Chapter 14. Widgets
THE WIDGETS PROVIDED BY STANDARD HTML—TEXT INPUTS, RADIOBUTTONS, AND SO ON—HAVEN’T changed much for ten years and are getting a little tired. So many people have been building their own widgets on top of the standard HTML offerings, and a few patterns have emerged. It’s unlikely you’ll need to build these widgets yourself, because library implementations are available for almost all of them. Nevertheless, it’s worth it to consider when to use them and how to configure them.
The chapter starts with smaller, isolated widgets and builds up to more complex components. Slider is “the widget HTML forgot”—a typical slider widget so useful it’s surprising it hasn’t yet become standard HTML. Progress Indicator is a simple message or animation shown while waiting for a web remoting call. Drilldown is a control for selecting an element within a hierarchy.
Traditional HTML widgets are turbo-charged in the next couple of patterns. Data Grid is a “table on steroids,” with tools for querying and restructuring that will be familiar to users of spreadsheets and database report tools. And Rich Text Editor is a “textarea on steroids,” with options such as font size and color similar to those of a modern word processor.
Suggestion is similar to the traditional combo-box, a mixture between browsing and searching that relies on web remoting to locate a set of options against a partial text input. Live Search works similarly but shows search results rather than helping to complete a text field. It also works with nontext controls.
Finally, Live Command-Line and Live Form are higher-level patterns that tie together various widgets and patterns. The former is largely speculative and explores techniques to help people learn and use command-line interfaces within the Web. The latter is a more proven Ajax Pattern—a form that keeps changing in response to user input.
Slider
⊙⊙⊙ Continuous, Lever, Multiple, Range, Slider
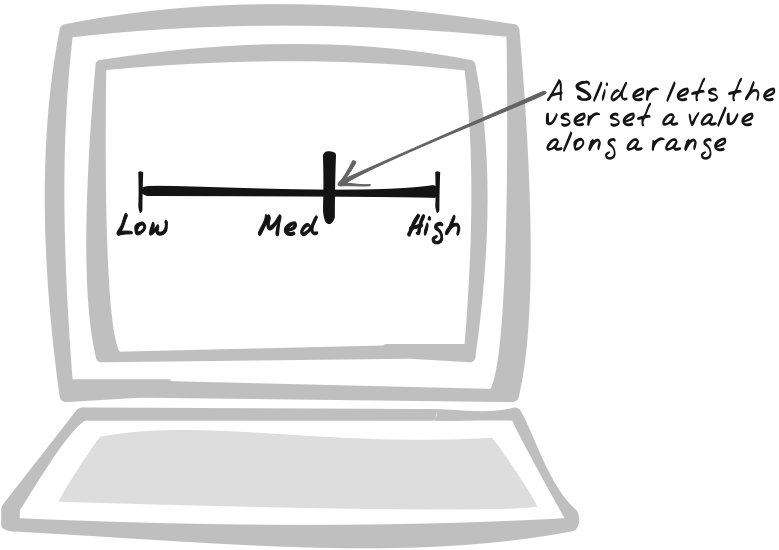
Goal Story
Stuart is rating his lecturer online. Each answer lies somewhere between “Strongly Disagree” and “Strongly Agree.” Unlike conventional surveys, the scale is continuous, because Stuart uses a Slider to set a precise value along the spectrum.
Problem
How can users specify a value within a range?
Forces
Most data is constrained to reside within a range.
Prevention is better than cure; the user interface should be designed such that the user is forced to choose a value within the range instead of the interface checking and providing an error message later on.
Solution
Provide a Slider to let the user choose a value within a range. The user drags a handle along one dimension to set the value. As a variant, two handles on the same Slider can allow the user to choose a range instead of a single value.
Standard HTML contains two related input controls: radiobuttons and selectors. Each of these lets you specify a value from a fixed list of choices. The biggest advantage of a Slider is that the data range can be continuous as well as discrete. Of course, “continuous” is an approximation, since you can only have as many choices as there are pixels in the Slider range. But with most Sliders, that means you have hundreds of unique values, which is continuous for most intents and purposes.
A Slider can also show discrete data by identifying several points along the range. When the user releases the handle, the Slider jumps to the nearest point. Why use a Slider when radio buttons and selectors already support discrete data? A Slider provides a better visual indication that the data resides in a spectrum. Also, it’s often faster because the user can click anywhere in the region as opposed to aiming precisely at a radiobutton or opening up a dialog box.
A further benefit of Sliders is their excellent support for comparing similar data. When several Sliders share the same range, they can be placed in parallel to show how the variables differ. For example, a product survey could ask questions such as “Were you happy with the price?” and “How easy was it to start using?” The answers lie on a different scale but ultimately map to the same range from “Unhappy” to “Happy.” Placing these horizontal rows in parallel helps the user stick to the same scale and compare each factor to the others.
Because Sliders aren’t standard controls, you’ll need to either use a library or roll your own. Typical control mechanisms include the following:
Dragging the handle moves it directly.
Clicking on either side of the handle moves it a little in that direction.
While the Slider has keyboard focus, pressing left and right arrows move it in either direction. It’s sometimes useful to offer an accelerator key such as Shift, which, held down at the same time as the arrow, speeds up the handle movement. Keyboard controls are particularly important when the control is part of a form.
Receiving notifications from external sources. The Slider is sometimes synchronized with another object, so if that object changes, the Slider must update too.
A typical implementation separates the scale from the handle.
The scale consists of a line, possibly with some notches and labels.
The handle is usually an image, with the zIndex property set to place it “in front
of” the main Slider. There are several event handlers required to
support all of the mechanisms above, and the Slider handle itself is
manipulated using techniques discussed in
Drag-And-Drop (Chapter 15). In addition, movements
will often trigger other activity, such as an
XMLHttpRequest Call or a change to another page
element.
Decisions
How will you orient the Slider?
There are two options for orientation: horizontal or vertical. Following are a few considerations:
- Data type
Sometimes the nature of the data dictates which option is more logical. For instance, Google Maps uses a vertical Slider for zoom, which corresponds to a feeling of flying toward and away from the map as you zoom in and out.
- Layout
Aesthetic appearance and space conservation are important. Many forms will feature horizontal Sliders because they fit well underneath questions. Vertical Sliders would lead to a lot of whitespace.
- Proximity
Where the Slider controls something else on the page, you’ll probably want to place them near each other, which might dictate orientation.
- Comparison
As mentioned earlier in the "Solution,” Sliders work well when placed in parallel, which means a common orientation.
What scale will you use?
There are quite a few ways to present a variable, and the choice will depend on the nature of the data and what users are comfortable with. Examples include:
Qualitative descriptions (“Low”, “High”). This might seem suited only to discrete ranges, but the labels can also be used as markers within a continuous range.
Absolute values.
Percentages (typically ranging from 0 to 100).
How will you present the scale?
There are various strategies for presenting the scale:
Provide no labels; rely on context and conventions. For instance, users—at least in western countries—usually assume Sliders increase in value to the right.
Provide just a label at either end.
Provide labels at several points along the range.
The labels are usually shown alongside the Slider, but to conserve space, you can sometimes show them inside it.
Real-World Examples
Yahoo! Mindset
A product of Yahoo Labs, Yahoo! Mindset (http://mindset.research.yahoo.com/) lets you tweak search results with an unusual type of Slider that ranges from “shopping” on one end to “researching” on the other (Figure 14-2). Pull the “Ajax” results towards “shopping” and you’ll see links to cleaning products and football. Pull it to the right and you’ll see some information about web design (and, it must be said, more football). Also of note: the Slider is “Live”—each time you change it, the results are automatically updated via an XMLHttpRequest Call.

Amazon Diamond Search
Amazon Diamond Search (http://www.amazon.com/gp/gsl/search/finder/002-1527640-2908837?%5Fencoding=UTF8&productGroupID=loose%5Fdiamonds) presents several elaborate Sliders (see Figure 14-5). Each lets you specify a range, which acts as a filter for the diamond search. There are several innovative aspects of the presentation, discussed next.
The labels are dynamic. As you drag the handles, the labels show exactly the value that’s been specified.
There’s a graphic inside the Slider, which represents the variable in each case. Price, for example, is shown as an increasing histogram, and Cut shows several diamonds of decreasing cut quality.
The Slider graphic is faded outside the selection region.
Each Slider has a Microlink (Chapter 15) that opens up an explanation about that variable.
The Sliders are horizontal and parallel to each other. Unfortunately, the directions aren’t aligned—price and carat increase from left to right, but cut quality increases from right to left.
Google Maps
Google Maps (http://maps.google.com), like most of its Ajaxian map counterparts, uses a Slider to control the zoom level.
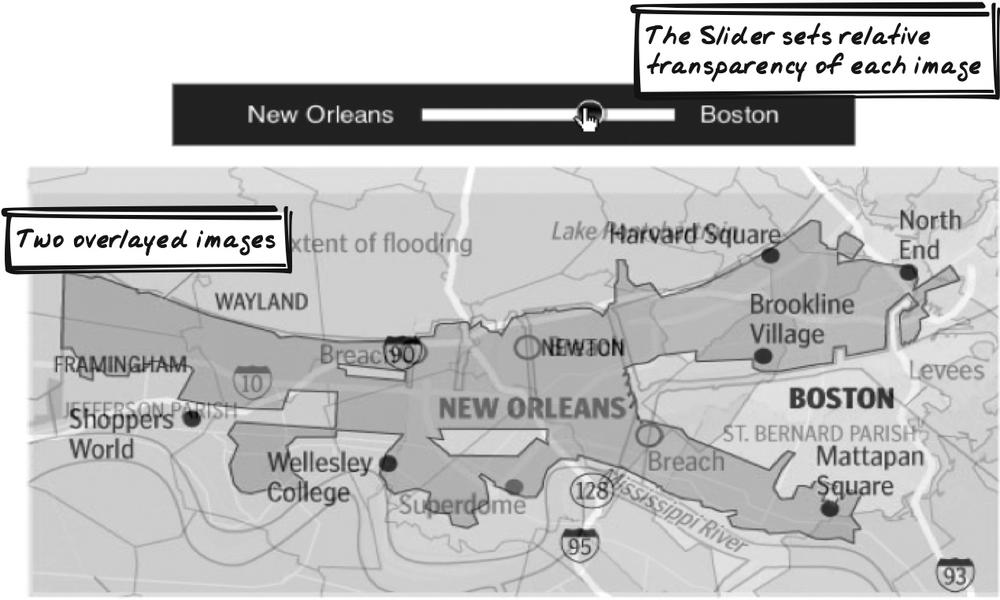
Katrina-Boston map overlay
In the wake of hurricane Katrina, Boston.com produced an overlay map (http://www.boston.com/news/weather/hurricanes/multimedia/globe_map/) combining the flood-affected area of New Orleans with a Boston region of identical proportions (Figure 14-3). A Slider is used to alter opacity: at one extreme, you can only see the New Orleans image; at the other extreme, you can only see the Boston image. In the middle, you can see both images, with one or the other dominant depending on the position of the Slider. The application is implemented in Flash, but could easily be implemented with standard Ajax technology.
WebFX Slider Demo
The WebFX Slider Demo (http://webfx.eae.net/dhtml/slider/slider.html) shows a few different Sliders, in both horizontal and vertical orientations. You can set the Slider directly and also update it with some text inputs.
Code Example: Yahoo! Mindset
The Yahoo! Mindset Slider (http://mindset.research.yahoo.com/) is created with several images. There are images for the vertical lines at the center and extremes. The main horizontal bar is created with a single vertical line; it’s 1 pixel wide, but the image width is set to 150 pixels, thus creating a horizontal bar. There’s a handler registered for the click event (which pulls the handle in that direction):
<img id="slidergrayrightimg" src="images/gray_bar.gif"
height="36" width="150" unselectable="on"
onClick="setup('1505998205%3Ac26b16%3A105900dfd3e%3Aff4', 'ajax');
endDrag(event); return false;">The Slider handle, called sliderball, is also an image:
<img id="sliderball" src="images/aqua_ball_trans.gif"
onMouseDown="dragStart(event, '1505998205%3Ac26b16%3A105900dfd3e%3Aff4',
'ajax'); return false;" unselectable="on"
style="position: relative; z-index: 1; top: 0px; left: -136px;"
height="36" width="18">A drag function is
registered to handle moving the mouse after the handle has been
selected. Based on the current mouse position, it calculates where
the Slider should be and calls a function to move it:
function dragStart(e, sID, q) {
...
document.onmousemove = function(e) { drag(e); };
document.onmouseup = function(e) { endDrag(e); };
...
}
function drag(e) {
...
var relativePos = e.clientX - sliderOffset;
...
moveSlider(relativePos);
}The moveSlider function
redraws the handle based on its relative position (positive or
negative offset from the center):
function moveSlider (relativePos) {
var centerPoint = (maxRight - minLeft) / 2;
var centerBuffer = 5;
//the ball position is relative
var ballPos = (-(maxRight - minLeft)) + (relativePos-(ballWidth/2));
document.getElementById('sliderball').style.left = ballPos+'px';
...
}Finally, when the Slider is released, the handle’s position is finalized and an XMLHttpRequest Call is issued to bring the results in line with the new value:
function endDrag(e) {
...
var relativePos = e.clientX - sliderOffset;
drag(e);
...
var sliderURI = "/searchify/slider?UserSession="+sessionID+
"&SliderValue="+threshold+"&query="+query;
(Sends XMLHttpRequest to SliderURI)
}Alternatives
Related Patterns
Drag-And-Drop
The Slider handle is usually manipulated with a Drag-And-Drop (Chapter 15) action.
Metaphor
Sliders are a UI metaphor based on physical sliders in control devices such as audio-visual consoles.
Progress Indicator
⊙⊙⊙ Activity, Feedback, Hourglass, Meter, Progress, Waiting
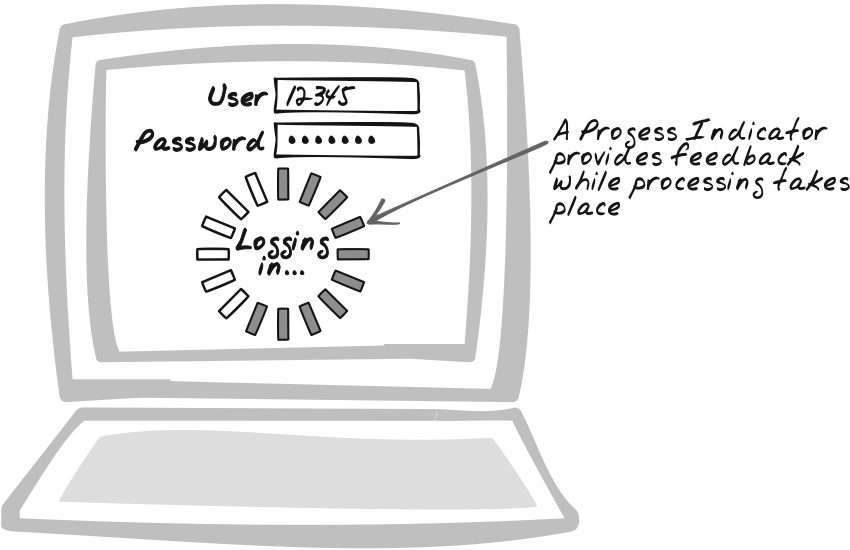
Goal Story
Reta has made a sale and is typing in the details. She completes the credit card details and proceeds down the page to delivery dates. Meanwhile, the status area has appeared beside the credit card details. While she completes the rest of the form, the status area continues to update with the current verification stage—initially “submitted,” then “responding,” then “verified.”
Problem
How can you provide feedback while waiting for server responses?
