Chapter 4. Traversing the Tree
In the previous three chapters, you have seen a number of examples that use the XML Path Language (XPath). This chapter discusses XPath topics, such as the XPath data model, the difference between patterns and expressions, predicates, the difference between abbreviated and unabbreviated location paths, axes, and node and name tests. (XPath and XSLT functions will be discussed in the next chapter.)
Tip
Though it is not exactly light reading, you may want to print a copy of the XPath 1.0 specification. It is a little over 30 pages. You can find it at http://www.w3.org/TR/xpath.
The XPath Data Model
The foundation of XPath is its view of the XML document as a tree with branches called nodes. XPath’s data model is a tree data model. The tree model comes to us from traditional computer science. It is a way of organizing or imagining the order of data in a hierarchical or structured way. To illustrate the tree model, Figure 4-1 represents roughly the XML document nodes.xml found in examples/ch04 as a tree of nodes.
Each box in Figure 4-1 represents a node or point in the tree structure of the document. In the XPath data model, a node represents part of an XML document such as the root or starting point of the document, elements, attributes, text, and so on. In the traditional tree model, the lines connecting the nodes are called edges . If a node does not have children, it is called a leaf node . (The terms edge and leaf node are not used in the XPath spec.) If you follow the edges, you are following a path. The nodes in a tree have family relationships: parent-child, ancestor-descendant, sibling, and so forth.
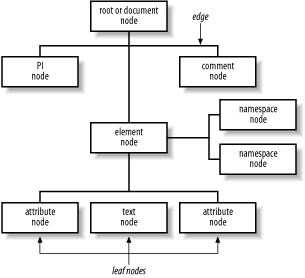
XPath Nodes
An XML document, according to the XPath 1.0 data model, can be conceptually described as having seven possible node types:
Root (called the document node in XPath 2.0)
Element
Attribute
Text
Namespace
Comment
Processing instruction
You have already encountered nodes of all these types earlier in the book. For further illustration, the file nodes.xml contains at least one occurrence of each of these nodes:
<?xml-stylesheet href="tree-view.xsl" type="text/xsl"?> <!-- Last invoice of day's batch --> <amount vendor="314" xml:lang="en" xmlns="urn:wyeast-net:invoice">7598.00</amount>
Each node is labeled with its appropriate XPath 1.0 node type in Figure 4-2, and Table 4-1 describes each of the XPath node types.

|
Node type |
Description |
|
The whole document, starting conceptually at the beginning of the document, before the document or root element. The root node must have at least (and at most) one element child: the document element. In the XPath model, a root node may also have processing instruction and comment children. Other children are ignored. | |
|
An element, such as | |
|
An attribute, such as | |
|
Text inside of an element, such as | |
|
A namespace name, a URI such as the URN
| |
|
A comment, such as | |
|
A processing instruction, such as |
Tip
XPath 2.0, which is not yet an approved recommendation of the W3C, takes a slightly different approach in regard to nodes and types, at least at this book’s level of detail. You will be introduced to XPath 2.0 in Chapter 16. For more information, see http://www.w3.org/TR/xpath20/
A View of the Tree
To get a good idea of the how the XPath 1.0 data model views an XML document as a tree, you can use the ASCII Tree Viewer (the stylesheet ascii-treeview.xsl ) created by Mike Brown and Jeni Tennison. This stylesheet labels all seven node types using plain text or ASCII output. An edited version of this stylesheet is available in examples/ch04.
When you process nodes.xml with ascii-treeview.xsl using Xalan, as follows:
xalan nodes.xml ascii-treeview.xsl
you will see each of the nodes labeled in the output:
root
|_ _ _processing instruction target='xml-stylesheet' instruction=
'href="tree-view.xsl" type="text/xsl"'
|_ _ _comment ' Last invoice of day's batch '
|_ _ _element 'amount' in ns 'urn:wyeast-net:invoice' ('amount')
| \_ _ _attribute 'vendor' = '314'
| \_ _ _attribute 'lang' in ns 'http://www.w3.org/XML/1998/namespace' ('xml:lang') = 'en'
| \_ _ _namespace 'xml' = 'http://www.w3.org/XML/1998/namespace'
| \_ _ _namespace 'xmlns' = 'urn:wyeast-net:invoice'
|_ _ _text '7598.00'Tip
You can download the original, unedited version of ascii-treeview.xsl from http://skew.org/xml/stylesheets/treeview/ascii/. I have edited this stylesheet so that it will find and label namespace nodes and ignore insignificant whitespace.
