April 2022
Intermediate to advanced
57 pages
1h 21m
English
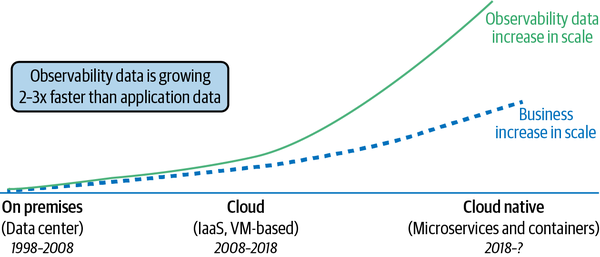
Metrics are growing in scale, and that means the data they produce also grows exponentially, far outpacing the growth of the business and its infrastructure (as shown in Figure 4-1). Growth this fast causes problems: storing all of the data your metrics produce about everything (logs, metrics, and traces) would be prohibitively expensive in terms of both cost and performance. In a survey of 357 IT, DevOps, and application development professionals by ESG, 71% saw the growth rate of observability data as “alarming.”1
Why so much growth? The reasons include faster deployments, a shift to microservices architectures, the ephemerality of containers, and even the cardinality of metric data itself. This causes a dilemma: how should you identify which metric data is worth storing?
To answer this question, you need to understand the major use cases for metrics in your organization. Look at RPC traffic, request/response rates, and latency, ideally as they enter your system. If you have, for example, 100 microservices, how many dimensions should you add to your metrics? Should you capture all data as it comes in for each metric?
Metrics cardinalities can generally be classified into three types, as Chronosphere’s John Potocny notes:3
These ...
Read now
Unlock full access






