Now that you've set up your workstation, let's spend some time talking about how to get around in a Unix system. In this chapter, we introduce basic Unix concepts, including the structure of the filesystem, file ownership, and commands for moving around the filesystem and creating files.[*] Another important focus of this chapter, however, is the approach you should take to organizing your research data so that it can be accessed efficiently by you and by others.
All computer filesystems, whether on Unix systems or desktop PCs, are basically the same. Files are named locations on the computer's storage device. Each filename is a pointer to a discrete object with a beginning and end, whether it's a program that can be executed or simply a set of data that can be read by a program. Directories or folders are containers in which files can be grouped. Computer filesystems are organized hierarchically, with a root directory that branches into subdirectories and subdirectories of subdirectories.
This hierarchical system can help organize and share information, if used properly. Like the taxonomy of species developed by the early biologists, your file hierarchy should organize information from the general level to the specific. Each time the filesystem splits into subdirectories, it should be because there are meaningful divisions to be created within a larger class of files.
Why should you organize your computer files in a systematic, orderly way? It seems like an obvious question with an obvious answer. And yet, a common problem faced by researchers and research groups is failure to share information effectively. Problems with information management often become apparent when a research group member leaves, and others are required to take over his project.
Imagine you work with a colleague who keeps all his books and papers piled in random stacks all over his office. Now imagine that your colleague gets a new job and needs to depart in a hurry—leaving behind just about everything in his office. Your boss tells you that you can't throw away any of your colleague's papers without looking at them, because there might be something valuable in there. Your colleague has not organized or categorized any of his papers, so you have to pick up every item, look at it, determine if it's useful, and then decide where you want to file it. This might be a week's work, if you're lucky, and it's guaranteed to be a tough job.
This kind of problem is magnified when computer files are involved. First of all, many highly useful files, especially binaries of programs, aren't readable as text files by users. Therefore, it's difficult to determine what these files do if they're not documented. Other kinds of files, such as files of numerical data, may not contain useful header information. Even though they can be read as text, it may be next to impossible to figure out their purpose.
Second, space constraints on computer system usage are much more nebulous than the walls of an office. As disk space has become cheaper, it's become easier for users of a shared system simply never to clean up after themselves. Many programs produce multiple output files and, if there's no space constraint that forces you to clean up while running them, can produce a huge mess in a short time.
How can you avoid becoming this kind of problem for your colleagues? Awareness of the potential problems you can cause is the first step. You need to know what kinds of programs and files you should share with others and which you should keep in your own directories. You should establish conventions for naming datafiles and programs and stick to these conventions as you work. You should structure your filesystem in a sensible hierarchy. You should keep track of how much space you are using on your computer system and create usable archives of your data when you no longer need to access it frequently. You should create informative documentation for your work within the filesystem and within programs and datafiles.
The nature of the filesystem hierarchy means that you already have a powerful indexing system for your work at your fingertips. It's possible to do computer-based research and be just as disorganized as that coworker who piles all his books and papers in random stacks all over his office. But why would you want to do that? Without much more effort, you can use your computer's filesystem to keep your work organized.
Like all modern operating systems, the file hierarchy on a Unix
system is structured as a tree. You may be used to this from PC
operating systems. Open one folder, and there can be files and more
folders inside it, layered as deep as you want to go. There is a root
directory, designated as /. The root directory
branches into a finite number of files and subdirectories. On a
well-organized system, each of these subdirectories contains files
and other subdirectories pertaining to a particular topic or system
function.
Of course, there's nothing inside your computer that really looks like a tree. Files are stored on various media—most commonly the hard disk, which is a recordable device that lives in your computer. As its name implies, the hard disk is really a disk. And the tree structure that you perceive in Unix is simply a way of indexing what is on that disk or on other devices such as CDs, floppy disks, and Zip disks, or even on the disks of every machine in a group of networked computers. Unix has extensive networking capabilities that allow devices on networked computers to be mounted on other computers over the network. Using these capabilities, the filesystems of several networked computers can be indexed as if they were one larger, seamless filesystem.
Each
file on the filesystem can be uniquely
identified by a combination of a filename and a path. You can
reference any file on the system by giving its full name, which
begins with a / indicating the root directory,
continues through a list of subdirectories (the components of the
path) and ends with the filename. The full name, or
absolute path, of a file in someone's home
directory might look like this:
/home/jambeck/mustelidae/weasels.txt
The absolute path describes the relationship of the file to the
root
directory, /. Each name in the path represents a
subdirectory of the prior directory, and /
characters separate the directory names.
Every file or directory on the system can be named by its absolute
path, but it can also be named by a relative
path
that describes its relationship to the
current working directory. Files in the directory you are in can be
uniquely identified just by giving the filename they have in the
current working directory. Files in subdirectories of your current
directory can be named in relation to the subdirectory they are part
of. From jambeck 's home directory, he can
uniquely identify the file weasels.txt as
mustelidae/weasels.txt. The absence of a
preceding / means that the path is defined
relative to the current directory rather than relative to the root
directory.
