s results. Or it might be based on a more sophisticated statistical model involving several data points.
Historical data is not the only basis for a Guesstimate. It’s also conceivable the browser performs a crude emulation of business logic normally implemented server side. The server, for example, might take 10 seconds to perform a complex financial query. That’s a problem for interactivity, where the user might like to rapidly tweak parameters. What if the browser could perform a simple approximation, perhaps based on a few assumptions and rule-of-thumb reasoning? Doing so might give the user a feel for the nature of the data, with the long server trip required only for detailed information.
There are a few gotchas with Guesstimate. For example, the Guesstimate might end up being an impossible result, like “-5 minutes remaining” or “12.8 users online”! If there’s a risk that your algorithm will lead to such situations, you probably want to create a mapping back to reality; for instance, truncate or set limits. Another gotcha is an impossible change, such as the number of all-time web site visitors suddenly dropping. The iTunes example discussed later in this chapter provides one mitigation technique: always underestimate, which will ensure that the value goes up upon correction. With Guesstimate, you also have the risk that you won’t get figures back from the server, leading to even greater deviation from reality than expected. At some point, you’ll probably need to give up and be explicit about the problem.
Decisions
How often will real data be fetched? How often will Guesstimates be made?
Most Guesstimates are made between fetches of real data. The point of the Guesstimate is to reduce the frequency of real data, so you need to decide on a realistic frequency. If precision is valuable, real data will need to be accessed quite frequently. If server and bandwidth resources are restricted, there will be fewer accesses and a greater value placed on the Guesstimate algorithm.
Also, how often will a new Guesstimate be calculated? Guesstimates tend to be fairly mathematical in nature, and too many of them will impact on application performance. On the other hand, too few Guesstimates will defeat the purpose.
How will the Guesstimate be consolidated with real data?
Each time new data arrives, the Guesstimate somehow needs to be brought into line with the new data. In the simplest case, the Guesstimate is just discarded, and the fresh data is adopted until a new Guesstimate is required.
Sometimes, a more subtle transition is warranted. Imagine a Guesstimate that occurs once every second, with real data arriving on the minute. The 59-second estimate might be well off the estimate by 1 minute. If a smooth transition is important, and you want to avoid a sudden jump to the real value, then you can estimate the real value at two minutes, and spend the next minute making Guesstimates in that direction.
The iTunes demo in the "Real-World Examples" section, later in this chapter, includes another little trick. The algorithm concedes a jump will indeed occur, but the Guesstimate is deliberately underestimated. Thus, when the real value arrives, the jump is almost guaranteed to be upward as the user would expect. Here, there is a deliberate effort to make the Guesstimate less accurate than it could be, with the payoff being more realistic consolidation with real data.
Will users be aware a Guesstimate is taking place?
It’s conceivable that users will notice some strange things happening with a Guesstimate. Perhaps they know what the real value should be, but the server shows something completely different. Or perhaps they notice a sudden jump as the application switches from a Guesstimate to a fresh value from the server. These experiences can erode trust in the application, especially as users may be missing the point that the Guesstimate is for improved usability. Trust is critical for public web sites, where many alternatives are often present, and it would be especially unfortunate to lose trust due to a feature that’s primarily motivated by user experience concerns.
For entertainment-style demos, Guesstimates are unlikely to cause much problem. But what about using a Guesstimate to populate a financial chart over time? The more important the data being estimated, and the less accurate the estimate, the more users need to be aware of what the system is doing. At the very least, consider a basic message or legal notice to that effect.
What support will the server provide?
In some cases, the server exposes information that the browser can use to make a Guesstimate. For example, historical information will allow the browser to extrapolate to the present. You need to consider what calculations are realistic for the browser to perform and ensure it will have access to the appropriate data. A Web Service exposing generic history details is not the only possibility. In some cases, it might be preferable for the server to provide a service related to the algorithm itself. In the Apple iTunes example shown later in the "Real-World Examples" section, recent real-world values are provided by the server, and the browser must analyze them to determine the rate per second. However, an alternative design would be for the server to calculate the rate per second, reducing the work performed by each browser.
Real-World Examples
Apple iTunes counter
As its iTunes Music Store neared its 500 millionth song download, Apple decorated its homepage (http://apple.com) with a rapid counter that appeared to show the number of downloads in real-time (Figure 13-6). The display made for an impressive testimony to iTunes’ popularity and received plenty of attention. It only connected with the server once a minute, but courtesy of a Guesstimate algorithm described later in "Code Example: iTunes Counter,” the display smoothly updated every 100 milliseconds.

Gmail Storage Space
The Gmail homepage (http://gmail.com) (Figure 13-7) shows a message like this to unregistered users:
2446.034075 megabytes (and counting) of free storage so you’ll never need to delete another message.
But there’s a twist: the storage capacity figure increases each second. Having just typed a couple of sentences, it’s up to 2446.039313 megabytes. Gmail is providing a not-so-subtle message about its hosting credentials.