Forces
Ajax Apps often make XMLHttpRequest Calls (Chapter 6) to query and update the server.
To provide good feedback, you should provide an idea of which page elements are affected by any update.
Users like to feel in control, and that control is taken away when the user is waiting for a response. It’s not just the delay that should be minimized, but the perceived delay.
Solution
Indicate the progress of server calls. You can’t always reduce delay, but you can include a Progress Indicator to ease the pain. A Progress Indicator helps maintain the user’s attention, improves the user’s understanding of how the system works, and also communicates that the system is still alive even if a response hasn’t yet occurred.
The Progress Indicator is typically introduced to the DOM once
an XMLHttpRequest Call begins and removed when the call has returned. The
easiest way to detect whether the call has returned is using the
XMLHttpRequest callback function.
An indicator need not relate to a single call—it can show progress
for a sequence of related calls.
Sometimes it’s a Popup (Chapter 15) element instead of a new element directly on the page. A popular idiom is a small opaque Popup on the corner of the page showing just a word or two (i.e., “Saving . . . “, “Loading . . . “).
For shorter delays, typical Progress Indicators include:
A small message like “Updating document”
An animated icon (there’s now a library of open source Progress Indicator icons available at http://mentalized.net/activity-indicators/)
For longer delays, the following can be used:
A meter showing how much progress has been made
An estimate of time remaining
A sequence of messages indicating what’s happening at present
Content that’s engaging but not directly related to the progress, such as “Tip of the Day” or a canned graphical depiction of system activity
Of course, you can combine these approaches. Generally speaking, some form of unobtrusive animation is worthwhile in any Progress Indicator, because it at least tells the user that something’s happening, even if progress is temporarily stuck. In addition, longer delays should usually be completed with a visual effect such as One-Second Spotlight (Chapter 16), since the user’s focus has probably moved elsewhere by that stage.
Note that one form of indicator to avoid is changing the cursor. Many traditional GUIs switch over to a “rotating hourglass” or related icon during delays. That’s probably inappropriate for Ajax because it’s something the actual browser software will do too—e.g., while loading a new page—so it’s likely to create confusion.
Decisions
What sort of Progress Indicator will you use?
A well known set of guidelines is summarized in Jakob Nielsen’s Usability Engineering (http://www.useit.com/papers/responsetime.html). Following is a quick summary:
If the delay is less than 0.1 second, the user will feel it’s instantaneous. No feedback necessary.
If the delay is between 0.1 second and 1 second, the user will notice it but it won’t break their flow of thought. No feedback necessary.
If the delay is between 1 and 10 seconds, the user’s flow of thought is interrupted as he awaits the response. Basic feedback necessary; i.e., an indication that a delay is occurring. Ajax examples include animated icons and simple text messages.
If the delay is greater than 10 seconds, the user will want to proceed to other tasks. Detailed feedback necessary. Ajax examples include progress meters and messages showing current state.
The precise figures may require some adjustment and I suspect a web context requires them to be dropped a bit. For example, users will probably want some feedback for a delay of 0.5 second rather than 1 second, and more detailed information is probably appropriate after 2–3 seconds rather than 10 seconds.
Bruce Tognazzini also offers some useful guidelines (http://www.asktog.com/basics/firstPrinciples.html#latencyReduction).
How will you provide feedback during longer delays?
For longer delays, you need to help the user track how much progress has been made, typically using a progress meter that shows percent complete. Sometimes, a long delay can come from a single XMLHttpRequest Call, because although the network transfer may be quick, the backend processing might not be. For example, the call might trigger a major database operation.
You probably won’t get any useful information about its
progress by monitoring the responseText component of XMLHttpRequest. The responseText tends not to populate in a
linear fashion, for two reasons. First, there are usually backend
calculations involved, during which no output can occur. Thus,
output tends to happen either in bursts or all at the end. Second,
the output is often compressed using the standard HTTP content
encoding facility, and the compression algorithm will force data
to be outputted in bursts. The XMLHttpRequest’s readyState won’t tell you very much
either. For reasons described in XMLHttpRequest
Call and
HTTP Streaming (Chapter 6), tracking
support is inconsistent across browsers.
So if you can’t monitor the progress of an XMLHttpRequest Call, how can you help the user understand how much progress has been made? One thing you can do is Guesstimate: predict the total time, and start running a timer to monitor how long it has been since the call began. The prediction of total duration need not be hardcoded every time; you could have the application track download times and reflect them in future estimates. This sort of thing is quite common; e.g., in the download-time estimates given by a web browser.
If you want more accuracy, introduce a second monitoring channel. While the primary request takes place, a sequence of monitoring requests are issued to ask the server for a progress estimates. For example, the server might be looping through 1,000 records, running a transformation on each and saving it to the database. The loop variable can be exposed in a second Web Service so that the browser monitoring can inform the user.
Not all Progress Indicators concern a single XMLHttpRequest Call. Indeed, those requiring a progress meter are longer processes, likely incorporating several XMLHttpRequest Calls. With those, you have much better opportunity for real-time progress monitoring; each time a call returns, further progress has occurred. In a simple model, you can show that progress is 50 percent complete when two of four calls have returned.
Real-World Examples
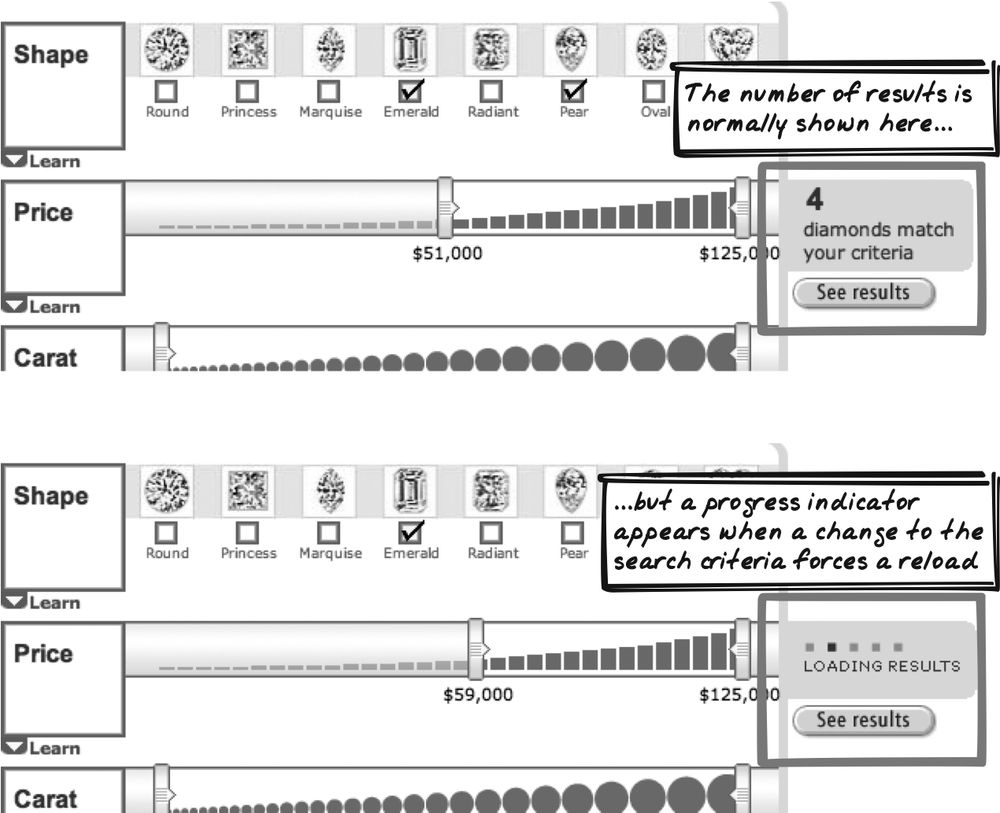
Amazon Diamond Search
Amazon Diamond Search (http://www.amazon.com/gp/gsl/search/finder/002-1527640-2908837?%5Fencoding=UTF8&productGroupID=loose%5Fdiamonds) is a Live Search that shows a Progress Indicator while updating the number of results (Figure 14-5). The indicator is a simple animation depicting a block moving back and forth with a “LOADING RESULTS” message. One nice design feature is the placement of the Progress Indicator on the result status. It replaces the results once searching has begun and remains until the new results are shown. Thus, it serves to invalidate the previous results at the start and focuses the user’s attention on the new results at the end.
Amazon Zuggest
Like Amazon Diamond Search, Francis Shanahan’s Amazon Zuggest (http://www.francisshanahan.com/zuggest.aspx)is a Live Search that shows a Progress Indicator while searching is underway. In this case, the indicator is a text message such as “Searching...beat.” It occupies its own fixed area, and when searching is complete, morphs into another message: “Done!”
Protopage
Protopage (http://www.protopage.com/) is an Ajax portal. Each time you make a change, such as dragging a Portlet (Chapter 15), an opaque “Saving . . . " message appears in the bottom-right corner. This is a good model for a Fat Client application, in which server synchronization should be unobtrusive.
TalkDigger
TalkDigger (http://talkdigger.com) simultaneously calls several search engines, showing a Progress Indicator on each result panel. It’s interesting because it shows how to use Progress Indicators in a Multi-Stage Download (Chapter 13) situation.
Kayak
Kayak (http://kayak.com) illustrates how to handle a longer delay. When you search for a trip, it creates a result page with several forms of progress feedback:
The number of search results so far.
A progress meter that fills up from left to right.
A sampling of web sites that are being searched.
A nice graphic depicting a retro, pre-electronic airport display board. Initially, each character is random. As the search of a particular web site proceeds, the random characters are replaced with the correct character for that web site. Meanwhile, the characters that remain unpopulated continue to flicker from one random character to another. Once all characters have been corrected and the web site name displays correctly, the display becomes random again and starts revealing another web site. All this is an excellent example of a graphic that is engaging and at the same time indicative of the processing that’s occurring.
The Pick’em Game
The Pick’em Game (http://www.pickemgame.com/welcome/picksheet) is an office pool game allowing you to predict this week’s football winners. It provides a form where you declare a prediction and confidence level for each game. Above the form is a small instruction message, and when data is being saved, it morphs into a Progress Indicator. The indicator is a spinning disk and an “Updating Pick Sheet” message. (The demo page doesn’t perform a real remote call.)
Code Refactoring: AjaxPatterns Progress Indicator Demo
This demo (http://ajaxify.com/run/sum/progress) introduces a progress display to the Basic Sum Demo (http://ajaxify.com/run/sum/progress). It’s a simple animated GIF that shows up while waiting for the sum to return.
An Img tag for the
animation is present in the initial HTML:
<img id="progress" class="notWaiting" src="progress.gif">
The script will toggle the image’s CSS class depending on whether you’re in waiting mode or not. The stylesheet ensures that it’s visible when waiting and invisible when not:
.waiting {
visibility: visible;
}
.notWaiting {
visibility: hidden;
}With the styles defined, the script just has to flick the CSS class back and forth as the waiting status changes:
function submitSum( ) {
$("progress").className = "waiting";
...
}
function onSumResponse(text, headers, callingContext) {
$("progress").className = "notWaiting";
...
}Related Patterns
Status Area
A Progress Indicator is usually presented as a Status Area (Chapter 15).
Popup
The Progress Indicator can sometimes reside in a Popup (Chapter 15).
One-Second Spotlight
Once a long process has completed, use a One-Second Spotlight (Chapter 16) to point this out to the user.
Guesstimate
Sometimes you don’t know how long a task will take or how much progress has been made so far. A sloppy guess is better than nothing at all, so make a Guesstimate (Chapter 13) of the progress.
Distributed Events
When a call comes in, you need to close off the Progress Indicator. There’s a risk here that you’ll end up with a single function that mixes Progress Indicator stuff with the logic of processing the response. Separate that logic using Distributed Events (Chapter 10).
Metaphor
Banks and post offices often use ticket-based queueing systems, showing the number that’s currently being served.
Want to Know More?
Gnome Guidelines, Chapter 7: Feedback (http://developer.gnome.org/projects/gup/hig/1.0/feedback.html)
AskTog.com First Principles of Interaction Design, Latency Reduction (http://www.asktog.com/basics/firstPrinciples.html)
Drilldown
⊙⊙ Drilldown, Menu, Progressive
Goal Story
Pam is booking a trip on the corporate travel planner. She sees a form with the usual fields and clicks on location. Suddenly, a list of cities fades in beside the form, and Pam selects Paris. Beside the city list, a third list appears, this one showing approved hotels. Pam chooses the Hilton, and both lists disappear. The location field now contains “Paris Hilton” as Pam had intended.
Problem
How can the user select an item in a hierarchical structure?
Forces
Applications and web sites are often arranged in hierarchies. To navigate, users need to choose a page from within the hierarchy.
Hierarchy navigation should be fast.
Solution
To let the user locate an item within a hierarchy, provide a dynamic Drilldown. The Drilldown allows for navigation through a hierarchy and ultimately for an item to be chosen. At each level, there are several types of elements in the Drilldown:
- Current category
A read-only name for the present level.
- Individual items
Items the user can choose in order to end the interaction.
- Child categories
Deeper levels the user can drill down to.
- Ancestor categories
Parent category and above that let the user “drill up.”
In some hierarchies, items and categories are mutually exclusive: items only exist at the edges—or leaves—of the hierarchy. Even when that’s the case, items and categories should be distinguished for the sake of clarity. The upward navigator goes by different names, but a general guideline is that it should tell the user which category that she is going back to.
Typical applications include navigating and filling out a field by drilling down a hierarchy of candidate items.
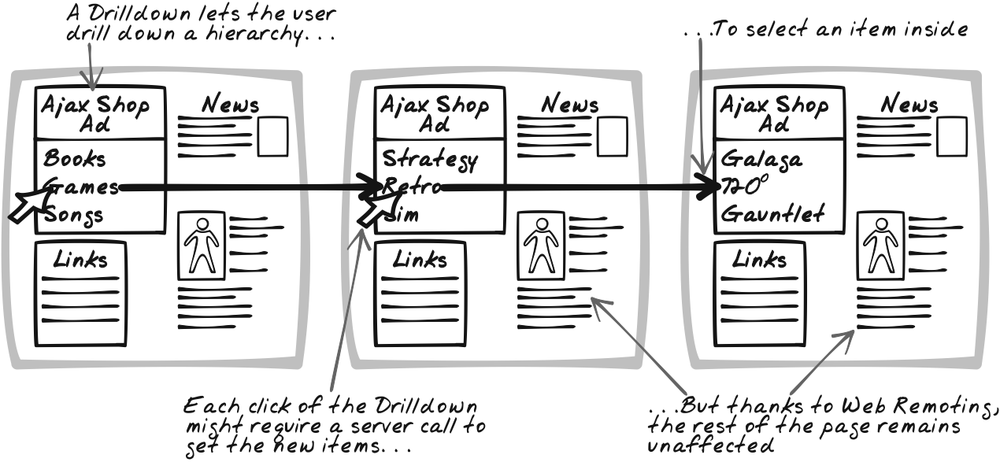
As the user drills down the hierarchy, will you show each progressive level? There are three main options (Figure 14-7):
Keep the Drilldown in a fixed area. Each time the user clicks on a category, the Drilldown morphs to show only that category. This has the benefit of preventing page rearrangement.
Show all levels at once. Each time the user clicks on a category, expand out the Drilldown region to add a new list for each category.
As a variant on the second approach, all levels are shown, but the submenus are rendered in front of the rest of the document, so the menu is effectively modal: nothing else can be done from the time the menu is opened to the time the selection is made. This approach is similar to choosing an application from the Windows Start menu.