If you want to name a directory that is on the same level or above
the current working directory, there is a shorthand for doing so.
Each directory on the system contains two links,
./ and ../, which refer to
the current directory and its parent directory
(the directory it's a subdirectory of ), respectively. If user
jambeck is working in the directory
/home/jambeck /mustelidae/weasels, he can refer
to the directory /home/jambeck
/mustelidae/otters as ../otters. A
subdirectory of a directory on the same level of the hierarchy as
/home/jambeck /mustelidae would be referred to
as ../../didelphiidae/opossums.
Another shorthand naming convention, which is implemented in the
popular csh and tcsh shell
environments, is that the path of the home directory can be
abbreviated as ~. The directory
home/jambeck /mustelidae can then be referred to
as ~/mustelidae.
Filesystems can be deep and narrow or broad and shallow. It's best to follow an intuitive scheme for organizing your files. Each level of hierarchy should be related to a step in the process you've used to carry out the project. A filesystem is probably too shallow if the output from numerous processing steps in one large project is all shoved together in one directory. However, a project directory that involves several analyses of just one data object might not need to be broken down into subdirectories. The filesystem is too deep if versions of output of a process are nested beneath each other or if analyses that require the same level of processing are nested in subdirectories. It's much easier to for you to remember and for others to understand the paths to your data if they clearly symbolize steps in the process you used to do the work.
As you'll see in the upcoming example, your home directory will probably contain a number of directories, each containing data and documentation for a particular project. Each of these project directories should be organized in a way that reflects the outline of the project. Each directory should contain documentation that relates to the data within it.
Unix allows an
almost unlimited variability in file naming. Filenames can contain
any character other than the / or the null
character (the character whose binary representation is all zeros).
However, it's important to remember that some characters, such
as a space, a backslash, or an ampersand, have special meaning on the
command line and may cause problems when naming files. Filenames can
be up to 255 characters in length on most systems. However,
it's wise to aim for uniformity rather than uniqueness in file
naming. Most humans are much better at remembering frequently used
patterns than they are at remembering unique 255-character strings,
after all.
A common convention in file naming is to name the file with a unique name followed by a dot (.) and then an extension that uniquely indicates the file type.
As you begin working with computers in your research and structuring your data environment, you need to develop your own file-naming conventions, or preferably, find out what naming conventions already exist and use them consistently throughout your project. There's nothing so frustrating as looking through old data sets and finding that the same type of file has been named in several different ways. Have you found all the data or results that belong together? Can the file you are looking for be named something else entirely? In the absence of conventions, there's no way to know this except to open every unidentifiable file and check its format by eye. The next section provides a detailed example of how to set up a filesystem that won't have you tearing out your hair looking for a file you know you put there.
Here are some good rules of thumb to follow for file-naming conventions:
Files of the same type should have the same extension.
Files derived from the same source data should have a common element in their unique names.
The unique name should contain as much information as possible about the experiment.
Filenames should be as short as is possible without compromising uniqueness.
You'll probably encounter preestablished conventions for file naming in your work. For instance, if you begin working with protein sequence and structure datafiles, you will find that families of files with the same format have common extensions. You may find that others in your group have established local conventions for certain kinds of datafiles and results. You should attempt to follow any known conventions.
Let's take a look at an example of setting up a filesystem. These are real directory layouts we have used in our work; only the names have been changed to protect the innocent. In this case, we are using a single directory to hold the whole project.
It's useful to think of the filesystem as a family tree,
clustering related aspects of a project into branches. The top level
of your project directory should contain two text files that explain
the contents of the directories and subdirectories. The first file
should contain an outline of the project, with the date, the names of
the people involved, the question being investigated, and references
to publications related to this project. Tradition suggests that such
informational files should be given a name along the lines of
README or 00README. For
example, in the shards project, a minimal
README file might contain the following:
98-05-22 Project: Shards Personnel: Per Jambeck, Cynthia Gibas Question: Are there recurrent structural words in the three-dimensional structure of proteins? Outline: Automatic construction of a dictionary of elements of local structure in proteins using entropy maximization-based learning.
The second file should be an index file (named something readily
recognizable like INDEX ) that explains the
overall layout of the subdirectories. If you haven't really
collected much data yet, a simple sketch of the directories with
explanations should do. For example, the following file hierarchy:
98-03-22 PJ Layout of the Shards directory (see README in subdirectories for further details) /shards /shards/data /shards/data/sequences /shards/data/structures /shards/data/results /shards/data/results/enolases /shards/data/results/globins /shards/data/test_cases /shards/graphics /shards/text /shards/text/notebook /shards/text/reports /shards/programs /shards/programs/source /shards/programs/scripts /shards/programs/bin
may also be represented in graphical form, as shown in Figure 4-1.