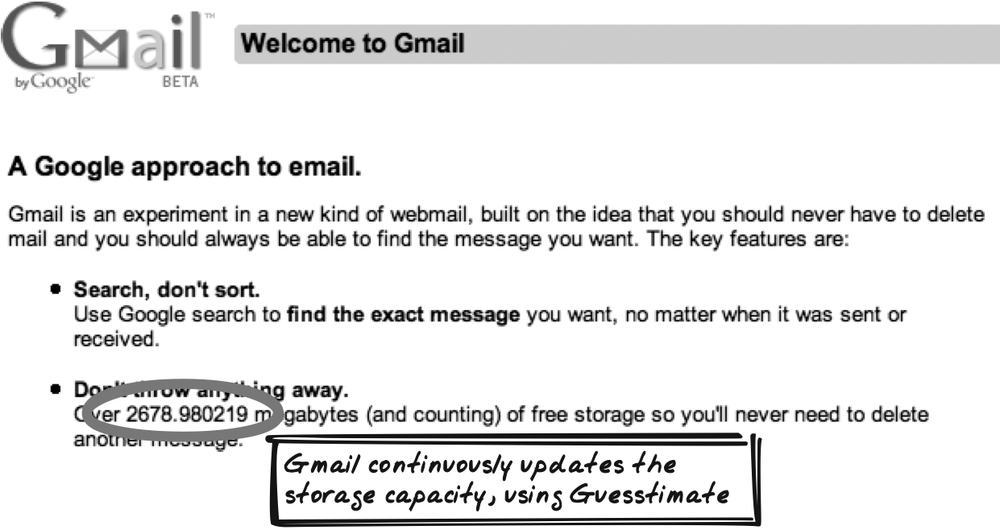
Andrew Parker has provided some analysis of the homepage (http://www.avparker.com/2005/07/10/itunes-gmail-dynamic-counters/). The page is initially loaded with the storage capacity for the first day of the previous month and the current month (also the next month, though that’s apparently not used). When the analysis occurred, 100 MB was added per month. Once you know that, you can calculate how many megabytes per second. So the algorithm determines how many seconds have passed since the current month began, and it can then infer how many megabytes have been added in that time. Add that to the amount at the start of the month, and you have the current storage capacity each second.
Code Example: iTunes Counter
The iTunes counter[*] relies on a server-based service that updates every five minutes. On each update, the service shows the current song tally and the tally five minutes prior. Knowing how many songs were sold in a five-minute period allows for a songs-per-second figure to be calculated. So the script knows the recent figure and, since it knows how many seconds have passed since then, it also has an estimate of how many songs were sold. The counter then shows the recent figure plus the estimate of songs sold since then.
There are two actions performed periodically:
The key global variables are rate and curCount:
rateis the number of songs purchased per millisecond, according to the stats in the XML that’s downloaded each minute.curCountis the counter value.
So each time the server response comes in, rate is updated to reflect the most recent
songs-per-millisecond figure. curCount is continuously incremented
according to that figure, with the output shown on the page.
The stats change on the server every five minutes, though
doCountdown( ) pulls down the
recent stats once a minute to catch any changes a bit sooner:
//get most recent values from xml and process
ajaxRequest('http://www.apple.com/itunes/external_counter.xml',
initializeProcessReqChange);
//on one minute loop
var refreshTimer = setTimeout(doCountdown,refresh);It fetches is the counter XML:
<root>
<count name="curCount" timestamp="Thu, 07 Jul 2005 14:16:00 GMT">
484406324
</count>
<count name="preCount" timestamp="Thu, 07 Jul 2005 14:11:00 GMT">
484402490
</count>
</root>setCounters( ) is the function that performs the
Guesstimate calculation based on this
information. It extracts the required parameters from XML into
ordinary variables—for example:
preCount = parseInt(req.responseXML.getElementsByTagName
('count')[1].childNodes[0].nodeValue);When a change is detected, it recalculates the current rate as
(number of new songs) / (time elapsed). Note
that no assumption is made about the five-minute duration; hence,
the time elapsed (dataDiff) is
always deduced from the XML.
//calculate difference in values countDiff = initCount-preCount; //calculate difference in time of values dateDiff = parseInt(initDate.valueOf()-preDate.valueOf( )); //calculate rate of increase // i.e. ((songs downloaded in previous time)/time)*incr rate = countDiff/dateDiff;
This is the most accurate rate estimate possible, but next, the script reduces it by 20 percent. Why would the developers want to deliberately underestimate the rate? Presumably because they have accepted that the rate will always be off, with each browser-server sync causing the counter to adjust itself in one direction or another, and they want to ensure that direction is always upwards. Making the estimate lower than expected just about guarantees the counter will increase—rather than decrease—on every synchronization point. True, there will still be a jump, and it will actually be bigger on average because of the adjustment, but it’s better than having the counter occasionally drop in value, which would break the illusion.
rate = rate*0.8;
As well as the once-a-minute server call, there’s the
once-every-100-milliseconds counter repaint. runCountdown( ) handles this. With the rate variable re-Guesstimated once a
minute, it’s easy enough to determine the counter value each second.
incr is the pause between
redisplays (in this case, 100 ms). So every 100 ms, it will simply
calculate the new Guesstimated song quantity by adding the expected
increment in that time. Note that the Gmail counter example just
discussed calculates the total figure each time, whereas the present
algorithm gradually increments it. The present algorithm is
therefore a little more efficient, although more vulnerable to
rounding errors.
//multiply rate by increment addCount = rate*incr; //add this number to counter curCount += addCount;
And finally, the counter display is morphed to show the new Guesstimate. The show was all over when the tally reached 500 million songs, so the counter will never show more than 500 million.
c.innerHTML = (curCount<500000000) ?
intComma(Math.floor(curCount)) : "500,000,000+";Related Patterns
Periodic Refresh
A Guesstimate can often be used to compensate for gaps between Periodic Refresh (Chapter 10).
Predictive Fetch
Predictive Fetch (see earlier) is another performance optimization based on probabilistic assumptions. Predictive Fetch guesses what the user will do next, whereas Guesstimate involves guessing the current server state. In general, Guesstimate decreases the number of server calls, whereas Predictive Fetch actually increases the number of calls.
Metaphor
If you know what time it was when you started reading this pattern, you can Guesstimate the current time by adding an estimate of your reading duration.
Multi-Stage Download
⊙ Download, Incremental, Multi-Stage, Parallel
Developer Story
Dave’s been informed an e-commerce homepage is turning many users away with its absurdly slow initial download. He refactors it so the initial download is nothing more than a banner and the key navigation links. News and featured items are still on the page, but they’re pulled down separately, after the initial page has loaded.
