Chapter 1. Transforming Documents with XSLT
Extensible Stylesheet Language Transformations, or XSLT, is a straightforward language that allows you to transform existing XML documents into new XML, Hypertext Markup Language (HTML), Extensible Hypertext Markup Language (XHTML), or plain text documents. XML Path Language, or XPath, is a companion technology to XSLT that helps identify and find nodes in XML documents—elements, attributes, and other structures.
Here are a few ways you can put XSLT to work:
Transforming an XML document into an HTML or XHTML document for display in a web browser
Converting from one markup vocabulary to another, such as from Docbook (http://www.docbook.org) to XHTML
Extracting plain text out of an XML document for use in a non-XML application or environment
Building a new German language document by pulling and repurposing all the German text from a multilingual XML document
This is barely a start. There are many other ways that you can use XSLT, and you’ll get acquainted with a number of them in the chapters that follow.
This book assumes that you don’t know much about XSLT, but that you are ready to put it to work. Through a series of numerous hands-on examples, Learning XSLT guides you through many features of XSLT 1.0 and XPath 1.0, while at the same time introducing you to XSLT 2.0 and XPath 2.0.
If you don’t know much about XML yet, it shouldn’t be a problem because I’ll also cover many of the basics of XML in this book. Technical terms are usually defined when they first appear and in a glossary at the end of the book. The XML specification is located at http://www.w3.org/TR/REC-xml.html.
Another specification closely related to XSLT is Extensible Stylesheet Language, or XSL, commonly referred to as XSL-FO (see http://www.w3.org/TR/xsl/). XSL-FO is a language for applying styles and formatting to XML documents. It is similar to Cascading Style Sheets (CSS), but it is written in XML and is somewhat more extensive. (FO is short for formatting objects.) Initially, XSLT and XSL-FO were developed in a single specification, but they were later split into separate initiatives. This book does not cover XSL-FO; to learn more about this language, I suggest that you pick up a copy of Dave Pawson’s XSL-FO, also published by O’Reilly.
How XSLT Works
About the quickest way to get you acquainted with how XSLT works is through simple, progressive examples that you can do yourself. The first example walks you through the process of transforming a very brief XML document using a minimal XSLT stylesheet. You transform documents using a processor that complies with the XSLT 1.0 specification.
All the documents and stylesheets discussed in this book can be found in the example archive available for download at http://www.oreilly.com/catalog/learnxslt/learningxslt.zip. All example files mentioned in a particular chapter are in the examples directory of the archive, under the subdirectory for that chapter (such as examples/ch01, examples/ch02, and so forth). Throughout the book, I assume that these examples are installed at C:\LearningXSLT\examples on Windows or in something like /usr/mike/learningxslt/examples on a Unix machine.
A Ridiculous XML Document
Now consider the ridiculously brief XML document contained in the file msg.xml :
<msg/>
There isn’t much to this document, but it’s perfectly legal, well-formed XML. It’s just a single, empty element with no content. Technically, it’s an empty element tag .
Because it is the only element in the document,
msg is the document
element
. The document element is sometimes
called the root element
, but this is not to be confused with
the root node, which will be explained later in
this chapter. The first element in any well-formed XML document is
always considered the document element, as long as it also contains
all other elements in the document (if it has any other elements in
it). In order for XML to be
well-formed
, it must follow the syntax rules laid out
in the XML specification. I’ll highlight
well-formedness rules throughout this book, when appropriate.
A document element is the minimum structure needed to have a
well-formed XML document, assuming that the characters used for the
element name are legal XML name characters, as they are in the case
of msg, and that
angle brackets
(< and >) surround the
tag,
and the
slash (/) shows up in the
right place. In an empty element tag, the slash appears after the
element name, as in <msg/>. Tags are part of
what’s called
markup
in XML.