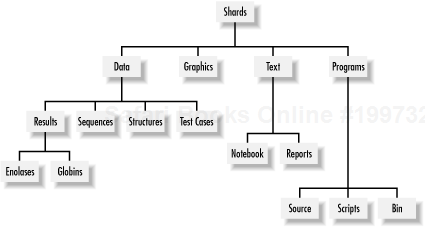
In this directory, we've made the first distinction between
programs and data (programs contains the
software we write, and data contains the
information we get from databases, or files the programs generate).
Within each subdirectory, we further distinguish between types of
data (in this case, protein structures and
protein sequences), and results (run on two sets
of proteins, the enolase family and the
globin superfamily) gleaned from running our
programs on the data, and some test cases. Programs are also
subdivided according to types, namely whether they are the
human-readable program listings (source code), scripts that aid in
running the programs, or the binaries of the programs.
As we mentioned earlier, when you store data in files, you should try
to use a terse and consistent system for naming files. Excessively
long filenames that describe the exact contents of a file but change
for different file types (like
all-GPCR-loops-in-SWISSPROT-on-99-7-14.text)
will cause problems once you start using the facilities Unix provides
for automatically searching for and updating files. In the
shards project, we began with protein structures
taken from the Protein Data Bank (PDB). We then used a homegrown Perl
program called unique.pl to generate a
nonredundant database, in which no protein's sequence had
greater than 25% similarity to any other protein in the set. Thus, we
can represent this information economically using the filename
PDB-unique-25 for files related to this data
set. For example, the list of the names of proteins in the set, and
the file containing the proteins' sequences in FASTA format (a
common text-file format for storing macromolecular sequence data),
are stored, respectively, in:
PDB-unique-25.list PDB-unique-25.fasta
Files containing derived data can be named consistently as well. For
example, the file containing all seven-residue pieces of protein
structure derived from the nonredundant set is called
PDB-unique-25-7.shard. This way, if you need to
do something with all files pertaining to this nonredundant database,
you can use the wildcard PDB-unique-25*,
ignoring databases generated by different programs or those generated
with unique.pl at different similarity
thresholds.
File naming conventions can take you only so far in organizing a project; the simple naming schemes we've laid out here will become more and more confusing as a project grows. For larger projects, you should consider using a database management system (DBMS) to manage your data. We introduce database concepts in Chapter 13.
Now that you have the basics of filesystems, let's dig into the specifics of working with files and directories in Unix. In the following sections, we cover the Unix commands for moving around the filesystem, finding files and directories, and manipulating files and directories.
As we introduce commands, we'll show you the format of the
command line for each command (for example, "Usage:
man
name"), and
describe the effects of some options we find most useful.
When you open a window on a Linux system, you see a command prompt:
$
Command prompts can look different depending on the configuration of
your system and your shell. For example, the following user is using
the tcsh shell environment and has configured
the command prompt to show the username and current working
directory:
[cgibas@gibas ~]$
Whatever the style of the command prompt, it means that your computer is waiting for you to tell it to do something. If you type an instruction at the prompt and press the Enter key, you have given your computer a command. Unix provides a set of simple navigation commands and commands for searching your filesystem for particular files and programs. We'll discuss the format of commands more thoroughly in Chapter 5. In this chapter, we'll introduce you to basic commands for getting around in Unix.
pwd
stands for
"print working directory," and that's exactly what
it does. pwd sends the full pathname of the
directory you are currently in, the current working directory, to
standard output—it prints to the screen. You can think of being
"in" a directory in this way: if the directory tree is a
map of the filesystem, the current working directory is the
"you are here" pointer on the map.
When you log in to the system, your "you are here"
pointer is automatically placed in your home
directory
. Your home directory is a unique
place. It contains the files you use almost every time you log into
your system, as well as the directories that you create to store
other files. What if you want to find out where your home directory
is in relation to the rest of the system? Typing
pwd at the command prompt in your home directory
should give output something like:
/home/jambeck
This means that jambeck 's home directory
is a subdirectory of the home directory, which in turn is a
subdirectory of the root ( / ) directory.
Usage: cd
pathname
|
The cd
command[†] changes the current working
directory. The only argument commonly used with this command is the
pathname of a directory. If cd is used without
an argument, it changes the current working directory to the
user's home directory.
In order for these "you are here" tools to be helpful, you need to have organized your filesystem in a sensible way in the first place, so that the name and location of the directory that you're in gives you information about what kind of material can be found there. Most of the filesystem of your machine will have been set up by default when you installed Linux, but the organization of your own directories, where you store programs and data that you use, is your responsibility.
Unix provides many ways to find files, from simply listing out the contents of a directory to search programs that look for specified filenames and the locations of executable programs.
Usage: ls
[
-
options
]
pathname
|
Now that you know where you are, how do you find out what's
around you? Simply typing the Unix list command,
ls
, at the prompt gives you a listing of
all the files and subdirectories in the current working directory.
