Kapitel 4. KI und maschinelles Lernen: Ein nichttechnischer Überblick
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Um eine KI-Vision und -Strategie zu entwickeln, muss man zwar kein Experte oder Praktiker auf dem Gebiet der KI sein, aber ein umfassendes Verständnis von KI und verwandten Themenbereichen ist entscheidend, um fundierte Entscheidungen zu treffen. Das Ziel dieses Kapitels ist es, dir dabei zu helfen, dieses Verständnis zu entwickeln.
In diesem Kapitel werden KI-bezogene Konzepte und Techniken definiert und diskutiert, darunter maschinelles Lernen, Deep Learning, Data Science und Big Data. Wir erörtern auch, wie Menschen und Maschinen lernen und wie dies mit dem aktuellen und zukünftigen Stand der KI zusammenhängt. Am Ende des Kapitels geht es darum, wie Daten KI antreiben und welche Datenmerkmale und Überlegungen für den Erfolg von KI notwendig sind.
Dieses Kapitel hilft dabei, einen stufengerechten Kontext für das Verständnis des nächsten Kapitels über reale Möglichkeiten und Anwendungen von KI zu entwickeln. Beginnen wir mit der Diskussion über das Feld der Datenwissenschaft.
Was ist Data Science, und was macht ein Data Scientist?
Beginnen wir die Diskussion mit einer Definition von Data Science und der Rolle und den Aufgaben eines Data Scientist, die beide den Bereich und die Fähigkeiten beschreiben, die für die Durchführung von KI- und Machine Learning-Initiativen erforderlich sind (beachte, dass es immer mehr spezialisierte Rollen gibt, wie z. B. den Machine Learning Engineer). Obwohl Datenwissenschaftler/innen oft viele verschiedene Ausbildungen und Berufserfahrungen haben, sollten die meisten in vier grundlegenden Bereichen stark sein (oder idealerweise Experten sein), die ich als die vier Säulen der Datenwissenschaft bezeichne. In keiner bestimmten Reihenfolge sind dies die Bereiche, in denen Datenwissenschaftler/innen über Fachwissen verfügen sollten:
-
Wirtschaft im Allgemeinen oder im relevanten Wirtschaftsbereich
-
Mathematik (einschließlich Statistik und Wahrscheinlichkeitsrechnung)
-
Informatik (einschließlich Softwareprogrammierung)
-
Schriftliche und mündliche Kommunikation
Es gibt noch andere Fähigkeiten und Kenntnisse, die ebenfalls sehr wünschenswert sind, aber das sind meiner Meinung nach die vier wichtigsten. In der Realität sind die Menschen meist in einer oder zwei dieser Säulen stark, aber nicht in allen vier gleich stark. Wenn du einen Datenwissenschaftler triffst, der wirklich in allen Bereichen ein Experte ist, dann hast du eine Person gefunden, die oft als Einhorn bezeichnet wird. Menschen mit einem hohen Maß an Fachwissen und Kompetenz in allen vier Säulen sind sehr schwer zu finden, und es gibt einen erheblichen Mangel an Talenten.
Daher haben viele Unternehmen damit begonnen, spezialisierte Funktionen für bestimmte Säulen der Datenwissenschaft zu schaffen, die in ihrer Kombination einem Datenwissenschaftler entsprechen. Ein Beispiel wäre die Bildung eines Teams aus drei Personen, von denen eine einen MBA-Hintergrund hat, eine andere ist Statistikerin oder Statistiker und eine weitere ist Machine Learning- oder Softwareentwicklerin oder -entwickler. Dem Team könnte auch ein Dateningenieur angehören, zum Beispiel. Dieses Team könnte dann an mehreren Initiativen gleichzeitig arbeiten, wobei sich jede Person jeweils auf einen bestimmten Aspekt einer Initiative konzentriert.
Basierend auf diesen Säulen ist ein Data Scientist eine Person, die in der Lage sein sollte, bestehende Datenquellen zu nutzen und bei Bedarf neue zu erstellen, um aussagekräftige Informationen zu extrahieren, tiefgreifende Erkenntnisse zu gewinnen, datengestützte Entscheidungsprozesse zu unterstützen und KI-Lösungen zu entwickeln. Dies geschieht durch Fachwissen, effektive Kommunikation und Ergebnisinterpretation sowie die Nutzung aller relevanten statistischen Techniken, Programmiersprachen, Softwarepakete und -bibliotheken sowie der Dateninfrastruktur. Kurz gesagt, darum geht es in der Datenwissenschaft.
Maschinelles Lernen - Definition und Hauptmerkmale
Maschinelles Lernen wird oft als eine Untergruppe der KI betrachtet. Wir besprechen zunächst das maschinelle Lernen, um eine Grundlage für unsere Diskussion über KI und ihre Grenzen im weiteren Verlauf dieses Kapitels zu schaffen.
Erinnere dich an unsere einfache Definition von KI als Intelligenz, die von Maschinen gezeigt wird. Das beschreibt im Grunde die Fähigkeit von Maschinen, aus Informationen zu lernen und dieses Wissen anzuwenden, um Dinge zu tun und weiter aus Erfahrungen zu lernen. In vielen KI-Anwendungen wird maschinelles Lernen als eine Reihe von Techniken für den Lernteil des KI-Anwendungsprozesses eingesetzt. Bestimmte Techniken, die wir später erörtern, können als Untergruppen von KI und maschinellem Lernen betrachtet werden und umfassen in der Regel neuronale Netze und Deep Learning, wie in Abbildung 4-1 dargestellt.

Abbildung 4-1. Beziehungen zwischen KI, maschinellem Lernen, neuronalen Netzen und Deep Learning
Mir gefällt diese kurze und prägnante Definition von maschinellem Lernen, die ich in einem Blogartikel von Google Design gefunden habe, sehr gut: "Maschinelles Lernen ist die Wissenschaft, die Vorhersagen auf der Grundlage von Mustern und Beziehungen macht, die automatisch in Daten entdeckt wurden."
Eine nicht-technische Definition von maschinellem Lernen, die ich üblicherweise gebe, lautet, dass maschinelles Lernen der Prozess des automatischen Lernens aus Daten ist, ohne dass eine explizite Programmierung erforderlich ist, mit der Fähigkeit, das gelernte Wissen mit der Erfahrung zu erweitern. Ein wesentliches Unterscheidungsmerkmal des maschinellen Lernens gegenüber regelbasierten Techniken ist das Fehlen einer expliziten Programmierung, insbesondere in Bezug auf bestimmte Bereiche, Branchen und Geschäftsfunktionen. Bei fortgeschrittenen Techniken wie Deep Learning ist unter Umständen überhaupt kein Fachwissen erforderlich, während in anderen Fällen das Fachwissen in Form von Merkmalen (in Anwendungen, die nicht dem maschinellen Lernen zuzuordnen sind, als Variablen, Datenfelder oder Datenattribute bezeichnet) zur Verfügung gestellt wird, die zum Trainieren der Modelle ausgewählt oder entwickelt werden. In jedem Fall ist der Teil, der keine explizite Programmierung erfordert, absolut entscheidend und der wichtigste Aspekt des maschinellen Lernens, den es zu verstehen gilt. Lass uns das an einem Beispiel erläutern.
Stell dir vor, du wärst ein Programmierer, bevor es maschinelles Lernen gab, und hättest die Aufgabe, ein Vorhersagemodell zu entwickeln, das vorhersagen kann, ob eine Person, die einen bestimmten Kredit beantragt, diesen Kredit nicht zurückzahlen kann und deshalb bewilligt oder nicht bewilligt werden sollte. Du hättest ein langes Softwareprogramm geschrieben, das speziell auf die Finanzbranche zugeschnitten ist und Eingaben wie den FICO-Score einer Person, ihre Kreditgeschichte und die Art des beantragten Kredits enthält. Der Code würde viele sehr explizite Programmieranweisungen enthalten (z. B. Konditionale, Schleifen). Der Pseudocode (in einfachem Englisch geschriebener Programmiercode) könnte etwa so aussehen:
If the persons FICO score is above 800, then they will likely not default
and should be approved
Else if the persons FICO score is between 700 and 800
If the person has never defaulted on any loan, they will likely not
default and should be approved
Else the will likely default and should not be approved
Else if the persons FICO score is less than 700
...
Dies ist ein Beispiel für eine sehr explizite Programmierung (ein regelbasiertes Vorhersagemodell), die spezifisches Fachwissen über die Kreditbranche enthält und als Code ausgedrückt wird. Dieses Programm ist fest programmiert, um nur eine Sache zu erreichen. Es erfordert Fachwissen, um die Regeln (auch Szenarien genannt) festzulegen. Es ist sehr starr und nicht unbedingt repräsentativ für alle Faktoren, die zu einem möglichen Kreditausfall beitragen. Außerdem muss das Programm bei Änderungen der Eingaben oder der Kreditbranche im Allgemeinen manuell aktualisiert werden.
