May 2025
Beginner to intermediate
616 pages
10h 32m
Korean
이 작품은 AI를 사용하여 번역되었습니다. 여러분의 피드백과 의견을 환영합니다: translation-feedback@oreilly.com
살아있고 틀린 것이 더 낫나요, 아니면 옳고 죽은 것이 더 낫나요?
제이 크렙스, 카프카와 젭슨에 대한 몇 가지 메모 (2013)
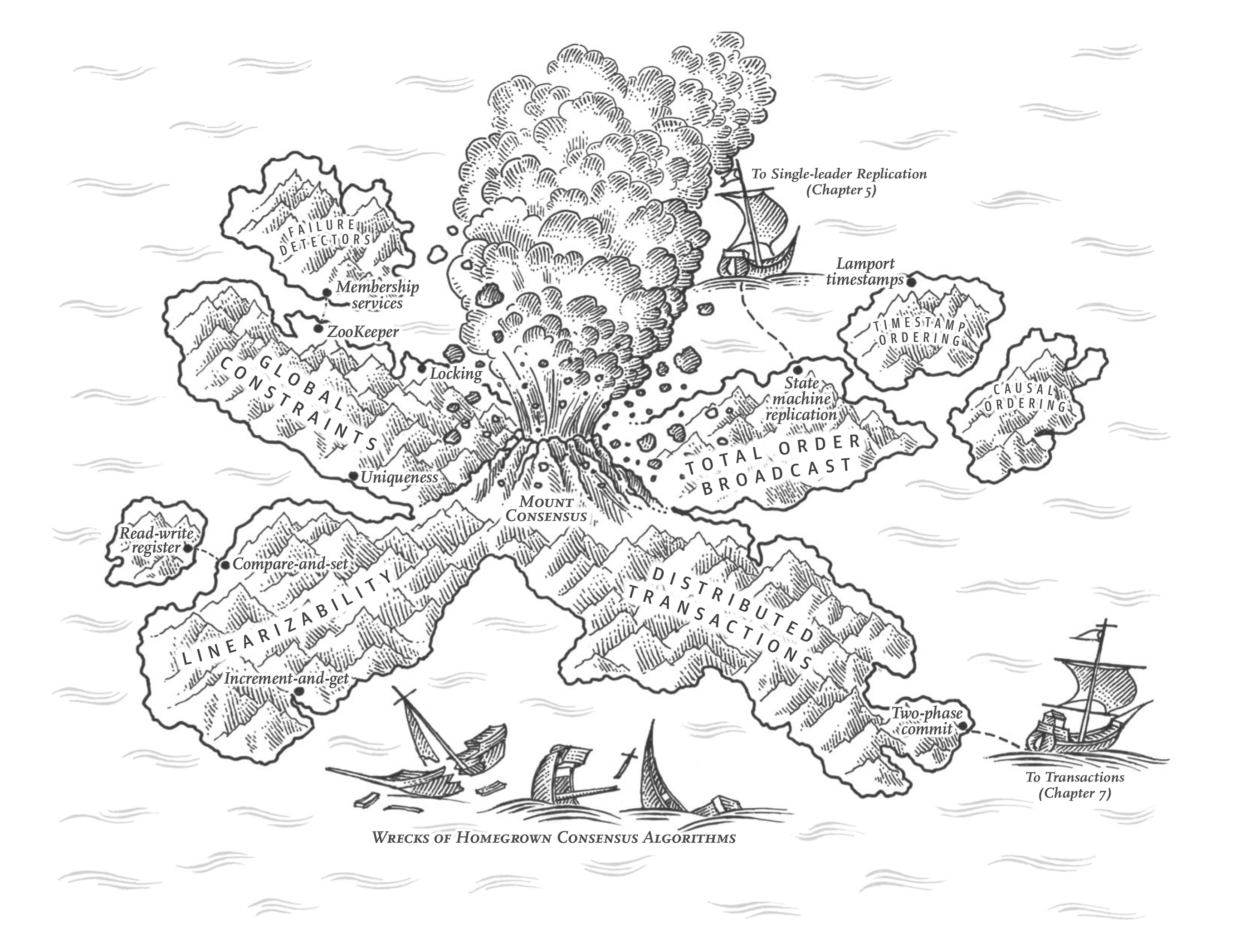
8장에서 설명한 것처럼 분산 시스템에서는 많은 일이 잘못될 수 있습니다. 이러한 결함을 처리하는 가장 간단한 방법은 단순히 전체 서비스가 실패하고 사용자에게 오류 메시지를 표시하는 것입니다. 이 방법이 허용되지 않는다면 결함을 허용하는 방법, 즉 일부 내부 구성 요소에 결함이 있더라도 서비스가 올바르게 작동하도록 유지하는 방법을 찾아야 합니다.
이 장에서는 내결함성 분산 시스템을 구축하기 위한 알고리즘과 프로토콜의 몇 가지 예에 대해 설명하겠습니다. 네트워크에서 패킷이 손실, 재순서화, 복제 또는 임의로 지연될 수 있고, 클럭은 기껏해야 근사치이며, 노드는 언제든지 일시 중지(예: 가비지 컬렉션으로 인해) 또는 충돌할 수 있는 등 8장의 모든 문제가 발생할 수 있다고 가정하겠습니다.
내결함성 시스템을 구축하는 가장 좋은 방법은 유용한 보장이 있는 범용 추상화를 찾아서 한 번 구현한 다음 애플리케이션이 이러한 보장에 의존하도록 하는 것입니다. 이는 7장에서 트랜잭션에 사용한 것과 동일한 접근 방식입니다. 트랜잭션을 사용하면 애플리케이션은 충돌이 없고(원자성), 아무도 데이터베이스에 동시에 액세스하지 않으며(격리), 저장 장치가 완벽하게 신뢰할 수 있는(내구성) 것처럼 가장할 수 있습니다. 충돌, 경쟁 조건 및 디스크 장애가 발생하더라도 트랜잭션 추상화는 이러한 문제를 숨기므로 애플리케이션이 이에 대해 걱정할 필요가 없습니다.
이제 같은 맥락에서 애플리케이션이 분산 시스템의 몇 가지 문제를 무시할 수 있는 추상화를 모색해 보겠습니다. 예를 들어, 분산 시스템의 가장 중요한 추상화 중 하나는 합의, 즉 모든 노드가 무언가에 동의하도록 하는 것입니다. 이 장에서 살펴보겠지만 네트워크 결함이나 프로세스 장애에도 불구하고 안정적으로 합의에 도달하는 것은 의외로 까다로운 문제입니다.
컨센서스를 구현한 후에는 애플리케이션에서 다양한 용도로 컨센서스를 사용할 수 있습니다. 예를 들어 단일 리더 복제를 사용하는 데이터베이스가 있다고 가정해 보겠습니다. 리더가 사망하여 다른 노드로 장애 조치해야 하는 경우, 나머지 데이터베이스 노드는 합의를 사용하여 새 리더를 선출할 수 있습니다. "노드 장애 처리하기"에서 설명한 대로 리더는 한 명만 있어야 하며, 모든 노드가 리더가 누구인지 동의하는 것이 중요합니다. 두 노드가 모두 자신이 리더라고 믿는 경우 이러한 상황을 스플릿 브레인이라고 하며, 종종 데이터 손실로 이어집니다. 합의를 올바르게 구현하면 이러한 문제를 방지하는 데 도움이 됩니다. ...