A First XSLT Stylesheet
You can use the XSLT stylesheet msg.xsl to transform msg.xml:
<stylesheet version="1.0" xmlns="http://www.w3.org/1999/XSL/Transform"> <output method="text"/> <template match="msg">Found it!</template> </stylesheet>
Before transforming msg.xml with msg.xsl, I’ll discuss what’s in this stylesheet. You’ll notice that XSLT is written in XML. This allows you to use some of the same tools to process XSLT stylesheets that you would use to process other XML documents.
The stylesheet element
The first element in msg.xsl is
stylesheet:
<stylesheet version="1.0" xmlns="http://www.w3.org/1999/XSL/Transform">
This is
the document element for stylesheet, one of two
possible document elements in XSLT. The other possible document
element is transform
, which is actually just a synonym for
stylesheet. You can use one or the other, but, for
some reason, I see stylesheet used more often than
transform, so I’ll knuckle under
and use it also. Whenever I refer to stylesheet in
this book, the same information applies to the
transform element as well. You are free to choose
either for the stylesheets you write. The
stylesheet and transform
elements are documented in Section 2.2 of the XSLT specification
(this W3C recommendation is available at http://www.w3.org/TR/xslt).
The version
attribute in
stylesheet is required, along with its value of
1.0. (Attributes are explained in Section 1.2.1.1, later in this chapter.) An
XSLT processor may support Versions 1.1 and 2.0 as the value of
version, but this support is only experimental at
this point (see Chapter 16). The
stylesheet element has other possible attributes
beside version, but don’t worry
about those yet.
The XSLT namespace
The
xmlns
attribute is a special attribute for
declaring a namespace. This attribute, together with a
Uniform Resource Identifier (URI)
value, is called a
namespace
declaration:
xmlns="http://www.w3.org/1999/XSL/Transform"
Such a declaration is not peculiar to stylesheet
elements, but is more or less universal in XML, meaning that you can
use it on any XML element. Nevertheless, an XSLT stylesheet must
always declare a namespace for itself in order for it to work
properly with an XSLT processor. The official namespace name, or URI,
for XSLT is http://www.w3.org/1999/XSL/Transform. A
namespace name is always a URI.
The special xmlns attribute is described in the
XML namespaces specification, officially,
“Namespaces in XML” (http://www.w3.org/TR/REC-xml-names). A
namespace declaration associates a namespace name with elements and
attributes that attempt to make such names unambiguous.
The output element
The stylesheet element is followed by an optional
output
element. This element has 10 possible
attributes, but I’ll only cover
method
right now:
<output method="text"/>
The value text in the method
attribute signals that you want the output to be plain text. The
default output method for XSLT is xml, and another
possible value is html. XSLT 2.0 also offers
xhtml (see Chapter 16).
There’s more to tell about the
output element, but I’ll leave it
at that until Chapter 3. In the XSLT
specification, the output element is discussed in
Section 16.
The template element
Next up in msg.xsl is the
template
element. This element is really at the
heart of what XSLT is and does. A template rule consists of two parts: a
pattern to match, and a sequence constructor (so named in XSLT 2.0).
The match attribute of template
contains a pattern, and the pattern in this
instance is merely the name of the element msg:
<template match="msg">Found it!</template>
A pattern attempts to identify nodes in a source document, but has
some limitations, which will come more fully to light in Chapter 4. A sequence
constructor
is a list of things telling the
processor what to do when a pattern is matched. This very simple
sequence constructor just tells the processor to write the text
Found
it! when the pattern is
matched. (I won’t use the phrase sequence
constructor much in this book but will usually just use
the term
template
instead.) Put another way, when an XSLT processor finds the
msg element in the source document
msg.xml, it writes the text Found
it! from the template to output. When a template writes
text from its content to the result tree, or triggers some other sort
of output, the template is said to be
instantiated.
The source document becomes a source tree when it is processed by an XSLT processor. Such source documents are usually files containing XML documents, such as msg.xml. The result of a transformation becomes a result tree within the processor. The result tree is then serialized to standard output (most often the computer’s display screen) or to an output file. The source or result of a transformation, however, doesn’t have to be a file. A source tree could be built just as easily from an input stream as from a file, and a result tree could be serialized as an output stream.