Wie du siehst, ist das nicht besonders effizient oder optimal und führt auch nicht zum bestmöglichen Vorhersagemodell. Maschinelles Lernen, das die richtigen Daten verwendet, ist dagegen in der Lage, dies ohne explizit geschriebenen Code zu tun, insbesondere ohne Code, der Fachwissen über die Kreditwirtschaft ausdrückt. Etwas vereinfacht ausgedrückt, ist maschinelles Lernen in der Lage, einen Datensatz als Input zu nehmen, ohne etwas über die Daten oder den betreffenden Bereich zu wissen, ihn durch einen maschinellen Lernalgorithmus zu leiten, der ebenfalls nichts über die Daten oder den betreffenden Bereich weiß, und ein Vorhersagemodell zu erstellen, das über Expertenwissen darüber verfügt, wie die Inputs dem Output zugeordnet werden, um möglichst genaue Vorhersagen zu treffen. Wenn du das verstehst, hast du den Zweck des maschinellen Lernens auf einem hohen Niveau verstanden.
Es ist erwähnenswert, dass maschinelle Lernalgorithmen zwar in der Lage sind, ohne explizite Programmierung zu lernen, dass aber Menschen nach wie vor gebraucht werden und in den gesamten Prozess der Entwicklung, des Aufbaus und des Testens von auf maschinellem Lernen basierenden KI-Lösungen involviert sind.
Wege, wie Maschinen lernen
Maschinen lernen aus Daten durch eine Vielzahl verschiedener Techniken. Die wichtigsten sind überwachtes, unbeaufsichtigtes, halbüberwachtes, verstärkendes und Transfer-Lernen. Die Daten, die zum Trainieren und Optimieren von maschinellen Lernmodellen verwendet werden, werden in der Regel in beschriftete und unbeschriftete Daten eingeteilt, wie in Abbildung 4-2 dargestellt.

Abbildung 4-2. Beschriftete versus unbeschriftete Daten
Markierte Daten haben eine Zielvariable oder einen Wert, der für eine bestimmte Kombination von Merkmalswerten (auch Variablen, Attribute, Felder genannt) vorhergesagt werden soll. Bei der prädiktiven Modellierung, einer Art von maschineller Lernanwendung, wird ein Modell auf einem markierten Datensatz trainiert, um den Zielwert für neue Kombinationen von Merkmalswerten vorherzusagen. Das Vorhandensein von Zieldaten im Datensatz ist der Grund dafür, dass die Daten als gekennzeichnete Daten bezeichnet werden. Unmarkierte Daten hingegen haben zwar Merkmalswerte, aber keine bestimmten Zieldaten oder Labels. Deshalb eignen sich unmarkierte Daten besonders gut für die Gruppierung (auch Clustering und Segmentierung genannt) und die Erkennung von Anomalien.
Eine Sache, die man beachten sollte, ist, dass es leider sehr schwierig sein kann, beschriftete Daten in ausreichender Menge zu bekommen, und dass es sehr viel Geld und Zeit kosten kann, sie zu erstellen. Beschriftungen können automatisch zu den Datensätzen hinzugefügt werden oder müssen von Menschen manuell hinzugefügt werden (stell dir einen Datensatz, auch Probe genannt, als eine Zeile in einer Tabelle vor).
Überwachtes Lernen bezieht sich auf maschinelles Lernen mit gekennzeichneten Daten und unüberwachtes Lernen mit nicht gekennzeichneten Daten. Beim teilüberwachten Lernen werden sowohl markierte als auch unmarkierte Daten verwendet.
Erläutern wir kurz die verschiedenen Lerntypen auf hohem Niveau. Überwachtes Lernen hat viele potenzielle Anwendungen wie Vorhersage, Personalisierung, Empfehlungssysteme und Mustererkennung. Es wird in zwei Anwendungen unterteilt: Regression und Klassifizierung. Beide Techniken werden verwendet, um Vorhersagen zu treffen. Die Regression wird in erster Linie zur Vorhersage einzelner diskreter oder reeller Zahlenwerte verwendet, während die Klassifizierung dazu dient, einem bestimmten Satz von Eingabedaten eine oder mehrere Klassen oder Kategorien zuzuordnen (z. B. Spam oder Nicht-Spam bei E-Mails).
Die häufigsten Anwendungen des unüberwachten Lernens sind das Clustering und die Erkennung von Anomalien, während sich das unüberwachte Lernen im Allgemeinen weitgehend auf die Mustererkennung konzentriert. Weitere Anwendungen sind die Dimensionalitätsreduktion (Vereinfachung der Anzahl der Datenvariablen und der Modellkomplexität) mithilfe der Hauptkomponentenanalyse (PCA) und der Singulärwertzerlegung (SVD).
Obwohl die zugrundeliegenden Daten nicht beschriftet sind, können unüberwachte Techniken in nützlichen prädiktiven Anwendungen eingesetzt werden, wenn Beschriftungen, Charakterisierungen oder Profile auf entdeckte Cluster (Gruppierungen) durch einen anderen Prozess außerhalb des unüberwachten Lernprozesses selbst angewendet werden. Eine der Herausforderungen beim unüberwachten Lernen ist, dass es keine besonders gute Methode gibt, um festzustellen, wie gut ein durch unüberwachtes Lernen erstelltes Modell funktioniert. Das Ergebnis ist das, was du daraus machst, und es gibt nichts Richtiges oder Falsches daran. Das liegt daran, dass es in den Daten keine Kennzeichnung oder Zielvariable gibt und somit nichts, womit man die Modellergebnisse vergleichen könnte. Trotz dieser Einschränkung ist das unüberwachte Lernen sehr leistungsfähig und wird in der Praxis häufig eingesetzt.
Semi-überwachtes Lernen kann ein sehr nützlicher Ansatz sein, wenn es viele unmarkierte Daten gibt, aber keine markierten Daten. Andere beliebte Lernmethoden, die wir im nächsten Kapitel genauer vorstellen, sind das Verstärkungslernen, das Transferlernen und Empfehlungssysteme.
Bei Aufgaben des maschinellen Lernens, die mit beschrifteten und unbeschrifteten Daten arbeiten, werden die eingegebenen Daten in eine Art Ausgabe umgewandelt. Die meisten Ergebnisse von Machine Learning-Modellen sind überraschend einfach und bestehen entweder aus einer Zahl (kontinuierlich oder diskret, z. B. 3,1415), einer oder mehreren Kategorien (auch Klassen genannt, z. B. "Spam", "Hot Dog") oder einer Wahrscheinlichkeit (z. B. 35 % Wahrscheinlichkeit). In fortgeschritteneren KI-Fällen kann die Ausgabe eine strukturierte Vorhersage sein (d.h. eine Reihe von vorhergesagten Werten im Gegensatz zu einem einzelnen Wert), eine vorhergesagte Abfolge von Zeichen und Wörtern (z.B. Phrasen, Sätze) oder eine künstlich erzeugte Zusammenfassung des letzten Spiels der Chicago Cubs (GO CUBS!).
KI-Definition und -Konzepte
Zuvor haben wir eine einfache Definition von KI als Intelligenz von Maschinen gegeben, die maschinelles Lernen und spezielle Techniken wie Deep Learning als Teilbereiche umfasst. Bevor wir eine weitere Definition von KI entwickeln, wollen wir den Begriff der Intelligenz im Allgemeinen definieren. Eine grobe Definition für Intelligenz ist:
Lernen, Verstehen und die Anwendung des erlernten Wissens, um ein oder mehrere Ziele zu erreichen
Im Grunde genommen ist Intelligenz also der Prozess, bei dem das erlernte Wissen genutzt wird, um Ziele zu erreichen und Aufgaben zu erfüllen (bei Menschen zum Beispiel Entscheidungen zu treffen, ein Gespräch zu führen oder Arbeitsaufgaben zu erledigen). Nachdem wir nun Intelligenz im Allgemeinen definiert haben, ist es leicht zu erkennen, dass KI einfach Intelligenz ist, wie sie von Maschinen gezeigt wird. Genauer gesagt, beschreibt KI, dass eine Maschine in der Lage ist, aus Informationen (Daten) zu lernen, ein gewisses Maß an Verständnis zu entwickeln und das gelernte Wissen dann zu nutzen, um etwas zu tun.
Der Bereich der KI ist mit Aspekten der Neurowissenschaften, der Psychologie, der Philosophie, der Mathematik, der Statistik, der Informatik, der Computerprogrammierung und mehr verbunden. KI wird manchmal auch als maschinelle Intelligenz oder kognitives Computing bezeichnet, da sie auf den Grundlagen und der Beziehung zur Kognition beruht, d.h. den mentalen Prozessen, die mit der Entwicklung von Wissen und Verständnis verbunden sind.
Der Begriff Kognition und der breitere Bereich der Kognitionswissenschaft beschreiben die Prozesse, Funktionen und anderen Mechanismen des Gehirns, die es ermöglichen, Informationen zu sammeln, zu verarbeiten, zu speichern und zu nutzen, um Intelligenz zu erzeugen und Verhalten zu steuern. Zu den kognitiven Prozessen gehören Aufmerksamkeit, Wahrnehmung, Gedächtnis, Argumentation, Verständnis, Denken, Sprache, Erinnern und vieles mehr. Weitere verwandte und etwas tiefer gehende philosophische Konzepte sind Geist, Empfindung, Bewusstsein und Bewusstheit.
