Preface
Todayâs most advanced computing technology exists in large buildings containing vast arrays of low-cost servers. Enormous computing resources are housed in well-fortified, secure areas, maintained by teams of highly trained technicians. The photograph in Figure P-1 depicts Googleâs 115,000-square-foot data center in Council Bluffs, Iowa, taken from an interactive website describing Googleâs amazing network of data centers (see http://www.google.com/about/datacenters/gallery).

Figure P-1. Google Data Center (Photograph by Google/Connie Zhou)
In the mainframe era, if you outgrew the capacity of a single computer, you needed to come up with millions of dollars to buy another computer. Modern data centers achieve scalable capacity by allocating tasks across large numbers of commodity servers. In the data center era, you allocate as many inexpensive servers as you need and then relinquish those resources when youâre done.
Until recently, data center resources were accessible by the few engineers fortunate enough to work for a new generation of technology companies. However, over the past few years, a revolution has taken place. Just as earlier revolutions in computer hardware made it feasible for more people to access larger numbers of smaller computers, cloud computing enables even greater access, via the public Internet, to vast clusters of computers in modern state-of-the-art data centers. And just as it did in the past, this expanded accessibility is stimulating tremendous innovation.
In its short history, Google has pioneered many of the techniques and best practices used to build and manage cloud computing services. From Search to Gmail to YouTube to Maps, Google services provide secure, scalable, reliable cloud computing to millions of users and serve billions of queries every day. Now, with Google Compute Engine, the infrastructure that supports those services is available to everyone.
Compute Engine offers many advantages: leading-edge hardware, upgraded regularly and automatically; virtually unlimited capacity to grow or shrink a business on demand; a flexible charging model; an army of experts maintaining computing and networking resources; and the ability to host your resources in a global network engineered for security and performance.
This book provides a guided tour of Google Compute Engine, with a focus on solving practical problems. At a high level, Google Compute Engine is about giving you access to the worldâs most advanced network of data centersâthe computing resources that power Google itself. Practically speaking, this means providing APIs, command-line tools and web user interfaces to use Googleâs computing and networking resources.
In succeeding chapters, weâll explain the detailed product capabilities, along with some best practices for getting the most out of Google Compute Engine. Weâll provide numerous examples, illustrating how to access Compute Engine services using all of the supported access methods. Although the programming examples in this book are all written in a combination of Python and JavaScript, the underlying RESTful API and the concepts presented are language independent.
Contents of This Book
Figure P-2 shows how all of Compute Engineâs components fit together. At a high level, Compute Engine instances, networks, and storage are all owned by a Compute Engine project. A Compute Engine project is essentially a named collection of information about your application and acts as a container for your Compute Engine resources. Any Compute Engine resources that you create, such as instances, networks, and disks, are associated with, and contained in, your Compute Engine project. The API offers a way to interact with Compute Engine components and resources programmatically.