Problem
How can you optimize downloading performance?
Forces
Content can be time-consuming to load, especially when it contains rich images.
Users rarely need to read all the content on the page.
Users often have to click through several times to locate a particular item.
Users sometimes browse around by exploring links between pages.
Solution
Break content download into multiple
stages, so that faster and more important content will arrive
first. Typically, the page is divided into placeholders
(e.g., div elements) with the
content for each placeholder downloaded independently.
XMLHttpRequest Calls can be issued
simultaneously or in a serial sequence, and the page will gradually
be populated as the calls return.
The pattern applies when an application needs to download a lot of content from the server. Typically, this occurs on startup and also when a major context switch occurs. By breaking up the call, you can deliver faster and more important data earlier on. You avoid bottlenecks that occur when a single piece of content blocks everything else from returning.
The initial download of a page might be very small, containing just a skeleton along with navigation links and enough context to help the user decide if it’s worth sticking around. That’s the critical content for a fresh visitor, and there’s no need to make him wait for the rest of the page to load. The browser can request the main page content as a separate call.
This pattern is in some respects an Ajaxian upgrade of the old technique of filling up a page gradually, where the server continues flushing the buffer and the user can see the page as it loads. Ajax makes the whole thing more powerful, because the latter downloads can attach to any existing part of the page.
One resource risk is having too many requests at once. Thus, consider a (purely speculative) Multiplex Call variant. Establish a browser/server protocol that lets the browser wrap multiple requests and the server wrap multiple responses. Then, issue only a single call with all required data inside. The immediate response might return a few results only, so the browser waits a bit, and then makes a further request for outstanding data. The whole process repeats until the browser has all the data.
Decisions
How will the page be divided into blocks?
The trickiest decision is how to divide the page into blocks, each of which will be downloaded individually. Since the blocks are downloaded in parallel, the main advice is to create small blocks of initial content to ensure the initial download is quick, and to group together content that’s likely to be ready at the same time. Also, too many blocks will give the initial load an ugly appearance and may have the undesirable effect of causing already displayed elements to move around. For a fresh visitor, one example would be to create blocks as follows:
A block of general information about the web site; e.g., name, summary, and a small icon.
A navigation block showing links within the site.
A block of general information about the current page, such as a heading and summary text. In a web app, this may be dynamic information based on what processing is being performed.
One or more blocks of main page content.
One or more blocks of auxiliary information; e.g., cross-site promotions, advertising, and legal notices.
Some of these may be combined too, as it’s important to avoid too many blocks. So you might have a single request to retrieve both navigation and general information, which is then split and painted onto separate blocks.
Note that this doesn’t have to apply to a homepage—if you are offering Unique URLs, visitors can jump into an Ajax App at different points, so the main page content might actually be quite “deep” into the application.
How will the page be structured?
Ideally, this pattern should not affect the page appearance, but will require some thinking about the underlying HTML. In particular:
As new information loads, it’s possible the browser application will automatically rearrange the page in order to accommodate new information. This can lead to the user clicking on the wrong thing, or typing into the wrong area, as items suddenly jump around the page. Ideally, information will not move around once it has been presented to the page. At least for images, it’s worthwhile defining the width and height in advance, as CSS properties.
CSS-based layout is likely to play a big part in any solution, as it provides the ability to exercise control over layout without knowing exact details.
What happens to the blocks while their content is being downloaded?
The entire DOM itself can be established on the initial
load, so that divs and other
structures are used as placeholders for incoming content. If
that’s the case, most of those elements can be left alone, but if
the user is waiting for something specific that may take some
time, it would be worth placing a Progress
Indicator on the block where the output will eventually
appear.
It’s also possible to construct the DOM dynamically, so that
new elements are added as new content arrives. This approach may
be more work, but it may help to decouple the browser and the
server. With the right framework in place, it means that the
browser does not have to know exactly which items will be
downloaded. The browser might ask the server to send all adverts,
and the sender simply responds by sending down an XML file with
three separate entries, which the browser then renders by adding
three new divs.
Will the calls be issued simultaneously?
Let’s say you’re at a point where you suddenly need
a whole lot of content. Should you issue several requests at once?
Not necessarily. Keep in mind there are limits on how many
outgoing requests the browser can handle at one time and consider
what’s best for the user. If there’s a bunch of content that might
not be used, consider deferring it for a bit with a JavaScript
setTimeout call. That way, you
can help ensure the user’s bandwidth is dedicated to pulling down
the important stuff first.
Real-World Examples
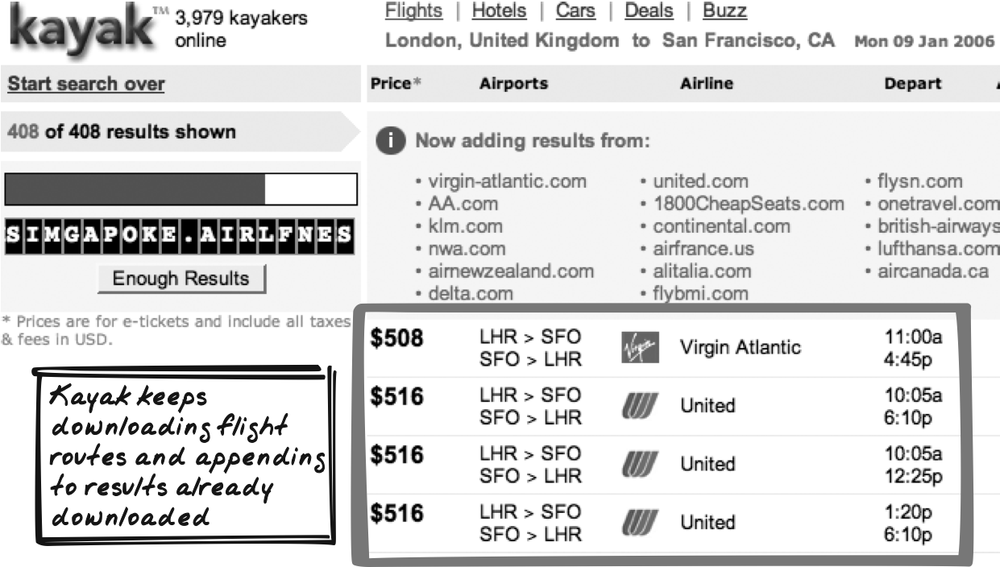
Kayak
Kayak (http://kayak.com) is a travel search engine. You tell it where you’re going, and it then searches through many online travel sites to build up a set of options for you.