Was also treibt Intelligenz an? Für KI-Anwendungen lautet die Antwort: Informationen in Form von Daten. Bei Menschen und Tieren werden über die fünf Sinne ständig neue Informationen aus Erfahrungen und der Umgebung gesammelt. Diese Informationen werden dann durch die kognitiven Prozesse und Funktionen des Gehirns weitergeleitet.
Erstaunlicherweise kann der Mensch auch aus bereits im Gehirn gespeicherten Informationen und Wissen lernen, indem er es anwendet, um etwas anderes zu verstehen und zu entwickeln, oder um seine Gedanken und Meinungen zu einem neuen Thema zu entwickeln, zum Beispiel. Wie oft hast du schon über etwas nachgedacht, das du bereits verstanden hast, und dann einen "Aha!"-Moment gehabt, der zu einem neuen Verständnis von etwas anderem führte?
Erfahrung spielt auch bei der KI eine große Rolle. KI wird durch einen Trainings- und Optimierungsprozess ermöglicht, der relevante Daten für eine bestimmte Aufgabe nutzt. KI-Anwendungen können im Laufe der Zeit aktualisiert und verbessert werden, wenn neue Daten zur Verfügung stehen - das ist der Aspekt des Lernens aus Erfahrung.
Kontinuierlich aus neuen Daten zu lernen ist aus vielen Gründen wichtig. Erstens: Die Welt und ihre Bewohner verändern sich ständig um uns herum. Trends und Modeerscheinungen kommen und gehen, neue Technologien werden eingeführt und alte Technologien werden überflüssig, Branchen werden umgestürzt und es werden ständig neue Innovationen eingeführt. Das führt dazu, dass die Daten, die du heute zum Beispiel zum Online-Shopping erhältst, ganz anders aussehen können als die Daten, die du morgen oder in einigen Jahren erhältst. Automobilhersteller könnten sich fragen, welche Faktoren am meisten dazu beitragen, dass Menschen fliegende Fahrzeuge kaufen, im Gegensatz zu den Elektrofahrzeugen, die heute immer beliebter werden und immer mehr Verbreitung finden.
Letztendlich können die Daten und die damit trainierten Modelle veralten, ein Phänomen, das als Modelldrift bezeichnet wird. Deshalb ist es wichtig, dass alle KI-Anwendungen immer wieder aufgefrischt werden und durch kontinuierliches Lernen aus neuen Daten an Erfahrung und Wissen gewinnen.
KI-Typen
Oft wird KI mit einem Zusatz wie "stark" oder "eng" bezeichnet. Mit diesen Begriffen, die wir im Folgenden erläutern, soll die Art der KI beschrieben werden, über die gesprochen wird. Der Aspekt der KI, der durch den Qualifikator beschrieben wird, kann sich auf die Anzahl der gleichzeitigen Aufgaben beziehen, die eine KI ausführen kann, auf die Architektur eines bestimmten Algorithmus (im Fall von neuronalen Netzen), auf die tatsächliche Verwendung der KI oder auf die relative Schwierigkeit, ein bestimmtes Problem mithilfe von KI zu lösen.
Obwohl dies je nach Referenz oder Forscher/in unterschiedlich sein kann, kann KI in Kategorien und Beziehungen eingeteilt werden, wie in Abbildung 4-3 dargestellt.
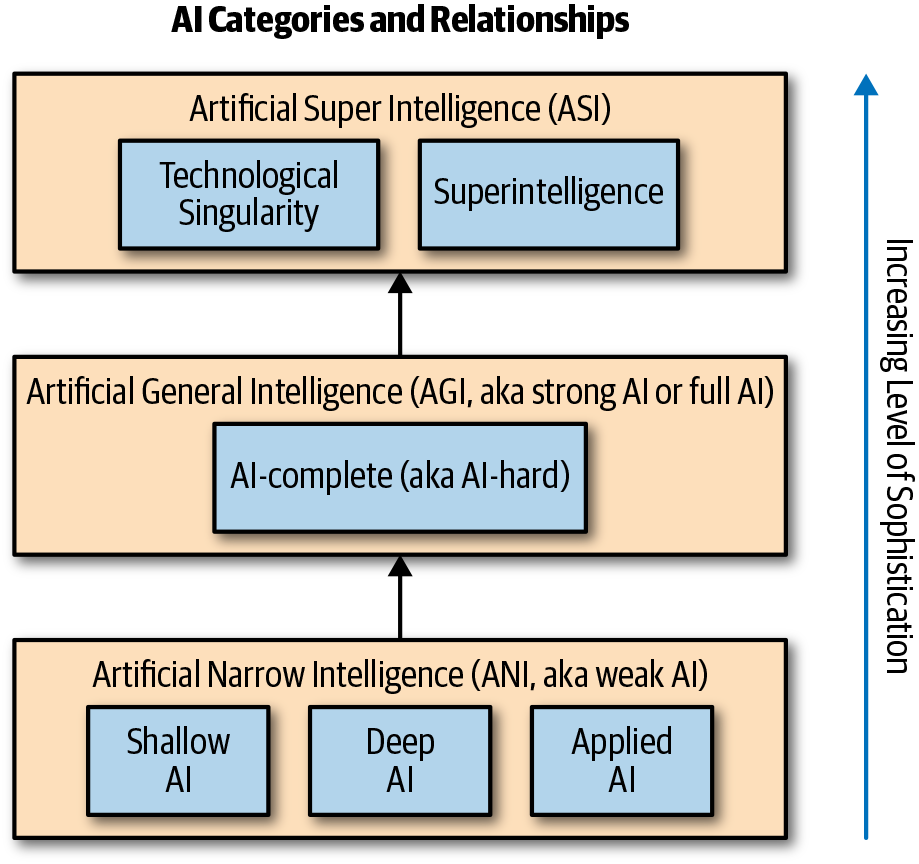
Abbildung 4-3. AI-Kategorien und Beziehungen
Die Begriffe "schwach" und " eng " werden austauschbar verwendet, um zu verdeutlichen, dass eine KI spezialisiert und in der Lage ist, nur eine einzige, eng begrenzte Aufgabe auszuführen; sie ist nicht in der Lage, Kognition zu zeigen. Das bedeutet, dass eine schwache KI zwar oft sehr beeindruckend ist, aber kein Gefühl, kein Bewusstsein oder keine Wahrnehmung hat. Zum jetzigen Zeitpunkt wird fast jede KI als schwache KI betrachtet.
Die Begriffe "Shallow" und "Deep" beschreiben die Anzahl der versteckten Schichten in der Architektur eines neuronalen Netzes (ausführlich in Anhang A). Shallow AI bezieht sich in der Regel auf ein neuronales Netzwerk mit einer einzigen versteckten Schicht, während deep AI (synonym für Deep Learning) ein neuronales Netzwerk mit mehr als einer versteckten Schicht bezeichnet.
Angewandte KI ist so, wie sie klingt. Es ist die Anwendung von KI auf reale Probleme wie Vorhersagen, Empfehlungen, natürliche Sprache und Erkennung. Heutzutage hört man oft den Begriff smart, um KI-gestützte Software- und Hardwarelösungen zu beschreiben (z. B. Smart Homes). Das heißt, eine Form von KI wird als Teil der Lösung eingesetzt, auch wenn die Unternehmen oft übertreiben. Da alle KI heutzutage als eng angesehen wird, wird die angewandte KI mit der engen KI in Verbindung gebracht. Das könnte sich in Zukunft ändern, womit wir bei der nächsten Kategorie wären.
Künstliche allgemeine Intelligenz (AGI) wird auch als "starke" oder "vollständige" KI bezeichnet. AGI setzt die Messlatte so hoch, dass sie eine maschinelle Intelligenz darstellt, die in der Lage ist, Kognition zu zeigen und kognitive Prozesse im gleichen Maße wie ein Mensch auszuführen. Mit anderen Worten: Sie verfügt über kognitive Fähigkeiten, die einem Menschen funktional gleichwertig sind. Das bedeutet, dass eine Maschine jede Aufgabe erledigen kann, die auch ein Mensch erledigen kann, und nicht darauf beschränkt ist, Intelligenz auf ein einziges spezifisches Problem anzuwenden. Das ist eine extrem hohe Messlatte, die wir anlegen. Auf AGI und die Herausforderungen, die damit verbunden sind, gehen wir später in diesem Kapitel näher ein.
Es ist erwähnenswert, dass bestimmte KI-Probleme als "vollständig" oder "schwer" bezeichnet werden (z. B. AGI, Verständnis natürlicher Sprache), was nur bedeutet, dass diese Probleme sehr fortgeschritten und schwer vollständig und allgemein zu lösen sind. Die Entwicklung von Maschinen, die genauso intelligent sind wie Menschen, ist ein sehr schwer zu lösendes Problem und entspricht nicht der KI, die wir heute haben.
