January 2018
Intermediate to advanced
310 pages
7h 48m
English
Donahue et al., in the paper https://arxiv.org/pdf/1411.4389.pdf, proposed Long-term recurrent convolutional architectures (LRCN) for the task of image captioning. The architecture of this model is shown here:
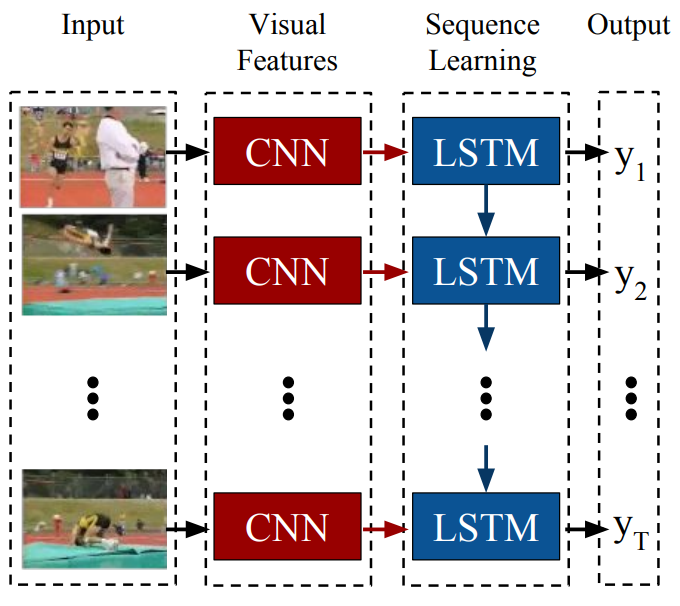
Both the CNN and LSTM is shown in the figure share weights across time, which makes this method scalable to arbitrarily long sequences.
Read now
Unlock full access