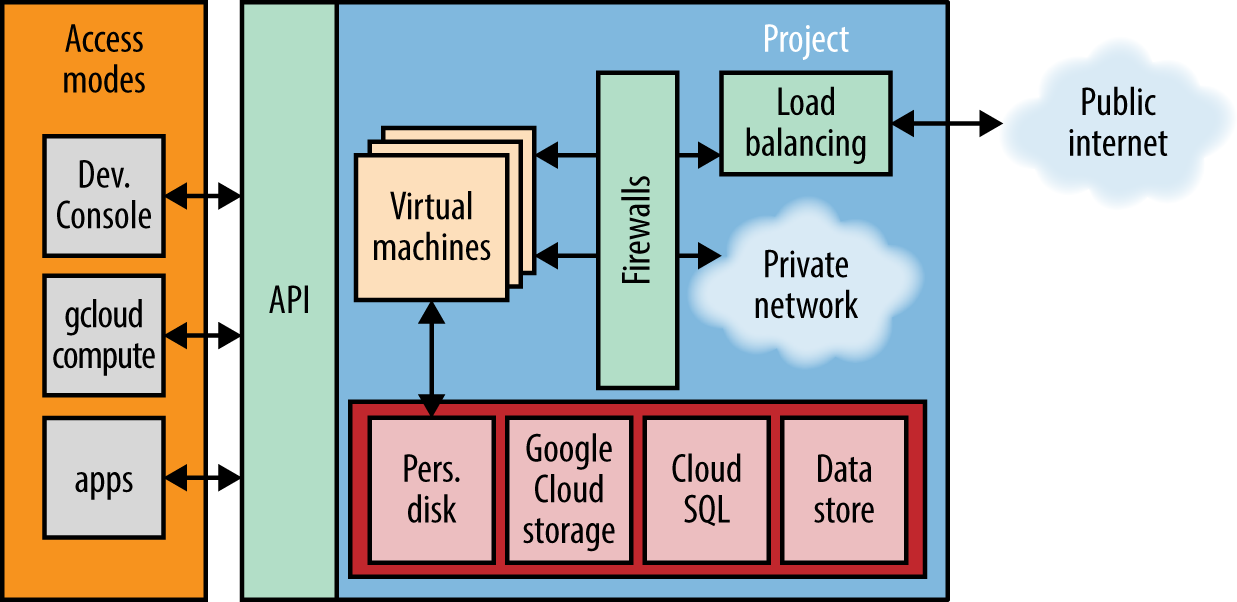
Figure P-2. Overview of Google Compute Engineâs components
Weâll explore the following Google Compute Engine components and resources:
-
Projects, access modes, and the API (Chapter 1)
-
Virtual machines (Chapter 2 and Chapter 7)
-
Persistent disk (Chapter 3)
-
Google Cloud Storage (Chapter 4)
-
Cloud SQL and Cloud Datastore (Chapter 5)
-
Firewalls, load balancing, and the private network (Chapter 6)
-
A complete application (Chapter 8)
What Each Chapter Covers
- Chapter 1, Getting Started
- Weâll take a look at how to get started using Compute Engine. We begin by creating a Compute Engine project using the Google Developers Console, a web UI. We then explore various means of accessing and managing Compute Engine resources via the Developers Console;
gcloud compute, a command-line interface; and the Compute Engine API, a RESTful interface. - Chapter 2, Instances
- Instances are customizable Linux machines and represent the core of Google Compute Engine. You have root access to any instance you create, which allows you to download and install packages and customize disk, hardware, or other configuration options. Chapter 2 covers the basics of working with Compute Engine instances and explains instance attributes in detail.
- Chapter 3, Storage: Persistent Disk; Chapter 4, Storage: Cloud Storage; and Chapter 5, Storage: Cloud SQL and Cloud Datastore
-
Most applications require a location for storing their data. The storage available to Compute Engine comes in many flavors, including persistent disks, Google Cloud Storage, Cloud SQL, and Cloud Datastore.
As the name implies, a persistent disk stores data beyond the life of any associated instance(s). Cloud Storage allows you to store, access, and manage objects of any size on Googleâs infrastructure. Cloud Storage offers an excellent option for highly durable, high availability data storage. Your data is accessible both inside and outside the scope of Compute Engine via a variety of mechanisms and tools, including the Developers Console, the
gsutilcommand, and the Cloud Storage API.Cloud SQL provides a MySQL service in the cloud, managed by Google, while Cloud Datastore provides a Google scale NoSQL data service. Both of these services are available inside and outside the scope of Compute Engine.
Chapter 3, Chapter 4, and Chapter 5 explain all of these storage options in depth, and provide detailed examples illustrating how to exercise all supported access methods.
- Chapter 6, Networking
- Every project has its own private network with an integrated DNS service, numbering plan, and routing logic. A project can have multiple networks, and each network can include multiple instances. Firewall rules can be applied to a network to allow or prohibit incoming traffic to any or all instances and the internet. Load balancing provides advanced and responsive scalable traffic distribution. Chapter 6 provides a short primer on TCP/IP networking and covers Compute Engineâs advanced networking features in depth.
- Chapter 7, Advanced Topics
- In Chapter 7, weâll cover a variety of advanced topics that provide additional ways to customize your Compute Engine resources. Topics include custom images, startup scripts, and the metadata server.
- Chapter 8, A Complete Application
In Chapter 8, we present a guided tour of an application that ties together several of the topics covered earlier. Using an example application, this chapter builds a simple but comprehensive cloud computing application, step by step.
Conventions Used in This Book
The following typographical conventions are used in this book:
- Italic
-
Indicates new terms, URLs, email addresses, filenames, and file extensions.