You can also give a directory name as an argument to
ls. It then prints the names of all files in the
named directory.
If you have a directory that contains a lot of files, you can use
ls combined with the wildcard character *
(asterisk) to produce a partial listing of files. There are several
ways to use the *. If you have files in a series (such as
ch1 to ch14 ), or files
with common characters (like those ending in
.txt), you can use * to specify all of them at
once. When given as the argument in a command, * takes the place of
any number of characters in a filename. For example, let's say
you're looking for files called seq11,
seq25, and seq34 in a
directory of 400 files. Instead of scrolling through the list of
files by eye, you could find them by typing:
% ls seq*
What if in that same directory you wanted to find all the text files?
You know that text files usually end with .txt,
so you can search for them by typing:
% ls *.txt
There are also a variety of command-line options to use with
ls. The most useful of these are:
- -a
Lists all the files in a directory, even those preceded by a dot. Filenames beginning with a dot (.) aren't listed by
lsby default and consequently are referred to as hidden files. Hidden files often contain configuration instructions for programs, and it's sometimes necessary to examine or modify them.- -R
Lists subdirectories recursively. The content of the current directory is listed, and whenever a subdirectory is reached, its contents are also explicitly included in the listing. This command can create a catalog of files in your filesystem.
- -1
Lists exactly one filename per line, a useful option. A single-column listing of all your source datafiles can quickly be turned into a shell script that executes an identical operation on each file, using just a few regular-expression tricks.
- -F
Includes a code indicating the file type. A / following the filename indicates that the file is a directory, * indicates that the file is executable, and @ following the filename indicates that the file is a symbolic link.
- -s
Lists the size of the file in blocks along with the filename.
- -t
Lists files in chronological order of when they were last modified.
- -l
Lists files in the long format.
- - - color
Uses color to distinguish different file types.
ls
gives its output in two formats, the short
and the long format. The short format is the default. It includes
only the name of each file along with information requested using the
-F or -s options:
#corr.pl# commands.txt hi.c psimg.c #eva.pl# corr.pl nsmail res.sty #pitch.txt# corr.pl~ paircount.pl res.sty~ #wish-list.txt# correlation.pl paircount.pl~ resume.tex Xrootenv.0 correlation.pl~ pj-resume.dvi seq-scratch.txt a.out detailed-prac.txt pj-resume.log sources.txt
The long format of the ls command output
contains a variety of useful information about file ownership and
permissions, file sizes, and the dates and times that files were last
modified:
drwxrwxr-x 4 jambeck weasel 2048 Mar5 18:23 ./ drwxr-xr-x 5 root root 1024 Jan 20 12:13 ../ -rw-r--r-- 1 jambeck weasel 293 Jan 28 17:39 commands.txt -rw-r--r-- 1 jambeck weasel 1749 Feb 21 12:43 corr.pl -rw-r--r-- 1 jambeck weasel 559 Feb 23 14:52 correlation.pl -rwxr-xr-x 1 jambeck weasel 3042 Jan 21 17:05 eva.pl* drwx------ 2 jambeck weasel 1024 Feb 16 14:44 nsmail/
This listing was generated with the command ls
-alF. The first 10 characters in the line give information
about file permissions. The first character describes the file type.
You will commonly encounter three types of files: the ordinary file
(represented by -), the directory (d ), and the
symbolic link (l ).
The next nine characters are actually three sets of three bits
containing file permission information. The first three characters
following the file type are the file permissions for the user. The
next set are for the user's group, and the final set are for
users outside the group. The character string
rwxrwxrwx indicates a file is readable
(r ), writable (w), and
executable (x ) by any user. We talk about how
to change file permissions and file ownership in Section 4.3.3.2.
The next column in the long format file listing tells you how many links a file has; that is, how many directory listings for that file exist on the filesystem. The same file can be named in multiple directories. In the section Section 4.2.3, we talk about how to create links (directory listings) for new and existing files.
The next two columns show the ownership of the file. The owner of the
files in the preceding example is jambeck , a
member of the group weasel.
The next three columns show the size of the file in characters, and the date and time that the file was last modified. The final column shows the name of the file.
Usage: find
pathname
list
-[test] criterion
|
The find
command is one of the most powerful,
flexible, and complicated commands in the standard set of Unix
programs. find searches a path or paths for
files based on various tests. There are over 20 different tests that
can be used with find; here are a few of the
most useful:
This test is always
trueand sends the pathname of the current file to standard output.-printshould be the last command specified in a line, because, as it's alwaystrue, it causes every file in the pathname being searched to be sent to the list if it comes before other tests in a sequence.- -name
This is the test most commonly applied with
findand the one that is the most immediately useful.find -name weasel.txt -printlists to standard output the full pathnames of all files on the filesystem namedweasel.txt. The wildcard operator * can be used within the filename criterion to find files that match a given substring.find-name weas* -printfinds not onlyweasel.txt,butweasel.candweasel.- -user uname
This test finds all files owned by the specified user.
