May 2025
Beginner to intermediate
616 pages
10h 32m
Korean
이 작품은 AI를 사용하여 번역되었습니다. 여러분의 피드백과 의견을 환영합니다: translation-feedback@oreilly.com
정돈이 안 된 사람은 찾기 어렵습니다.
(물건을 깔끔하게 정리해 두면 너무 게을러져서 검색하러 가기 힘들어집니다.)
독일 속담
가장 기본적인 수준에서 데이터베이스는 사용자가 데이터를 제공하면 데이터를 저장하고, 나중에 다시 요청하면 데이터를 돌려주는 두 가지 작업을 수행해야 합니다.
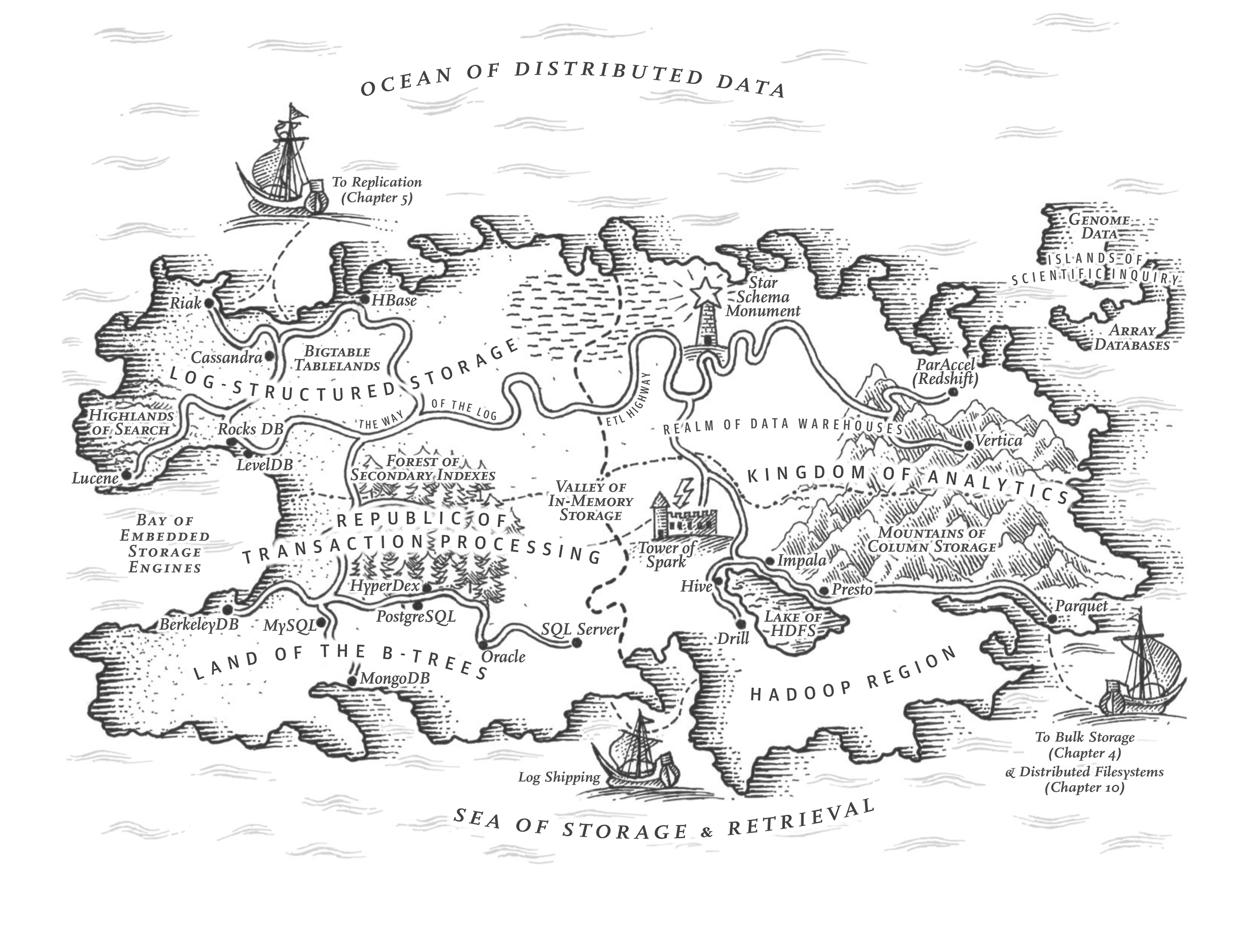
2장에서는 데이터 모델과 쿼리 언어, 즉 사용자(애플리케이션 개발자)가 데이터베이스에 데이터를 제공하는 형식과 나중에 데이터를 다시 요청할 수 있는 메커니즘에 대해 설명했습니다. 이 장에서는 데이터베이스의 관점, 즉 주어진 데이터를 저장하는 방법과 데이터를 요청받았을 때 다시 찾을 수 있는 방법에 대해 논의합니다.
애플리케이션 개발자로서 데이터베이스가 내부적으로 저장 및 검색을 처리하는 방식에 관심을 가져야 하는 이유는 무엇일까요? 처음부터 자체 스토리지 엔진을 구현하지는 않겠지만, 사용 가능한 많은 스토리지 엔진 중에서 애플리케이션에 적합한 스토리지 엔진을 선택해야합니다. 자신의 워크로드에 적합한 성능을 발휘하도록 스토리지 엔진을 조정하려면 스토리지 엔진이 내부에서 어떤 작업을 수행하는지 대략적으로 파악해야 합니다.
특히 트랜잭션 워크로드에 최적화된 스토리지 엔진과 분석에 최적화된 스토리지 엔진 사이에는 큰 차이가 있습니다. 이러한 차이점은 나중에 "트랜잭션 처리 또는 분석?"에서 살펴보고, "열 지향 스토리지" 에서는 분석에 최적화된 스토리지 엔진 제품군에 대해 설명하겠습니다.
하지만 이 장에서는 먼저 여러분이 익히 알고 있는 데이터베이스, 즉 전통적인 관계형 데이터베이스와 대부분의 소위 NoSQL 데이터베이스에 사용되는 스토리지 엔진에 대해 이야기하는 것으로 시작하겠습니다. 여기서는 로그 구조의 스토리지 엔진과 B-tree와 같은 페이지 지향 스토리지 엔진이라는 두 가지 스토리지 엔진 제품군을 살펴볼 것입니다.
두 개의 bash 함수로 구현된 세계에서 가장 간단한 데이터베이스를 예로 들어보겠습니다:
#!/bin/bashdb_set(){echo"$1,$2">> database}db_get(){grep"^$1,"database|sed -e"s/^$1,//"|tail -n 1}
이 두 함수는 키-값 저장소를 구현합니다. db_set key value 을 호출하면key 과 value 이 데이터베이스에 저장됩니다. 키와 값은 (거의) 원하는 모든 것이 될 수 있습니다(예: 값은 JSON 문서일 수 있습니다). 그런 다음 db_get key 을 호출하면 해당 특정 키와 관련된 가장 최근 값을 조회하여 반환합니다.
그리고 작동합니다:
$ db_set ...