Constant width-
Used for program listings, as well as within paragraphs to refer to program elements such as variable or function names, databases, data types, environment variables, statements, and keywords.
Constant width bold-
Shows commands or other text that should be typed literally by the user.
Constant width italic-
Shows text that should be replaced with user-supplied values or by values determined by context.
Tip
This element signifies a tip or suggestion.
Note
This element signifies a general note.
Warning
This element indicates a warning or caution.
Using Code Examples
This book is here to help you get your job done. In general, if example code is offered with this book, you may use it in your programs and documentation. You do not need to contact us for permission unless youâre reproducing a significant portion of the code. For example, writing a program that uses several chunks of code from this book does not require permission. Selling or distributing a CD-ROM of examples from OâReilly books does require permission. Answering a question by citing this book and quoting example code does not require permission. Incorporating a significant amount of example code from this book into your productâs documentation does require permission.
We appreciate, but do not require, attribution. An attribution usually includes the title, author, publisher, and ISBN. For example: âBook Title by Some Author (OâReilly). Copyright 2012 Some Copyright Holder, 978-0-596-xxxx-x.â
If you feel your use of code examples falls outside fair use or the permission given above, feel free to contact us at permissions@oreilly.com.
Safari® Books Online
Safari Books Online is an on-demand digital library that delivers expert content in both book and video form from the worldâs leading authors in technology and business.
Technology professionals, software developers, web designers, and business and creative professionals use Safari Books Online as their primary resource for research, problem solving, learning, and certification training.
Safari Books Online offers a range of plans and pricing for enterprise, government, education, and individuals.
Members have access to thousands of books, training videos, and prepublication manuscripts in one fully searchable database from publishers like OâReilly Media, Prentice Hall Professional, Addison-Wesley Professional, Microsoft Press, Sams, Que, Peachpit Press, Focal Press, Cisco Press, John Wiley & Sons, Syngress, Morgan Kaufmann, IBM Redbooks, Packt, Adobe Press, FT Press, Apress, Manning, New Riders, McGraw-Hill, Jones & Bartlett, Course Technology, and hundreds more. For more information about Safari Books Online, please visit us online.
How to Contact Us
Please address comments and questions concerning this book to the publisher:
- OâReilly Media, Inc.
- 1005 Gravenstein Highway North
- Sebastopol, CA 95472
- 800-998-9938 (in the United States or Canada)
- 707-829-0515 (international or local)
- 707-829-0104 (fax)
We have a web page for this book, where we list errata, examples, and any additional information. You can access this page at http://shop.oreilly.com/product/0636920028888.do.
To comment or ask technical questions about this book, send email to bookquestions@oreilly.com.
For more information about our books, courses, conferences, and news, see our website at http://www.oreilly.com.
Find us on Facebook: http://facebook.com/oreilly
Follow us on Twitter: http://twitter.com/oreillymedia
Watch us on YouTube: http://www.youtube.com/oreillymedia
Acknowledgments
Marc, Kathryn, and Paul would like to thank their expert editor, Rachel Roumeliotis, for her patience and guidance throughout this project. Theyâd also like to thank their many helpful reviewers and colleagues, who provided invaluable feedback on many revisions: Andrew Kadatch, Ankur Parikh, Benson Kalahar, Dan Miller, Danielle Aronstam, Dave Barth, Elizabeth Markman, Eric Johnson, Greg DeMichillie, Ian Barber, Jay Judkowitz, Joe Beda, Joe Faith, Johan Euphrosine, Jonathan Burns, Julia Ferraioli, Laurence Moroney, Martin Maly, Mike Trinh, Nathan Herring, Nathan Parker, Phun Lang, Rebecca Ward, Renny Hwang, Scott Van Woudenberg, Simon Newton, and Sunil James.
Marc would like to thank his dedicated, talented, and supportive coauthors for their hard work and inspiration. Marc is also grateful for the love and support of his family, including his wife Kimberly and daughter Maya, who tolerated many long hours spent completing this project.
Kathryn would like to thank her husband, James, and daughter, Violet, for their love and support and her coauthors, Marc and Paul, for being awesome.
Paul would like to thank Marc and Kathryn for the opportunity to collaborate on this project, even though he got to the party late.
Get Google Compute Engine now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