While waiting for a search query, the results page initially shows just the site banner, the search you entered, and a Progress Indicator (Figure 13-9). As the results for each external site arrives, Kayak adds the site name and whatever flights it found there. The flights aren’t just appended, but kept in sorted order. You also have the option to finish the search by clicking an Enough Results button.
NetVibes
NetVibes (http://netvibes.com) is an Ajax portal that launches parallel XMLHttpRequest Calls on startup, one for each Portlet. Many portals follow this pattern.
TalkDigger
TalkDigger (http://talkdigger.com) is an Ajaxian
meta-search for web feeds. Traditional meta-searches usually
output results to the browser as they’re received from individual
engines, so the results page isn’t well-ordered. With TalkDigger,
each individual search engine gets its own div on the page. As the results come in,
they’re placed on the right spot.
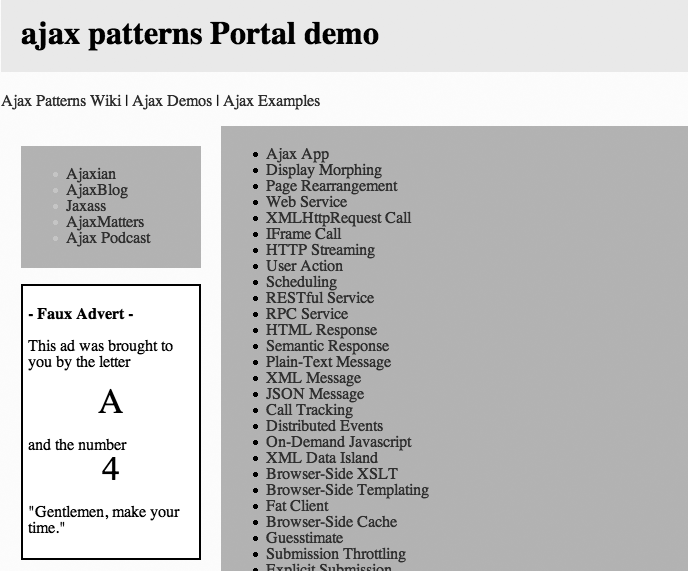
Code Example: AjaxPatterns Portal
The code example is a portal demo (http://ajaxify.com/run/portal) that downloads content in various stages (Figure 13-10):
The page banner and key links are downloaded immediately, as part of the initial HTML.
On page load, a place is set aside for side links, which are then requested and injected into the placeholder.
Likewise, the main content is also requested on page load.
Finally, an ad is requested after a short delay. This ensures the main content arrives first, so the ad doesn’t affect the overall flow. (If you’re feeling entrepreneurial, you can refactor it to reverse the order.)
The initial HTML contains the header and placeholders for the content that will be injected. There’s an initial Loading message for each of these:
<h1>ajax patterns Portal demo</h1>
<a href="http://ajaxpatterns.org">Ajax Patterns Wiki</a> |
<a href="http://ajaxify.com">Ajax Demos</a> |
<a href="http://ajaxpatterns.org/Ajax_Examples">Ajax Examples</a>
<div class="spacer"> </div>
<div id="leftLinks">
<div id="siteLinks">Loading ...</div>
<div class="spacer"> </div>
<div id="ad">Loading ...</div>
</div>
<div id="allPatterns">Loading ...</div>The side links and main content are loaded immediately on page
load, and sent to a callback function that morphs the corresponding
div:
window.onload = function( ) {
ajaxCaller.get("sideLinks.html", null,
onServerResponse, false, "siteLinks");
ajaxCaller.get("allPatterns.phtml", null,
onServerResponse, false, "allPatterns");
...
}
function onServerResponse(html, headers, elementId) {
$(elementId).innerHTML = html;
}A few seconds later—probably after all the content has been loaded—the ad content is requested:
window.onload = function( ) {
ajaxCaller.get("sideLinks.html", null,
onServerResponse, false, "siteLinks");
ajaxCaller.get("allPatterns.phtml", null,
onServerResponse, false, "allPatterns");
setTimeout("ajaxCaller.get('ad.html',null,onServerResponse,false,'ad')",
5000
}Alternatives
All-In-One
As was mentioned, the alternative—and the de facto choice—is to download everything in one go.
Related Patterns
Portlet
Portlets (Chapter 15) are good candidates for content-specific downloads. A portal’s overall structure can be downloaded initially, and each Portlet’s content then be downloaded (and refreshed) in parallel to the rest of the page.
Guesstimate
While a block is waiting to be loaded, you might populate it temporarily with a Guesstimate (see earlier).
Progress Indicator
While a block is waiting to be loaded, you might populate it temporarily with a Progress Indicator (Chapter 14).
On-Demand JavaScript
Like Multi-Stage Download, On-Demand JavaScript (Chapter 6) involves an initial download followed by further downloads later on. That pattern focuses specifically on JavaScript content rather than display and semantic content. It’s also about downloading only when needed. The emphasis here is on downloading according to an initial schedule. Other patterns, such as Microlink and Live Search, cover on-demand downloading of display and semantic content.