Künstliche Superintelligenz (KI ) und verwandte Konzepte wie technologische Singularität und Superintelligenz beschreiben das Szenario, in dem sich KI in rasantem Tempo selbst verbessert und schließlich die menschliche Intelligenz und den technischen Fortschritt übertrifft. Auch wenn die Möglichkeit einer Singularität und Superintelligenz weitgehend umstritten ist, ist es höchst unwahrscheinlich, dass sie in naher Zukunft eintritt, wenn überhaupt. Auch wenn es nichts ist, worüber man sich im Moment Sorgen machen müsste, ist es erwähnenswert, dass bestimmte Techniken wie Deep Reinforcement Learning in KI-Anwendungen für selbstgesteuertes Lernen eingesetzt werden, das sich mit der Zeit verbessert.
Lernen wie die Menschen
Man bedenke, dass Babys und sehr kleine Kinder in der Lage sind, ein Objekt wie ein bestimmtes Tier in fast jedem Kontext (z. B. Standort, Position, Pose, Beleuchtung) zu erkennen, obwohl sie ein Bild oder eine Illustration eines bestimmten Tieres nur einmal gesehen haben. Das ist eine bemerkenswerte Leistung des menschlichen Gehirns, das zunächst lernt und dieses Wissen dann auf verschiedene Kontexte anwendet.
In der MIT Technology Review ist ein großartiger Artikel mit dem Titel "The Missing Link of AI" (Das fehlende Glied der KI) erschienen , der von Tom Simonite geschrieben wurde. In dem Artikel geht es um die Art und Weise, wie Menschen lernen, und wie sich die KI-Techniken weiterentwickeln müssen, um auf ähnliche Weise zu lernen und letztendlich eine menschenähnliche Intelligenz zu entwickeln. Jeff Dean von Google wird darin mit den Worten zitiert: "Letztendlich wird unüberwachtes Lernen eine wirklich wichtige Komponente beim Aufbau wirklich intelligenter Systeme sein - wenn man sich ansieht, wie Menschen lernen, ist das fast vollständig unüberwacht." Yann LeCun führt dies weiter aus: "Wir alle wissen, dass unüberwachtes Lernen die ultimative Antwort ist."
Der Artikel weist darauf hin, dass Kleinkinder von selbst lernen, dass Gegenstände von anderen Gegenständen gestützt werden (z. B. ein Buch auf einem Couchtisch) und deshalb gestützte Gegenstände trotz der Schwerkraft nicht zu Boden fallen. Kinder lernen auch, dass unbelebte Gegenstände im Raum an der gleichen Stelle bleiben, wenn sie den Raum verlassen, und sie können davon ausgehen, dass sie noch da sind, wenn sie zurückkommen. Sie tun dies, ohne dass es ihnen explizit beigebracht wird. Mit anderen Worten: Dieses Lernen ist unbeaufsichtigt und beinhaltet keine markierten Daten, wobei das Etikett ein Elternteil sein könnte, das dem Kind etwas beibringt.
Kinder lernen auch, indem sie im Laufe der Zeit verschiedene Dinge ausprobieren, z. B. durch Experimente und Versuch und Irrtum. Sie tun dies auch dann, wenn sie es nicht tun sollen oder wenn sie wissen, dass einige Ergebnisse negativ sein könnten, aber sie tun dies, um etwas über Ursache und Wirkung und die Welt um sie herum zu lernen. Diese Art des Lernens ist dem Verstärkungslernen sehr ähnlich, das in der KI-Forschung und -Entwicklung sehr aktiv ist und dazu beitragen kann, große Fortschritte in Richtung menschenähnlicher Intelligenz zu machen.
Im Kontext des menschlichen Lernens im Allgemeinen sind Menschen in der Lage, die Welt um sich herum wahrzunehmen und den Dingen eine eigene Bedeutung zu geben. Das kann das Erkennen von Mustern, Gegenständen, Menschen und Orten sein. Es kann auch bedeuten, herauszufinden, wie etwas funktioniert. Menschen wissen auch, wie sie sich mit der natürlichen Sprache verständigen können. Vieles, was Menschen lernen, geschieht unbeaufsichtigt, selbstlernend und durch Versuch und Irrtum. All das sind bemerkenswerte Leistungen des menschlichen Gehirns, die sich nur sehr schwer mit Algorithmen und Maschinen nachahmen lassen, wie wir weiter unten erläutern werden.
AGI, Killerroboter und das Ein-Trick-Pony
AGI - eine KI, die in der Lage ist, alles zu tun und zu verstehen, was ein Mensch mindestens genauso gut kann - liegt noch in weiter Ferne. Das bedeutet, dass wir uns vorerst keine Sorgen über Killerroboter machen müssen, vielleicht sogar nie. Pedro Domingos schreibt in seinem Buch The Master Algorithm1 erklärt: "Die Menschen machen sich Sorgen, dass Computer zu schlau werden und die Welt übernehmen, aber das eigentliche Problem ist, dass sie zu dumm sind und die Welt bereits übernommen haben." Er fährt fort, dass die Chancen, dass KI die Welt übernimmt, gleich null sind, weil Maschinen lernen und vor allem, weil Computer keinen eigenen Willen haben.
AGI ist ein sehr schwer zu lösendes Problem. Überleg mal - um die menschliche Intelligenz wirklich in einer Maschine nachzubilden, müsste die KI in der Lage sein, die Welt um sich herum zu beobachten, kontinuierlich und selbstgesteuert zu lernen (d.h. echte Autonomie zu demonstrieren), um sich ständig einen Reim auf alles machen zu können, und sich potenziell selbst zu verbessern wie der Mensch. Es müsste alles verstehen, was Menschen tun, vielleicht sogar mehr, und in der Lage sein, Wissen zu verallgemeinern und auf jeden Kontext zu übertragen. Das ist es, was Kinder und Erwachsene weitgehend tun. Aber wie macht man das, wenn es beim unüberwachten Lernen keine richtigen Antworten gibt, wie wir bereits besprochen haben? Wie kann man einer Maschine beibringen, etwas zu lernen, ohne ihr etwas beizubringen, d. h. sie dazu bringen, selbst zu lernen?
Das sind gute Fragen, und die Antwort ist, dass man sie nicht beantworten kann, zumindest nicht mit den modernen KI- und maschinellen Lernmethoden. Zu den fortschrittlichsten Techniken der KI gehören derzeit neuronale Netze, Deep Learning, Transfer Learning und Reinforcement Learning. Diese Techniken eignen sich nicht besonders gut für unüberwachte Lernanwendungen. Außerdem sind sie sehr auf eine einzige, hoch spezialisierte Aufgabe ausgerichtet.
Ein neuronales Netzwerk mit Deep Learning, das darauf trainiert ist, Katzen auf einem Bild zu erkennen, ist nicht in der Lage, auch den Preis deines Hauses in drei Jahren vorherzusagen; es kann nicht mehr als Katzen auf einem Bild erkennen. Wenn du willst, dass ein Modell den Preis deines Hauses vorhersagt, musst du ein separates Modell erstellen und trainieren. KI ist also nicht gut im Multitasking, und jede Instanz ist vorerst nur ein One-Trick-Pony.
Obwohl die genaue Funktionsweise des menschlichen Gehirns für Neurowissenschaftler/innen nach wie vor ein Rätsel ist, scheint eines klar zu sein: Das Gehirn ist keine reine Rechenmaschine im Sinne eines Computers. Es wird angenommen, dass das Gehirn sensorische Informationen mit einem komplexen, auf Algorithmen basierenden biologischen neuronalen Netzwerkmechanismus verarbeitet, der Erinnerungen auf der Grundlage von Mustern speichern, Probleme lösen und motorische Aktionen (Verhalten) auf der Grundlage von Informationsabruf und Vorhersage steuern kann.
Dieser Prozess beginnt mit der Geburt und setzt sich im Laufe unseres Lebens fort, und zwar wie gesagt oft auf eine sehr unbeaufsichtigte, auf Versuch und Irrtum basierende Weise. Der unglaubliche Speicher- und Abrufmechanismus des Gehirns unterscheidet es von einer reinen Rechenmaschine und macht das unbeaufsichtigte Lernen des Menschen erst möglich. Ein einzelnes menschliches Gehirn ist in der Lage, kontinuierlich zu lernen und alle Informationen und Erinnerungen zu speichern, die es in einem ganzen Menschenleben gelernt hat. Wie könnte eine Maschine das nachahmen? Gar nicht - zumindest nicht in absehbarer Zeit.
Im Gegensatz zu den unbeaufsichtigten und selbstlernenden Menschen sind Computermaschinen vollständig von extrem detaillierten Anweisungen abhängig. Das ist das, was wir Softwarecode nennen. Selbst automatisch gelernte und nicht explizit programmierte Vorhersagemodelle (die Magie der KI und des maschinellen Lernens) werden in softwarebasierte Programme eingebaut, die von Computerprogrammierern geschrieben wurden. Beim derzeitigen Stand der KI ist AGI unmöglich, wenn eine Maschine nicht für jedes mögliche sensorische Szenario, das ihr in jeder Umgebung und unter jeder Bedingung begegnet, trainiert oder programmiert wird.