The first two options are modeless; the third is modal. Modeless interaction works well with Ajax, where it’s possible to dynamically update, without page refresh, the menu as well as any surrounding content related to the user’s selection. Specifically:
Each navigation through the Drilldown can result in a server call to fill the next level with the latest content or even auto-generate new content.
The display throughout the application can change to reflect the state of the Drilldown, giving the user a “tour” through the hierarchy. As a user drills down from the top level to a deep category, the application is always synchronized with the current level, so the display reflects the medium-depth categories along the way. Because the interaction is modeless, the user is then free to stay on those categories.
The user can iterate between drilling down and performing other tasks. Imagine the user is a human resources clerk who needs to use a Drilldown to select an “employee of the month.” She’s already decided on the region and drills down to show all of the employees there. Now that she can see each candidate, she can go perform some research in another region of the page, or on another web site. When she returns, the Drilldown is still there, waiting to be completed.
Decisions
Will you call on the server each time the user navigates through the Drilldown?
Sometimes the entire hierarchy is loaded as a one-off event. Other times, categories can be pulled down as required using an XMLHttpRequest Call (Chapter 6). The choice is governed by two things:
How big is the hierarchy? The more items, and the more information per item, the less desirable it is to transfer and cache the data.
Is the hierarchy subject to change? In this case, you’ll need to retrieve fresh data from the server at the time a category is opened up. In a more extreme case, the server might even generate the hierarchy data on demand. For instance, an RSS feed aggregator might present a Drilldown with categories such as “sports feeds” or “politics feeds.” The contents of these will be generated at the time the user drills down to a particular feed.
Real-World Examples
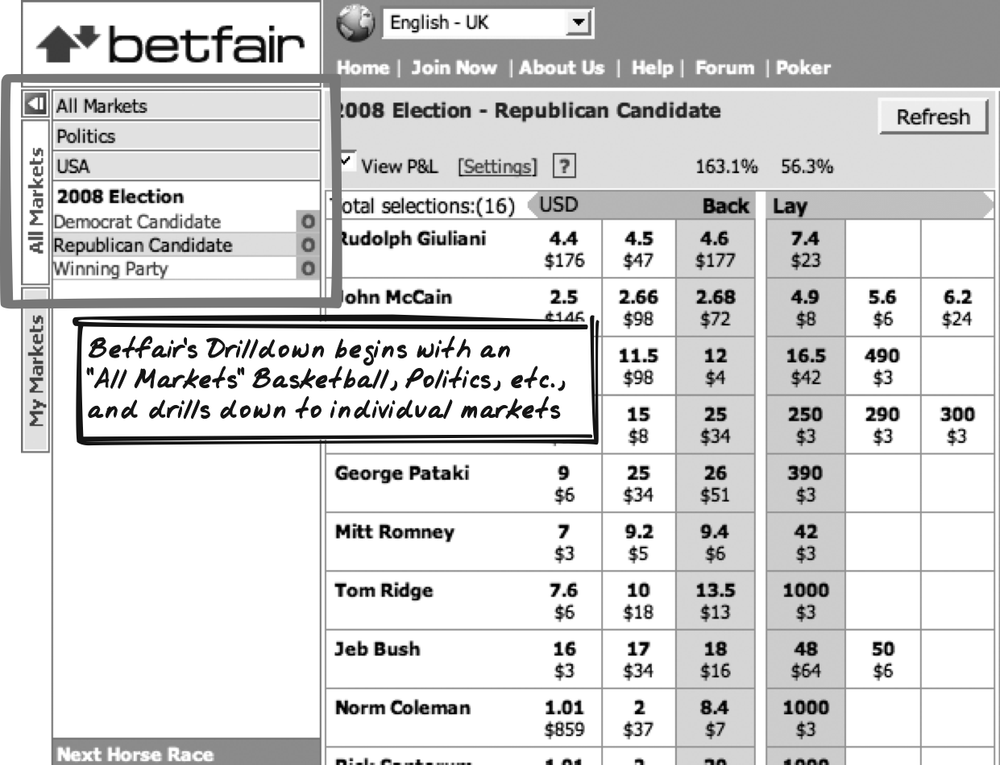
Betfair
Betfair (http://betfair.com) uses a Drilldown to locate an event you wish to bet on (Figure 14-8). At the top level, the “All Markets” Drilldown contains various categories in alphabetical order, from “American Football” to “Special Bets” to “Volleyball.” Clicking on “Special Bets” yields several countries, along with a “General” category, and you can continue to drill down to the list of bets. Clicking on one of those bets sets the main page content.
“All Markets” is one of two Drilldowns. The other is “My Markets,” a personalized Drilldown available to registered users.
Backbase portal
The Backbase portal demo (http://projects.backbase.com/RUI/portal.html) contains several independent Portlets. Of interest here is the “local directory” Portlet, which is actually a Drilldown with top-level categories such as “education” and “health” drilling down to relevant links.
OpenRico accordian widget
The OpenRico framework (http://openrico.org/rico/demos.page?demo=ricoAccordion.html) includes an accordian widget. Clicking on a category bar reveals the content. Because it lacks a deep hierarchy of categories, it’s technically not a Drilldown, but it’s a good solution when you do have a flat set of categories.
Code Refactoring: AjaxPatterns Drilldown Portal
Overview
The basic Portal Demo (http://ajaxify.com/run/portal) illustrates Multi-Stage Download (Chapter 13), showing how different content blocks can be downloaded in parallel. One of those is a block of links to Ajax resources. To keep the block small, only a few links are present. But is there any way we could keep the link block physically small while offering a large number of links? Of course there is . . . a Drilldown will occupy roughly the same space, yet with a little interaction, the user will be able to navigate through a large collection of links.
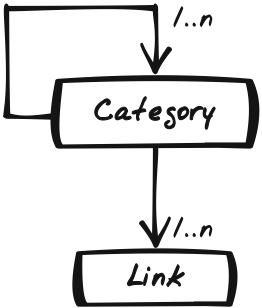
The Drilldown Portal Demo (http://ajaxify.com/run/portal/drilldown) introduces a Drilldown. A Category can contain any combination of Categories and Links (Figure 14-9). For instance: The top-level category, “All Categories,” contains only Categories, the “Websites” category contains just links, and the “Overviews” category contains some overviews as well as a subcategory, “Podcast Overviews” (Figure 14-10). Categories and links are rendered similarly, but not identically. Each category menu includes a link to the previous category level.
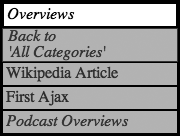
The basic interaction sequence works like this:
User clicks on a category.
A callback function detects the click and issues an
XMLHttpRequestquery on the desired category.Server responds with the new category name, its parent (null in the case of the top-level category), and each category and link in the Drilldown. All of this is in XML format.
Browser replaces existing Drilldown with a Drilldown based on the new category information.
On page load, the Drilldown is blank, and the browser requests information for the top-level category. The server response triggers the creation of a new Drilldown.
Browser-side implementation
The initial HTML just shows a blank div. The width is constrained because
the Drilldown’s parent container has a fixed width:
<div id="drilldown">Loading ...</div>
On page load, the top-level category is requested:
retrieveCategory("All Categories");Then begins the standard process of requesting a category
with XMLHttpRequest, then
rendering the menu accordingly. This occurs not only on page load,
but every time the user clicks on a category within the
drop-down.
The server returns an XML file with category data.[*] The specification contains the name, the parent name, and a list of items. Each item is either a category or a link. Note that only the information for this level of the Drilldown is provided.
<category name="Overviews" parent="All Categories">
<items>
<link>
<url>http://en.wikipedia.org/wiki/AJAX</url>
<name>Wikipedia Article</name>
</link>
<link>
<url>http://www.adaptivepath.com/publications/essays/archives/000385.php
</url>
<name>First Ajax</name>
</link>
<category name="Podcast Overviews" parent="Overviews" />
</items>
</category>The browser then parses this XML, using the standard DOM
API, to produce HTML for the Drilldown. Links are shown as
standard HTML anchor links; categories are Div elements. Event handlers ensure that
when a category is clicked, including the “Back To (previous)”
category, the browser will kick off another retrieve-and-render
cycle:
function onDrilldownResponse(xml) {
var category = xml.getElementsByTagName("category")[0];
var html="";
var categoryName = category.getAttribute("name");
html+="<div id='categoryName'>" + categoryName + "</div>";
var parent = category.getAttribute("parent");
if (parent && parent.length > 0) {
var parentName = category.getAttribute("parent");
html+="<div id='parent' onclick=\"retrieveCategory('" + parent + "')\""
+ "'>Back to <br/>'" + parent + "'</div>";
}
var items = category.getElementsByTagName("items")[0].childNodes;
for (i=0; i<items.length; i++) {
var item = items[i];
if (item.nodeName=="link") {
var name = item.getElementsByTagName("name")[0].firstChild.nodeValue;
var url = item.getElementsByTagName("url")[0].firstChild.nodeValue;
html+="<div class='link'><a href='" + url + "'>" + name + "</a>
</div>";
} else if (item.nodeName=="category") {
var name = item.getAttribute("name");
html+="<div class='category' "
+ "onclick='retrieveCategory(\""+name+"\")'>"+name+"
</div>";
}
}
$("drilldown").innerHTML = html;
}Server-Side Implementation
The server-side implementation relies on the Composite
pattern (see Gamma et al., 1995). A Category consists of further Category objects
and also of Link objects. We rely on Category and Link having two common
operations:
- asXMLTag( )
Renders the item as an XML tag. For categories, there is a special optional parameter that determines whether or not the tag will include all items.
- findItems($name)
Recursively finds an item—either a
Categoryor aLink—having the specified name.
With these operations encapsulated in the Category and Link objects, the main script is quite
small:
require_once("Link.php");
require_once("Category.php");
require_once("categoryData.php");
header("Content-type: text/xml");
$categoryName = $_GET['categoryName'];
$category = $topCategory->findItem($categoryName);
if ($category) {
echo $category->asXMLTag(true);
} else {
echo "No category called '$categoryName'";
}Further refactoring: a Drilldown with dynamic content
In the refactoring above, the top-level category,
and all of the data underneath it, is hardcoded in categoryData.php. In fact, the hierarchy
data could easily be generated on demand to create a Drilldown
with dynamic content. In a further refactoring (http://ajaxify.com/run/portal/drilldown/syncLinks),
a Cross-Domain Proxy (Chapter 10)
is introduced to grab the actual results from the AjaxPatterns
Wiki Links Page (http://ajaxpatterns.org/Ajax_Links). It’s
not a true Cross-Domain Proxy because instead of grabbing the
results in real-time, a process runs to pull them every sixty
seconds and store them locally, where they can be picked up by the
Drilldown script.
Alternatives
Live Search
Drilldown lets the user locate an item by browsing through a hierarchy. Live Search (see later) instead lets you locate an item by typing, and the data need not be hierarchical.
Tree
Like a Drilldown, a Tree widget lets the user navigate a hierarchy, just like the tree of files and folders in desktop file managers. Tree widgets, even if they expand and collapse, tend to take up more space than Drilldowns, but the more detailed view can be useful for longer, more complex, tasks.
Related Patterns
Microlink
Content blocks, produced when particular categories or items are selected can be associated with the Drilldown. Thus, the Drilldown contents are being used as Microlinks (Chapter 15).
Browser-Side Cache
If each navigation event leads to a query of the server, consider retaining results in a Browser-Side Cache (Chapter 13).
Portlet
A Drilldown is usually a form of Portlet (Chapter 15). It has its own state, and the user can usually conduct a conversation with the Drilldown in isolation.
Data Grid
⊙ Database, Query, Report, Summary, Table
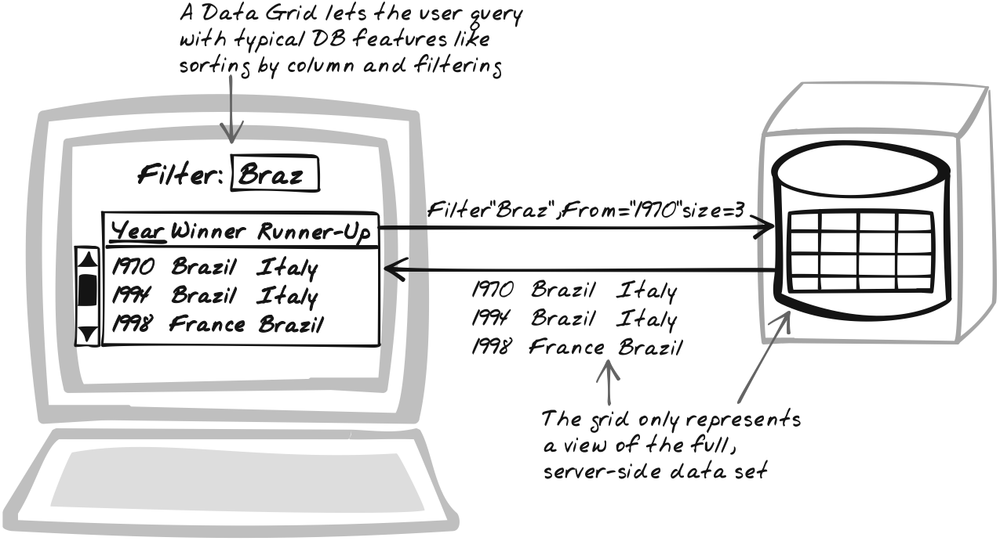
Goal Story
Reta is doing a little data mining on this season’s sales figures. She’s scrolling through a table showing a row for every transaction. Noticing that higher sales figures tend to come in the morning, she sorts the table by sales figure. There’s too much data there, so she filters out any transactions below $1,000, then groups the transactions by time of day.
Problem
How can you help users explore data?
Forces
Ajax Apps have their own databases, as well as access to external systems.
Users need a way to explore all this data, in order to verify it, understand how it works, predict future trends, and so on.
You can’t anticipate what users will need to do with data.
Solution
Report on some data in a rich table and support common querying functions. A Data Grid has the familiar database client interface: a table with a row for each result and a column for each property. Think of it as a traditional table on steroids. Typical database client functionality is as follows (and it’s feasible to achieve each of these in an Ajax interface):
- Sorting
Each column can be usually be sorted by clicking on the header. To let the user sort by more than one category, use a sorting algorithm that preserves the order of equal values. Then, users can click on one header followed by the other.
- Filtering
The user can filter in to retain data matching certain criteria, or filter out to exclude that data.
- Grouping
Data can be grouped by similarity. A large table is essentially broken into smaller tables, in which each item in a smaller table is similar to the other items in that table.
- Aggregate calculations
Calculations can be performed across the whole table—for example, a sum or average for a column, or a sum of the products of two columns in each row.
- Editing
Some Data Grids allow fields to be edited.
With the magic of Web Remoting (Chapter 6), the grid can become a Virtual Workspace (Chapter 15, giving the illusion of holding a massive set of data. In reality, the data lives on the server, and each User Action leads to a new server call. Most queries lead to a structured response, such as an XML Message or a JSON Message, containing a list of results for JavaScript rendering, or alternatively an HTML Message with the specific view the user will see. The semantic style has the advantage of encouraging performance optimizations such as Predictive Fetch, which are essential if you want the grid to feel responsive.
Decisions
Will the Grid be Read-Only or Mutable?
Editing a table directly can be more productive for experts, though it’s often more difficult for novices than editing a single record in a form, since a form usually has a more verbose interface. Grid mutability adds a couple of extra considerations:
You need to validate the data. In a live context, this might mean showing a Progress Indicator during validation, then Highlighting invalid columns.
Cells should ideally morph into input widgets when a user begins editing them. For instance, create a drop-down when the user begins to change a constrained field.