The stylesheet referenced at the top of nodes.xml is tree-view.xsl. It is the Pretty XML Tree Viewer, also developed by Mike Brown and Jeni Tennison. It produces HTML output rather than ASCII. You can get tree-view.xsl , along with its required companion stylesheet, from http://skew.org/xml/stylesheets/treeview/html/. There already are edited copies of these stylesheets in examples/ch04.
If you open and view nodes.xml with IE, you will see the result shown in Figure 4-3. The seven node types are all represented, as you can see from the labels.
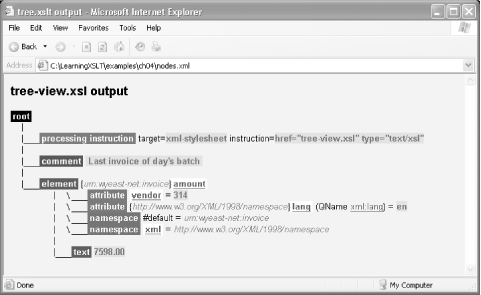
As with ascii-treeview.xsl, I have made a few
small edits to tree-view.xsl. The
edit changes a parameter value to a nonzero value, switching on the
behavior that makes the stylesheet show namespace nodes. I have also
uncommented a line so that insignificant whitespace is stripped using
the strip-space element. You will learn more about
parameters in Chapter 7. You will learn about
stripping and preserving insignificant space later in the book.
What’s a Context?
In order to work properly, XPath and XSLT have to keep track of where processing occurs in the source document and what node it’s working on at any particular moment. XPath and XSLT have developed a vocabulary to describe such things. The more familiar you are with the terms described in the following paragraphs, the better off you will be when working with XSLT. You will get more and more exposure to these terms throughout the remainder of this book.
Most of the terms revolve around something called a
context
.
In XPath, the context
node
is the node that is currently selected
and being processed. The context node is usually the node addressed
by a select attribute, such as with the
apply-templates element. The XSLT spec also refers
to a current node
, which is almost always the same thing as
the context node. You can retrieve the current node with the
current( ) function, an XSLT function that
I’ll discuss in Chapter 5.
Tip
The only time the context node and the current node are not the same
thing is when a predicate is being evaluated. A predicate is a filter
for nodes, contained in square brackets, such as in
amount[@xml:lang='en']. When a node is being
evaluated within the square brackets or predicate, it temporarily
becomes the current node. This is the only time that the context node
and the current node are not identical. You’ll learn
about predicates in Section 4.5, later in this chapter.
A
node-set
is a set of unordered nodes that can be of different kinds. A
node-set can consist of an unordered group of element, attribute, and
text nodes, for example. The current node list
is an XSLT term and refers to an ordered set of nodes, obtained when,
for example, the select attribute of the
apply-templates element is processed.
The context position , represented by a nonzero, positive integer, is an XPath term that indicates the node at which processing is positioned, something like the current position when iterating through an array or vector in a programming language. The context size represents the number of nodes in the current list, and is also a nonzero, positive integer. This is like an array size, though numbering starts at 1, not 0.
The term document order refers to the order in which nodes actually appear as they are encountered in a source document. The current node list can be a subset of the nodes found in document order in a source tree. Document order can be in forward or reverse, along a given axis such as the child or parent axis (see Section 4.6, later in the chapter for a more thorough explanation).
If you don’t feel like you’ve got your arms around all these terms, that’s okay: you’ll get more exposure to them over time and they’ll eventually sink in. Now that you have a basic understanding of the XPath data model and some of its essential terminology, I’ll start exploring expressions and patterns after a brief discussion of location paths.
Location Paths
The basic syntax of XPath is the location path. A location path consists of one or more items that identify nodes in a tree using the XPath data model and syntax. For example, looking back at nodes.xml, the following simple location path identifies the sole element node in that document:
amount
This is actually XPath’s abbreviated syntax form, which you’ve seen a lot of already (you’ll learn more about XPath’s unabbreviated syntax a little later). This path assumes that the node will be found along the child axis (discussed in Section 4.6, later in this chapter).
Now, I’ll add another location step to the location path:
amount/@vendor
Location steps are separated by a slash
(/
). This location path
has two steps. The first step identifies the
amount
element, and the second step identifies
the vendor
attribute. This path assumes that the
node will be found along the child axis followed by the attribute
axis.
Another location path might be:
/amount/@xml:lang
Notice that this location path is preceded by a
slash. The slash at the beginning of the location path indicates the
root or document node, so this path tells the processor that the
amount element must be the document element
because it is the element child of the root node. The next step
locates the xml:lang attribute that is associated
with amount. Now here is another one:
/comment( )
This path will locate a comment that is a child of the root or
document node. comment( ) is a node test. A
node
test
checks whether a node matches a particular kind of node such as
comment( ), text( ),
processing-instruction( ), or node(
) for any node.