Das bedeutet, dass intelligente Maschinen nicht wie Menschen einen freien Willen haben können, d. h. die Fähigkeit, jede beliebige Entscheidung zu treffen oder jede beliebige Handlung innerhalb der Grenzen der Vernunft vorzunehmen, so wie es Menschen tun, wenn sie eine begrenzte oder sogar unbegrenzte Anzahl von Möglichkeiten haben. Mit Ausnahme von Techniken wie dem Reinforcement Learning sind intelligente Maschinen darauf beschränkt, Eingaben nur bestimmten Ausgaben zuzuordnen.
Menschliche Gehirne hingegen können auf Szenarien reagieren, denen sie vorher nicht begegnet sind oder die sie nicht kennen. Sie können sensorische Informationen aus den fünf Sinnen auf natürliche Weise in Echtzeit, mit scheinbarer Leichtigkeit und mit großer relativer Geschwindigkeit integrieren. Menschen sind in der Lage, sich ständig an ungeplante Veränderungen in ihrer Umgebung anzupassen, z. B. unerwartete Gespräche mit anderen Menschen zu führen (z. B. ein Telefonanruf, das Zusammentreffen mit einem Freund), herauszufinden, warum sich der Fernseher plötzlich nicht mehr einschalten lässt, mit plötzlichen Wetterveränderungen umzugehen, auf Unfälle zu reagieren (z. B., Auto, verschüttetes Wasser, zerbrochenes Glas), einen Bus verpassen, feststellen, dass ein Aufzug außer Betrieb ist (Menschen wissen sofort, dass sie stattdessen die Treppe nehmen müssen), dass eine Kreditkarte nicht funktioniert, dass eine Einkaufstasche kaputt geht, dass sie einem Kind ausweichen müssen, das ihnen plötzlich über den Weg läuft - die Zahl der Beispiele aus der realen Welt ist fast unendlich.
Menschen sind auch in der Lage zu denken, ein Prozess, der keine sensorischen Eingangsdaten benötigt. Du könntest am Strand sitzen und auf die Wellen des Ozeans starren, während du über viele Dinge nachdenkst, die nichts mit dem Strand und dem Ozean zu tun haben, aber die heutigen KI-Algorithmen sind wie Fleischwölfe: Du musst Rindfleisch in den Fleischwolf geben, um Hackfleisch zu erhalten. Abgesehen von Techniken wie dem Verstärkungslernen produzieren KI-Algorithmen keine Ergebnisse ohne entsprechende Eingaben, schon gar nicht etwas, das den menschlichen Gedanken nahe kommt.
In The Book of Why2 erläutern die Autoren, dass Menschen auch in der Lage sind, auf der Grundlage eines kausalen Verständnisses (Ursache und Wirkung) der Welt und der Fähigkeit zur Reflexion zu denken, Entscheidungen zu treffen, zu handeln und Schlussfolgerungen zu ziehen. Reflexion bedeutet, dass wir in der Lage sind, unsere Entscheidungen oder Handlungen im Nachhinein zu betrachten, die Ergebnisse zu analysieren und zu entscheiden, ob wir etwas anders gemacht hätten oder in einer ähnlichen Situation das nächste Mal anders handeln würden. Dies ist eine Form des natürlichen menschlichen Lernens, bei dem die Inputs frühere Handlungen oder Entscheidungen sind.
Wir haben auch ein kausales Verständnis von der Welt, das wir im Laufe unseres Lebens immer weiter entwickeln. Wir wissen, dass Korrelation nicht gleichbedeutend mit Kausalität ist, und dennoch basieren die meisten KI- und maschinellen Lernalgorithmen auf Korrelationen (z. B. prädiktive Analysen) und haben absolut kein Konzept von Kausalität. Ein bekanntes Beispiel ist die Tatsache, dass ein Anstieg der Eisverkäufe mit einer Zunahme der Todesfälle durch Ertrinken einhergeht, so dass ein Vorhersagealgorithmus daraus lernen könnte, dass ein erhöhter Eiskremkonsum zum Ertrinken führt. Mit ein wenig Nachdenken kann der Mensch leicht herausfinden, dass die fehlenden Faktoren, die so genannten Störvariablen, die Jahreszeit und die Temperatur sind, die die wahren Ursachen für den Anstieg in beiden Fällen sind. Eine KI wäre nicht in der Lage, dies herauszufinden.
Schließlich gibt es einen bedeutenden Unterschied zwischen Automatisierung und Autonomie, die beide im Zusammenhang mit der Entwicklung von Robotik und KI in Richtung AGI von großer Bedeutung sind. Automatisierung ist das Ergebnis des Schreibens von Softwareprogrammen, die automatisch eine einmalige oder sich wiederholende Aufgabe ausführen, die zuvor menschliche Hilfe erforderte. Bei der Autonomie hingegen geht es um Unabhängigkeit, Selbstbestimmung und die Fähigkeit, auf Interaktionen und Veränderungen in der Umgebung zu reagieren. In bestehenden Robotik- und KI-Anwendungen gibt es unterschiedliche Grade von Automatisierung und Autonomie, wobei die meisten Anwendungen derzeit eher auf der Automatisierungsseite angesiedelt sind.
Echte Autonomie ist aus den bereits im Zusammenhang mit AGI erwähnten Gründen sehr schwierig, aber auch wegen der Grenzen von Sensortechniken wie Computer Vision. Computervision und Bilderkennung haben große Fortschritte bei der Erkennung und Identifizierung von Objekten unter kontrollierten und konsistenten Bedingungen gemacht, aber die Technologie ist nicht sehr gut darin, sich in ständig verändernden, unbeständigen und überraschungsreichen Umgebungen zurechtzufinden, die eher der Realität entsprechen.
Die Daten, die KI antreiben
Es gibt eine Sache, die KI, maschinelles Lernen, Big Data, IoT und jede andere Form von analytischen Lösungen gemeinsam haben: Daten. In der Tat sind Daten die Grundlage für jeden Aspekt der digitalen Technologie.
In diesem Kapitel geht es um die Macht der Daten, die Nutzung von Daten für Entscheidungen, gängige Datenstrukturen und -formate, die in KI-Anwendungen verwendet werden, die Speicherung von Daten und gängige Datenquellen sowie das Konzept der Datenreife.
Big Data
Noch nie hat die Welt so viele Daten gesammelt und gespeichert wie heute. Hinzu kommt, dass die Vielfalt, das Volumen und die Generierungsrate der Daten in einem alarmierenden Tempo zunehmen. Rio Tinto zum Beispiel, ein führendes Bergbauunternehmen mit einem Umsatz von mehr als 40 Milliarden Dollar, setzt auf Big Data und KI, um aus 2,4 Terabyte Sensordaten pro Minute datengesteuerte Entscheidungen zu treffen!
Im Bereich Big Data geht es darum, Informationen aus diesen riesigen, vielfältigen und schnelllebigen Datenbeständen effizient zu erfassen, zu integrieren, aufzubereiten und zu analysieren. Die Verarbeitung und Auswertung dieser Datenmengen ist jedoch aufgrund von Hardware- und/oder Rechenbeschränkungen oft nicht möglich oder nicht durchführbar. Um diese Herausforderungen zu bewältigen, sind neue und innovative Hardware, Software-Tools und Analysetechniken erforderlich. Big Data ist der Begriff, der diese Kombination aus Datensätzen, Techniken und maßgeschneiderten Tools beschreibt.
Außerdem sind Daten jeglicher Art ohne eine Form der begleitenden Analyse im Grunde nutzlos (es sei denn, die Daten werden zu Geld gemacht). Zusätzlich zu dieser Beschreibung wird Big Data auch verwendet, um die Analyse sehr großer Datensätze zu beschreiben, die fortgeschrittene Analysetechniken wie KI und maschinelles Lernen beinhalten kann.
Datenstruktur und Format für KI-Anwendungen
Auf einer hohen Ebene können wir Daten als strukturiert, unstrukturiert oder semistrukturiert klassifizieren, wie in Abbildung 4-4 dargestellt.

Abbildung 4-4. Datentypen
Beginnen wir mit strukturierten Daten. Strukturierte Daten sind, nun ja, Daten mit einer Struktur. Obwohl sie in Abbildung 4-4 in tabellarischer Form dargestellt sind, handelt es sich bei strukturierten Daten um Daten, die im Allgemeinen organisiert sind und leicht in eine Tabelle, eine Tabellenkalkulation oder eine relationale Datenbank passen. Strukturierte Daten zeichnen sich in der Regel durch Merkmale aus, die auch Attribute oder Felder genannt werden. Wenn sie auf diese Weise strukturiert sind, werden sie allgemein als Datenmodell bezeichnet, und es ist relativ einfach, die Daten abzufragen, zu verknüpfen, zu aggregieren, zu filtern und zu sortieren.