Tip
The output and template
elements are called
top-level
elements. They are two of a dozen
possible top-level elements that are defined in XSLT 1.0. They are
called top-level elements because they are contained within the
stylesheet element.
The root node
Another way you
could write a location path is with a slash
(/)
. In
XPath, a slash by itself indicates the
root node or starting point of the document, which comes
before the first element in the document or
document element. A
node
in XPath represents a distinct part of an XML document. A few
examples of nodes are the root node, element nodes, and attribute
nodes. (You’ll get a more complete explanation of
nodes in Chapter 4.)
In root.xsl, the
match
attribute in
template matches a root node in any source
document:
<stylesheet version="1.0" xmlns="http://www.w3.org/1999/XSL/Transform"> <output method="text"/> <template match="/">Found it!</template> </stylesheet>
The msg element is the document element of
msg.xml, and it is really the only element in
msg.xml. The template in
root.xsl only matches the root node
(/), which demarcates the point at which
processing begins, before the document element. But because the
template processes the children of the root node, it finds
msg in the source tree as a matter of course.
Because of a feature called built-in templates , this stylesheet will produce the same results as msg.xsl. Just trust me on this for now: it would be overwhelming at this point to go into all the ramifications of the built-in templates. I will say this, though: built-in templates automatically find nodes that are not specifically matched by a template. This can rattle nerves at first, but you’ll get more comfortable with built-in templates soon enough.
Using Client-Side XSLT in a Browser
Now comes the action. An XSLT processor is probably readily available to you on your computer in a browser such as Microsoft Internet Explorer (IE) Version 6 or later, Netscape Navigator (Netscape) Version 7.1 or later, or Mozilla Version 1.4 or later. All three of these browsers have client-side XSLT processing ability already built-in.
A common way to apply an XSLT stylesheet like msg.xsl to the document msg.xml in a browser is by using a processing instruction. You can see a processing instruction in a slightly altered version of msg.xml called msg-pi.xml . Open the file msg-pi.xml from examples/ch01 with one of the browsers mentioned. The result tree (a result twig, really) is displayed. Figure 1-1 shows you what the result looks like in IE Version 6, with service pack 1 (SP1). I explain how msg-pi.xml works in the section “The XML Stylesheet Processing Instruction” which follows.
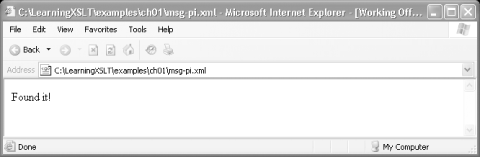
When the XSLT processor in the browser found the pattern identified
by the template in msg.xsl, it wrote the string
Found it! onto the browser’s
canvas or rendering space.
Warning
If you look at the source for the page using View → Source or View → Page Source, you will see that the source tree for the transformation (the document msg-pi.xml) is displayed, not the result tree.
The XML Stylesheet Processing Instruction
To apply an XSLT stylesheet to an XML document with a browser, you must first add an XML stylesheet processing instruction to the document. This is the case with msg-pi.xml, which is why you can display it in an XSLT-aware browser. A processing instruction, or PI, allows you to include instructions for an application in an XML document.
The document msg-pi.xml, which you displayed earlier in a browser, contains an XML stylesheet PI:
<?xml-stylesheet href="msg.xsl" type="text/xsl"?>
<msg/>The XML stylesheet PI should always come before the document element
(msg in this case), and is part of what is called
the prolog of an XML document. The purpose of
this PI is similar to one of the purposes of the
link tag in HTML, that is, to associate a
stylesheet with the document. Usually, there is only one XML
stylesheet PI in a document, but under certain circumstances, you can
have more than one.
Tip
For the official story on PIs in XML, refer to Section 2.6 of the XML
specification. The xml-stylesheet PI is documented
in the W3C Recommendation “Associating Style Sheets
with XML Documents” (http://www.w3.org/TR/xml-stylesheet/).