Now, I’ll go into more detail about location paths by describing XPath expressions.
Expressions
An XPath expression allows you to go beyond the basic location of an element or attribute in a document by name, as you have just seen. Expressions let you:
Specify location paths using names with either an abbreviated syntax, such as
name/family, or unabbreviated syntax, such aschild::name/child::family.Use XPath axes such as parent, as in
.. in abbreviated syntax, orparent::namein unabbreviated.Perform basic arithmetic such as addition (
+), subtraction (-), multiplication (*), division (div), and modulo (mod)—using parentheses optionally—such as3+(5*5).Perform Boolean logic using the operators
and,or,=,!=,<=,<,>=and>such as2<3(because expressions occur in attribute values, you must use<instead of<).Reference variables defined elsewhere, such as
$var=3(=in XPath tests for equivalence, and doesn’t perform assignment; Chapter 7 describes variables).Call functions such as
current( ),local-name( ), orposition( )(Chapter 5 discusses functions).Perform name and node tests such as
rng:*(name test) ortext( )(node test).
When an XPath expression is evaluated, it can return an object of one of four types:
- node-set
An unordered collection of zero or more nodes without duplicates.
- boolean
A value of either true or false.
- number
A floating-point number.
- string
A string that is a sequence of legal Unicode characters.
By return, I mean that the XSLT processor hands back a node to the processing stream, in this case, one that has a particular type.
An XSLT processor can also return a type added by the XSLT spec called a result tree fragment . This is a portion of the result tree that may or may not be well-formed XML and is treated like a string. A result tree fragment is not an XPath type but was added to the four XPath types by the XSLT spec.
Tip
XPath, by the way, isn’t locked into XSLT alone. Beyond XSLT, XPath is also used in other W3C specifications such as the XPointer scheme (see http://www.w3.org/TR/xptr-xpointer/), in XQuery (see http://www.w3.org/TR/xquery), and in XForms (see http://www.w3.org/TR/xforms/). The W3C is also working on integrating XPath with DOM, the Document Object Model (see http://www.w3.org/TR/DOM-Level-3-XPath/).
Expressions occur in certain attribute values in XSLT. These features will be explored later in the chapter, but before moving any further, it’s important that you understand what patterns are and how they work.
What Is a Pattern?
An XSLT pattern is a subset of an XPath expression. It is part of a template rule that allows the template to test whether a node matches certain criteria. This subset of expressions called a pattern is defined by XSLT, not by XPath.
A pattern can only evaluate a node-set, meaning a group of zero or
more nodes. A node-set type is the only thing a pattern can evaluate
or return. A pattern can match elements and attributes and use node
tests (see Section 4.7, later in
this chapter) and predicates (see the next section, Section 4.5). It can also use the
id( ) function (demonstrated in Chapter 5) and the key( ) function
(described in Chapter 11), but
that’s about the sum of it.
There are four places in XSLT where you can identify a pattern, each
time as a value of an attribute. The places that specify a pattern
are in the match attribute of
template and key elements, and
in the count and from
attributes of the number element. You can read
more about patterns in Section 5.2 of the XSLT specification.
A pattern is one of two parts of a template rule , which, according to XSLT 2.0, consists of a pattern described in an attribute value and a sequence constructor, which tells the processor what to do—what items to produce—when it encounters the pattern and therefore is instantiated (see Section 2.4.1 of the XSLT 2.0 spec available at http://www.w3.org/TR/xslt20/).
Predicates
A predicate is a filter that can be used with a pattern as well as an expression. It checks to see whether a node-set matches an expression contained in square brackets. Again harking back to nodes.xml, here is an example of a pattern with a predicate:
amount[@vendor = '314']
One way to think about predicates is in terms of the word
where—in other words, this pattern matches
an amount element where the
vendor attribute associated with
amount has a value of 314. (As
I mentioned earlier in the chapter, when the predicate is evaluated,
the node in the predicate temporarily becomes the current node.)
The content between the square brackets is actually an expression.
This is the only way that a pattern makes use of an expression. You
can, of course, use predicates with expressions, as well as with
patterns. If a predicate matches a given criteria, the predicate
returns a Boolean value of true, or
false if otherwise. In other words, if the
expression in a predicate matches a node-set in a pattern, it returns
true, and the template that matches the pattern is
instantiated; if there is no match, the template is skipped.