Metaphor
Multi-Stage Download mirrors agile project management. If you can deliver some really useful things early on, why hold off until everything else is ready?
Fat Client
⊙ BrowserSide, Decoupled, DHTML, Fast, Responsive, Rich, Thick
Developer Story
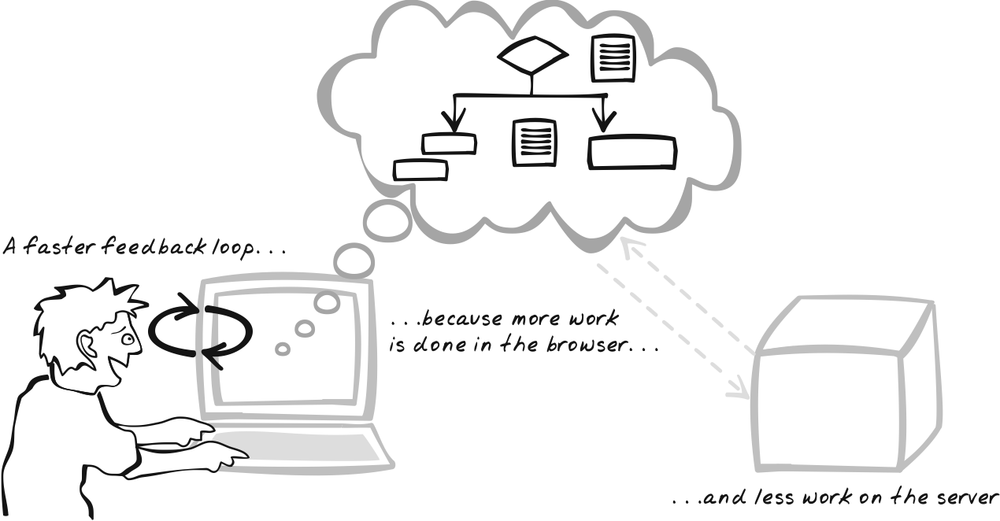
Dave’s new mortgage application is very quick as it avoids server calls wherever possible. After some benchmarking, he discovered that optimized JavaScript is actually fast enough to run the financial algorithms in the browser, so that users now receive almost immediate feedback as they tweak parameters.
Problem
How can you architect the system to feel truly rich and interactive?
Forces
The application should respond to user actions quickly—ideally, instantaneously.
Responses from the server can be noticeably latent due to data transfer and server processing overheads.
Solution
Create a responsive Ajax App by performing remote calls only when there is no way to achieve the same effect in the browser. Whereas the server is traditionally the realm of more complex processing, this pattern suggests harnessing the browser for all it’s worth. In the extreme case, it means running just about everything inside the browser, but that’s not the main message here. The main message is to reconsider the traditional server-centric view of web architecture; for developers to be more conscious about decisions on matters regarding where the various components live. Placing more logic inside the browser gives you the opportunity to make the application more responsive.
Web apps usually have several layers:
User interface
Application logic
Business logic
Data access
External system communication
The user interface is what the user sees and interacts with. The application logic concerns the dialogue between the user and the computer, the flow of information back and forth—for example, given a particular user action, what should the computer do next? The business logic concerns knowledge about the domain and the web site owner’s practices and policies. The data access layer concerns reading and writing data to a persistent store. External system communication is also necessary in many enterprise systems, where outside systems play the role of information sources and sinks.
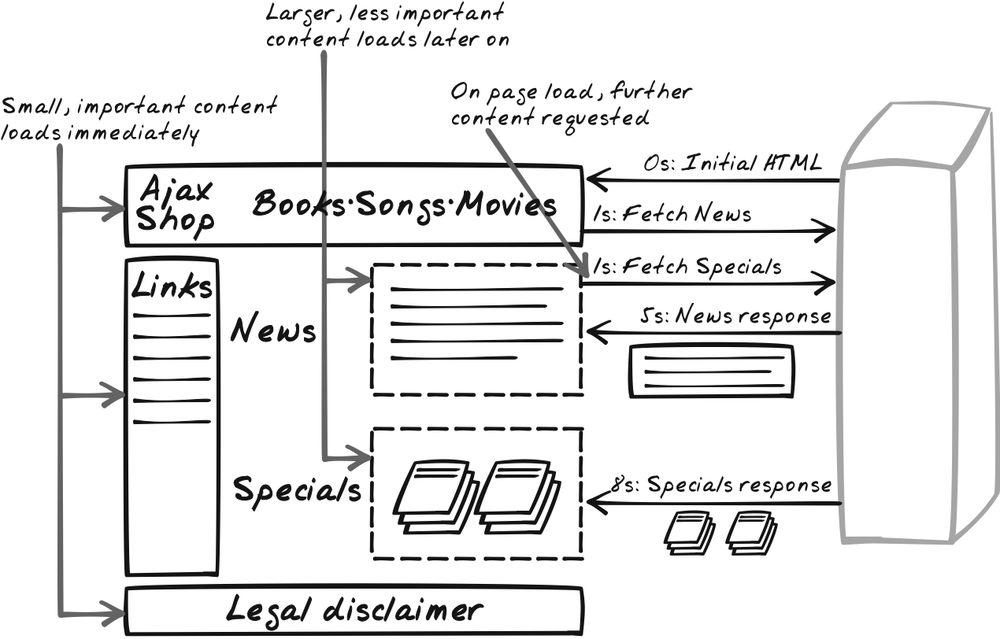
Conventional web apps concentrate UI code in the browser, using a mix of HTML and CSS, with some JavaScript used to perform a few basic UI tricks like placing keyboard focus or showing some animation or offering a dynamic menu. Everything else is usually managed on the server. This pattern reconsiders the balance by suggesting that some applications are better served pushing application and business logic into the browser (Figure 13-12).