- -group gname
This test finds all files owned by the specified group.
- -ctime n
This test is
trueif the current file has been changed n days ago. Changing a file refers to any change, including a change in permissions, whereas modification refers only to changes to the internal text of the file.-atimeand-mtimetests, which check the access and modification times of the files, are also available.
Performing two find tests one after another
amounts to applying a logical "and" between the tests. A
-o between tests indicates a logical
"or." A slash ( / ) negates a
command, which means it finds only those files that fail the test.
find can be combined with other commands to
selectively archive or remove particular files from a filesystem.
Let's say you want a list of every file you have modified in
your home directory and all subdirectories in the last week:
% find ~ -type f -mtime -7 -print
Changing the type to d shows only new
directories; changing the -7 to +7 shows all files modified more than
a week ago. Now let's go back to the original problem and find
executable files. One way to do this with find
is to use the following command:
% find / -name progname -type f -exec ls -alF '{' ';' This example finds every match for progname and
executes ls -alF
FullPathName for every match. Any Unix command
can be used as the object of -exec. Cleanup of
the /tmp directory, which is usually done
automatically by the operating system, can be done with this command:
find /tmp -type f -mtime +1 -exec rm -rf '{' ';' This deletes everything that hasn't been modified within the last day. As always, you need to refer to your manual pages, or manpages, for more details (for more on manpages, see Chapter 5).
Usage: which
progname
|
The which
command searches your current path and
reports the full path of the program that executes if you enter
progname at the command prompt. This is useful
if you want to know where a program is located, if, for instance, you
want to be sure you're using the right version of the program.
which can't find a program in a directory
that isn't in your path.
Usage: whereis
-
[
options
]
progname
|
The whereis
command searches a standard set of
directories for executables, manpages, and source files. Unlike
which, whereis isn't
dependent on your path, but it looks for programs only in a limited
set of directories, so it doesn't give a definitive answer
about the existence of a
program.
Of course, just as with the stacks of papers on your desk, you periodically need to do some housekeeping on your files and directories to keep everything neat and tidy. Unix provides commands for moving, copying, and deleting files, as well as creating and removing directories.
Usage: cp
-
[
options
]
source
destination
|
The cp
command makes a copy of a source file at
a destination. If the destination is a directory, the source can be
multiple files, copies of which are placed in the destination
directory. Frequently used options are -R and
-r. Both copy recursively; that is, they copy
the source directory and all its subdirectories to the destination.
The -R option prevents cp
from following symbolic links; only the link itself is copied. The
-r option allows cp to
follow symbolic links and copy all files it finds. This can cause
problems if the symbolic links happen to form a circular path through
the filesystem.
Normally, new files created by cp get their file
ownership and permissions from your shell settings. However, the
POSIX version of cp provides an
-a option that attempts to maintain the original
file attributes.
Usage: mv
source
destination
|
The mv
command simply moves or renames
source to destination.
Files and directories can both be either source
or destination. If both
source and destination are
files or both are directories, the result of mv
is essentially that the file or directory is renamed. If the
destination is a directory, and the intention is
to move already existing files or directories under that directory in
the hierarchy, the directory must exist before the
mv command is given. Otherwise the
destination is created as a regular file, or the
operation is treated as a renaming of a directory. One problem that
can occur if mv isn't used carefully is
when source represents a file list, and
destination is a preexisting single file. When
this happens, each member of source is renamed
to destination and then promptly overwritten,
leaving only the last file of the list intact. At this point,
it's time to look for your system administrator and hope there
is a recent backup.
Usage: ln
-[
options
]
source
destination
|
The ln
command establishes a link between files
or directories at different locations in the directory tree. While
creating a link creates the appearance of a new file in the
destination location, no data is actually copied. Instead,
what's created is a new pointer in the filesystem index that
allows the source file to be found at more than
one location "on the map."
The most commonly used option, -s, creates a
symbolic link (or
symlink) to a file or directory, as in the
following example:
% ln -s perl5.005_03 perl
This allows you to type in just the word perl
rather than remembering the entire version nomenclature for the
current version of Perl.
Another common use of the ln command is to
create a link to a newly compiled binary executable file in a
directory in the system path, e.g.,
/usr/local/bin. Doing this allows you to run the
program without addressing it by its full pathname.
Usage: mkdir
-[
options
]
dirname
|
Usage: rmdir
-[
options
]
dirname
|
New directories can be created with the
mkdir
command, which has only two command-line
options.
mkdir -p creates a directory and any
intermediate components of the path that are missing. For instance,
if user jambeck decides to create a directory
mustelidae/weasels in his home directory, but
the intermediate directory mustelidae
doesn't exist, mkdir -p creates the
intermediate directory and its subdirectory
weasels.
mkdir -m mode creates a directory with the
specified file-permission mode.
rmdir removes a directory if it's empty.