Look at another example of a predicate:
amount[current( ) = '7598.00']
This one checks to see whether the content of
amount is 7598.00 and returns
true if it is. This could also be written as:
amount[. = '7598.00']
Here is yet another example:
amount[position( )=1]
This tests to see whether amount is the first node
in the set. This could also be written as:
amount[1]
To illustrate these concepts further, Example 4-1
shows the document names.xml.
It’s a slightly different version of
wg.xml, which you worked with in the last
chapter. The last and first
elements have been changed to family and
given, respectively. Several attributes and an
encoding declaration have been added.
<?xml version="1.0" encoding="ISO-8859-1"?> <!-- names of persons acknowledged as current and past members of the W3C XML Working Group at the time of the publication of the first edition of the XML specification on 1998-02-10 --> <names> <name> <family>Angerstein</family> <given>Paula</given> </name> <name title="chair"> <family>Bosak</family> <given>Jon</given> </name> <name title="editor"> <family>Bray</family> <given>Tim</given> </name> <name title="technical lead"> <family>Clark</family> <given>James</given> </name> <name> <family>Connolly</family> <given>Dan</given> </name> <name> <family>DeRose</family> <given>Steve</given> </name> <name> <family>Hollander</family> <given>Dave</given> </name> <name> <family>Kimber</family> <given>Eliot</given> </name> <name> <family>Magliery</family> <given>Tom</given> </name> <name> <family>Maler</family> <given>Eve</given> </name> <name> <family>Maloney</family> <given>Murray</given> </name> <name> <family>Murata</family> <given>Makoto</given> </name> <name> <family>Nava</family> <given>Joel</given> </name> <name> <family>O'Connell</family> <given>Conleth</given> </name> <name title="editor"> <family>Paoli</family> <given>Jean</given> </name> <name> <family>Sharpe</family> <given>Peter</given> </name> <name title="editor"> <family>Sperberg-McQueen</family> <given>C. M.</given> </name> <name> <family>Tigue</family> <given>John</given> </name> </names>
Now consider the stylesheet pattern.xsl , shown in Example 4-2.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:apply-templates select="names"/>
</xsl:template>
<xsl:template match="names">
<xsl:apply-templates select="name[4]/@title"/>
</xsl:template>
<xsl:template match="name[4]/@title">
<xsl:text>The XML 1.0 WG's </xsl:text>
<xsl:value-of select="."/>
<xsl:text> was </xsl:text>
<xsl:value-of select="../given"/>
<xsl:text> </xsl:text>
<xsl:value-of select="../family"/>
<xsl:text>.</xsl:text>
</xsl:template>
</xsl:stylesheet>Apply this stylesheet to names.xml with Xalan:
xalan names.xml pattern.xsl
and you’ll see this one-line result:
The XML 1.0 WG's technical lead was James Clark.
There are other, more efficient ways to write this stylesheet, but
this version suffices for the moment. Each match
attribute in each of the three templates contains a pattern:
The pattern in the first template rule,
/, matches the root or document node and then applies the template that matchesnames.The pattern in the second template rule matches the document element
names, and then applies the template that matches thetitleattribute (@title) of the fourthnamechild (name[4]) ofnames.The third and final pattern matches the
titleattribute of the fourthnameelement.
When the final template is instantiated, it uses several
value-of elements to take information out of the
source document, and also uses four text elements
to put text on the result tree. The period (.) in
the select attribute of the first
value-of selects the current node.
Matching Multiple Nodes with a Pattern
You can match a union of
multiple nodes by using the union operator
(|
) in a pattern or
expression. The union operator denotes alternatives, that is, when
you see the union operator separating node names, read the word
or. To see what I mean, I’ll
show you union.xsl, which produces valid, string
HTML 4.01 output. But first, Example 4-3 shows
provinces.xml, along with an internal subset
DTD, which contains a list of Canadian provinces.
