October 2016
Beginner
391 pages
10h 38m
English
This isn’t a complete or comprehensive introduction to Unicode; it’s just enough for you to understand the parts of Unicode that we present in Learning Perl. Unicode is tricky not only because it’s a new way to think about strings, with lots of adjusted vocabulary, but also because computer languages in general have implemented it so poorly. Perl 5.14 makes lots of improvements to Perl’s Unicode compliance, but it’s not perfect (yet). Each version since then has brought Perl closer to full compliance. It is, arguably, the best Unicode support that you will find, though.
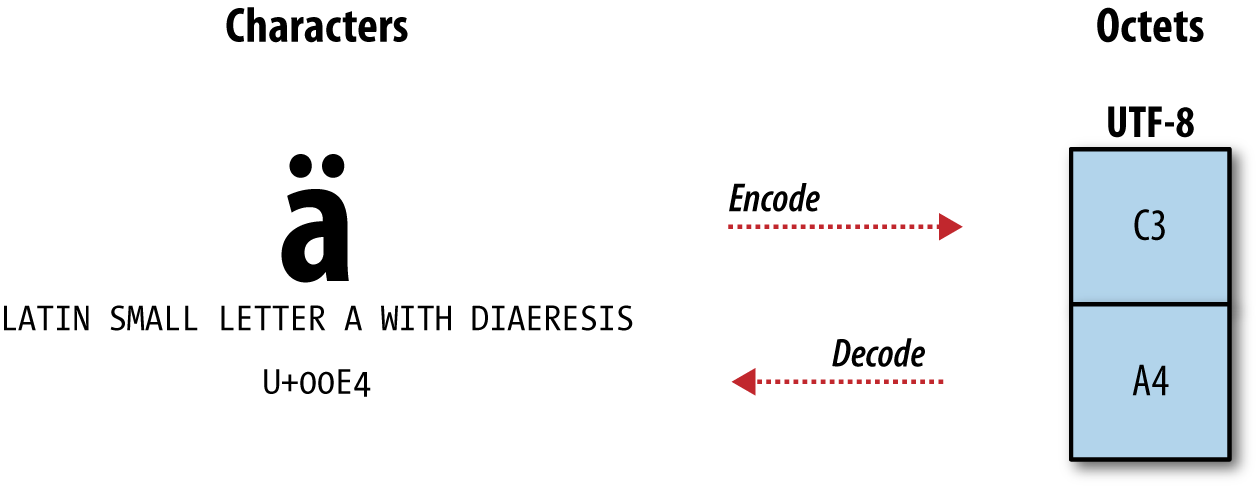
The Universal Character Set (UCS) is an abstract mapping of characters to code points. It has nothing to do with a particular representation in memory, which means we can agree on at least one way to talk about characters no matter which platform we’re on. An encoding turns the code points into a particular representation in memory, taking the abstract mapping and representing it physically within a computer. You probably think of this storage in terms of bytes, although when talking about Unicode, we use the term octets (see Figure C-1). Different encodings store the characters differently. To go the other way, interpreting the octets as characters, you decode them. You don’t have to worry too much about these because Perl can handle most of the details for you.
Read now
Unlock full access