Real-World Examples
OpenRico Data Grid example
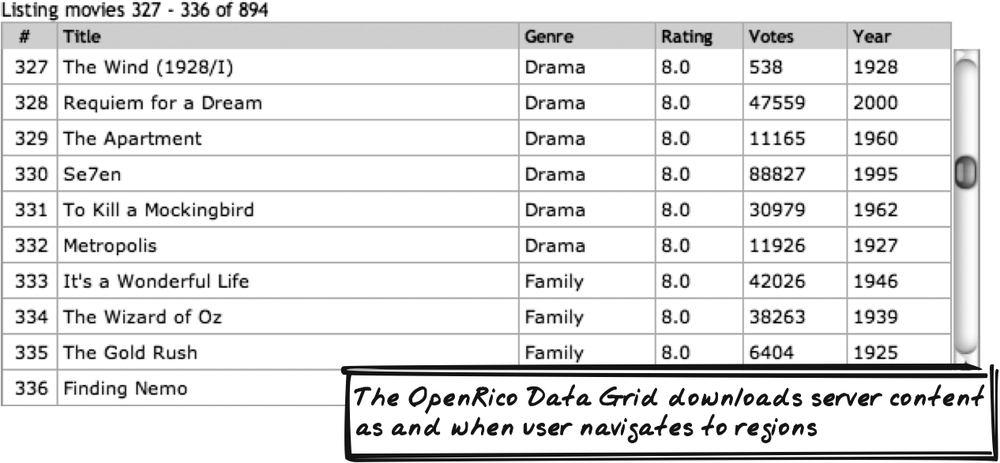
The OpenRico Data Grid example (http://openrico.org/rico/livegrid.page) shows a list of movies, each with several fields: ranking, title, genre, rating, votes, and year (Figure 14-12). You can scroll down the list and sort each column header. You can also bookmark a position in the table (an example of Unique URLs).
NumSum
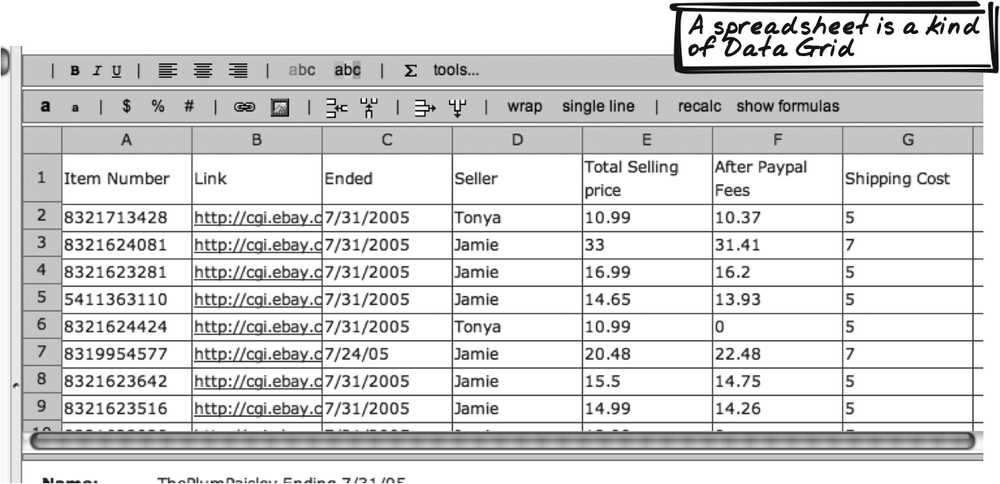
NumSum (http://NumSum.com) is a spreadsheet, and spreadsheets are a special, powerful case of Data Grids; they are to Data Grids what Data Grids are to conventional tables (Figure 14-13).
Oddpost
Oddpost (http://oddpost.com/learnmore) is an Ajax mail client with a very similar look and feel to desktop clients like Outlook. The subject headers table is a form of Query-Report Table. As with the OpenRico example, you can scroll through the table and sort by column.
Delta Vacations
Delta Vacations (http://www.deltavacations.com/destination.aspx?code=MONTEGOBAY) appears as a Live Search example, but it also serves as an example of filtering. Initially, all hotels in a destination are shown, and typing a search term retains only matching results.
Code Example: OpenRico Data Grid
The OpenRico Data Grid example (http://openrico.org/rico/livegrid.page) uses OpenRico’s LiveGrid API. In the initial HTML, there are two tables: one for the column headers and one for the data. Note that the data table declares all the visible table rows, initialized with the values in the first few rows. This is an example of a Virtual Workspace (Chapter 15)—the rows will always stay fixed, but their data will change as scrolling occurs:
<table id="data_grid_header" class="fixedTable" cellspacing="0" cellpadding=
"0" style="width:560px">
<tr>
<th class="first tableCellHeader" style="width:30px;text-align:center">
#</th>
<th class="tableCellHeader" style="width:280px">Title</th>
<th class="tableCellHeader" style="width:80px">Genre</th>
<th class="tableCellHeader" style="width:50px">Rating</th>
<th class="tableCellHeader" style="width:60px">Votes</th>
<th class="tableCellHeader" style="width:60px">Year</th>
</tr>
</table>
<table id="data_grid" class="fixedTable" cellspacing="0"
cellpadding="0" style="width:560px; border-left:1px solid #ababab">
<tr>
<td class="cell" style="width:30px;text-align:center">1</td>
<td class="cell" style="width:280px"> Bend of the River</td>
<td class="cell" style="width:80px">Western</td>
<td class="cell" style="width:50px">7.3</td>
<td class="cell" style="width:60px">664</td>
<td class="cell" style="width:60px">1952</td>
</tr>
...
</table>The grid is initialized on page load, with some configurable options passed in:
var opts = { prefetchBuffer: true, onscroll: updateHeader };
onloads.push( function( ) {
tu = new Rico.LiveGrid(
'data_grid', 10, 950, 'getMovieTableContent.do', opts )}
);The grid will then handle all user events. Notice the getMovieTableContent.do argument in its
construction. That’s the URL that will feed the grid with further
data. It must be capable of accepting in certain parameters, such as
initial position and number of rows to retain. For example, to load
the page initially and scroll all the way to the end (rows 940 and
on), the XMLHttpRequest Call (Chapter 6) goes to the following URL:
getMovieTableContent.do?id=data_grid&page_size=10&offset=940&_=.
What’s retrieved are 10 movies starting at 941 in an XHTML format,
as shown in the following example. The grid component then updates
itself with those rows.
<?xml version="1.0" encoding="ISO-8859-1"?>
<ajax-response>
<response type="object" id='data_grid_updater'>
<rows update_ui='null' >
<tr>
<td>941</td>
<td convert_spaces="true"> El Dorado</td>
<td> <span style="font-weight:bold"> Western </span> </td>
<td>7.4</td>
<td>2421</td>
<td>1966</td>
</tr>
...
</rows>
</response>
</ajax-response>Related Patterns
Virtual Workspace
As explained earlier in the "Solution,” Data Grids are usually Virtual Workspaces (Chapter 15).
Predictive Fetch
To improve performance, consider Predictive Fetches (Chapter 13) that preload nearby results and aggregation functions.
Metaphor
A Data Grid is the natural sequel to the traditional HTML table.
Acknowledgments
Christian Romney (http://www.xml-blog.com/) suggested the idea of a sort-and-filter pattern from which this pattern evolved, and also pointed out the Delta Vacations example.
Rich Text Editor
⊙⊙⊙ Editor, Formatting, Fonts, Rich, Text, Textarea, Toolbar, Write, WordProcessor, WYSIWYG

Goal Story
Pam is working on a presentation for the steering committee; style will count here. From the toolbar, she sets the font to Arial, the size to 24 pt, and switches italics on. She then types out the heading, selects it, and moves to the toolbar again to set the color scheme.
Forces
Many Ajax Apps let users create and edit substantial chunks of content.
Rich content for the Web needs to make the most of HTML and go well beyond a string of plain-text.
Most users don’t know HTML; even “easy” markup substitutes for HTML are complicated and inconsistent.
Solution
Incorporate a Rich Text Editor widget
with easy formatting and WYSIWYG[*] display. Typically, the widget looks like a
mini word processor: a toolbar on top with a rich editing area
underneath. The editing area is usually a div rather than a textarea, meaning that any HTML content is
possible.
Typical features include:
Flexible font styles, sizes, boldfacing, etc.
Flexible color schemes
Embedded images
Embedded tables
Bullet-point and numeric lists
Indenting and flexible text alignment
All of these features are usually accessible by the toolbar, as well as via keyboard shortcuts. It would also be possible to make them available from drop-down menus, though the main examples to date have avoided doing so. In addition, the toolbar sometimes offers other operations too:
Undo, Redo
Cut, Paste, Copy
Save (Explicit Submission [Chapter 10])
Spellcheck
Rich Text Editors are a great tool for nontechnical users, but as with GUI word processors, they can slow down power users. If power users are important to you, a few guidelines apply:
Offer an alternative “WYSIWYN” (What You See Is What You Need) interface, where the user can enter raw HTML and/or some other text-based markup such as Markdown (http://daringfireball.net/projects/markdown/).
Offer keyboard shortcuts and advertise them well, e.g., as tooltip Popups (Chapter 15) on the corresponding toolbar icons.
Offer personalized toolbars and keyboard bindings.
The major browsers do have some support for rich text editing.
Firefox has Midas (http://kb.mozillazine.org/Firefox_:_Midas),
an embedded text editor, and IE (http://msdn.microsoft.com/workshop/author/dhtml/reference/properties/contenteditable.asp)
has a similar editor available on items flagged as contentEditable. However, neither
mechanism is portable, and with both versions, you’re stuck with
whatever version the user’s browser has. For that reason, the best
solution right now is probably the Cross-Browser
Component (Chapter 12)
libraries mentioned in the following "Real-World Examples.”
Real-World Examples
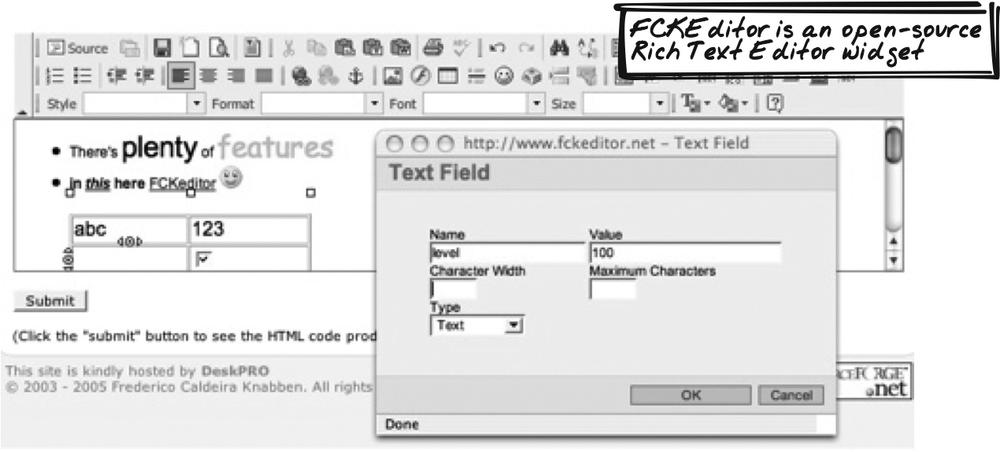
FCKEditor library
Frederico Caldeira Knabben’s FCKEditor (http://www.fckeditor.net/) is a feature-rich, open source Cross-Browser Component you can pull into your own projects (Figure 14-15). It also has some server-side integration and web remoting support.
Jotspot, Dojo Rich Text Editor
Jotspot is a wiki host that allows editing in three
formats: WYSIWYG, markup, or XML (i.e., the underlying XHTML). The
WYSIWYG supports all the Rich Text Editor capabilities mentioned
in the previous Solution, and is based on the open source Dojo
Rich Text Editor component (http://dojotoolkit.org/docs/rich_text.html).
(See Figure 14-16.) In
the simplest case, using the component is as simple as declaring a
div with the right
class.
<div class="dojo-Editor"> Initial
content </div>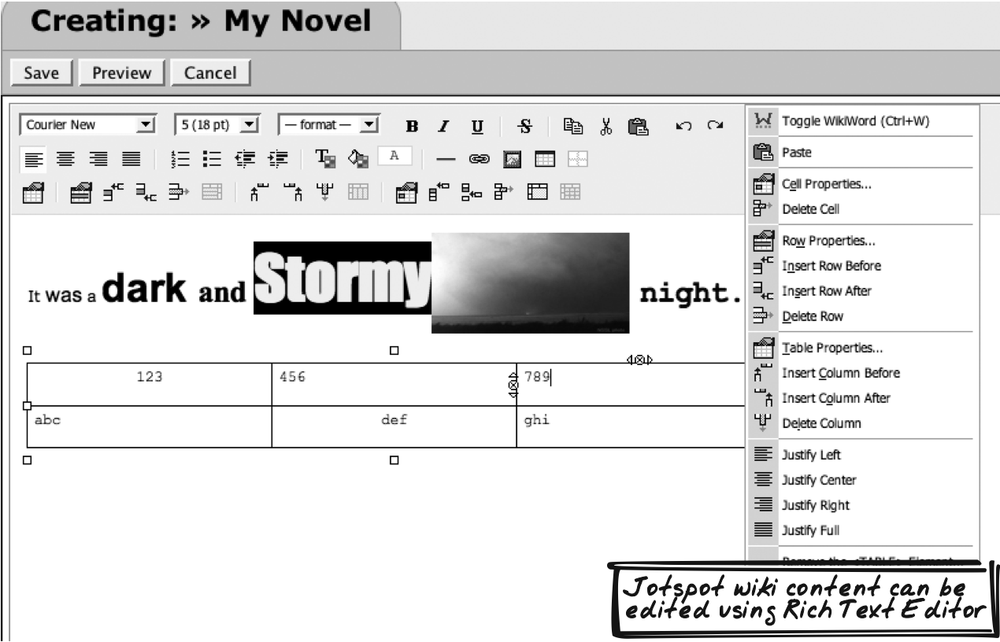
Writely
Writely (http://writely.com) promotes itself as “The Web Word Processor.” It edits content using a mechanism similar to that used by Jotspot. One nice feature is a spell-check.
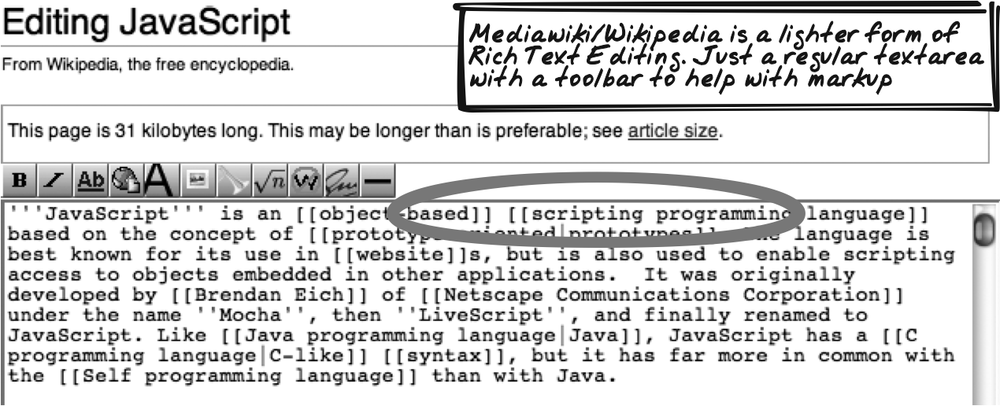
Wikipedia
Wikipedia’s (http://Wikipedia.org) editing interface is characteristic of slightly older editors that offer a rich editing toolbar but only a markup-based textarea mechanism for the content (Figure 14-17). This is also true of the open source MediaWiki framework (http://mediawiki.org) on which Wikipedia is based.