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet href="union.xsl" type="text/xsl"?> <!DOCTYPE provinces [ <!ELEMENT provinces (province)+> <!ELEMENT province (name, abbreviation)> <!ATTLIST province id ID #REQUIRED> <!ELEMENT name (#PCDATA)> <!ELEMENT abbreviation (#PCDATA)> ]> <provinces> <province id="AB"> <name>Alberta</name> <abbreviation>AB</abbreviation> </province> <province id="BC"> <name>British Columbia</name> <abbreviation>BC</abbreviation> </province> <province id="MB"> <name>Manitoba</name> <abbreviation>MB</abbreviation> </province> <province id="NB"> <name>New Brunswick</name> <abbreviation>NB</abbreviation> </province> <province id="NL"> <name>Newfoundland and Labrador</name> <abbreviation>NL</abbreviation> </province> <province id="NT"> <name>Northwest Territories</name> <abbreviation>NT</abbreviation> </province> <province id="NS"> <name>Nova Scotia</name> <abbreviation>NS</abbreviation> </province> <province id="NU"> <name>Nunavut</name> <abbreviation>NU</abbreviation> </province> <province id="ON"> <name>Ontario</name> <abbreviation>ON</abbreviation> </province> <province id="PE"> <name>Prince Edward Island</name> <abbreviation>PE</abbreviation> </province> <province id="QC"> <name>Quebec</name> <abbreviation>QC</abbreviation> </province> <province id="SK"> <name>Saskatchewan</name> <abbreviation>SK</abbreviation> </province> <province id="YT"> <name>Yukon</name> <abbreviation>YT</abbreviation> </province> </provinces>
This document has an internal subset DTD. The only attribute declared
is the required attribute id, which is of type ID.
This attribute type is explained further in Chapter 5.
This document may be transformed into HTML with union.xsl, shown in Example 4-4.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="html"/> <xsl:output doctype-system="http://www.w3.org/TR/html4/strict.dtd"/> <xsl:output doctype-public="-//W3C//DTD HTML 4.01//EN"/> <xsl:template match="provinces"> <html> <head><title>Provinces of Canada and Abbreviations</title></head> <body style="text-align:center"> <h3 style="text-align:center">Provinces of Canada and Abbreviations</h3> <table style="margin-left:auto;margin-right:auto" rules="all" border="4"> <thead style="background-color:black;color:white"> <tr> <th style="width:230">Province</th> <th style="width:230">Abbreviation</th> </tr> </thead> <tbody align="center"> <xsl:apply-templates select="province"/> </tbody> </table> </body> </html> </xsl:template> <xsl:template match="province"> <tr> <xsl:apply-templates select="name|abbreviation"/> </tr> </xsl:template> <xsl:template match="name|abbreviation"> <td> <xsl:apply-templates/> </td> </xsl:template> </xsl:stylesheet>
After the first template rule matches provinces,
it generates the main body of HTML markup, which includes
table-related elements such as table,
thead, and tbody, plus CSS
rules in style attributes.
The second template rule matches province nodes
and then applies templates to the name or
abbreviation children of
province. (name
|
abbreviation) surrounds the
output with tr (table row) tags. The final
template rule matches on the pattern of name or
abbreviation nodes, enclosing that output with
td (table data) tags.
When you process provinces.xml with union.xsl:
xalan provinces.xml union.xsl
you see the following outcome from processing the union of
name and abbreviation nodes.
Note how the text content of both name and
abbreviation nodes are contained in
td elements, which are children of
tr elements. This allows the columns of the table
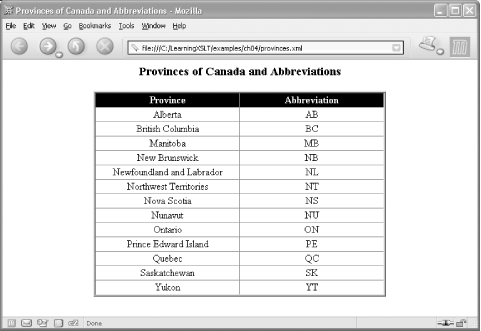
to line up properly. The resulting HTML document, listed in Example 4-5, is shown in Figure 4-4.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/ strict.dtd"> <html> <head> <META http-equiv="Content-Type" content="text/html; charset=UTF-8"> <title>Provinces of Canada and Abbreviations</title> </head> <body style="text-align:center"> <h3 style="text-align:center">Provinces of Canada and Abbreviations</h3> <table style="margin-left:auto;margin-right:auto" rules="all" border="4"> <thead style="background-color:black;color:white"> <tr> <th style="width:230">Province</th><th style="width:230">Abbreviation</th> </tr> </thead> <tbody align="center"> <tr> <td>Alberta</td><td>AB</td> </tr> <tr> <td>British Columbia</td><td>BC</td> </tr> <tr> <td>Manitoba</td><td>MB</td> </tr> <tr> <td>New Brunswick</td><td>NB</td> </tr> <tr> <td>Newfoundland and Labrador</td><td>NL</td> </tr> <tr> <td>Northwest Territories</td><td>NT</td> </tr> <tr> <td>Nova Scotia</td><td>NS</td> </tr> <tr> <td>Nunavut</td><td>NU</td> </tr> <tr> <td>Ontario</td><td>ON</td> </tr> <tr> <td>Prince Edward Island</td><td>PE</td> </tr> <tr> <td>Quebec</td><td>QC</td> </tr> <tr> <td>Saskatchewan</td><td>SK</td> </tr> <tr> <td>Yukon</td><td>YT</td> </tr> </tbody> </table> </body> </html>
Axes
XPath views
nodes along axes. An axis refers to various ways
that you can locate nodes along the edges (branches) of a tree
structure, either forward or backward. For example, the
parent axis refers to the parent of a node, and
the self axis refers only to a node itself. You
can specify a few of the axes by using the abbreviated syntax, such
as the parent (../given), child
(given), and self (.) axes, but
you can also specify them using the unabbreviated syntax, as in
parent::given, child::given,
and self::node( ). One of the reasons you would
want to use unabbreviated axes specifiers is because they allow you
to find and access nodes that are not in the current node list.