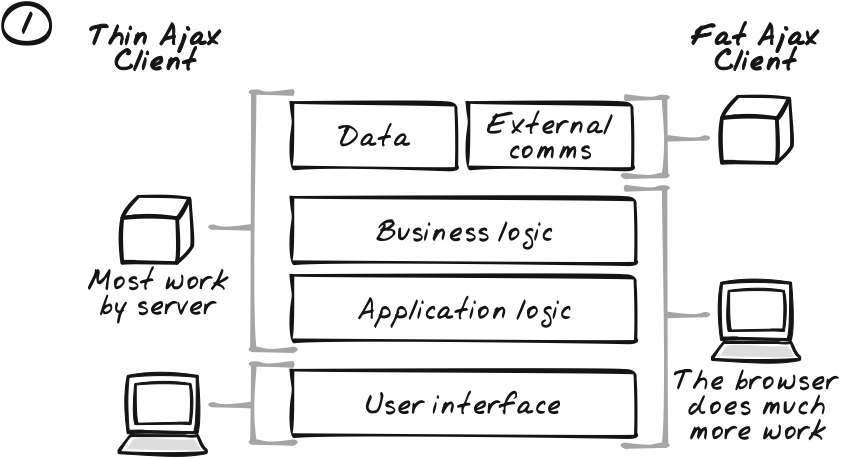
With application logic in the browser, an inversion of control occurs in which the browser now controls the flow of activity. When the user performs some action, it is the browser that decides how to respond, and it calls the server only if necessary, and for very specific services.
The advice to hold business logic in the browser is anathema to most literature on serious web site development and should not be taken lightly. Business logic in the browser has numerous problems:
Programming in JavaScript can be difficult because many features familiar to mainstream developers are unavailable. The standard API is minimal and object-oriented facilities are based on prototypes rather than classes. Indeed, the usage of dynamic typing is also uncomfortable for many developers in the Java and C# camps.
Portability is a further complication due to the number of platforms that must be supported, and their subtly inconsistent behaviors.
Development is also a challenge. Coding, refactoring, debugging, automated testing, and monitoring, are standard in modern IDEs like IntelliJ Idea, but support at this level is minimal for JavaScript.
Security is another constraint that forces logic server side. Savvy users can peruse code and data in the browser and can even tamper with what’s sent back to the server. Obfuscation—making the code difficult to read—is a very weak defense.
Business and application logic should be held on the server, where they can be reused by other clients.
Web data generally can’t be saved on the local machine.
Are any of these showstoppers? Let’s look at how we can cope with each of these problems:
JavaScript may be different from server-side languages, but many programmers are discovering it’s a lot more powerful than previously assumed (http://www.crockford.com/javascript/javascript.html). Until recently, the main resources on JavaScript were “cut-and-paste this code” web sites, but there are an increasing number of books and resources that take the language seriously. The language has undergone a renaissance in parallel with Ajax. New idioms and patterns are emerging, along with a pile of cross-browser frameworks to augment the relatively bare native API. The recent introduction of JSAN (http://openjsan.org)—a repository of JavaScript libraries like Perl’s CPAN—will only further reuse. Object-oriented concepts, including inheritance and aggregation, are indeed possible, if not in a manner familiar to all server-side developers. Dynamic versus static typing is a matter of taste that shouldn’t affect a language’s credibility; the dynamic approach of JavaScript may not be everyone’s preference, but JavaScript is hardly an outsider here.
Browsers are more standard nowadays, and many of the new libraries abstract away browser dependencies (see Cross-Browser Component [Chapter 12]). For example, over a dozen libraries offer a browser-independent factory method to retrieve
XMLHttpRequest.Recent tools are making life a lot easier; some are discussed in Development Patterns (Part V).
Security remains an issue, but it’s possible to deploy the application so that security- critical functionality can be exposed server side in well-defined services, with the bulk of the application logic held locally and calling on those services as required. There might be duplication because browser-side validation is also important for quick feedback, using JavaScript to create a screening test before passing a request to the server. However, there are ways to deal with such duplication if it’s a serious issue. For instance, with server-side JavaScript, you can have the same script running in the browser and the server, or you can use some custom, declarative notation to capture business rules and have processors for it on both sides.
It’s true that certain business logic needs to be made available to multiple clients and therefore needs to exposed as Web Services, in which case there’s a good argument for keeping it inside the server. (It could also be executed in the server as well as the browser, though that’s a fairly unusual practice.) Often, though, business logic is application-specific, and that’s even more the case for application logic (notwithstanding grandiose plans for running the same app on mobile phones and desktops).
Browsers cannot normally persist data locally, but a background thread can be used to periodically synchronize with the server. In the 1990s, many desktop applications forced users to explicitly save their work, whereas today, many desktop applications now save periodically and upon the user quitting. In the same way, it’s now feasible for web apps to persist data transparently, without affecting workflow. If local persistence is critical enough to break away from “pure Ajax,” some easily deployed Flash libraries are available (e.g., Brad Neuberg’s AMASS; see http://codinginparadise.org/projects/storage/README.html).
None of this says that programming in JavaScript is more productive than programming in Java or C# or Ruby. In most cases, it isn’t and never will be. Serious JavaScript programming is nonetheless a very real proposition. Professional software development involves choosing the language that fits the task at hand. Given the many benefits of browser-side coding, there are at least some circumstances that make JavaScript the language of choice for implementation of business and application logic.
Decisions
How will business and application logic be implemented in the browser?