With the -p option, rmdir
removes all the empty directories in a given path. If user
jambeck decides to remove the directory
mustelidae/weasels, and directory
mustelidae is empty except for directory
weasels, rmdir -p
~/mustelidae/weasels removes both
weasels and its parent directory
mustelidae.
Usage: rm
-[
options
]
files
|
The rm
command removes files and directories.
Here are its common options:
- -f
Forces the removal of files without prompting. You still can't remove files you don't own, but the write permissions on files you do own are ignored. For example,
rm -f a*deletes all files starting with the letter a, but doesn't delete any subdirectories.- -i
Prompts you with
rm: remove filename?Files are removed only if you begin your answer with ayorY.- -r
(recursive option) Removes all directories and subdirectories in the list of files. Symbolic links aren't traversed; only the symlink itself is removed.
- -v
(verbose option) Echoes the names of all files/directories that are removed.
While rm is a fairly simple command, there are a
few instances in which it can cause serious problems for the careless
user.
The command rm * removes all files in a
directory. Unless you have the files set as read-only or have the
interactive flag set, you will delete everything in the directory. Of
course this isn't as bad as using the command rm
-r
* or rm -rf
*, the last of which overrides any read-only file modes,
traverses down through your directories and deletes everything in
your current directory or below.
Occasionally you will find that you create odd files in your
directories. For instance, you might have a file named
-myfile where the - is part of the filename. Try
deleting it, and you will get an error message concerning the fact
that rm doesn't have a
-m option. Your shell program interprets the
-m as a command flag, not part of the filename.
The solution to this problem is trivial but not always instantly
apparent: simply provide a more complete path to the file, such as
rm ./-myfile or rm
/home/jambeck/-myfile. Similar solutions are needed if you
accidently create a file with a space in
the
name.
Unix systems are designed to allow multiple users to share system resources and software, yet at the same time to allow users to selectively protect their work from each other. To work with others in a multiuser environment, there are a number of general Unix concepts you need to understand.
If you
use a Unix system, you must be
registered. You are identified by a login name and can log in only by
entering the password uniquely associated with your login name. You
have control over an area of the filesystem, which may be as large or
small as system resources allow. You belong to one or more groups and
can share files with other members of a group without needing to make
the files accessible to other users. At any given time, only one of a
your groups is active, and new files you create are automatically
associated with the active, or primary, group. If you use group
permissions to share files with other users, and you need to change
to a particular group ID, the command
newgrp
allows you to change your primary group
ID. The id
command tells you what your user and
primary group IDs are.
Information about your account is stored the
/etc/passwd file, a file that provides the
system with information needed when you log in. Your username and
user ID mapping are found here, along with your default groups, full
name, home directory and default shell program. The shell program is
described in Chapter 5. The encrypted version of
your password used to be stored here, but on most systems, for
security reasons, the actual password has been removed from the
passwd file. Additional group information is
found in the /etc/group file. You can view the
contents of these files with an editor, even though they are system
files you normally can't overwrite.
When
your system
administrator creates a new user account, the process includes
creating an entry in the /etc/passwd file,
possibly adding you to a number of groups in
/etc/group, creating a home directory for you
somewhere on the system, and then changing the ownership of that
directory so that you own it and any files that are put into it at
the time of creation. Your entry in /etc/passwd
needs to match the path to your home directory, and the user and
group that own your home directory. There should also be a set of
files in your home directory that set up your work environment when
you log in and are specific to the Unix shell listed in your
passwd entry. These files are discussed in more
detail in Chapter 5.
As
we
discussed in the section on the
ls
command, each file and directory
has an owner and a group with which it's associated. Each file
is created with permissions that allow or
prevent you access to the file dependent on your user ID and group.
In this section we discuss how to view and change file permissions
and ownership.
Usage: stat
-[
options
]
filename
|
stat
lets you view the complete set of
attributes of a file or directory, including permissions,
modification times, and ownership. It may be more information than
you need, but it's there if you want it. For example, the
command stat image1.rgb returns:
image1.rgb: inode 11750927; dev 77; links 1; size 922112 regular; mode is rw-------; uid 12430 (jambeck); gid 280 (weasel) projid 0 st_fstype: xfs change time - Sun Mar 14 14:21:50 1999 <921442910> access time - Sat Mar 13 18:11:21 1999 <921370281> modify time - Sat Mar 13 10:28:39 1999 <921342519>
On most Unix systems, you wouldn't want every file to be
readable, writable, and executable by every user. The
chmod
command
allows you to set the file permissions, or mode,
on a list of files and directories. The recursive option,
-R, causes chmod to descend
recursively through a directory tree and change the mode of the files
and directories.