Rich Text Editor
Kevin Roth’s Rich Text Editor (http://www.kevinroth.com/rte/demo.htm) is a good demo of the native browser support mentioned in the preceding "Solution" because it provides an editor built on top of whichever browser it’s running in.
Code Example: FCKEditor
This example introduces the FCKEditor API and looks at some of the internals. To use FCKEditor in your own project, first create a regular textarea:
<textarea id="comments"></textarea>
FCKEditor can then replace the text editor with a rich editor:
var commentsEditor = new FCKeditor("comments");
commentsEditor.ReplaceTextarea(
);To track usage, register an initialization handler for the global FCKEditor module, which applies to all editor instances. Here you probably want to set up an event handler that will fire when a user changes an individual editor. See the API documentation (http://wiki.fckeditor.net/) for more details and options.
function FCKeditor_OnComplete(editor) {
editor.Events.AttachEvent('OnSelectionChange', onEditorChange);
}
function onEditorChange(editor) {
// Respond to change.
// You can get the editor contents with editor.GetXHTML( );
}Now the internals. ReplaceTextarea will locate the textarea
object, hide it, then insert the Rich Text Editor content just above
it.
FCKeditor.prototype.ReplaceTextarea = function( )
...
var oTextarea = document.getElementById( this.InstanceName ) ;
oTextarea.style.display = 'none' ;
...
this._InsertHtmlBefore( this._GetIFrameHtml( ), oTextarea ) ;_GetIFrameHtml( ) outputs
the HTML for the editor IFrame, and its source is fckeditor.html. The editor is structured
as a three-row table. The top row is the toolbar (and some other
controls for expanding and collapsing it); the second row is the
WYWIWYG editing area, backed by an IFrame; the third row shows the HTML
source, which is usually invisible.
<table height="100%" width="100%" cellpadding="0" cellspacing="0"
border="0" style="TABLE-LAYOUT: fixed">
<tr>
...
<td id="eToolbar" class="TB_ToolbarSet" unselectable="on"></td>
...
</tr>
<tr id="eWysiwyg">
<td id="eWysiwygCell" height="100%" valign="top">
<iframe id="eEditorArea" name="eEditorArea" height="100%" width="100%"
frameborder="no" src="fckblank.html"></iframe>
</td>
</tr>
<tr id="eSource" style="DISPLAY: none">
<td class="Source" height="100%" valign="top">
<textarea id="eSourceField" dir="ltr" style="WIDTH: 100%; HEIGHT: 100%">
</textarea>
</td>
</tr>
</table>The toolbar consists of toolbar buttons linked to commands. The commands follow the Command pattern (Gamma et al., 1995)—they are objects encapsulating a command and can be launched from the toolbar or with a keyboard shortcut. The command is identified in each toolbar button declaration as well as several display properties.
var FCKToolbarButton = function (commandName, label, tooltip, style, sourceView, contextSensitive)
For example, here’s the toolbar button to paste plain-text:
oItem = new FCKToolbarButton('PasteText',
FCKLang.PasteText, null, null, false, true);The PasteText command in
the preceding example is ultimately tied to a Command object that will launch a Paste
Text dialog.
FCK.PasteAsPlainText=function( ) {
FCKDialog.OpenDialog('FCKDialog_Paste',FCKLang.PasteAsText,
'dialog/fck_paste.html',400,330,'PlainText'); }Manipulations of the WYSIWYG editor content involve getting
hold of the content element and simply altering its HTML. In the
case of the Paste operation, it appends the new HTML, sHtml, at the right place.
var oEditor = window.parent.InnerDialogLoaded( ) ; ... oEditor.FCK.InsertHtml(sHtml) ;
Related Patterns
Virtual Workspace
For editing large chunks of text, you might want to experiment with a Virtual Workspace (Chapter 15).
Progress Indicator
Provide a Progress Indicator (see earlier) while saving text. Indeed, many text editors take a while to start up as well, partly due to scripting overhead and partly due to toolbar images. Thus, a Progress Indicator might help during loading as well.
Status Area
Create a Status Area (Chapter 15) to help the user monitor details such as word count and cursor position, if these aren’t already provided by the Rich Text Editor widget. You’ll need to hook into the widget’s event model to keep the status up-to-date.
Metaphor
A Rich Text Editor is like an embedded GUI word processor.
Suggestion
⊙⊙ Auto-Complete, Fill, Intelligent, Populate, Predict, Suggest, Wizard
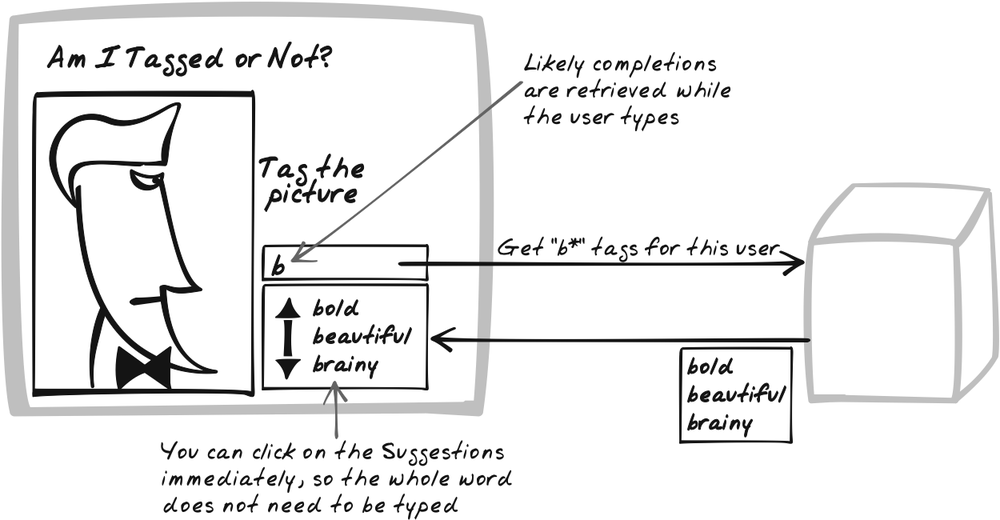
Goal Story
Doc is typing out an electronic prescription. He intends to prescribe “Vancomycin 65 mg,” but as soon as he types in “V”, the system has already detected a handful of likely choices, based on the patient’s history and Doc’s prescription style. Doc selects “Vancomycin 65 mg” from the list and proceeds to the next field.
Problem
How can you improve throughput?
Forces
Free text remains the most powerful way for humans to communicate with computers. The trend seems to be toward more typing than ever before due to instant messaging, blogging, and email. Even search engines are undergoing a transformation to become general-purpose, as described in Live Command-Line later in this chapter.
When presented with a free text area, people don’t always know what they’re meant to type in.
Though many users are now quick on the keyboard, there are still many users for whom the Web is a click-mostly experience.
Typing speed remains a bottleneck even for fast typists, most of whom think faster than they can type.
People make mistakes when they type.
Solution
Suggest words or phrases that are likely to complete what the user is typing. The user can then select the Suggestion and avoid typing it in full. The results usually come from an XMLHttpRequest Call (Chapter 6)—the partial input is uploaded and the server responds with a collection of likely matches.
Suggestion has its roots in “combo boxes”—fields on traditional GUI forms that combine a text input with a drop-down list. The elements are kept synchronized. The user is free to type any text, and the current selection in the list will track what’s been typed so far. The user is also free to choose an element from the list, which will then be posted back to the text field. In some cases, the list constrains what the user types; in other cases, it’s there to provide Suggestions only.
It’s the latter style that has become popular in recent years—free text entry, with some Suggestions for completion at any time. Auto-completion became popular with Internet Explorer 5, which auto-completed fields based on user history. Most users are comfortable with the approach, as all the modern browsers offer a similar feature, and the technique is also popular in mobile phone text messaging and East Asian text entry.
In an Ajaxian context, Google set the standard with its introduction of Google Suggest (http://www.google.com/webhp?complete=1), which suggests the most popular terms to complete the user’s search query. Its release surprised many, as Google had managed to completely replicate conventional combo-box behavior, but this time, the terms were dynamically fetched from the server instead of being present when the form was created.
The mechanics of a Suggestion usually work like this:
A standard
inputfield is used. At the same time, an initially invisibledivelement is created to contain the Suggestions as they appear. Theinputfield needs an event handler to monitor the text it contains so as to ensure that the list always highlights whichever Suggestion matches.Instead of requesting a Suggestion upon each keypress, Submission Throttling is usually adopted. Thus, every 100 milliseconds or so, the browser checks whether anything has changed since the last request. If so, the server is passed the partial query as a GET-based XMLHttpRequest Call.
The server then uses some algorithm to produce an ordered list of Suggestions.
Back in the browser, the callback function picks up the Suggestions and does some Display Morphing (Chapter 5) to show them to the user in a format that allows them to be selected. Each entry will have an event handler, so that if the entry is clicked, the
inputfield will be altered.
A combo-box is not the only way to render results, but it has the dual virtues of efficiency and familiarity. "Code Example: Kayak,” later in this section, covers Kayak’s implementation.
You might think the main benefit of a Suggestion is to cut down on typing, but that’s not the case. If anything, it’s often slower to enter a single word using Suggestion, as it’s a distraction and probably requires some mousing. The main benefit is to offer a constrained set of choices—when there are more choices than would fit in a standard option list, but still a fixed set. For Google Suggest, it’s a list of choices that are considered probable based on search history. In tagging web sites, it’s a list of tag names that have been used in the past. In travel web sites, it’s a list of airports you can include on your ticket.
Decisions
What algorithm will be used to produce the Suggestions?
Ultimately, the Suggestion algorithm needs to find the most likely completions.
In general, historical data is the best predictor. Log what users commonly search for and use that as a basis for Suggestions. So when the user types “A,” suggest the most frequent responses beginning with “A.”
Personalize. Instead of completing “A” with the most common “A"-query all users have entered, return the most common “A"-queries for this user. The only problem here is lack of data, so consider a collaborative filtering algorithm to provide Suggestions based on similar users.
Recent history is a more pertinent guide, whether you’re personalizing the results or not. In some cases, it makes sense to provide only recent queries. In other cases, consider weighting recent results more heavily, but taking into account older queries as well.
In some cases, it might make more sense for the browser to provide Guesstimates (Chapter 13) rather than real results from the server in real-time. This information might be based on what’s in a Browser-Side Cache (Chapter 13) and, potentially, on a few algorithms to help the browser decide what’s relevant.
How will the Suggestions be ordered?
Typical ordering algorithms include:
Estimated likelihood, e.g., historical frequency.
How recently the query was last used.
Alphabetical or numerical order.
Application-specific ordering. A currency list often begins with the U.S. Dollar, for instance.
However you order your Suggestions, the first item is particularly important because it can be designed to enable the user to select the first element without explicitly choosing it from the list. For example, Google’s combo-box implementation automatically inserts the first element in the text field, though with a text selection over the completion text so the user can easily override it.
How many Suggestions will be shown?
Deciding how many Suggestions to show is a balancing act. You want to show enough Suggestions to be useful, but not so many that the good ones get lost in the crowd. Space is limited as well, even if you use a pop-up list.
It’s generally useful if your Suggestion algorithm not only ranks Suggestions, but also makes a relevance estimate. Then, you can ensure Suggestions are shown only if they are particularly useful. Sometimes it isn’t really worth it to show any Suggestions.
What auxiliary information will be present with each Suggestion?
The core part of the Suggestion is always a word or phrase that completes what the user is typing. You can augment each Suggestion with supportive information. Google Suggest, for example, shows how many results each completion has. It would even be possible to present the Suggestions in a table, with several columns of background information per completion. Taken to an extreme, the Suggestion resembles a Live Search (see later in this chapter).
Real-World Examples
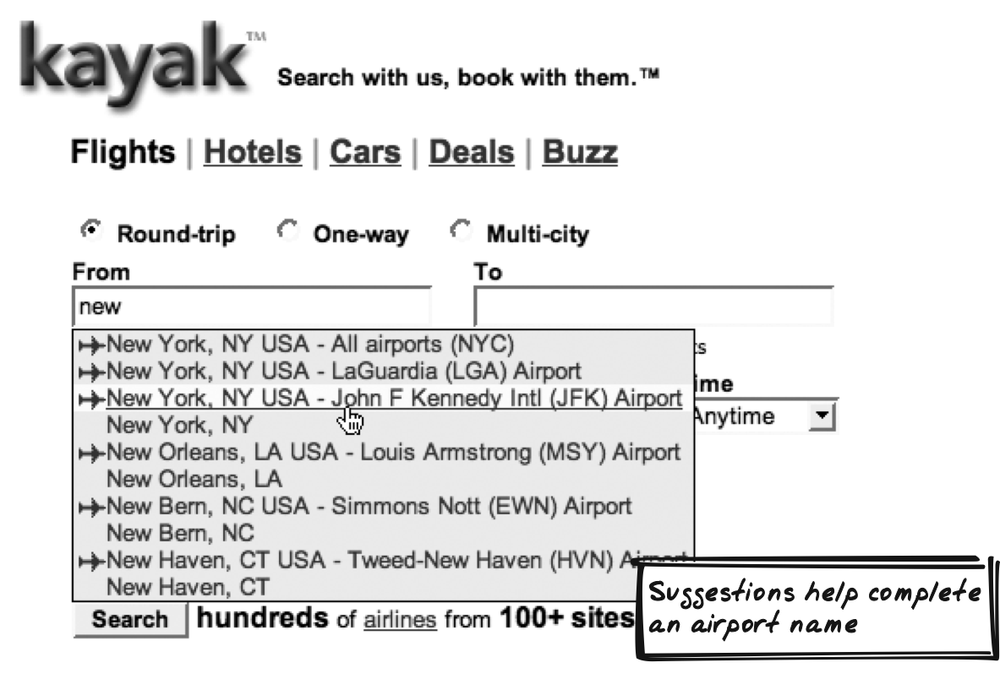
Kayak
Kayak (http://kayak.com) is a travel search engine that suggests airports as you type in a location (Figure 14-19). The Suggestions appear in a combo-box format similar to Google Suggest.
Google Suggest
Google Suggest (http://www.google.com/webhp?complete=1)
was probably the first public usage of Suggestion and remains an
excellent example. Results are shown in a combo-box style. The
combo-box appearance is achieved with a custom control. A div is placed just under the text input,
with a Suggestion on each row, and the zIndex property is used to make the
div appear “in front of” the
usual page content.
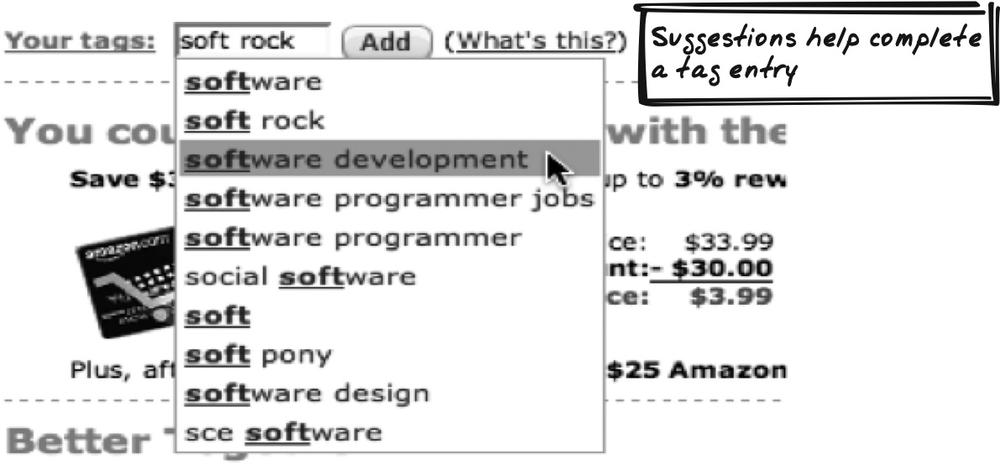
Delicious, Amazon
Delicious (http://del.icio.us) and Amazon (http://amazon.com) both offer Suggestions to help complete tags (Figure 14-20). As you type a tag, several Suggestions appear immediately and are populated below the field. You can click on a Suggestion to complete the term.