Conventional applications use JavaScript for a little decoration. Even when a lot of JavaScript is used, it’s often packed into tightly scoped library routines, to perform little tricks like validating a form’s fields match regular expressions or popping up a calendar. These are just little detours on the well-travelled road between browser and server. In contrast, a Fat Client responds to many events itself, delegating to the server only if and when it deems necessary.
All this implies a very different usage of JavaScript, and there are some techniques that can help. It’s beyond the scope of this chapter to cover them in detail, but here are a few pointers:
It’s easy to fall into the trap of “paving the cow paths”[*] by applying design styles from other languages to JavaScript. It’s usually more productive to embrace JavaScript as a unique language with its own idiosyncratic features and usage patterns, and to be wary of applying architectural concepts from your favorite server-side language if they don’t seem to fit in.
JavaScript uses a prototype-based paradigm, which is worth learning about. Object-oriented concepts like inheritance are certainly possible, but it’s important to appreciate how they fit in to the prototype model.
Development and deployment practices apply as much to a rich browser application, and are as important as testing the server code, as discussed in Development Patterns (Part V).
JavaScript runs slower than equivalent desktop applications, so optimization is important. Also, consider issues memory usage and be aware of browser-specific bugs that might lead to memory leaks.
Break complex applications into multiple JavaScript files and consider managing them with On-Demand JavaScript.
Reuse, Reuse, Reuse. As Appendix A shows, there’s a proliferation of JavaScript frameworks and libraries becoming available.
Real-World Examples
NumSum
NumSum (http://numsum.com) is an Ajax spreadsheet that provides all the basic spreadsheet functionality in JavaScript: insertion and deletion of rows and columns; various formulas; the ability of a user to enter values into any cell; text-formatting (bold, italic, or underlining); text-justification; and embedded links and images.
The basic spreadsheet is implemented as a table. Table cells aren’t actually
editable, so the script needs to simulate an editable table. An
event handler ensures that a cell becomes active when the user
clicks on it, and that cell is then morphed to reflect subsequent
user input.
Gmail
Gmail (http://gmail.com), like several of its competitors, presents a rich, Ajax interface to a mail system. Conventional web mail offerings rely heavily on form submissions and page reloads—a new page must be opened each time the user wants to start composing an email, finish composing an email, or open up an email message. With Gmail, the list of emails is always present and regularly refreshed. Partial edits are periodically saved as well. All of these activities are handled within the browser using a combination of Display Manipulation (Chapter 5) and Web Remoting (Chapter 6).
DHTML Lemmings
DHTML Lemmings (http://www.oldgames.dk/freeflashgames/arcadegames/playlemmings.php) shows how much can be achieved with some clever JavaScript hacking (Figure 13-13). It’s a full-featured implementation of the Lemmings PC game utilizing a Richer Plugin only for sound—the entire game runs on DHTML, DOM, and CSS. The gameplay consists of a static image for the current level, with Sprites used to render the lemmings and other objects in the game. There is a periodic timer continuously checking the current state of each object, and DOM manipulation of the objects’ properties is used to render their states at any time.

JS/UIX shell
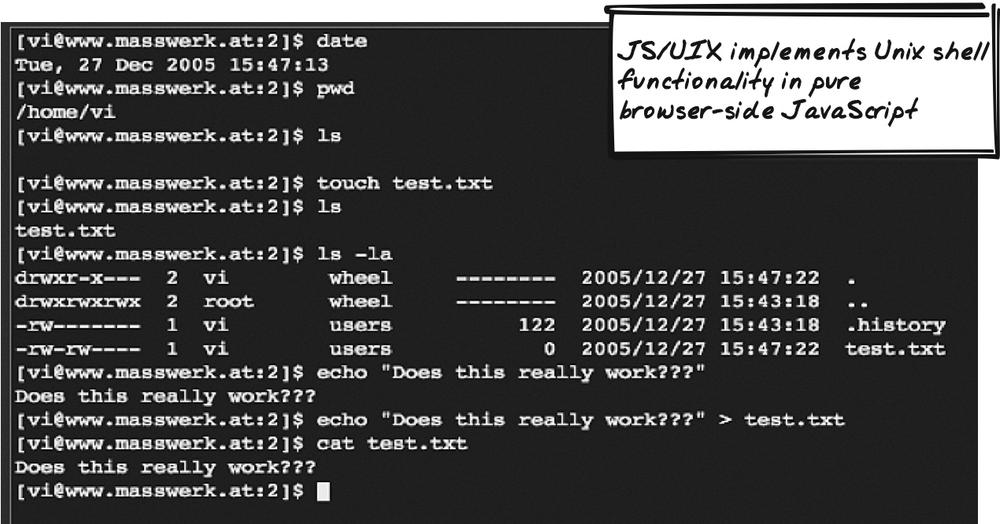
JS/UIX shell (http://www.masswerk.at/jsuix/) is a demo of an in-browser Unix shell (Figure 13-14). In its current form, it’s a demo only. But it’s capable of all the basic operating systems commands and even includes a vi editor! The approach stands in contrast to browser-side terminal emulators, which are thin applications that pass characters back and forth. With appropriate server-side integration, the application could be made into a functional multiuser application. Command line remains the mode of choice for many power users, and this demo shows how an Ajax Fat Client can achieve it.
Code Example: AjaxPatterns Basic Wiki
The Wiki Demo (http://ajaxify.com/run/wiki) is based on Fat Client principles, though its functionality is fairly limited. All of the interaction and rendering occurs locally. The only interaction with the server is a periodic synchronization event, when the following occurs:
Pending messages are uploaded, an example of Submission Throttling (Chapter 10).
All current messages are retrieved from the server, so that messages from other users are shown. This is an example of Periodic Refresh (Chapter 10).