For example, a long directory listing for a directory, a symlink, and a file looks like this:
drwxr-xr-x 7 jambeck weasel 2048 Feb 10 19:08 image/ lrwxr-xr-x 1 jambeck weasel 10 Mar 14 13:12 image.rgb-> image1.rgb -rw-r--r-- 1 jambeck weasel 922112 Mar 13 10:28 image1.rgb
The first character in each line indicates whether the entry is a
file, directory, symlink, or one of a number of other special file
types found on Unix systems. The three listed here are by far the
most common. The remaining nine characters describe the mode of the
file. The mode is divided into three sets of three characters. The
sets correspond—in the following order—to the user, the
group, and other. The user is the account that owns the directory
entry, the group can be any group on the system, and other is any
user that doesn't belong to the set that includes the user and
the group. Within each set, the characters correspond to read
(r ), write (w), and
execute (x) permissions for that person or
group.
In the previous example, to change the mode of the file
image1.rgb so that it's readable only by
the user and modified (writable) by no one, you can issue one of the
following commands:
chmod u-w,g-r,o-r image1.rgb chmod u=r,g=-,o=- image1.rgb chmod u=r,go=- image1.rgb
Any one of these commands results in image1.rgb
's permissions looking like:
-r-------- 1 jambeck weasel 922112 Mar 13 10:28 image1.rgb
The first two commands should be fairly obvious. You can add or subtract user's, group's or other's read, write or execute permissions by this mechanism. The mode parameters are:
- [u,g,o]
User, group, other
- [+,-,=]
Add, subtract, set
- [r,w,x]
Read, write, execute
u, g, and
o can be grouped or used singly. The same is
true for r, w, and
x. The operators +,
-, and = describe the
action that is to be performed.
Usage: chown
-[
options
]
filenames
item
|
Usage: chgrp
-[
options
]
filenames
|
The chown
command lets you change the owner (or,
in file-permission parlance, the user) of a file or directory. The
operation of the chown command is dependent on
the version of Unix you are running. For example, IRIX allows you to
"give" the ownership to someone else, while this is
impossible to do in Linux. We will cite only examples of the
chgrp
command, since in Linux, you can be a
member of two groups and get this command to work for you.
chgrp lets you change the group of a file or
directory. You must be a member of the group the file is being
changed to, so you have to be a member of more than one group and
understand how to use the
newgrp
command (which is described later in
this chapter). Assume for a moment that you created
image/, a directory containing files, while you
were in your default group. Later, you realize that you want to share
these files with members of another group on the system. So, at
first, the permissions look like this:
drwxr-xr-x 7 jambeck weasel 2048 Feb 10 19:08 image/
Change to the other group using the command
newgrp
wombat, then type:
chgrp -R wombat image
to make all files in the directory accessible to the
wombat group. Finally, you should change the
permissions to make the files writable by the
wombat group as well. This is done with the
command:
chmod -R g+w image
Your entry should now appear as follows:
drwxrwxr-x 7 jambeck wombat 2048 Feb 10 19:08 image/
Most files that control the
configuration of the Unix system on your computer are writable only
by the system administrator. Adding and deleting users, backing up
and restoring files, installing new software in shared directories,
configuring the Unix kernel, and controlling access to various parts
of the filesystem are tasks normally handled by one specially
designated user, with the username root. When
you're doing day-to-day tasks, you shouldn't be logged in
as root, because root has privileges ordinary
users don't, and you can inadvertently mess up your computer
system if you have those privileges. Use the
su
command from your command line to assume
system-administration privileges temporarily, do only those tasks
that need to be done by the system administrator, and then exit back
to your normal user status.
If you set up a Unix system for yourself, you need to become the system administrator or superuser and learn to do the various system-administration tasks necessary to maintain your computer in a secure and useful condition. Fortunately, there are several informative reference books on Unix system administration available (several by O'Reilly), and an increasing number of easy-to-use graphical system-administration tools are included in every Linux distribution.
Unix uses a
simple set of designations for the various types of files found on
the system. Normally you can find what you need with
info, find, or
which, but sometimes it's necessary to
search manually, and you don't want to look in
/bin for a library. These designations are used
at the operating-system level, but they are also often used in
project subdirectories or software distributions to separate files:
- bin
Executable files, or binaries
- lib
Libraries, both runtime or shared, and those needed when compiling
- spool
Directories used by the system when communicating with external devices and machines
- tmp
Temporary storage
- src
Source code for programs
- etc
Configuration information
- man
Manual pages, documentation
- doc
Documentation
- X
X or X11R6 refers to X programs, libraries,
src, etc.; directories typically have a fairly complete set of subdirectories
Once you have a basic understanding of how to organize and manage your files and directories, you're well on your way to understanding how to work in a Unix environment. In Chapter 5 we complete our lightning Unix tutorial with a discussion of many of the most commonly used Unix commands. In order to really master the art of Unix, we strongly recommend consulting one or more of the books in the Bibliography.
While all your own files should be created in your home directory or in other areas specifically designated for users to share, you need to be aware of the locations of files in other parts of the system. One benefit of a system environment designed for multiple users is that many users can share common resources while controlling access to their own files.
