Chapter 6. How MapReduce Works
In this chapter, we look at how MapReduce in Hadoop works in detail. This knowledge provides a good foundation for writing more advanced MapReduce programs, which we will cover in the following two chapters.
Anatomy of a MapReduce Job Run
You can run a MapReduce job with a single line of code:
JobClient.runJob(conf).
It’s very short, but it conceals a great deal of processing behind the
scenes. This section uncovers the steps Hadoop takes to run a
job.
The whole process is illustrated in Figure 6-1. At the highest level, there are four independent entities:
The client, which submits the MapReduce job.
The jobtracker, which coordinates the job run. The jobtracker is a Java application whose main class is
JobTracker.The tasktrackers, which run the tasks that the job has been split into. Tasktrackers are Java applications whose main class is
TaskTracker.The distributed filesystem (normally HDFS, covered in Chapter 3), which is used for sharing job files between the other entities.
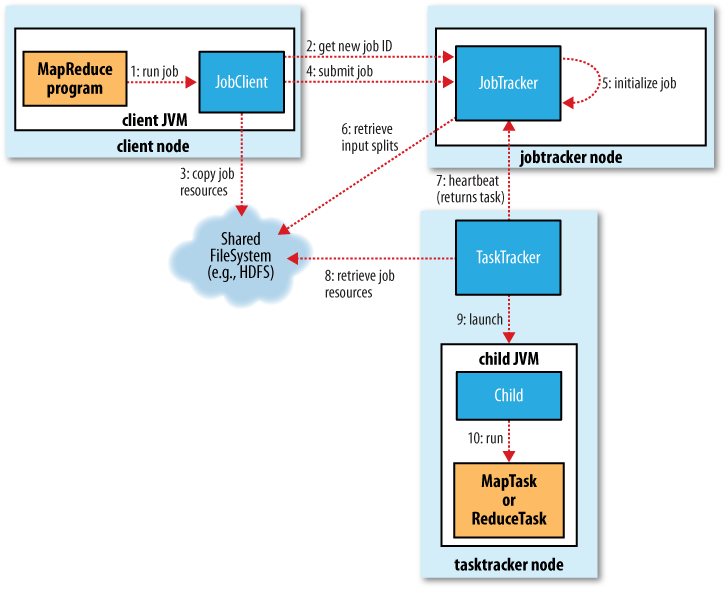
Figure 6-1. How Hadoop runs a MapReduce job
Job Submission
The runJob() method
on JobClient is a convenience
method that creates a new JobClient instance and
calls submitJob() on it (step 1 in
Figure 6-1). Having submitted
the job, runJob() polls the job’s progress once a second and reports the progress to the console if it has changed since the last report. When the job is complete, ...
Get Hadoop: The Definitive Guide, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

