March 2025
Intermediate to advanced
344 pages
9h 30m
Portuguese (Portugal, Brazil)
Este trabalho foi traduzido com recurso a IA. Agradecemos o teu feedback e comentários: translation-feedback@oreilly.com
O formato de tabela Apache Iceberg fornece consultas de alto desempenho durante leituras e gravações, permitindo executar cargas de trabalho de processamento analítico online (OLAP) diretamente no lago de dados. O que facilita esse desempenho é a forma como os vários componentes do formato de tabela Iceberg são projetados. Por isso, é fundamental entender a estrutura desses componentes para que os mecanismos de consulta possam usá-los com eficiência para agilizar o planejamento e a execução da consulta. Discutimos estes componentes arquitecturais em pormenor no Capítulo 2. A um nível elevado, todos estes componentes podem ser divididos em três camadas diferentes, conforme apresentado na Figura 3-1.
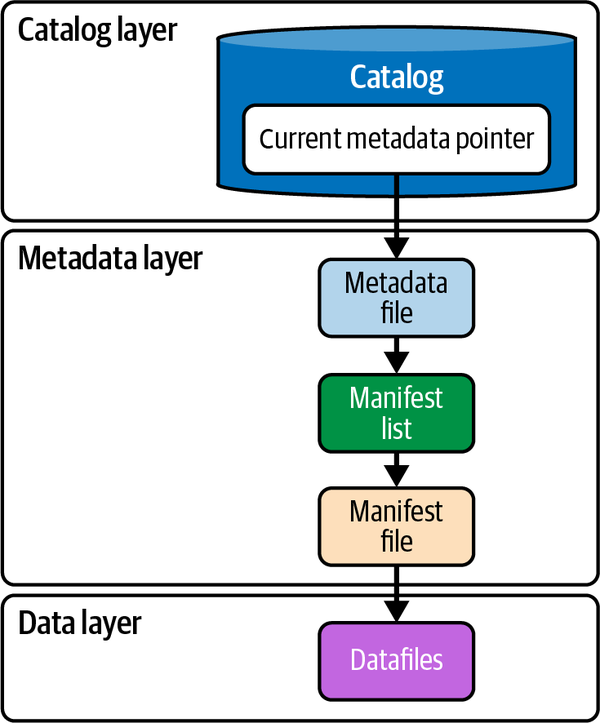
Vamos rever rapidamente como um motor de consulta interage com estes componentes para leituras e escritas:
Como aprendeste no Capítulo 2, um catálogo contém as referências ao ponteiro de metadados atual, ou seja, o ficheiro de metadados mais recente para cada tabela. Independentemente de estares a fazer uma operação de leitura ou uma operação de escrita, o catálogo é o primeiro componente com o qual um motor de consulta interage. No caso das leituras, ...