In the XML stylesheet PI, the term xml-stylesheet is the target of the PI. The target identifies the name, purpose, or intent of the PI. This assumes that the application understands what the PI target is. Home-grown PIs are usually application-specific, but the XML stylesheet PI is widely supported and understood. If you invent a new, unique PI target, you also have to write the code to process your PI.
Attributes and pseudoattributes
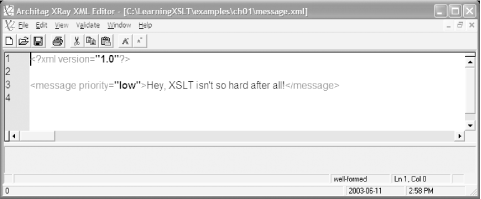
In XML, attributes may only appear in element start tags or empty element tags, as shown in this element start tag (from message.xml):
<message priority="low">
This message element contains an attribute, with
priority as the attribute name and
low as the attribute value. The attribute name and
value are separated by an equals sign
(=
). In well-formed XML,
attribute values must always be surrounded by either
single
(') or double (“) quotes. The quotes
must not be mixed together. You can read more about attributes in
Section 3.1 of the XML specification.
The constructs that follow the target in the XML stylesheet PI,
href
and
type
, are not attributes but are
pseudoattributes. PIs can contain any legal XML characters
between the target and the closing ?>, not just
text that looks like attributes. For example, the following PI is
perfectly legal:
<?do not go gentle into that good night?>
The first word following <? is
do. This is the target of the PI, and there must
be no space between <? and the target. The
target is followed by the data not
go
gentle
into
that
good
night. This
may not be complete nonsense to a Dylan Thomas fan, but a PI will be
nonsense to an application unless the PI contains a target and other
data that the application understands and knows what to do with it.
If an XML processor does not understand the content of a PI, the
consequences are not dire. The processor will simply ignore the PI
and move on. Pseudoattributes structure the data so processors may
have an easier time interpreting it.
The href pseudoattribute contains a value that is
a URI reference. This URI specifies the relative location of the
stylesheet msg.xsl. An XSLT processor knows
where to find resources relative to its base
URI
. The
base URI is usually the directory that holds the source document. The
other pseudoattribute, type, identifies the
content type of the stylesheet, text/xsl. The
content type identifies the content of the stylesheet as XSL or XSLT
text.
Using apply-templates
One possible element that can be contained inside of a
template element is
apply-templates. Because
apply-templates
is contained in
template, it is called a child
element
of template. In
XSLT, apply-templates is also termed an
instruction
element
. An instruction element in XSLT is
always contained within something called a
template
.
A template is a series of transformation instructions that usually
appear within a template element, but not always.
A few other elements can contain instructions, as you will see later
on. XSLT 1.0 has a number of instruction elements that will
eventually be explained and discussed in this book.
The apply-templates element triggers the
processing of the children of the
node
in the source document that the template matches. These children
(child nodes)
can be elements, attributes, text, comments, and processing
instructions. If the apply-templates element has a
select attribute, the XSLT processor searches
exclusively for other nodes that match the value of the
select attribute. These nodes are then subject to
being processed by other templates in the stylesheet that match those
nodes.
Let’s not fret about what all that means right now.
It’s hard to follow exactly what XSLT is doing when
you are just starting out. I’ll cover more about how
apply-templates works in the next chapter.
Analysis of message.xml
To understand how apply-templates works, first
take a look at the document message.xml in
examples/ch01:
<?xml version="1.0"?> <message priority="low">Hey, XSLT isn't so hard after all!</message>
The message element in
message.xml has an attribute in its start tag:
the priority attribute with a value of
low. Also, this element is not empty; it holds the
string Hey, XSLT
isn't
so
hard
after
all! In the terminology of XML, this text is
called parsed character
data
, and in the terminology of XPath, this
text is called a text
node
.
