March 2017
Beginner to intermediate
370 pages
9h 55m
English
NOW THAT YOU HAVE THE BASICS DOWN, it’s time to put them into action beginning in this chapter. Using the framework introduced in Chapter 3, we’ll begin to flesh out each step in the process of designing an A/B test, and explain how the early and close involvement of designers is necessary to your team’s success. We’ll be discussing the activities shown in Figure 4-1 that are outlined in a dotted line. Throughout, we’ll revisit some of the common themes we highlighted in the Preface and Chapter 1.
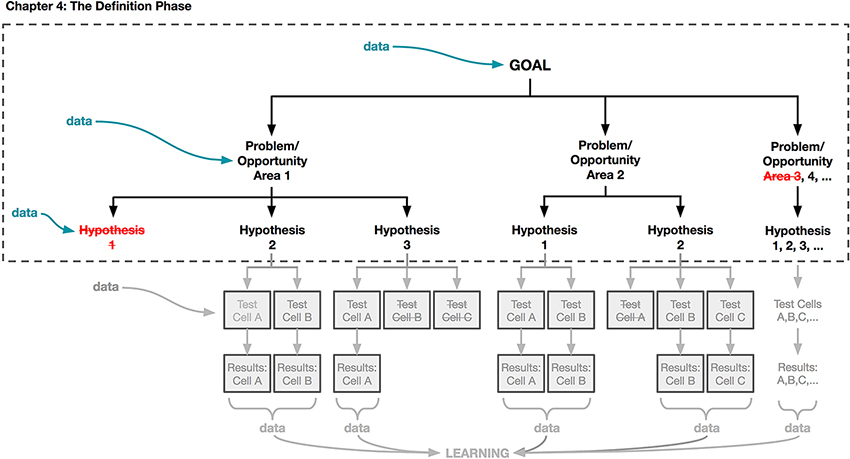
Taking a data-aware approach to design requires approaching your work with an open-minded attitude toward learning as much as you can about your users and which designs resonate with them. Adopting an approach of experimentation, and using data to explore and evaluate your ideas, will make you a better designer overall.
We’re going to spend the bulk of this chapter laying out how you can define your goals, problems, and hypotheses to maximize your learning when designing with data. Recall that a hypothesis is a statement that captures the impact you believe your design will have on your users. In this chapter, we’ll show you how to craft a strong hypothesis and ...
Read now
Unlock full access






