When XML first appeared, people widely believed that it was the imminent successor to HTML. This viewpoint was influenced by a variety of factors, including media hype, wishful thinking, and simple confusion about the number of new technologies associated with XML. The reality is that millions of web sites are written in HTML, and no widely used browser fully supports XML and its related standards. Even when browser vendors incorporate full support for XML and its family of related technologies, it will take years before enough people use these new versions to justify rewriting most web sites in XML. Although maintaining compatibility with older browsers is essential, companies should not hesitate to move forward with XML and related technologies on the server.
From the browser perspective, HTML will remain dominant on the Web for many years to come. Looking beneath the hood will reveal a much different picture, however, in which HTML is used only during the last instant of presentation. Web applications must support a multitude of browsers, and the easiest way to do this is to simply transform data into HTML before sending it to the client. On the server side, XML is the preferred way to process and exchange data because it is portable, standard, and easy to work with. This is where Java and XSLT enter the picture.
Extensible Stylesheet Language Transformations (XSLT) is designed to transform XML data into some other form, most commonly HTML, XHTML, or another XML format. An XSLT processor , such as Apache’s Xalan, performs transformations using one or more XSLT stylesheets , which are also XML documents. As Figure 1-1 illustrates, XSLT can be utilized on the web tier while web browsers on the client tier deal only with HTML.
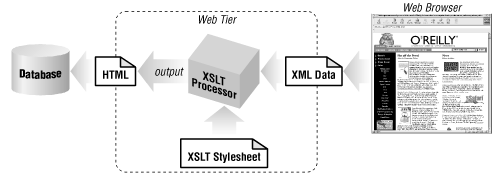
Typically in an XSLT- and Java-based web application, XML data is generated dynamically based on database queries. Although some newer databases can export data directly as XML, you will often write custom Java code to extract data using JDBC and convert it to XML. This XML data, such as a customized list of benefit elections or perhaps an airline schedule for a specific time window, may be different for each client using the application. In order to display this XML data on most browsers, it must first be converted to HTML. As Figure 1-1 shows, the XML data is fed into the processor as one input, and an XSLT stylesheet is provided as a second input. The output is then sent directly to the web browser as a stream of HTML. The XSLT stylesheet produces HTML formatting instructions, while the XML provides raw data.
One of the fundamental problems with HTML is its haphazard implementation. Although the specification for HTML is available from the World Wide Web Consortium (W3C), its evolution was driven mostly by competition between Netscape and Microsoft rather than a thoughtful design process and open standards. This resulted in a bloated language littered with browser-specific tags and varying support for standards. Since no two browsers support the exact same set of HTML features, web authors often limit themselves to a subset of HTML. Another approach is to create and maintain separate copies of each web page, which take advantage of the unique features found in a particular browser. The limitations of HTML are compounded for dynamic sites, in which Java programs are often responsible for accessing enterprise data sources and presenting that information through the browser.
Extracting information from back-end data sources is much more difficult than simple web page authoring. This requires skilled developers who know how to interact with Enterprise JavaBeans or relational databases. Since skilled Java developers are a scarce and expensive resource, it makes sense to let them work on the back-end data sources and business logic while web page developers and less experienced programmers work on the HTML user interface. As we will see in Chapter 4, this can be difficult with traditional Java servlet approaches because Java code is often cluttered with HTML generation code.
HTML does not separate data from presentation. For example, the
following fragment of HTML displays some information about a
customer. In it, data fields such as “Aidan” and
“Burke” are clearly intertwined with formatting elements
such as <tr> and
<td>:
<h3>Customer Information</h3> <table border="1" cellpadding="2" cellspacing="0"> <tr><td>First Name:</td><td>Aidan</td></tr> <tr><td>Last Name:</td><td>Burke</td></tr> <!-- etc... --> </table>
Traditionally, this sort of HTML is generated dynamically using
println( ) statements in a servlet, or perhaps
through a JavaServer Page (JSP). Both require Java programmers, and
neither technology explicitly keeps business logic and data separated
from the HTML generation code. To support multiple incompatible
browsers, you have to be careful to avoid duplication of a lot of
Java code and the HTML itself. This places additional burdens on Java
developers who should be working on more important problems.
There are ways to keep programming logic separate from the HTML
generation, but extracting meaningful data from
HTML pages is next to impossible. This is because the HTML does not
clearly indicate how its data is structured. A human can look at HTML
and determine what its fields mean, but it is quite difficult to
write a computer program that can reliably extract meaningful data.
Although you can search for text patterns such as First Name: followed by <td>, this
approach[1] fails as soon as
the presentation is modified. For example, changing the page as
follows would cause this approach to fail:
<tr><td>Full Name:</td><td>Aidan Burke</td></tr>
XSLT makes it possible to define clearly the roles of Java, XML, XSLT, and HTML. Java is used for business logic, database queries and updates, and for creating XML data. The XML is responsible for raw data, while XSLT transforms the XML into HTML for viewing by a browser. A key advantage of this approach is the clean separation between the XML data and the HTML views. In order to support multiple browsers, multiple XSLT stylesheets are written, but the same XML data is reused on the server. In the previous example, the XML data for the customer did not contain any formatting instructions:
<customer> <firstName>Aidan</firstName> <lastName>Burke</lastName> </customer>
Since XML contains only data, it is almost always much simpler than
HTML. Additionally, XML can be created using a Java API such as JDOM
(http://www.jdom.org). This
facilitates error checking and validation, something that cannot be
achieved if you are simply printing HTML as text using
PrintWriter and println( )
statements in a servlet.
Best of all, the XML-generation code has to be written only once. The XML data can then be transformed by any number of XSLT stylesheets in order to support different browsers, alternate languages, or even nonbrowser devices such as web-enabled cell phones.
Get Java and XSLT now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