The XML declaration
Before the message element, at the beginning of
this document, is something that looks like a processing instruction,
but it’s not. It’s called an
XML declaration
.
The XML declaration is optional. You don’t have to use one if you don’t want to, but it’s generally a good idea. If you do use one, however, it must be on the first line to appear in the XML document. Because it must appear before the document element, that also means that an XML declaration is part of the prolog, like the XML stylesheet PI.
If present, an XML declaration must provide version information.
Version information appears in the form of a pseudoattribute,
version, with a value representing a version
number, which is almost always 1.0. Other values
are possible, but none are authorized at the moment because an XML
version later than 1.0 has not yet been approved.
Tip
XML 1.1, which mainly adds more characters to the XML Unicode character repertoire, is currently under consideration, and may become a W3C recommendation by the time you read this book or shortly thereafter. You can see the XML 1.1 spec at http://www.w3.org/TR/xml11/.
You can also declare character encoding for a document with an XML declaration, and whether a document stands alone. The XML declaration will be covered in more detail in Chapter 3. See Section 2.8 of the XML specification for more information on XML declarations.
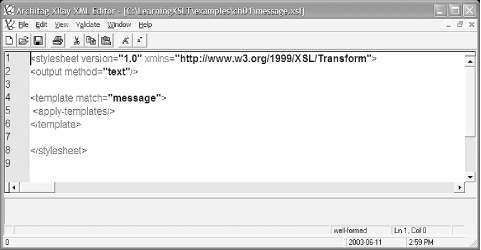
The stylesheet message.xsl in
examples/ch01 includes the
apply-templates
element:
<stylesheet version="1.0" xmlns="http://www.w3.org/1999/XSL/Transform">
<output method="text"/>
<template match="message">
<apply-templates/>
</template>
</stylesheet>Now you’ll get a chance to apply this stylesheet to message.xml and see what happens. Instead of using a browser as you did earlier, this time you’ll have a chance to use Xalan, an open source XSLT processor from Apache, written in both C++ and Java. The C++, command-line version of Xalan runs on Windows plus several flavors of Unix, including Linux. (When I refer to Unix in this book, it usually applies to Linux; when I refer to Xalan, I mean Xalan C++, unless I mention the Java version specifically.)
Running Xalan
To run Xalan, you also need the C++ version of Xerces, Apache’s XML parser. You can find both Xalan C++ and Xerces C++ on http://xml.apache.org. After downloading and installing them, you need to add the location of Xalan and Xerces to your path variable. If you are unsure about how to install Xalan or Xerces, or what a path variable is, you’ll get help in the appendix.
Once Xalan and Xerces are installed, while still working in examples/ch01 directory, type the following line in a Unix shell window or at a Windows command prompt:
xalan message.xml message.xsl
If successful, the following results should be printed on your screen:
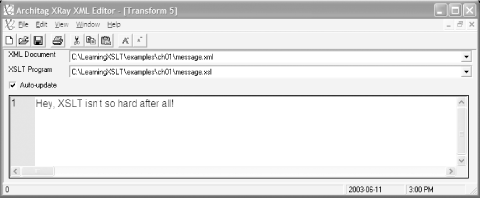
Hey, XSLT isn't so hard after all!
So what just happened? Instead of the processor writing content from
the stylesheet into the result tree by using instructions in the
stylesheet message.xsl, Xalan grabbed content
from the document message.xml. This is because,
once the template found a matching element (the
message element),
apply-templates processes its children. The only
child that message had available to process was a
child text node—the string Hey, XSLT isn't so hard
after all!
The reason why this works is because of a built-in template that
automatically renders text nodes. You’ll learn more
about how apply-templates and built-in templates
work in more detail in later chapters. If you want to go into more
depth, you can read about apply-templates in
Section 5.4 of the XSLT specification.
More About Xalan C++
If you enter the name xalan on a command line, without any arguments, you will see a response like this:
Xalan version 1.5.0
Xerces version 2.2.0
Usage: Xalan [options] source stylesheet
Options:
-a Use xml-stylesheet PI, not the 'stylesheet' argument
-e encoding Force the specified encoding for the output.