Code Example: Kayak
Kayak (http://kayak.com) is a slick, Ajaxian
interface with a handy Suggestion feature for source and destination
airports. The list of Suggestions appears below the input field, is
referred to in the code as a smartBox, and exists as long as the input
field has focus.
Whenever a key is pressed, the smartBox is aborted—which stops any pending request—and a new
request is initiated. A check is made to ensure that the text entry
actually contains something, otherwise the smartBox is closed:
function _typer(input)
{
if ((_input != null ) && _input.value.length > 0)
{abortSmartBox( );_runSearch(input);
}
else {_setValue(-1);closeSmartBox( );}
}_runSearch( ) kicks off a
call to the server to receive the Suggestion list. The query goes to
http://www.kayak.com/m/smarty.jsp?where=LOCATION.
The result is some XML containing the airport names and codes and
what appears to be an ID number, for example:
<i>28501</i><m>L</m><d>London, United Kingdom</d> <a>LON</a>
The callback function accumulates an HTML string to be
inserted into the smartbox. A loop runs over each result, appending
a div element to the HTML:
var html = ""; var list = "";
for (var j = 0; j < ii.length; j++) {
var id=client.getTagText(results[0], "i", j);
var str=client.getTagText(results[0], "d", j);
var match=client.getTagText(results[0], "m", j);
...
list += _divB + _spanB + icon + str + _spanE + _divE;cnt++;
}Also of interest is the optional icon, which appears beside the airport name, as shown in the preceding code. Depending on the resulting XML, the icon is chosen from one of two images:
var _iconAir = "<img style='vertical-align: middle' src='/images/airport_icon.gif' border= '0'>"; var _iconLoc = "<img style='vertical-align: middle; visibility: hidden' src= '/images/place_icon.gif' border='0'>"; ... icon = (match == "L") ? _iconLoc : _iconAir;
An event handler monitors key presses. As the user moves up and down, the airport text is changed according to the selection, and the selection is incremented or decremented:
case UP:
_cursel--;if (_cursel<0){_cursel=0;}selChoice(_cursel);
...
case DOWN:
_cursel++;if (_cursel>=_ids.length){_cursel=_ids.length-1;}selChoice(_cursel);Finally, the value is set when the user clicks tab or enter. In the former case, focus will also
proceed to the next field:
case ENTER:
if (_ids.length>0){
_setValue(_cursel);
closeSmartBox( );
}
...
case TAB:
if (_cursel>=0&&_cursel<_ids.length){_setValue(_cursel);}Alternatives
Selector
In some cases, a plain old HTML selection input will suffice. Most
modern browsers support navigation through the drop-down with a
keyboard, so it’s an easy, viable alternative if the range of
inputs is constrained.
Related Patterns
Guesstimate
Sometimes the browser may be smart enough to derive Suggestions without resorting to the server. This is an application of Guesstimate (Chapter 13).
Predictive Fetch
Suggestion is similar to Predictive Fetch (Chapter 13). Predictive Fetch queries the server in anticipation of a future user action, whereas Suggestion queries the server to help the user complete the current action. In theory, you could actually combine the two patterns—perform a Predictive Fetch to pull down some Suggestions that might be needed in the future. On an intranet, for instance, it might be practical to continuously make 26 parallel queries in anticipation of the user, who might type any letter of the alphabet.
Submission Throttling
To cut down on queries, don’t issue an XMLHttpRequest Call upon every keypress. Instead, apply Submission Throttling (Chapter 10) to cap calls to a maximum frequency.
Highlight
When one of the Suggestions in the list matches the free text input, it’s usually a good idea to Highlight (Chapter 16) it.
Lazy Registration
Lazy Registration (Chapter 17) involves the accumulation of profile information, and profiles can be used to generate personalized Suggestions. You can also retain user preferences regarding the appearance and timing of Suggestion lists.
Live Search
When full result details are provided, Suggestion resembles a Live Search (see the next pattern). However, the design goals are different and this should usually be reflected in the user interface. A Suggestion is intended to complete a word or phrase; a Live Search is intended to locate or report on an item being searched.
Want to Know More?
“How Search Engines Rank Web Pages” by Danny Sullivan (http://searchenginewatch.com/webmasters/article.php/2167961)
“Google Suggest Dissected” by Chris Justus (http://serversideguy.blogspot.com/2004/12/google-suggest-dissected.html)
Acknowledgments
Chris Justus’s thorough analysis of Google Suggest (http://serversideguy.blogspot.com/2004/12/google-suggest-dissected.html) was very helpful in explaining the magic behind Google’s Suggestion implementation.
Live Search
⊙⊙ Feedback, Immediate, Live, Real-Time, Search
Goal Story
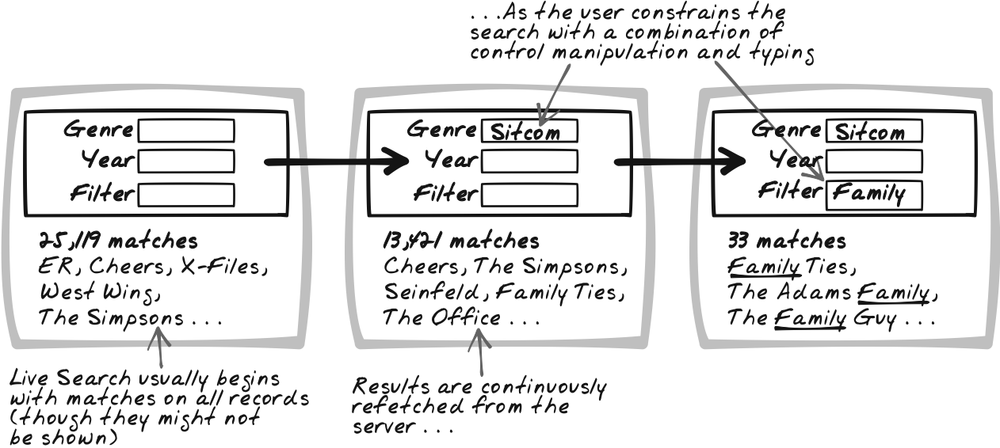
Browsing a trade magazine, Reta has just spotted the “Curiously Costly” line of shoes and declared them a “must-have” for the upcoming season. She heads over to her favorite wholesaler’s web site and sees an empty search form with an assortment of products underneath it and the message, “50,000+ items.” First, she selects “shoes” from a drop-down and watches as the products below morph into a collection of shoes; the message is now “8,000+ shoes.” Then, she begins typing. As she types “C,” she now sees all 500 shoes beginning with “C.” This continues until the search field contains “Curio,” at which point only three items remain. One of those is “Curiously Costly,” which is what Reta clicks on to successfully conclude the search.
Problem
How can users quickly search for an item?
Forces
Ajax Apps often require a search capability. Users search for business objects, other users, web sites, and more.
Sometimes the user is searching for a needle in a very large haystack. In the case of search engines, a haystack of over a billion items.
To help deal with the complexity, users should be free to experiment.
Solution
As the user constructs and refines his search query, continuously show all valid results. The search query is a combination of controls that lets the user narrow down the collection of items. It may be a straightforward text field, or a complex arrangement of Sliders (see earlier in this chapter), radiobuttons, and other controls. The results appear in a separate region and are continuously synchronized with the query that’s been specified. The search concludes when a result is chosen.
There are several benefits to using Live Search instead of the conventional style:
Browsing and searching can be combined.
Searching proceeds more quickly because no explicit submission is required. The results are ready almost immediately, so the user can experiment more easily.
There’s no page reload, so the interaction feels smoother; results are updated, but the input query is completely unaffected.
The most common form of Live Search right now closely mirrors traditional searching. The user types into a free-text search field, and results are frequently updated as the user types. So, searching for “cataclysmic,” the user will see results for “c,” “ca,” and so on. (With Submission Throttling (Chapter 10) in place, the sequence might skip a bit, so a fast typist would see results “c,” “cata,” etc.)
Search and browse have often been considered mutually exclusive on the Web, which is unfortunate because both have their benefits. Search is good for finding something you already know about, while browse is good for exploring all of the items and stumbling across things you didn’t know about. Live Search provides a way to combine the two. Some controls—such as selectors, radiobuttons, and Sliders—let the user choose an item from a small collection. If the search form can change dynamically (see Live Form later in this chapter), you can support browsing through a hierarchical structure.
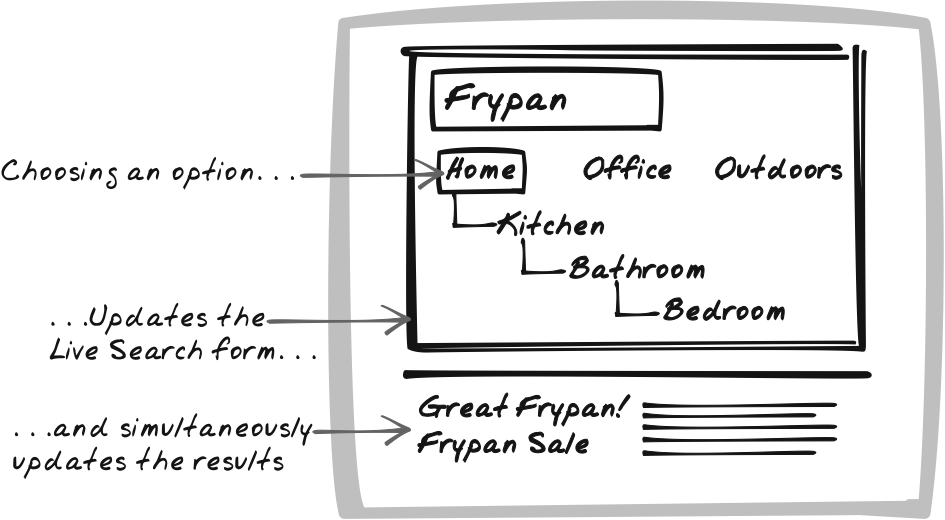
Imagine how a web site search engine might achieve this. The initial control is just an empty text box and a selector with ten categories—Arts, Tech, News, and so on (Figure 14-22). The user chooses News on the selector and a new selector appears—World, Business, Science, etc. At any point, the user can change any selector. All the while, the results below are updating to show a sampling of results in the most specific category that’s been specified. Furthermore, the text input is there all along, acting as an additional filter. So if you search at the top level, the interface degenerates into a standard live text search. But if you search while the selectors are set to a category, only the matching results from that category will be shown.
Live Search makes use of event handlers on the input controls, which listen for user activity and update the results. A typical sequence works like this:
The user changes a control; e.g., types a new character or clicks a radio button.
The entire input query—all of the input fields’ settings—is transmitted to the server in an XMLHttpRequest Call.
The server decides which—if any—results should be shown and returns the list.
The browser replaces the list of results with this new list.
In the preceding scenario, the XMLHttpRequest Call need not occur in direct response to the user input. Often, Submission Throttling is used to delay the response.
A weaker form of Live Search doesn’t show the actual results, but hints at them, e.g., indicating how many results and what type of results. The benefits to this are that there are less processing, improved caching opportunities (because there’s much less to store), and no space required for results while the search is occurring.
Live Search is not always desirable. Showing intermediate results, which happens when the search involves typing, can be distracting (http://looksgoodworkswell.blogspot.com/2005/12/distracting-or-narrowing-looking.html) and is not very useful anyway. If the user is searching for “cataclysmic,” does she really care about the results for “cat”? An alternative might be to require an Explicit Submission (Chapter 10) but apply Predictive Fetch (Chapter 13) to keep pulling down results according to the user’s current input. That way, the results will be ready as soon as the user clicks on the search button.
Decisions
How will you interpret incomplete text?
The user begins searching for “cataclysmic.” Having typed as far as “cat,” what will you show?
Matches for “cat,” “catalogue,” “cataclysmic,” and anything else beginning with “cat”?
Matches for “tomcat,” “delicate,” scatter,” and anything else containing cat.
Just matches for “cat”.
A combination, with a few of each.
In the first two preceding options, “cat” is implicitly transformed to “cat*” and “*cat*”, where “*” represents any character. For most searches, the “cat*” style is preferable because the user knows what she is looking for—a user searching for “cataclysmic” has no need to search for “*aclys*”—so inserting a wildcard at both ends merely clutters the interface and increases search cost.
Whether to use a wildcard at all is another matter. That is, should “cat” match just “cat,” or also “cataclysmic”? There are benefits on both sides, which is why combining them is worth considering. It also comes down to how many results you generally expect. If there’s only one or two results for “cat,” then you might want to anticipate further typing. If there’s a heap of results for “cat” alone, then there are probably enough to show that you don’t need to anticipate any further characters.
How verbose will the results be?
As with regular search, you need to decide how much each candidate result will show. Because the results are sent frequently, you might need to limit results to just a basic summary. An interesting variation on this would be to use Multi-Stage Download —get a quick summary immediately, then a few seconds later, if the user is inactive, refine the results with a second query.
What will happen when there are too many results?
You can usually show only a fraction of the results at once—typically, up to 50 or 100 results and probably much less than that if bandwidth and server processing are critical constraints. However, there could be thousands of results. In the worst case, before the user has specified anything, there are no constraints and every item is a candidate. So you’ll need to decide what happens when there are too many results to show.
One option is not to show any results at all, on the basis that the user should refine his search. This is not always the best idea, because you will have missed an opportunity to provide a little feedback and help the user explore. So you often want a way to provide a reduced list of matches. The search algorithm might have a way to prioritize results, perhaps based on popularity or the user’s personal history.
You could also consider using a Virtual Workspace (Chapter 15) to give the appearance of having loaded all results and thus allow the user to navigate through them. The OpenRico Yahoo! Search Demo (http://openrico.org/yahooSearch.page) provides search results in this way. It’s not a Live Search, but you could easily incorporate a Live Search into the approach.
A further possibility would be to place the results “on rotation”—that is, run a Periodic Refresh (Chapter 10) to show an ever-changing collection of results. I haven’t seen this in an Ajax Live Search, but a slideshow-type navigation—rapidly rotating images—has been used in other domains to reduce information overload (for example, some TVs support channel surfing with a collage of rapidly changing channels).
Real-World Examples
Delta Vacations
Delta Vacations has a hotel booking facility. After identifying a destination on the destination page (http://www.deltavacations.com/destinations.aspx), you can perform a Live Search for a hotel. For example, if you type “dis” in the Los Angeles page (http://www.deltavacations.com/destination.aspx?code=LOSANGELES), you’ll promptly see all of the Disney hotels appear (Figure 14-23). You can also change the sort order dynamically.