Axes are oriented along a forward or reverse direction. Only 4 of the 13 axes have a reverse orientation. For example, the ancestor axis refers to nodes that come before the context node in the reverse direction, up to and including the root node. The descendant axis, on the other hand, includes nodes that come after the context node in the forward direction.
XPath defines 13 different axes, which are all listed and described in Table 4-2.
|
Axis |
Direction |
Description |
|
Ancestor |
Reverse |
Ancestors of the context node, up to and including the root or document node. This includes the parent node. |
|
Ancestor-or-self |
Reverse |
Ancestors of the context node, including the context node itself and the root node. |
|
Attribute |
Forward |
Attributes of the element context node. |
|
Child |
Forward |
Children of the context node. |
|
Descendant |
Forward |
Descendants of the context node. |
|
Descendant-or-self |
Forward |
Descendants of the context node, up to and including the root node. |
|
Following |
Forward |
All nodes that follow the context node in the same document, in document order, excluding descendants, attribute nodes, and namespace nodes. |
|
Following-sibling |
Forward |
All sibling nodes that follow the context node, excluding attribute and namespace nodes. |
|
Namespace |
Forward |
Namespace nodes of the current context. |
|
Parent |
Forward |
Parent of the context node. |
|
Preceding |
Reverse |
All nodes that precede the context node in the same document, in document order, excluding descendants, attribute nodes, and namespace nodes. |
|
Preceding-sibling |
Reverse |
All sibling nodes that precede the context node, excluding attribute and namespace nodes. |
|
Self |
Not applicable |
The context node itself. |
Unabbreviated Syntax
The axes can be explicitly expressed using XPath’s unabbreviated syntax, by connecting an axis name with a node name or a node test (see Section 4.7, later in this chapter). Table 4-3 compares a few abbreviated and unabbreviated syntax examples to help you understand the relationship between the two.
The following stylesheet shows you how axes and the unabbreviated syntax work together. The stylesheet, shown in Example 4-6, is called unabbreviated.xsl and is similar to pattern.xsl, which you saw earlier in this chapter.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="text"/> <xsl:template match="/"> <xsl:apply-templates select="child::names"/> </xsl:template> <xsl:template match="child::names"> <xsl:apply-templates select="child::name[4]/attribute::title"/> </xsl:template> <xsl:template match="child::name[4]/attribute::title"> <xsl:text>The XML 1.0 WG's </xsl:text> <xsl:value-of select="self::node( )"/> <xsl:text> was </xsl:text> <xsl:value-of select="parent::name/child::given"/> <xsl:text> </xsl:text> <xsl:value-of select="parent::name/child::family"/> <xsl:text>.</xsl:text> </xsl:template> </xsl:stylesheet>
Lines in the stylesheet that use unabbreviated syntax are highlighted
in bold. The parent, child,
self, and attribute axes
are connected to node names using a connector
(::). The parent axis may be
abbreviated as .., so that
parent::name/child::given could be
../given.
The self axis is connected to node(
). This syntax looks like a function call, but
it’s really not. It’s a
node test that tests to see whether a node
matches a particular criterion. The node( ) test
matches any node and is sometimes called a
wildcard (though the word
wildcard doesn’t appear in the
XPath 1.0 spec).
If you apply unabbreviated.xsl to names.xml, using:
xalan names.xml unabbreviated.xsl
you get the following line as a result:
The XML 1.0 WG's technical lead was James Clark.