To say there is a standard Unix filesystem is somewhat of an
overstatement, but, like Plato's vision of the perfect chair,
we will attempt to imagine one out in the ether. Since Linux is being
developed by thousands of programmers on different continents and has
the benefit of the development of both Berkeley and AT&T's
SysV Unix, along with the POSIX standards, we will use the Linux
filesystem as a template and point out major discrepancies when
necessary. The current standard for the Linux filesystem is described
at http://www.pathname.com/fhs/.
Here, we present a brief skeleton of the complete filesystem and
point out a few salient features. Most directories described in this
section are configurable only by the system administrator; however,
as a user, you may sometimes need to know where system files and
programs can be found. Figure 4-2 illustrates the
major subdirectories, which are further described in the following
list.

- /dev
Contains all the device drivers needed to connect peripherals to the system. Drivers for SCSI, audio, IDE drives, PPP, mice, and most other devices are found here. In general there are no user-configurable options here.
- /etc
Houses all the configuration files local to your machine. This includes items such as the system name, Internet address, password file (unless your machine is part of some larger cluster), filesystem information, and Unix initialization information.
- /home
A common, but not standard, part of Unix.
/homeis usually a fairly large, separate partition that houses all user home directories. Having/homeon a separate partition has the advantage of allowing it to be shared in a cluster environment, and it also makes it difficult for users to completely fill an important system partition and cause it to lock up.- /lost+found
A system directory that is a repository for files and directories that have somehow been misplaced by the system. Typically, users can't
cdinto this directory. Files usually end up in thelost+foundbecause of a system crash or a disk problem. At times it's possible that your system administrator can recover files that appear to be lost simply by moving them fromlost+foundand renaming them. There's a separatelost+foundfor each partition on the system.- /mnt
While not found on all systems, this is the typical place to mount any partitions not described by the standard Unix filesystem description. Under Linux, this is where you will find a mounted CD-ROM or floppy drive.
- /nfs
Often used as the top-level directory for any mount points for partitions that are mounted from remote machines.
- /opt
A relatively new addition to the Unix filesystem. This is where optional, usually commercial, packages are installed. On many systems you will find higher-end, optimizing compilers installed here.
- /root
The home directory for root, i.e., for the system administrator when she is logged in as root.
- /sbin, /bin, and /lib
Since the machine may need to start the boot process without the
/usrpartition present, any programs that are using it prior to mounting the/usrpartition must reside on the main or root partition. The contents of the/sbindirectory, for instance, are a subset of the/usr/sbindirectory. Labeling directoriessbinindicates that only system-level commands are present and that normal users probably won't need them, and therefore don't need to include these directories in their path. The/libdirectory is a small subset of system libraries that are needed by programs in/binand/sbin. Current Unix programs use shared libraries, which means that many programs can use functions from the same library, and so the library needs to be loaded into memory only once. What this means for practical purposes is that programs don't take as much memory as they would if each program included all the library routines, and the programs don't actually run if the correct library has been deleted or hasn't been mounted yet.- /tmp and /var/tmp
Typically configured to be readable/writable/executable by all users. Many standard programs, such as
vi, write temporary files to one of these directories while they are running. Normally the system cleans out these directories automatically on a regular basis or when the machine is rebooted. This is a good place to write temporary files, but you can't assume that the system will wait for you to erase them.- /usr
The repository for the majority of programs, compilers, libraries, and documentation for the Unix filesystem. The current recommendation for most Unix systems is that the system should be able to mount
/usras a separate, read-only partition. In a workstation-cluster environment, this means that a server can export a/usrpartition, and all the workstations in that cluster will share the programs. This makes the system administrator's job easier and provides users with a uniform set of machines.- /usr/local
The typical directory in which to install programs and documentation so that they aren't overwritten by the operating system. You will often find programs such as Perl and various others that have been downloaded from the Internet installed in this location.
- /var
The directory used by all system programs that write output to the disk. All system logs, spools, and temporary data are written here. This includes logging information such as that written during the boot process, by the mailer, by the login program, and by all other system processes. Incoming and outgoing mail is stored in the
/var/spooldirectory, as are files being sent to printers. Information needed forcron,batch, andatjobs is also found here.
[*] Throughout this chapter and Chapter 5, we introduce many Unix commands. Our quick and dirty approach to outlining the functions of these commands and their options should help you get started working fast, but it's by no means exhaustive. The Bibliography provides several excellent Unix books that will help you fill in the details.
[†] As you'll see when we cover the Unix shell and the command line in Chapter 5, Unix commands can be issued with or without arguments on the command line. The first word in a line is always a command. Subsequent words are arguments and can include options, which modify the command's behavior, and operands, which specify pathnames. Words in the command line are items separated by whitespace (spaces or tabs).
Get Developing Bioinformatics Computer Skills now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