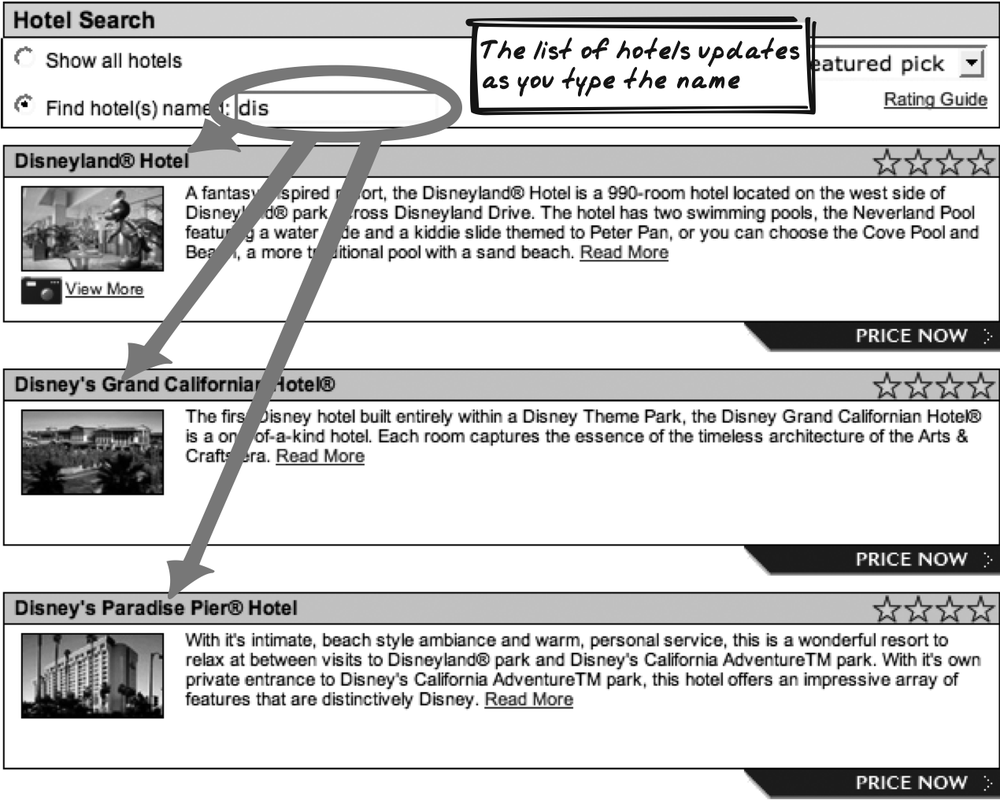
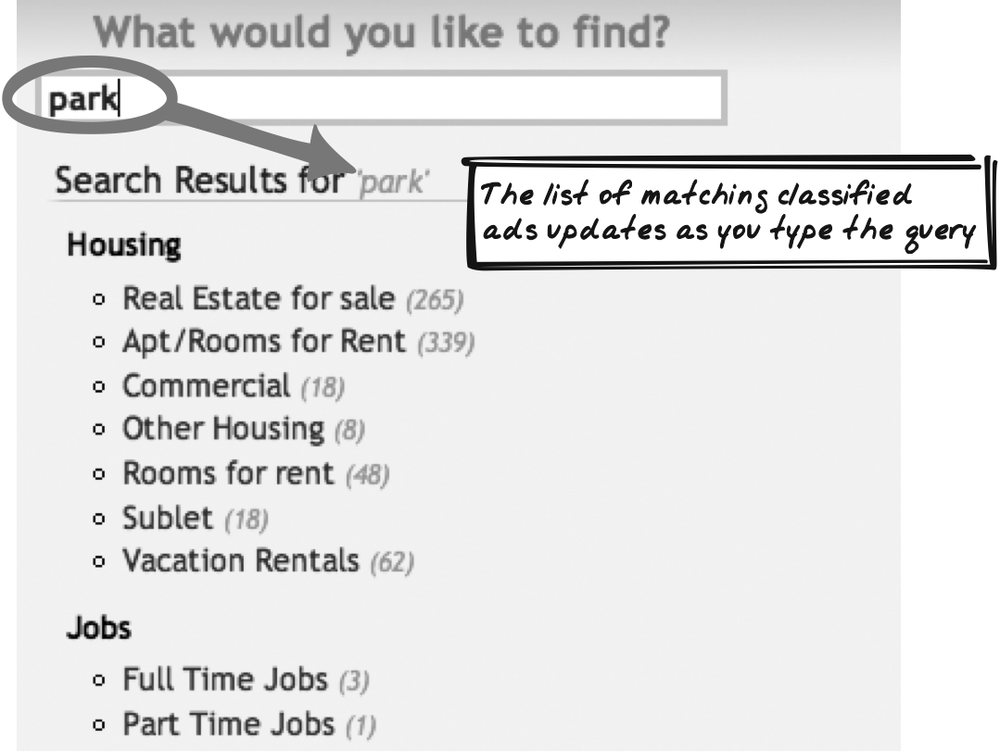
Amazon Diamond Search
Amazon’s Diamond Search (http://www.amazon.com/gp/gsl/search/finder/102-1689279-4344148?productGroupID=loose%5fdiamonds) is a unique search interface, incorporating several Sliders (see earlier in this chapter) to set such variables as shape, price, and number of carats (see Figure 14-5). Each time you alter a Slider, a message appears beside it showing the total number of results for the current search. Unfortunately, this is a weak variant of Live Search in which the results themselves are not shown until an Explicit Submission (Chapter 10) takes place.
Skype
Skype’s Skype-In service (http://skype.com) lets you choose a real-world phone number that will redirect to your Skype account. As you type some digits, you’ll see Skype’s available numbers.
Code Example: Delta Vacations
Delta Vacations
The Delta Vacations search registers an updateHotelList event handler on each
control that manages the Live Search: the text input, a
radiobutton pair determining whether to show all hotels or just
those matching the text input, and a selector for the sort order.
For example, here’s the static HTML or the text input:
<input type="text" id="HotelNameBox" onfocus="setChecked('FindByName')"
onkeyup="updateHotelList('hdnDestCode', 'HotelNameBox', 'SortOptions');" />updateHotelList( ) will
then call the server. In this case, the server offers an
HTML Message that outputs the exact HTML for
the results. If you visit http://www.deltavacations.com/ajax.aspx?d=LOSANGELES&n=dis&s=rating,
you can see that the result is just a segment of HTML:
<div id="H0" class="StandardHotel">
<h2 class="FourStar">
<a href="property.aspx?code=LAX0001&&dest=LOSANGELES">Disneyland
Hotel</a>
</h2>
...The results are then morphed to show the HTML:
var container = document.getElementById('HotelListView');
if (null == container) return;
if (http.responseText)
{
container.innerHTML = http.responseText;
}
else
{
container.innerHTML = "No hotels matched your search.";
}Assistive Search demo
The Assistive Search demo (http://ajaxify.com/run/assistiveSearch) can be considered a weak form of Live Search because it shows which categories of results will be retrieved but not the results themselves. It does illustrate some of the concepts discussed in this section and is analyzed in the examples in Live Command-Line, later in this chapter.
Related Patterns
Progress Indicator
While waiting for results to load after a user inputs data, you might choose to show a Progress Indicator (see earlier). Keep it fairly subtle, though, as it will appear and disappear frequently.
Virtual Workspace
Early in the Live Search, there are often more results than you can show at once. Consider presenting them in a Virtual Workspace (Chapter 15) to let the user explore all the results.
One-Second Spotlight
One-Second Spotlight (Chapter 16) can be used to transition from older to newer results.
Submission Throttling
Instead of submitting upon each keypress, Live Searches often submit the input query at intervals—a form of Submission Throttling (Chapter 10). In many cases, it makes sense to submit only after an idle period so that the search term is exactly what the user is looking for rather than an incomplete version.
Unique URLs
Different search queries should generally have Unique URLs (Chapter 17) associated with them.
Predictive Fetch
You can look at Live Search as a kind of Predictive Fetch (Chapter 13) in which the prefetched results are made visible.
Suggestion
Suggestion is similar to Live Search in that both involve performing a search to synchronize the display against an incomplete input. However, they differ in the following ways:
Suggestion is not just about search—you can use it to complete words as a user types. The backend algorithm involves search but searching isn’t the user’s goal.
Even in the context of search, Suggestion aims to complete the query, whereas Live Search aims to fill the results. If the search says “ab,” a Suggestion will give you potentially useful terms—e.g., “abdominals,” “absolutely”—while a Live Search will give you all items matching “ab” or “ab . . . .”
Live Command-Line
○ Assistive, CLI, Command-Line, Grammar, Supportive
Goal Story
Frank is using an advanced query tool to run a report on current output. He begins entering an SQL-like query: “list all.” At this point, a suggestion list appears with all the things that can be listed, and he chooses “products.” Continuing on, the query now reads “list all products where” and a new list appears: “creationTime,” “quality,” and so on. He chooses “creationTime,” and. then enters the rest manually, preferring to ignore further suggestions. The query ends up as “list all products where creationTime is today and quality is faulty.” There’s a tick mark next to the query to indicate that it’s valid.
Problem
How can a command-line interface be supported?
Forces
Users can only say so much with point-and-click interfaces. The command line is more expressive and remains the tool of choice for expert users.
URLs and search fields are becoming general-purpose command-lines (http://www.codinghorror.com/blog/archives/000296.html).
Solution
In command-line interfaces, monitor the command being composed and dynamically modify the interface to support the interaction. The interface changes according to data, business logic, and application logic. When the command line is to be executed on the server, as is often the case, the browser usually delegates to the server the task of evaluating the partial command.
The command line is the quintessential expert interface and it’s worth bearing in mind that most users are “perpetual intermediates” (http://www.codinghorror.com/blog/archives/000098.html). That is, they learn enough to get by and generally learn new things only as and when required. So, while a powerful command line may be a superior choice in the long run, most users simply don’t have the time to spend learning it in advance.
Traditional command lines present a problem because they offer the user a blank slate. Everything the user types must be based on prior, upfront, learning, and the only feedback occurs after the command line has been executed. That’s not only inefficient for learning, but downright dangerous for sufficiently powerful commands. The model is: human enters command, computer executes command.
The solution is to be more interactive: with a smarter, more proactive command line, the construction of a command—its quick evolution from nothingness to an executable string—becomes something of a human/computer collaboration. For example, you can:
Indicate whether the command is valid before submitting it. If it’s not valid, prevent it from executing and inform the user what’s wrong and how it can be rectified.
Offer to fix invalid commands.
Offer Suggestions to help complete part of the command.
Help the user predict what will happen when the command is executed. For a query, this means hinting at the result—e.g., estimating number of matches (see Guesstimate [Chapter 13]).
Provide graphical widgets to help the user construct the command. For example, build up a mathematical expression using a calculator-like interface to introduce numbers and functions. The query is still represented as plain-text, but the text doesn’t need to be entered by hand.
Provide graphical widgets to help the user refactor the command. For example, you could provide a “delete this” button next to each condition in a query.
Provide visualization tools to render the query in other formats. For example, certain numerical queries might be visualized graphically.
The benefits apply to novices and experts alike. In supporting novices, the technique has sometimes been referred to as a “training wheels” approach. Like training wheels on a bike, you get a feel for the more powerful interface while still being productive.
Often, the command goes to the server, so it usually makes sense for the server to advise the use regarding partial commands. Basically, the procedure goes like this:
Submission Throttling (Chapter 10) periodically uploads the partial command string as an XMLHttpRequest Call.
The server then processes the command and returns supporting information.
The browser updates the user interface accordingly.
As an Ajax feature, this pattern is largely speculative: I’m not aware of any production-level Ajax Apps, but the command-line interface is growing at the same time as Ajax; it’s inevitable that these things will collide, and as the discussion here suggests, there are plenty of synergies. One source of inspiration here is the evolution of IDEs over the past five years, particularly in the Java space. Environments like Eclipse (http://eclipse.org) and IntelliJ Idea (http://www.jetbrains.com/idea/) internally represent source files as data structures, leading to features such as ongoing error detection, offers to fix errors, suggestions, powerful refactorings, and alternative displays. All of this happens without the user ever having to compile the source code. As another source of inspiration, there was a recent experiment on training wheels for the command line (http://www.cs.utep.edu/nigel/papers/HCII2005.pdf). Students learned about the Unix command line from either a book or a GUI “training wheels” interface, similar to a Live Command-Line. The training wheels interface was found to be more productive and a more pleasant experience, too.
Decisions
Where will the partial command be analyzed—browser or server?
It’s possible to perform some kinds of analysis in the browser—for example, the browser can check the query against a constant regular expression. So should you try to support analysis in the browser or delegate it to the server?
There are several advantages to analyzing the command server side:
The analysis can take into account server-side data, external services, and server-side hardware resources.
In most cases, the command will ultimately be processed by the server, so this allows related logic to be kept in the same place.
Since the command is just a text string, it’s in a convenient form for uploading and server-side processing. Also, it’s easier to keep earlier results in a Browser-Side Cache because the command constitutes a key for the cache.
The downsides are:
There is an extra load on the server.
Extra bandwidth is required to download richer responses.
There is extra lag time between the user’s input typing and the browser’s response.
How much information will the server provide?
Producing more information for partial commands will consume more server resources. The information will also take a bit longer to download. You’ll need to trade off resources in favor of supportive information. For example:
In supporting validation, you can often rule out many errors with a simple regular expression. But more complex errors relating to the existence of business objects, for example, will get past that filter. Should you try to catch those too? Doing so would improve usability at the expense of resources.
In hinting at the command’s result, there’s a spectrum of precision. For a query, you can say “there might be results,” “there are results,” or “there are 4123 results.” In an extreme case, you can offer a Live Search (earlier in this chapter) and actually show the results.
Real-World Examples
I’m not aware of an all-encompassing Live Command-Line demo. However, the examples in Live Search and Suggestion (earlier in this chapter) are special cases of Live Command-Lines. There are also some JavaScript terminal emulators around, though they don’t provide Live Command-Lines—see Web Shell (http://a-i-studio.com/cmd/) and JS/UNIX Unix Shell (http://www.masswerk.at/jsuix/jsuix_support/). Also, see the Try Ruby! tutorial (http://tryruby.hobix.com/) for an impressive web interface to the interactive Ruby programming environment.
YubNub
YubNub (http://yubnub.org) isn’t Ajaxian, but it is noteworthy as the first explicit exploration of the “search as command line” meme. Yubnub lets users submit commands, which are then mapped into external queries. For example, if you type in “sum 10 20” (http://yubnub.org/parser/parse?command=sum+10+20), you get the sum of 10 and 20; if you type in “ajax form” (http://yubnub.org/parser/parse?command=ajax+form, you get search results from ajaxpatterns.org for “form.”
Code Example: AjaxPatterns Assistive Search Demo
The Assistive Search Demo (http://ajaxify.com/run/assistiveSearch) was inspired by services such as Google Search, which are trending toward a general-purpose command line. It aims to illustrate the “training wheels” style of command-line support.
The Assitive Search Demo has a typical search engine form—a free-range text input with a Submit button—in addition to several images, one for each category that can be searched. Thus, the user is alerted to the capabilities of the search. As the user types, the categories highlight and unhighlight to help predict what kind of results will be returned (Figure 14-26). All of this information comes from the server side; the browser application doesn’t know anything about the categories. It calls the server and startup to discover the categories and corresponding images. A timer monitors the command line, continually asking the server which categories it matches. The browser then highlights those categories.
The startup sequence loads the categories and kicks off the command-line monitoring loop. The server is required to have an image for each category. If it says that there’s a “phone” category, then there will be a corresponding image at Images/phone.gif. The images are all downloaded and placed alongside each other:
window.onload = function( ) {
initializeCategories( );
requestValidCategoriesLoop( );
...