Reaching Out of Context with Unabbreviated Syntax
As I mentioned earlier, you can use axes to reach for nodes that are
not in context. As usual, I’ll illustrate how to do
this with an example. When the stylesheet shown in Example 4-7,
ancestor.xsl
,
processes the last name node in
names.xml, it also processes the first
name node in the document by using the
ancestor axis.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="text"/> <xsl:template match="/"> <xsl:apply-templates select="child::names"/> </xsl:template> <xsl:template match="child::names"> <xsl:apply-templates select="child::name[18]"/> </xsl:template> <xsl:template match="child::name[18]"> <xsl:value-of select="ancestor::names/child::name[1]/child::given"/> <xsl:text> </xsl:text> <xsl:value-of select="ancestor::names/child::name[1]/child::family"/> <xsl:text> is first on the list, and </xsl:text> <xsl:value-of select="child::given"/> <xsl:text> </xsl:text> <xsl:value-of select="child::family"/> <xsl:text> is last.</xsl:text> </xsl:template> </xsl:stylesheet>
The node processed by the last template in the stylesheet is the last
(child::name[18]) name node in
names.xml. While this template processes the
last name node, it also finds an ancestor, the
names node, and then processes the first
name child of names called
given
(ancestor::names/child::name[1]/child::given) and
the first name child of names called family
(ancestor::names/child::name[1]/child::family).
Apply it with:
xalan names.xml ancestor.xsl
The result of processing names.xml with this stylesheet is as follows:
Paula Angerstein is first on the list, and John Tigue is last.
Name and Node Tests
You can match a variety of nodes with XPath using name and node tests. A name test can match any element name, any element name with a given prefix, or a QName (a namespace-qualified name, with or without a prefix). Node tests can match text, comment, processing instruction nodes, or any node. You can use abbreviated or unabbreviated syntax with name and node tests. Table 4-4 describes each of the tests.
Tip
node( ) matches only nodes along the specified
axis; if no axis is specified, the child axis is
assumed, and you won’t get attributes!
Example 4-8 shows a RELAX NG schema for provinces.xml called provinces.rng.
<?xml version="1.0"?> <!--Relax NG schema for provinces.xml--> <rng:element name="provinces" xmlns:rng="http://relaxng.org/ns/structure/1.0" datatypeLibrary="http://www.w3.org/2001/XMLSchema-datatypes"> <rng:oneOrMore> <rng:element name="province"> <rng:attribute name="id"> <rng:data type="ID"/> </rng:attribute> <rng:element name="name"> <rng:text/> </rng:element> <rng:element name="abbreviation"> <rng:text/> </rng:element> </rng:element> </rng:oneOrMore> </rng:element>
RELAX NG is a
simple yet elegant schema language for XML (see http://www.relaxng.org). The document
provinces.xml
is valid with regard to this schema, which defines the instance
document with a natural, structured hierarchy of definitions. RELAX
NG adopts XML Schema datatypes as a datatype library (note the
datatypeLibrary attribute on the first element and
the rng:data element as a child of
rng:attribute).
Example 4-9, splat.xsl , is a simple stylesheet that uses name and node tests to analyze the RELAX NG schema.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:rng="http://relaxng.org/ns/structure/1.0"> <xsl:output method="text"/> <xsl:template match="/"> <xsl:value-of select="comment( )"/> <xsl:text> </xsl:text> <xsl:apply-templates select="rng:*"/> </xsl:template> <xsl:template match="rng:*"> <xsl:value-of select="local-name( )"/> <xsl:text>, </xsl:text> <xsl:value-of select="name(@*)"/> <xsl:text> = </xsl:text> <xsl:value-of select="@*"/> <xsl:text> </xsl:text> <xsl:apply-templates select="rng:*"/> </xsl:template> </xsl:stylesheet>
Because the elements in the schema are namespace-qualified and use a
prefix (rng:), the stylesheet must declare the
namespace and prefix as well
(xmlns:rng="http://relaxng.org/ns/structure/1.0“).
The template that matches the root uses a comment(
) node test to return the text content of a comment in the
source. It then applies templates to any element qualified with the
RELAX NG namespace (rng:*).
Tip
Don’t make the mistake of using a location path like
rng:element/attribute instead of
rng:element/rng:attribute. The first location path
searches for rng:element followed by an
attribute element in no namespace! The second
location example uses a prefix with the element name. Take care to
use namespace prefixes where needed in location paths.
The next template matches on rng:* and reports the
names of these elements using the XPath local-name(
) function, which returns the element name without the
prefix. The name( ) function returns the names of
attributes, if any, using name( ) with
@* as an argument; @* is used
by itself to return an attribute value. This template uses
apply-templates with rng:*
again and thereby reports on all RELAX NG elements in the source
tree.