Abbildung 4-4 zeigt ein Beispiel für strukturierte Daten im Tabellenformat. In diesem Fall sind die Daten in Spalten und Zeilen organisiert, wobei die Zeilen einzelne Datenbeispiele (auch Datensätze, Stichproben oder Datenpunkte genannt) darstellen. Die Spalten stellen die Datenmerkmale für jedes Beispiel dar. Abbildung 4-4 zeigt auch Beispiele für beschriftete und unbeschriftete Daten, Konzepte, die wir bereits besprochen haben.
Unstrukturierte Daten sind das Gegenteil von strukturierten Daten und daher in keiner Weise organisiert oder strukturiert und auch nicht durch ein Datenmodell gekennzeichnet. Gängige Beispiele sind Bilder, Videos, Audiodateien und Text, wie er in Kommentaren, im Text von E-Mails und in Text übersetzter Sprache vorkommt.
Beachte, dass auch unstrukturierte Daten beschriftet werden können, wie es bei Bildern oft der Fall ist. Bilder können nach dem Hauptmotiv des Bildes beschriftet werden, z. B. als Katze oder Hund, je nachdem, welches Tier abgebildet ist.
Semistrukturierte Daten haben eine gewisse Struktur, lassen sich aber nicht so einfach in Tabellen organisieren wie strukturierte Daten. Beispiele hierfür sind die Formate XML und JSON, die beide häufig in Softwareanwendungen für die Datenübertragung, Nutzdaten und die Darstellung in flachen Dateien verwendet werden.
Die letzte Art und das letzte Format von Daten, die für KI-Anwendungen relevant sind, sind Sequenzdaten, wobei Sprache und Zeitreihen zwei gängige Beispiele sind. Sequenzdaten sind durch Daten gekennzeichnet, die in einer Reihenfolge angeordnet sind, deren Ordnungsmechanismus eine Art Index ist. Die Zeit ist der Index in Zeitreihendaten, und Sensoren in einem IoT- oder Datenerfassungssystem sind ein gutes Beispiel für eine Quelle von Zeitreihendaten.
Ein weiteres Beispiel für Sequenzdaten ist die Sprache. Sprache zeichnet sich nicht nur durch die Grammatik und die Verwendung in der Kommunikation aus, sondern auch durch die Abfolge von Buchstaben und Wörtern. Ein Satz ist eine Abfolge von Wörtern, und wenn die Wortfolge umgestellt wird, kann sie leicht eine andere Bedeutung annehmen oder im schlimmsten Fall überhaupt keinen Sinn ergeben. Die Wörter sind so angeordnet, dass sie eine ganz bestimmte Bedeutung haben und für diejenigen, die eine bestimmte Sprache sprechen, den meisten Sinn ergeben.
Speicherung und Beschaffung von Daten
Unternehmen und Menschen im Allgemeinen generieren eine Menge Daten, und zwar oft durch unterschiedliche und nicht vereinheitlichte Software- und Hardwareanwendungen, die jeweils auf einem eigenen "Backend" oder einer Datenbank aufbauen. Datenbanken werden sowohl für die dauerhafte als auch für die temporäre Speicherung von Daten verwendet. Es gibt viele verschiedene Arten von Datenbanken, z. B. die Art der physischen Datenspeicherung auf der Festplatte, die Art der gespeicherten Daten (z. B. strukturiert, unstrukturiert und semistrukturiert), die von ihnen unterstützten Datenmodelle und Schemata, die verwendete Abfragesprache und die Art, wie sie Governance- und Managementaufgaben wie Skalierbarkeit und Sicherheit handhaben. In diesem Abschnitt konzentrieren wir uns auf einige der am häufigsten verwendeten Datenbanken für KI-Anwendungen: relationale Datenbanken und NoSQL-Datenbanken.
Relationale Datenbankmanagementsysteme (RDBMS) eignen sich sehr gut für die Speicherung und Abfrage strukturierter relationaler Daten, obwohl einige auch die Speicherung unstrukturierter Daten und mehrerer Speichertypen unterstützen. Relationale Daten bedeuten, dass Daten, die in verschiedenen Teilen (d.h. Tabellen) der Datenbank gespeichert sind, oft durch vordefinierte Arten von Beziehungen miteinander verbunden sind (z.B. eins zu vielen). Jede Tabelle (oder Beziehung) besteht aus Zeilen (Datensätzen) und Spalten (Feldern oder Attributen) mit einem eindeutigen Bezeichner (Schlüssel) pro Zeile. Relationale Datenbanken bieten in der Regel Datenintegritäts- und Transaktionsgarantien, die andere Datenbanken nicht haben.
NoSQL-Datenbanksysteme wurden vor allem wegen ihrer Skalierbarkeit und hohen Verfügbarkeit entwickelt und erfreuen sich einer großen Beliebtheit. Diese Systeme zeichnen sich auch dadurch aus, dass es sich um moderne Web-Datenbanken handelt, die in der Regel schemafrei sind, eine einfache Replikation ermöglichen und über einfache Anwendungsprogrammierschnittstellen (APIs) verfügen. Sie eignen sich am besten für unstrukturierte Daten und Anwendungen mit großen Datenmengen - zum Beispiel Big Data. Viele dieser Systeme sind sogar für außergewöhnliche Anfragen und Datenmengen ausgelegt und können die Vorteile einer massiven horizontalen Skalierung (z. B. Tausende von Servern) nutzen, um die Nachfrage zu befriedigen.
Es gibt verschiedene Arten von NoSQL-Datenbanken, wobei Dokument-, Key-Value-, Graph- und Wide-Column-Datenbanken am weitesten verbreitet sind. Die verschiedenen Typen beziehen sich hauptsächlich darauf, wie die Daten gespeichert werden und welche Eigenschaften das Datenbanksystem selbst hat. Es gibt noch eine weitere Art von Datenbanksystemen, die in den letzten Jahren an Aufmerksamkeit gewonnen hat. NewSQL-Datenbanksysteme sind relationale Datenbanksysteme, die RDBMS-ähnliche Garantien mit NoSQL-ähnlicher Skalierbarkeit und Leistung kombinieren.
Spezifische Datenquellen
Es gibt viele verschiedene Arten von Datenquellen, und viele werden in einem großen Unternehmen gleichzeitig genutzt. Bestimmte Arten von Daten können zur Automatisierung und Optimierung von kundenorientierten Produkten und Dienstleistungen verwendet werden, während andere besser für die Optimierung interner Anwendungen geeignet sind. Hier ist eine Liste potenzieller Datenquellen, die wir uns einzeln ansehen werden:
-
Kunden
-
Vertrieb und Marketing
-
Operativ
-
Ereignis und Transaktion
-
IoT
-
Unstrukturiert
-
Dritte Partei
-
Öffentlich
Die meisten Unternehmen nutzen ein Kundenbeziehungsmanagement-Tool, kurz CRM. Diese Tools verwalten die Interaktionen und Beziehungen mit bestehenden und potenziellen Kunden, Lieferanten und Dienstleistern. Darüber hinaus sind viele CRM-Tools in der Lage, Multikanal-Kundenmarketing, Kommunikation, Targeting und Personalisierung entweder nativ und/oder durch Integrationen zu verwalten. Daher können CRM-Tools eine sehr wichtige Datenquelle für kundenorientierte KI-Anwendungen sein.
Obwohl viele Unternehmen CRM-Tools als primäre Kundendatenbank nutzen, werden Kundendatenplattform-Tools (CDP) wie AgilOne verwendet, um eine einzige, einheitliche Kundendatenbank zu erstellen, indem Datenquellen zu Kundenverhalten, Kundenbindung und Vertrieb kombiniert werden. CDP-Tools sind für technisch nicht versierte Personen gedacht und ähneln Data Warehouses, da sie für effiziente Analysen, das Sammeln von Erkenntnissen und gezieltes Marketing eingesetzt werden.
Verkaufsdaten gehören zu den wichtigsten, wenn nicht sogar zu den wichtigsten Daten, die ein Unternehmen hat. Typische Datenquellen sind Kassendaten für Unternehmen mit Ladengeschäften, E-Commerce-Daten für Online-Shopping-Anwendungen und Debitorenbuchhaltung für den Verkauf von Dienstleistungen. Viele Unternehmen, die Produkte vor Ort verkaufen, verkaufen ihre Produkte auch online und können daher beide Datenquellen nutzen.
Marketingabteilungen kommunizieren und bieten ihren Kunden Angebote über verschiedene Kanäle an und generieren entsprechend kanalspezifische Daten. Zu den gängigen Marketingdatenquellen gehören E-Mail, soziale Netzwerke, bezahlte Suche, programmatische Werbung, digitales Medienengagement (z. B. Blogs, Whitepapers, Webinare, Infografiken) und Push-Benachrichtigungen für mobile Apps.
