The Google Webmaster Tools, explained in the previous section, help give you some notion of Google’s evaluation of your website. But let’s step back for a second and look at some general issues:
Why this evaluation is very important
How you can get a better intuitive feeling for bot evaluation
To state the obvious, before your site can be indexed by a search engine, it has to be found by the search engine. Search engines find websites and web pages using software that follows links to crawl the Web. This kind of software is variously called a crawler, a spider, a search bot, or simply a bot (bot is a diminutive for “robot”).
Note
You may be able to short circuit the process of waiting to be found by the search engine’s bot by submitting your URL or site map directly to search engines, as explained in Chapter 3.
To be found quickly by a search engine bot, it helps to have inbound links to your site. More important, the links within your site should work properly. If a bot encounters a broken link, it cannot reach, or index, the page pointed to by the broken link.
Pictures don’t mean anything to a search bot. The only information
a bot can gather about pictures comes from the file name, from the
alt attribute used within a picture’s
<img> tag, from text
surrounding the picture, and in some cases from the image meta data. Therefore, always take care to
provide description information via alt along with your images and at least one
link (outside of an image map) to all pages on your site.
Note
While effective automated image analysis is still largely in the lab, or in use by the military, its day is coming to the Internet. It’s likely that by the time this book goes into its next edition, Google and others will have added at least rudimentary image recognition features to their bots and crawlers.
Some kinds of links to pages (and sites) simply cannot be traversed by a search engine bot. The most significant issue is that a bot cannot log in to your site. If a site or page requires a username and a password for access, then it probably will not be included in a search index.
Note
Don’t be fooled by seamless page navigation using such techniques as cookies or session identifiers. If an initial login is required, these pages probably cannot be accessed by a bot.
When I was writing the previous edition of this book, there were some issues with search engine navigation of dynamic URLs. Dynamic URLs are generated on the server side from a database, and can often be recognized by characters in the URL such as ?, &, and =. The current word from Google is that there are no problems with dynamic URLs, and it may not be worth creating server-side rules to rewrite dynamic URLs to make them look more like static URLs.
Most search engines and search engine bots are capable of parsing and indexing many different kinds of file formats. For example, Google states: “We are able to index most types of pages and files with very few exceptions. File types we are able to index include: pdf, asp, jsp, html, shtml, xml, cfm, doc, xls, ppt, rtf, wks, lwp, wri, swf.”
However, simple is often better. To get the best search engine placement, you are well advised to keep your web pages, as they are actually opened in a browser, to straight HTML. Note a couple of related issues:
A file with a suffix other than .htm or .html can contain straight HTML. For example, when they are opened in the browser, .asp, .aspx, .cfm, php, and .shtml files often consist of straight HTML (it has, of course, been generated by server-side software).
Scripts (such as a PHP program) or include files (such as an .shtml page) running on your web server usually generate HTML pages that are returned to the browser. This architecture is shown in Figure 4-4. An important implication: check the source file as shown in a browser rather than the script file used to generate a dynamic page to see what the search engine will index.
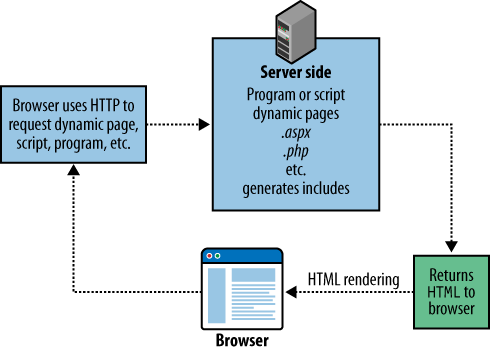
Google puts the “simple is best” precept this way: “If fancy features such as JavaScript, cookies, session IDs, frames, DHTML, or Flash keep you from seeing all of your site in a text browser, then search engine spiders may have trouble crawling your site.” The only way to know for sure whether a bot will be unable to crawl your site is to check your site using an all-text browser.
So go ahead, find out for sure. View your site in an all-text browser. It’s easy. And fun.
Improvement implies a feedback loop: you can’t know how well you are doing without a mechanism for examining your current status. The feedback mechanism that helps you improve your site from an SEO perspective is to view it as the bot sees it. While information shown by the Google Webmaster Tools and other helpers is useful, nothing beats a text-only view of your site.
This means viewing the site using a text-only browser. A text-only browser, just like the search engine bot, will ignore images and graphics and only process the text on a page.
The best-known text-only web browser is Lynx. You can find more information about Lynx at http://lynx.isc.org/. Generally, the process of installing Lynx involves downloading source code and compiling it.
Don’t want to get into compiled source code or figuring out which idiosyncratic Lynx build to download? There is a simple Lynx Viewer available on the Web at http://www.delorie.com/web/lynxview.html.
All you have to do is navigate to this page in your browser and submit the URL for your site. The text view of the page you’ll see (Figure 4-5) is starkly simpler than the comparable fully rendered view with images and graphics (Figure 4-6). The contrast may be a real eye opener. You should take the time to “crawl” the text link in your site to understand site navigation as well as page appearance from the bot’s viewpoint.
Get Google Advertising Tools, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