When applied like this:
xalan provinces.rng splat.xsl
the text output is:
Relax NG schema for provinces.xml element, name = provinces oneOrMore, = element, name = province attribute, name = id data, type = ID element, name = name text, = element, name = abbreviation text, =
The first line of the result is the comment at the top of provinces.rng. The remaining lines report the RELAX NG element names followed by the names and values of any attributes the element might have.
For more information on name and node tests, see Section 2.3 of the XPath specification.
Doing the Math with Expressions
Expressions
allow you to perform simple arithmetic and Boolean logic when
processing nodes. Here’s an example of some simple
addition and multiplication. The document
math.xml
contains a group of operand elements, each
containing an integer:
<math> <operand>12</operand> <operand>23</operand> <operand>45</operand> <operand>56</operand> <operand>75</operand> </math>
You can use an expression to add and multiply 25 with these operands, as shown in Example 4-10, the stylesheet math.xsl .
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="text"/> <xsl:template match="math"> <xsl:apply-templates select="operand"/> </xsl:template> <xsl:template match="operand"> <xsl:value-of select="."/> <xsl:text> + 25 = </xsl:text> <xsl:value-of select=". + 25"/> <xsl:text> </xsl:text> <xsl:value-of select="."/> <xsl:text> * 25 = </xsl:text> <xsl:value-of select=". * 25"/> <xsl:text> </xsl:text> </xsl:template> </xsl:stylesheet>
The expression is the value of several select
attributes of value-of that add and multiply the
content of each operand element with 25. The
value-of element returns a string value, but the
presence of + or *
automatically converts the content of operand to a
number, if possible. If the content of operand
were a nonnumerical string, however, the number conversion
wouldn’t take place. This won’t
cause an error, but you will get NaN (Not a
Number) in response.
When you process math.xsl against math.xml using:
xalan math.xml math.xsl
you get this result:
12 + 25 = 37 12 * 25 = 300 23 + 25 = 48 23 * 25 = 575 45 + 25 = 70 45 * 25 = 1125 56 + 25 = 81 56 * 25 = 1400 75 + 25 = 100 75 * 25 = 1875
The stylesheet shown in Example 4-11,
boolean.xsl
,
combines addition and multiplication with some Boolean logic. It uses
expressions in predicates to test whether the content of
operand nodes are both greater-than and less-than
a value.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="text"/> <xsl:template match="/"> <xsl:apply-templates select="math"/> </xsl:template> <xsl:template match="math"> <xsl:apply-templates select="operand[(. < 50) and (. > 30)]"/> </xsl:template> <xsl:template match="operand[(. < 50) and (. > 30)]"> <xsl:value-of select="."/> <xsl:text> + 25 = </xsl:text> <xsl:value-of select=". + 25"/> <xsl:text> </xsl:text> <xsl:value-of select="."/> <xsl:text> * 25 = </xsl:text> <xsl:value-of select=". * 25"/> <xsl:text> </xsl:text> </xsl:template> </xsl:stylesheet>
In ordinary English, the expression:
(. < 50) and (. > 30)
tests whether the operand is less than 50 and greater than 30. The
entity references
<
and
>
are used
in the predicates instead of < and
> because < is forbidden
in attribute values in XML (see Section 3.1 of the XML
specification). To balance this limitation, XML uses entity
references for both symbols, even though > is
legal in attribute values. The parentheses distinguish the
greater-than and less-than tests, which are compared with the
and operator. For a complete list of Boolean and
math operators in XPath, see Table 4-5.
|
Operator |
Type |
Description |
|
|
Boolean |
Boolean AND |
|
|
Boolean |
Boolean OR |
|
|
Boolean |
Equals |
|
|
Boolean |
Not equal |
|
|
Boolean |
Less than |
|
|
Boolean |
Less than or equal to |
|
|
Boolean |
Greater than |
|
|
Boolean |
Greater than or equal to |
|
|
Number |
Addition |
|
|
Number |
Subtraction |
|
|
Number |
Multiplication |
|
|
Number |
Division |
|
|
Number |
Modulo (remainder of division) |
This concludes your mini math lesson in XPath and XSLT. To learn more about math in XPath, see Sections 3.4 and 3.5 in the XPath specification.
Summary
This chapter discussed the XPath data model with its seven node types. It also explained location paths, expressions and patterns, predicates, abbreviated and unabbreviated location paths, and axes. You learned how to do simple arithmetic and name and node tests, as well. For additional light on this subject, see Chapter 9 of O’Reilly’s XML in a Nutshell by Elliotte Rusty Harold and W. Scott Means, and Chapter 3 from O’Reilly’s XSLT by Doug Tidwell.
The next chapter continues the theme by exploring XPath and XSLT functions used in expressions.
Get Learning XSLT now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