Operative Daten beziehen sich auf Geschäftsfunktionen und -prozesse. Beispiele dafür sind Daten aus den Bereichen Kundenservice, Lieferkette, Lagerbestand, Bestellwesen, IT (z. B. Netzwerk, Protokolle, Server), Produktion, Logistik und Buchhaltung. Betriebsdaten lassen sich oft am besten nutzen, um tiefe Einblicke in die unternehmensinternen Abläufe zu gewinnen, um Prozesse zu verbessern und möglicherweise zu automatisieren, um Ziele wie die Steigerung der betrieblichen Effizienz und die Senkung von Kosten zu erreichen.
Für Unternehmen, die hauptsächlich digitale Produkte wie Software-as-a-Service (SaaS)-Anwendungen und mobile Apps entwickeln, werden in der Regel viele ereignis- und transaktionsbasierte Daten erzeugt und gesammelt. Auch wenn einzelne Verkäufe durchaus als transaktionsbezogen gelten können, sind nicht alle Transaktionsdaten mit Verkäufen verbunden. Zu den Ereignis- und Transaktionsdaten gehören Überweisungen, das Absenden einer Bewerbung, das Verlassen eines Online-Warenkorbs sowie Daten zur Interaktion und zum Engagement der Nutzer/innen, z. B. Clickstream-Daten und Daten, die von Anwendungen wie Google Analytics erfasst werden.
Die IoT-Revolution ist in vollem Gange. Untersuchungen zeigen, dass sie bis 2025 durch mehr als 75 Milliarden vernetzte Geräte weltweit einen wirtschaftlichen Wert von bis zu 11 Billionen Dollar generieren wird. Es versteht sich von selbst, dass die vernetzten Geräte und Sensoren eine riesige und wachsende Menge an Daten erzeugen. Diese Daten können für KI-Anwendungen sehr nützlich sein.
Unternehmen haben auch eine Menge wertvoller unstrukturierter Daten, die oft ungenutzt bleiben. Zu den unstrukturierten Daten gehören, wie bereits erwähnt, Bilder, Videos, Audio und Text. Textdaten können für Anwendungen der natürlichen Sprachverarbeitung besonders nützlich sein, wenn sie aus Kundenrezensionen, Feedback und Umfrageergebnissen stammen.
Schließlich setzen Unternehmen in der Regel mehrere Software-Tools von Drittanbietern ein, die in diesem Abschnitt vielleicht noch nicht erwähnt wurden. Viele Software-Tools ermöglichen es, Daten in andere Tools zu integrieren und sie zur Analyse und Übertragbarkeit zu exportieren. In vielen Fällen können die Daten von Drittanbietern auch gekauft werden. Und schließlich gibt es mit der explosionsartigen Entwicklung des Internets und der Open-Source-Bewegung auch eine riesige Menge an frei verfügbaren und äußerst nützlichen öffentlich zugänglichen Daten, die wir nutzen können.
Der Schlüssel zur Nutzung von Daten, um tiefgreifende Erkenntnisse zu gewinnen und KI-Lösungen zu unterstützen, sind Datenverfügbarkeit und -zugriff, die Frage, ob die Daten zentralisiert werden sollen oder nicht, sowie alle Überlegungen zur Datenbereitschaft und -qualität, die ich im nächsten Abschnitt behandle.
Datenbereitschaft und -qualität (die "richtigen" Daten)
Schließen wir dieses Kapitel mit einem wichtigen Konzept, das bei AIPB eine wichtige Rolle spielt - dem Konzept der Datenbereitschaft und -qualität. Qualitativ hochwertige und einsatzbereite Daten (wie wir sie definieren), die eine bestimmte KI-Lösung erfolgreich unterstützen können, nenne ich die "richtigen" Daten. Das ist für den Erfolg der Lösung von entscheidender Bedeutung.
Ich verwende den Begriff "Datenbereitschaft" als Sammelbegriff für die folgenden Punkte:
-
Angemessene Datenmenge
-
Angemessene Datentiefe
-
Ausgewogene Daten
-
Äußerst repräsentative und unverzerrte Daten
-
Vollständige Daten
-
Saubere Daten
Bevor wir auf die einzelnen Datenbereitschaftspunkte eingehen, wollen wir das Konzept des Merkmalsraums erläutern. Der Begriff "Merkmalsraum" bezieht sich auf die Anzahl der möglichen Merkmalswertkombinationen für alle Merkmale in einem Datensatz, der für ein bestimmtes Problem verwendet wird. In vielen Fällen führt das Hinzufügen weiterer Merkmale zu einem exponentiellen Anstieg der Datenmenge, die für ein bestimmtes Problem benötigt wird, und zwar aufgrund eines Phänomens, das als Fluch der Dimensionalität bekannt ist.
Angemessene Datenmenge
Beginnen wir mit der Notwendigkeit einer ausreichenden Menge an Daten. Genügend Daten sind notwendig, um sicherzustellen, dass die während des Lernprozesses entdeckten Beziehungen repräsentativ und statistisch signifikant sind. Und je mehr Daten du hast, desto genauer wird das Modell wahrscheinlich sein. Je mehr Daten du hast, desto genauer wird das Modell sein. Mehr Daten ermöglichen auch einfachere Modelle und eine geringere Notwendigkeit, neue Merkmale aus bestehenden Merkmalen zu erstellen - ein Prozess, der als feature engineering bekannt ist. Das ist ein Prozess, der als Feature Engineering bezeichnet wird. Bei der Entwicklung von Merkmalen kann es sich um eine einfache Umrechnung von Einheiten handeln, manchmal müssen aber auch völlig neue Messgrößen aus Kombinationen anderer Merkmale erstellt werden.
Angemessene Datentiefe
Es reicht nicht aus, generell eine ausreichende Menge an Daten zu haben: KI-Anwendungen brauchen auch genügend unterschiedliche Daten. An dieser Stelle kommt die angemessene Datentiefe ins Spiel. Tiefe bedeutet, dass es genügend abwechslungsreiche Daten gibt, die den Merkmalsraum angemessen ausfüllen - eine ausreichende Menge an Kombinationen verschiedener Merkmalswerte, damit ein Modell die zugrunde liegenden Beziehungen zwischen den Datenmerkmalen selbst sowie zwischen den Datenmerkmalen und der Zielvariable, wenn sie in gelabelten Daten vorhanden sind, richtig lernen kann.
Stell dir außerdem vor, du hast eine Datentabelle mit Tausenden von Datenzeilen. Nehmen wir an, dass die überwiegende Mehrheit der Zeilen aus genau denselben Merkmalswerten besteht, die sich wiederholen. In diesem Fall nützt uns eine große Datenmenge nichts, wenn das Modell nur die Beziehungen zwischen den wiederholten Merkmalen und dem Ziel lernen kann. Es ist sehr unwahrscheinlich, dass ein bestimmter Datensatz jede Kombination aller Merkmalswerte enthält und somit den gegebenen Merkmalsraum vollständig ausfüllt. Das ist in Ordnung und wird normalerweise auch erwartet. Mit genügend Variation in den Daten kannst du oft angemessene Ergebnisse erzielen.
Ausgewogene Daten
Ein verwandtes Konzept ist das der ausgewogenen Daten, das für gelabelte Datensätze gilt. Wie ausgewogen ein Datensatz ist, bezieht sich auf den Anteil der Zielwerte im Datensatz. Angenommen, du hast einen Datensatz mit Spam- und Nicht-Spam-Daten, mit dem du einen E-Mail-Spam-Klassifikator trainieren willst. Wenn 98 % der Daten Nicht-Spam-E-Mails und nur 2 % Spam-E-Mails sind, hat der Klassifikator nicht annähernd genug Spam-Beispiele, um zu lernen, was echte Spam-E-Mails enthalten könnten, um alle neuen und noch nicht gesehenen zukünftigen E-Mails effektiv als Spam oder Nicht-Spam zu klassifizieren. Ideal ist es, wenn die Zielwerte gleichmäßig verteilt sind, aber das ist oft schwer zu erreichen. Oft sind bestimmte Werte oder Klassen einfach seltener und daher ungleichmäßig vertreten. Es gibt einige Techniken zur Datenmodellierung, mit denen du versuchen kannst, dies zu kompensieren, aber das würde den Rahmen dieser Diskussion sprengen.
Hochrepräsentative und unverzerrte Daten
Ein weiteres verwandtes Konzept sind repräsentative Daten. Dies ist vergleichbar mit einer ausreichenden Datentiefe, um den Merkmalsraum angemessen zu füllen. Repräsentative Daten zu haben bedeutet nicht nur, den Merkmalsraum so weit wie möglich auszufüllen, sondern auch die Bandbreite und Vielfalt der Merkmalswerte zu repräsentieren, die ein bestimmtes Modell in der realen Welt unter allen gegenwärtigen und zukünftigen Umständen wahrscheinlich sehen wird. Aus dieser Perspektive ist es wichtig sicherzustellen, dass die Daten nicht nur eine ausreichende Vielfalt und Kombinationen von Merkmalswerten enthalten, sondern auch die Bereiche und Kombinationen abdecken, die in der realen Welt nach der Einführung des Modells wahrscheinlich vorkommen werden.