-i integer Indent the specified amount.
-m Omit the META tag in HTML output.
-o filename Write output to the specified file.
-p name expression Sets a stylesheet parameter.
-u Disable escaping of URLs in HTML output.
-v Validates source documents.
-? Display this message.
- A dash as the 'source' argument reads from stdin.
- A dash as the 'stylesheet' argument reads from stdin.
'-' cannot be used for both arguments.)The command-line interface for Xalan offers you several options that
I want to bring to your attention. For example, if you want to direct
the result tree from the processor to a file, you can use the
-o option:
xalan -o message.txt message.xml message.xsl
The result of the transformation is redirected to the file named
message.txt. Depending on your platform (Unix or
Windows), use the cat or type
command to display the contents of the file
message.txt:
Hey, XSLT isn't so hard after all!
As with a browser, you can also use Xalan with a document that has an XML stylesheet PI, such as message-pi.xml:
<?xml version="1.0"?>
<?xml-stylesheet href="message.xsl" type="text/xsl"?>
<message priority="low">Hey, XSLT isn't so hard after all!</message>To process this document with the stylesheet in its stylesheet PI,
use Xalan’s -a option on the
command line, like this:
xalan -a message-pi.xml
The results of the command should be the same as when you specified both the document and the stylesheet as arguments to Xalan.
Using Other XSLT Processors
There are a growing number of XSLT processors available. Many of them are free, and many are available on more than one platform. In this chapter, I have already discussed the Xalan command-line processor, but I will also demonstrate others throughout the book.
Generally, I use Xalan on the command line, which runs on either Windows or Unix, but you can also choose to use a browser if you wish, or another command-line processor, such as Michael Kay’s Instant Saxon—a Windows executable, command-line application written in Java. Another option is Microsoft’s MSXSL, which also runs in a Windows command prompt. You may prefer to use a processor with a Java interpreter, or you may want to use one of these XSLT processors with a graphical user interface, such as:
Victor Pavlov’s CookTop (http://www.xmlcooktop.com)
Architag’s xRay2 (http://architag.com/xray/)
Altova’s xmlspy (http://www.xmlspy.com)
SyncRO Soft’s <oXygen/> (http://www.oxygenxml.com)
eXcelon’s Stylus Studio (http://www.stylusstudio.com)
I’ll demonstrate here how to use one of these graphical editors: xRay2.
Using xRay2
Architag’s xRay2 is a free, graphical XML editor with XSLT processing capability. It is available for download from http://www.architag.com/xray. xRay2 runs only on the Windows platform. Assuming that you have successfully downloaded and installed xRay2, follow these steps to process a source document with a stylesheet:
Launch the xRay2 application.
Open the file message.xml with File → Open from your working directory, such as from C:\LearningXSLT\examples\ch01\.
Open the file message.xsl with File → Open.
Choose File → New XSLT Transform.
In the XML Document pull-down menu, select message.xml (see the result in Figure 1-2).
In the XSLT Program pull-down menu, select message.xsl (see what it should look like in Figure 1-3).
If it is not already checked, check Auto-update.
The result of the transformation should appear in the transform window (see Figure 1-4).
Those are the steps for transforming a file with xRay2. When I suggest transforming a document anywhere in this book, you can use xRay2—or any other XSLT processor you prefer—instead of the one suggested in the example (unless there is a specifically noted feature of the processor used in the example).
Summary
This chapter has given you a little taste of XSLT—how it works and a few things you can do with it. After reading this introduction, you should understand the ground rules of XSLT stylesheets and the steps involved in transforming documents with a browser, a command-line processor like Xalan, or a processor with a graphical interface, such as xRay2. In the next chapter, you will learn how to create elements, attributes, text, comments, and processing instructions in a result tree using both XSLT instruction elements and literal result elements.
Get Learning XSLT now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