There’s a timer to ensure synchronization occurs after five seconds of inactivity:
var syncTimer = null;
function startPeriodicSync( ) {
stopPeriodicSync( );
syncTimer = setInterval(synchronise, 5000);
}
function stopPeriodicSync( ) {
clearInterval(syncTimer);
}The timer starts on page load and is suspended each time the user begins to modify some text:
window.onload = function( ) {
synchronise( );
startPeriodicSync( );
}
function onMessageFocus(event) {
...
stopPeriodicSync( );
}
function onMessageBlur(event) {
...
startPeriodicSync( );
}The script also contains a variable to accumulate pending messages whenever the user changes something:
var pendingMessages = new Array( );
...
function onMessageBlur(event) {
...
if (message.value != initialMessageContent) {
pendingMessages[message.id] = true;
...
}The synchronization event builds up some XML to post to the
server, based on the pendingMessages array that has been
accumulated. If no changes are pending, it simply requests the
current server state. If there are changes pending, it posts those
changes as an XML message. Either way, the server will respond with
an XML specification of its current state.
function synchronise( ) {
var messageTags = "";
for (messageId in pendingMessages) {
var initialServerMessage = $(messageId).serverMessage;
messageTags += "<message>";
messageTags += "<id>" + messageId + "</id>";
messageTags += "<lastAuthor>" + $("authorIdSpec").value + "</lastAuthor>";
messageTags += "<ranking>" + initialServerMessage.ranking + "</ranking>";
messageTags += "<content>" + escape($(messageId).value) + "</content>";
messageTags += "</message>";
$(messageId).style.backgroundColor = "#cccccc";
}
var changesOccurred = (messageTags!="");
if (!changesOccurred) {
ajaxCaller.getXML("content.php?messages", onMessagesLoaded);
return;
}
var changeSpec = "<messages>" + messageTags + "</messages>";
ajaxCaller.postBody
("content.php", null, onMessagesLoaded, true, null, "text/xml", changeSpec);
pendingMessages = new Array( );
}The main application logic is virtually orthogonal to server synchronization. The only concession is the accumulation of pending messages, to save uploading the entire browser state each time. The timer and the synchronization process know about the core wiki logic, but the core wiki knows nothing about them and can therefore be developed independently. It’s easy to imagine how the wiki could evolve into something with much richer browser-side features, like formatted text and draggable messages and so on.
Alternatives
Thin client
A thin client contains only basic JavaScript and frequently refers back to the server for user interaction. This is likely to remain the dominant style for Ajax Apps and is useful in the following circumstances:
It’s important to support legacy browsers. Graceful degradation is still possible with Fat Clients, but requires more work, and there’s the potential for a lot of redundancy.
Business logic requires sophisticated programming techniques and libraries that can only be implemented server side.
Business logic involves substantial number crunching or other processing that can only be performed server side.
Due to bandwidth and memory constraints, the application cannot be held locally.
There is complex dialogue required with external services, and due to cross-domain security policies, those services cannot be accessed from the browser.
Desktop client
A desktop client runs as a standard application in the user’s operating system, and connects to one or more servers using HTTP or any other protocol. Compared to a Fat Client, a desktop client can be richer and faster. However, the benefits of a web-enabled application are lost as a result. You can compensate for some of these benefits:
Portability can be achieved with a platform-neutral programming platform.
Centralized data can be achieved by ensuring all data is retained server side.
Familiar user interfaces can be achieved by tailoring to each individual platform’s look-and-feel.
In some contexts, a desktop client represents the best of both worlds: a rich client backed by a powerful server. In other situations, a Fat Client based on Ajax principles is a more appropriate sweet spot: a powerful server, a rich-enough client, and easy access through any modern web browser.
Related Patterns
Periodic Refresh
Periodic Refresh (Chapter 10) is a relatively unobtrusive way for the client state to be enriched with any new server-side information.
Submission Throttling
Submission Throttling (Chapter 10) is a relatively unobtrusive way for the server to be notified of any significant changes that have occurred in the browser.
Widgets
If the user is going to spend a long time in the browser, the various widgets (Chapter 14) should be adopted to improve the experience.
On-Demand JavaScript
Since Fat Clients tend to contain bulkier scripts, On-Demand JavaScript (Chapter 6) is useful for managing them.
Drag-And-Drop
Drag-And-Drop (Chapter 15) is familiar to many desktop users and helps to make a large application feel more natural. Whereas more conventional web clients rely on form-style interaction, Fat Clients can feel more rich if they support Drag-And-Drop.
Host-Proof Hosting
Where a Fat Client is seen as a replacement for a desktop equivalent, Host-Proof Hosting (Chapter 17) might be considered to avoid compromising on the superior security a localized solution sometimes offers.
Metaphor
Agile development methodologies such as Scrum aim for an “inversion-of-control.” Workers (like the Fat Client) are empowered to plan their own activities, and management’s role (the Server) is to offer whatever services workers request in order to conduct those activities.
Want to Know More?
Google Groups Discussion: “Applications in the Browser or the Server?” (http://groups-beta.google.com/group/ajax-web-technology/browse_thread/thread/e40317a830ad841d/06483bf77587a62c#06483bf77587a62c)
“JavaScript: The World’s Most Misunderstood Programming Language” by Douglas Crockford (http://www.crockford.com/javascript/javascript.html)
“JavaScript is not the devil’s plaything” by Cameron Adams (http://www.themaninblue.com/writing/perspective/2005/04/12/)
[*] This example is taken from an O’Reilly Network article (http://www.oreillynet.com/pub/wlg/6782).
[*] An expanded analysis of the iTunes counter can be found on my blog at http://www.softwareas.com/ajaxian-guesstimate-on-download-counter. Some of the comments and spacing has been changed for this analysis.
[*] “Paving the cow paths” refers to the way cows mindlessly follow an old path, continuing to walk around trees that aren’t actually there anymore.
Get Ajax Design Patterns now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