Wenn du mit Daten arbeitest, die eine Stichprobe oder eine Auswahl aus einem viel größeren Datensatz sind, ist es wichtig, Stichprobenverzerrungen zu vermeiden. Die Vermeidung von schiefen oder verzerrten Stichproben führt, wie bereits erwähnt, zu sehr repräsentativen Daten. Die Randomisierung ist eine wirksame Methode, um Stichprobenverzerrungen zu vermeiden. Eine andere, viel schwerwiegendere Form der Verzerrung, die vermieden werden sollte, ist die algorithmische Verzerrung, die wir in Kapitel 13 behandeln.
Vollständige Daten
Datenvollständigkeit bedeutet, dass alle Daten verfügbar sind, die führende Faktoren, Mitwirkende, Indikatoren oder andere Möglichkeiten zur Beschreibung der Daten enthalten, die die größte Beziehung und den größten Einfluss auf die Zielvariable in Anwendungen des überwachten Lernens haben. Es kann sehr schwierig sein, ein Modell zur Vorhersage von etwas zu erstellen, wenn die verfügbaren Daten nicht die Faktoren enthalten, die am meisten zum Wert dieses Etwas beitragen.
Manchmal reicht es aus, einfach zusätzliche Datenmerkmale hinzuzufügen, während in anderen Fällen neue Merkmale aus bestehenden Merkmalen und Rohdaten erstellt werden müssen - mit anderen Worten: der bereits erwähnte Feature-Engineering-Prozess. Um sicherzustellen, dass deine Daten vollständig sind, musst du auch sicherstellen, dass fehlende Werte berücksichtigt werden. Es gibt viele Möglichkeiten, mit fehlenden Werten umzugehen, z. B. Imputation und Interpolation, aber das würde hier den Rahmen sprengen.
Saubere Daten
Schließlich ist die Datenbereinigung ein entscheidender Teil der Datenvorbereitung. Zusammen mit dem Feature-Engineering und der Feature-Auswahl sind die Datenbereinigung und -vorbereitung zwei der wichtigsten Aufgaben bei der Entwicklung von KI und maschinellem Lernen. Die Datenbereinigung und -aufbereitung - oft auch als Datenmangeln, -wrangling, -verarbeitung, -umwandlung und -bereinigungbezeichnet - wirdin der Regel im Rahmen des eigentlichen Data-Science- und Modellierungsprozesses durchgeführt, auf den ich in Anhang B näher eingehe. Daten sind selten sauber und gut für maschinelles Lernen und KI-Aufgaben geeignet. In der Praxis wird oft gesagt, dass 80% der Arbeit im Bereich KI und maschinelles Lernen darin besteht, Daten zu bereinigen, und die anderen 20% sind die coolen Sachen, zum Beispiel Predictive Analytics und Natural Language Processing (NLP). Das ist das klassische Beispiel für das Pareto-Prinzip.
Wir können Daten aus vielen verschiedenen Gründen als "schmutzig" betrachten. Oft bestehen die Daten aus offensichtlichen Fehlern. Zum Beispiel könnte bei der Vorbereitung des Datensatzes ein Fehler gemacht worden sein und die Kopfzeile stimmt nicht mit den tatsächlichen Datenwerten überein. Ein anderes Beispiel wäre ein E-Mail-Adressdatenmerkmal, das als "E-Mail" gekennzeichnet ist, aber alle Werte bestehen aus einer Telefonnummer. Manchmal sind die Werte unvollständig, beschädigt oder falsch formatiert. Ein Beispiel wären Telefonnummern, bei denen aus irgendeinem Grund eine Ziffer fehlt. Vielleicht hast du Textstrings in den Daten, die eigentlich Zahlen sein sollten. Datensätze bestehen oft auch aus seltsamen Werten wie NA oder NaN (keine Zahl). Zuverlässige und fehlerfreie Daten sind ein Maß für die Wahrhaftigkeit von Daten und sehr begehrt.
Eine Anmerkung zu Ursache und Wirkung
Ein sehr wichtiges Konzept, das es zu erwähnen gilt, ist der Unterschied zwischen Ursache und Wirkung und wie sich dieser auf KI, maschinelles Lernen und Datenwissenschaft bezieht. Auch wenn es relativ einfach ist, die in den Daten erfassten Auswirkungen zu messen, ist es in der Regel viel schwieriger, die zugrunde liegenden Ursachen zu finden, die zu den beobachteten Auswirkungen führen.
In der prädiktiven Analytik gibt es Möglichkeiten, die Parameter bestimmter Modelltypen (die ich in Anhang A behandle) als Schätzung der Wirkung eines bestimmten Merkmals oder Faktors auf ein bestimmtes Ergebnis zu verwenden und damit den relativen und quantitativen Einfluss eines Prädiktors auf die Zielvariable, die uns interessiert und die wir vorhersagen wollen. Ebenso können wir mit statistischen Verfahren Korrelationen zwischen Merkmalen messen, z. B. wie stark sie miteinander verbunden sind. Beides sind sehr nützliche Verfahren und liefern nützliche Informationen, aber diese Informationen können auch irreführend sein.
Ein völlig erfundenes Beispiel zur Veranschaulichung: Vielleicht stellen wir fest, dass der Anstieg der Marshmallow-Verkäufe direkt mit den steigenden Immobilienpreisen zusammenhängt, und die Korrelation zwischen beiden scheint sehr stark zu sein. Wir könnten zu dem Schluss kommen, dass der Verkauf von Marshmallows den Anstieg der Immobilienpreise verursacht, aber wir sind klug und wissen, dass dies höchst unwahrscheinlich ist und etwas anderes dahinterstecken muss. Normalerweise sind andere Faktoren im Spiel, die wir nicht messen oder über die wir nichts wissen (d.h. die oben erwähnten Störvariablen).
In diesem Beispiel sind Marshmallows vielleicht zu einem super trendigen Dessert in Restaurants in einer Gegend geworden, in der die Nachfrage nach Immobilien und das Wachstum aufgrund des Zustroms großer Unternehmen enorm gestiegen sind. Die eigentliche Ursache für den Anstieg der Immobilienpreise ist der Zuzug von Unternehmen, und der zunehmende Verkauf von Marshmallows ist einfach ein Trend in der Region, aber beides geschieht zur gleichen Zeit.
Die wahren Ursachen eines bestimmten Effekts zu verstehen, ist ideal, denn so können wir ein tiefes Verständnis und einen tiefen Einblick gewinnen und die am besten geeigneten und optimalen Änderungen vornehmen (d.h. die richtigen Hebel um den richtigen Betrag ziehen), um ein bestimmtes Ergebnis zu erzielen. Es gibt verschiedene Test- und Versuchsmethoden (z. B. A/B und multivariate Tests), um kausale Zusammenhänge zu ermitteln, aber diese Techniken sind in der Praxis für bestimmte Szenarien (z. B. bei der Suche nach den Ursachen von Lungenkrebs) schwierig oder unmöglich. Deshalb wurden andere Verfahren entwickelt, wie z. B. die kausale Beobachtung, die versucht, die gleichen Erkenntnisse aus beobachteten Daten zu gewinnen.
Zusammenfassung
Wir hoffen, dass dieses Kapitel dir geholfen hat, die Definitionen, Arten und Unterschiede zwischen KI und den damit verbundenen Bereichen besser zu verstehen. Wir haben besprochen, wie Menschen und Maschinen lernen und dass KI und maschinelles Lernen die Techniken sind, mit denen Maschinen aus Daten lernen, ohne dass sie explizit programmiert werden müssen, und dann das gewonnene Wissen nutzen, um bestimmte Aufgaben auszuführen. Das macht die Intelligenz von Maschinen aus; es ist die geheime Soße. Sie ermöglicht es den Menschen, Analysen auf eine Art und Weise zu nutzen, zu der sie alleine nicht in der Lage wären.
Data Science hingegen steht für das, was ich die vier Säulen der Data-Science-Expertise nenne (Wirtschaft/Bereich, Mathematik/Statistiken, Programmierung und effektive Kommunikation), zusammen mit einem wissenschaftlichen Prozess, um angemessene Daten zu kultivieren und iterativ tiefe, umsetzbare Erkenntnisse zu gewinnen und KI-Lösungen zu entwickeln.
Wir haben auch darüber gesprochen, wie Daten KI-Lösungen antreiben und welche wichtigen Datenmerkmale und Überlegungen für den KI-Erfolg notwendig sind. Dazu gehören vor allem die Konzepte der Datenbereitschaft und -qualität. Beides ist Voraussetzung für den Erfolg von KI.
Mit dem Wissen aus diesem Kapitel wollen wir nun die realen Möglichkeiten und Anwendungen von KI diskutieren. Dies soll helfen, Ideen zu entwickeln und den nötigen Kontext für die Entwicklung einer KI-Vision zu schaffen, die Gegenstand von Teil II dieses Buches ist.
Get KI für Menschen und Unternehmen now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