}
}
function initializeCategories( ) {
ajaxCaller.getPlainText("categories.php?queryType=getAllCategoriesCSV",
onAllCategoriesResponse);
}
function onAllCategoriesResponse(text, callingContext) {
allCategoryNames = text.split(",");
var categoriesFragment = document.createDocumentFragment( );
for (i=0; i<allCategoryNames.length; i++) {
var categoryName = allCategoryNames[i];
var categoryImage = document.createElement("img");
categoryImage.id = categoryName;
categoryImage.src = "Images/"+categoryName+".gif";
categoriesFragment.appendChild(categoryImage);
}
document.getElementById("categories").appendChild(categoriesFragment);
}The key to the Live Command-Line is the monitoring loop. Whenever a change occurs, it asks the server to return a list of all matching categories:
function requestValidCategoriesLoop( ) {
if (query( )!=latestServerQuery) {
var vars = {
queryType: "getValidCategories",
queryText: escape(query( ))
}
ajaxCaller.get("categories.php", vars, onValidCategoriesResponse,
false, null);
latestServerQuery = query( );
}
setTimeout('requestValidCategoriesLoop( );', THROTTLE_PERIOD);
}The server uses a bunch of heuristics to calculate the valid categories for this query. For instance, it decides if something belongs to the “people” category by looking up a collection of pronouns in the dictionary. A controller will ultimately return the categories as a comma-separated list generated with the following PHP logic:
function getValidCategories($queryText) {
logInfo("Queried for '$queryText'\n");
$cats = array( );
eregi(".+", $queryText) && array_push($cats, 'web');
eregi("^[0-9\+][A-Z0-9 \-]*$", $queryText) &&
array_push($cats, 'phone');
eregi("^[0-9\.\+\/\* -]+$",$queryText) &&
array_push($cats, 'calculator');
isInTheNews($queryText) && array_push($cats, 'news');
isInWordList($queryText, "./pronouns") && array_push($cats, 'people');
isInWordList($queryText, "./words") && array_push($cats, 'dictionary');
return $cats;
}The browser dynamically updates the category images using a CSS class indicating whether they are valid, which it determines by checking whether they were in the list. There’s also an event handler to perform searches on specific categories, as long as those categories are valid:
function onValidCategoriesResponse(text) {
var validCategoryNames = text.split(",");
// Create a data structure to make it faster to determine if a named
// category is valid. For each valid category, we add an associative array
// key into the array, with the key being the category name itself.
validCategoryHash = new Array( );
for (i=0; i<validCategoryNames.length; i++) {
validCategoryHash[validCategoryNames[i]] = "exists";
}
// For all categories, show the category if it's in the valid category map
for (i=0; i<allCategoryNames.length; i++) {
var categoryName = allCategoryNames[i];
var categoryImage = $(categoryName);
if (validCategoryHash[categoryName]) {
categoryImage.onclick = onCategoryClicked;
categoryImage.className="valid";
categoryImage.title =
"Category '" + categoryName + "'" +" probably has results";
} else {
categoryImage.onclick = null;
categoryImage.className="invalid";
categoryImage.title =
"Category '" + categoryName + "'" + " has no results";
}
}
}Alternatives
Point-and-click
The command line involves typing, while point-and-click is a simpler interface style that shows available options and lets the user click on one of them.
Drag-And-Drop
Another means of issuing commands is with Drag-And-Drop (Chapter 15)—dragging an item into a trash can to delete it.
Related Patterns
Submission Throttling
Instead of processing the command upon each keystroke, use Submission Throttling (Chapter 10) to analyze it at frequent intervals.
Status Area
Feedback such as input validation and result prediction is usually shown in a Status Area (Chapter 15).
Highlight
Some parts of the command can be highlighted to point out errors, incomplete text, and so on. Also, aspects of the Status Area can be highlighted to help with prediction.
Progress Indicator
If it takes more than one second to process the command line, consider showing a Progress Indicator (see earlier).
Browser-Side Cache
Introduce a Browser-Side Cache (Chapter 13) to retain the server’s analysis of partial commands.
Fat Client
Consider creating a Fat Client (Chapter 13) that tries to handle as much of the analysis as possible, thus reducing server calls.
Want To Know More?
Yubnub (http://yubnub.org) lets users search different sites based on a command line. Users are allowed to add new commands; is this “social command line sharing”?
Russell Beattie: “Search as Practical Artificial Intelligence” (http://www.russellbeattie.com/notebook/1008310.html).
Jeff Attwood: “Google-Fu: (T)he browser address bar is the new command line” (http://www.codinghorror.com/blog/archives/000296.html).
Live Form
⊙⊙ Dynamic, Live, Real-Time, Validation
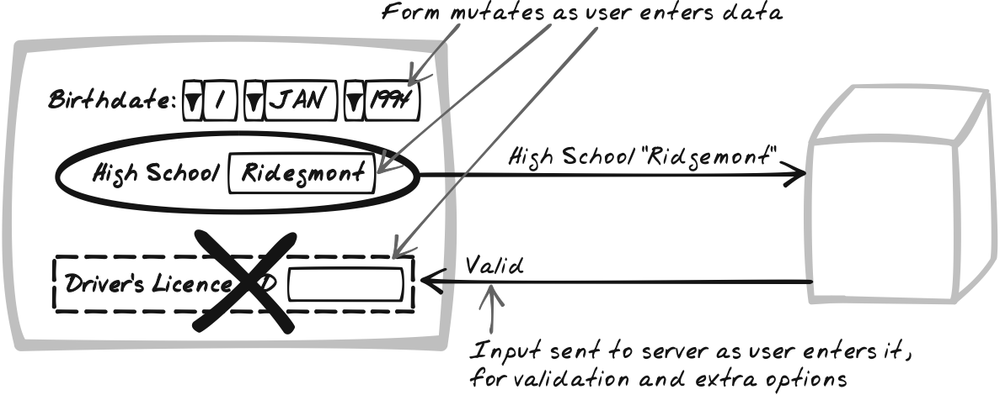
Goal Story
Tracy is using a Live Form to apply for a new online brokerage account. Upon declaring her place of residence, some additional regulation-related questions specific to her region appear. Several asset classes can be traded. She clicks a box to indicate that she wants to trade in bonds, and further questions specifically for that asset class appear. She then clicks on another box, for options. A moment later, a warning appears that new users can trade in either options or bonds, but not both. After further refinement, she successfully submits the form and sees it fade into a welcome message.
Problem
How can the user submit data as quickly as possible?
Forces
Most data submission tasks require some flexibility. A particular answer for one item may necessitate further questions. Often, this must occur server side, where business logic and data usually reside.
Most data submission requires validation. This must occur server side to prevent browser-side manipulation of inputs.
Users get frustrated waiting for data to be validated and continuously refining data upon each explicit submission.
Solution
Validate and modify a form throughout the entire interaction instead of waiting for an explicit submission. Each significant user event results in some browser-side processing, often leading to an XMLHttpRequest Call. The form may then be modified as a result.
Modifying the form is similar to responding to a Microlink (Chapter 15)—there’s usually a server call followed by some Page Rearrangement (Chapter 5). Typical modifications include the following:
New controls appear.
Controls become disabled.
Information and error messages appear.
The result is a more interactive form. The user doesn’t have to wait for a page reload to find out if a form field is invalid, because it’s validated as soon as she enters the value. Due to the asynchronous nature of XMLHttpRequest Call, the validation occurs as a background process while the user continues entering data. If there’s an error, the user will find out about it while filling out a field further down on the form. As long as errors don’t happen too often, this is no great inconvenience.
Validation doesn’t always occur at field level though. Sometimes it’s the combination of data that’s a problem. This can be handled by checking validation rules only when the user has provided input for all related fields. A validation error can result in a general, form-level error message or a message next to one or more of the offending fields.
A Live Form usually ends with an Explicit Submission (Chapter 10), allowing the user to confirm that everything’s valid. Note that unlike a conventional form, the Explicit Submission does not perform a standard HTTP form submission but posts the contents as an XMLHttpRequest Call.
Real-World Examples
WPLicense
WPLicense (http://yergler.net/projects/wplicense) is a plugin for the WordPress blogging framework, allowing users to specify a copyright license for their blog content (Figure 14-28). Refer to Cross-Domain Proxy (Chapter 10) for details on the plugin and to the section "Code Example: WPLicense,” later in this chapter, for a walkthrough of its Live Search implementation.

Betfair
Betfair (http://betfair.com) lets the user make a bet using a Live Form—one which changes but doesn’t actually interact with the server (Figure 14-29). You can try this even as a nonregistered user by opening up a bet from the Drilldown (see earlier in this chapter) menu. There are three columns on the page: the left column shows the current bet topic within the Drilldown, the center column shows odds for all candidates, and the right column shows your stake in the bet. Click on a candidate to make it appear in your stake form, where you can then set the amount for the bet you’re placing. As you change your stake, a Status Area shows your total liability. Another column shows your profit with respect to each potential outcome. There are also some “meta” controls—e.g., the “Back All” button, which creates an editable row for every candidate.
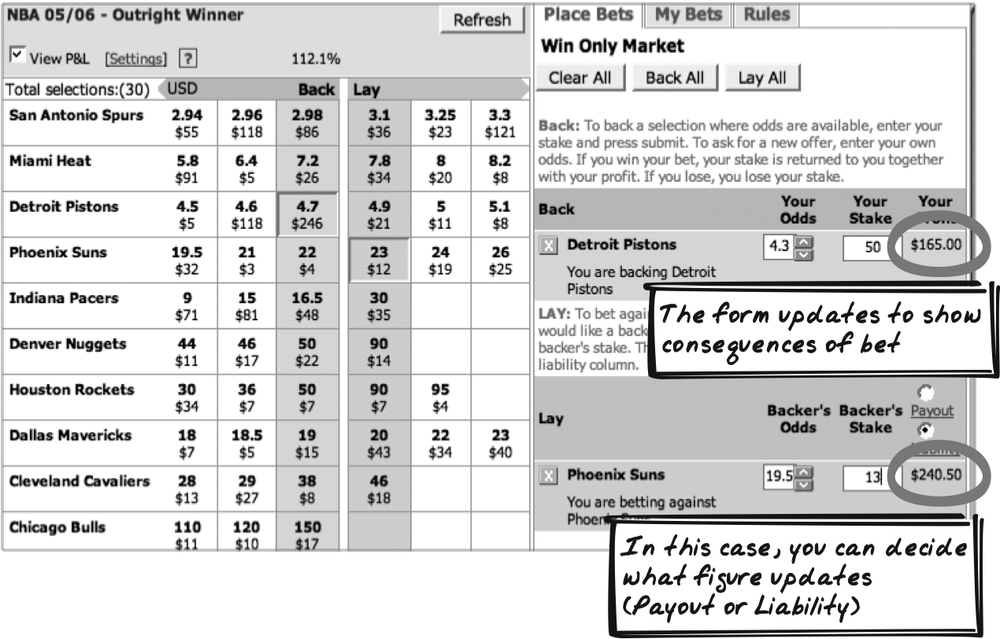
MoveableType Comment hack
Simian Design (http://www.simiandesign.com/blog-fu/2005/07/ajax_comments_b.php#comments) is a blog where you can add comments, Ajax style. As you type into the text box, a live preview appears beneath it and takes markup into account. If you click on Preview or Post, the text fades and an animated Progress Indicator (see earlier in this chapter) bar shows that the server is processing. Page Rearrangement then embeds the result in the page.
Code Example: WPLicense
WPLicense (http://yergler.net/projects/wplicense) is a form with a live component. Initially, the “License Type” field simply shows the current license, if any. But when the user clicks on the update link, a new block opens up and a conversation between the browser and server ensues to establish the precise details of the license. (More precisely, the conversation is between the browser and the Creative Commons web site; see the corresponding example in Cross-Domain Proxy (Chapter 10). Each license type has associated questions, so the license options are fetched according to the user’s license type selection.
When the user launches the plugin, a PHP function begins by drawing the Live Form. In this case, the form is ultimately submitted as a conventional POST upload, so the form has a conventional declaration:
<form name="license_options" method="post" action="' . $_SERVER[REQUEST_URI] . '">
...
<input type="submit" value="save" />
<input type="reset" value="cancel" id="cancel" />
...
</form>The current license is shown and loaded with initial values along with the link that triggers the cross-domain mediation to update the license setting:
<tr><th>Current License:</th><td>
<a href="'.get_option('cc_content_license_uri').'">'
.get_option('cc_content_license').'</a>
...The form includes hidden input fields to capture information gleaned during the Ajax interaction. They will be populated by JavaScript event handlers:
<input name="license_name" type="hidden"
value="'.get_option('cc_content_license').'" />Also, an initially invisible div will be shown once the user decides to
change the license. Don’t confuse this with the hidden input
fields—those will never be shown to the user, whereas this just
happens to have a hidden style when the page initially loads. Most
critically, the div contains a
selection field:
<select id="licenseClass"> <option id="-">(none)</option>
...
foreach($license_classes as $key => $l_id) {
echo '<option value="' . $key . '" >' . $l_id . '</option>';
}; // for each...
...
</select>Now for the live part. The licenseClass selector is associated with
retrieveQuestions, a function
that fetches the questions corresponding to the chosen license. The
call is made courtesy of the Sack library (http://twilightuniverse.com/2005/05/sack-of-ajax/),
which paints the server’s HTML directly onto the license_optionsdiv. When you switch to a
new license class, the form automatically shows the questions
associated with that class:
el.onchange = function( ) {
retrieveQuestions( );
} // onchange
function retrieveQuestions( ) {
ajax = new sack(blog_url);
ajax.element='license_options';
ajax.setVar('func', 'questions');
ajax.setVar('class', cmbLC.value); ''Current license passed to server''
ajax.runAJAX( );
...
}The server determines the appropriate questions to ask and outputs them as HTML Messages. (See the section "Code Example: WPLicense" in Cross-Domain Proxy [Chapter 10] for details.)
Now how about those hidden fields? Well, not all the information related to the options is hidden: the license URL is shown to the user, so that also needs to be updated after an option is chosen. Each time the user changes the server-generated options, the server is called to get a bunch of information about the current selection. That information then comes back to the browser, and the callback function updates both the hidden fields and the URL accordingly:
[Updating the hidden fields]
document.license_options.license_name.value = licenseInfo['name'];
document.license_options.license_uri.value = licenseInfo['uri'];
document.license_options.license_rdf.value = licenseInfo['rdf'];
document.license_options.license_html.value = licenseInfo['html'];
[Updating the visible license URL]
href_text = '<a href="' + licenseInfo['uri'] + '">' + licenseInfo['name'] + '
</a>';
document.getElementById("newlicense_name").innerHTML = href_text;Now, what, so far, changed on a permanent basis? Well, nothing. Everything so far has served the purpose of setting up the form itself. But that’s fine in this case, because the form is submitted in the conventional manner. So as soon as the user clicks on the Submit button, all of those hidden fields will be uploaded and processed as standard HTTP form data.
Related Patterns
Microlink
Like Live Form, Microlink (Chapter 15) opens up new content directly on the page. Indeed, a Microlink can be used on a Live Form to open up supporting information.
Live Search
Consider including a Live Search (see earlier) when users need to perform a search within the Live Form.
Suggestion
Consider offering Suggestions (see earlier) to help users complete fields within the Live Form.
Drilldown
Consider including a Drilldown (see earlier) when users need to identify an item within a hierarchy.
Progress Indicator
Use a Progress Indicator (see earlier) to show that the server is working to process a field with a Progress Indicator.
One-Second Spotlight
Since Live Forms are usually submitted with an
XMLHttpRequest Call, a One-Second
Spotlight (Chapter
16) effect, such as Fade
Out, is a good way to convey that the form has been
submitted.
[*] For example, you can see the data for the “Overviews” category at http://ajaxify.com/run/portal/drilldown/drilldown.phtml?categoryName=Overviews.
[*] “What You See Is What You Get” (WYSIWYG) interfaces are a staple of windows-based apps, where the editing interface is essentially the same as the output (i.e., a printout or a presentation).
Get Ajax Design Patterns now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

