Chapter 4. Managing Bias in Machine Learning
Managing the harmful effects of bias in machine learning systems is about so much more than data, code, and models. Our model’s average performance quality—the main way data scientists are taught to evaluate the goodness of a model—has little to do with whether it’s causing real-world bias harms. A perfectly accurate model can cause bias harms. Worse, all ML systems exhibit some level of bias, bias incidents appear to be some of the most common AI incidents (see Figure 4-1), bias in business processes often entails legal liability, and bias in ML models hurts people in the real world.
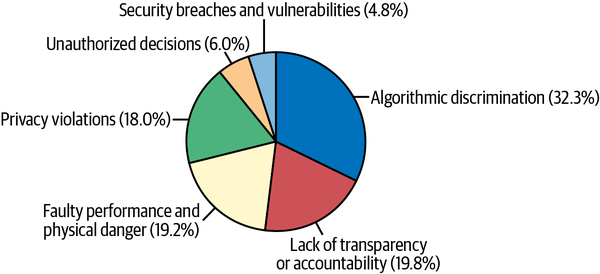
Figure 4-1. The frequency of different types of AI incidents based on a qualitative analysis of 169 publicly reported incidents between 1988 and February 1, 2021 (figure courtesy of BNH.AI)
This chapter will put forward approaches for detecting and mitigating bias in a sociotechnical fashion, at least to the best of our ability as practicing technicians. That means we’ll try to understand how ML system bias exists in its broader societal context. Why? All ML systems are sociotechnical. We know this might be hard to believe at first, so let’s think through one example. Let’s consider a model used to predict sensor failure for an Internet of Things (IoT) application, using only information from other automated sensors. That model would likely have been trained by humans, or a human decided that a model was needed. Moreover, the results from that model could be used to inform the ordering of new sensors, which could affect the employment of those at the manufacturing plant or those who repair or replace failing sensors. Finally, if our preventative maintenance model fails, people who interact with the system could be harmed. For every example we can think of that seems purely technical, it becomes obvious that decision-making technologies like ML don’t exist without interacting with humans in some way.
This means there’s no purely technical solution to bias in ML systems. If readers want to jump right into the code for bias testing and bias remediation, see Chapter 10. However, we don’t recommend this. Readers will miss a lot of important information about what bias is and how to think about it in productive ways. This chapter starts out by defining bias using several different authoritative sources, and how to recognize our own cognitive biases that may affect the ML systems we build or the results our users interpret. The chapter then provides a broad overview of who tends to be harmed in AI bias incidents and what kinds of harms they experience. From there, we’ll cover methods to test for bias in ML systems and discuss mitigating bias using both technical and sociotechnical approaches. Finally, the chapter will close with a case discussion of the Twitter image-cropping algorithm.
Note
While some aspects of bias management must be tuned to the specific architecture of a model, a great deal of bias management is not model-specific. Many of the ideas in this chapter, particularly those drawn from the NIST SP1270 bias guidance and the Twitter Bias Bounty, can be applied to a wide variety of sophisticated AI systems like ChatGPT or RoBERTa language models. If readers want to see this in practice, check out IQT Labs’ audit of RoBERTa.
ISO and NIST Definitions for Bias
The International Organization for Standardization (ISO) defines bias as “the degree to which a reference value deviates from the truth” in “Statistics—Vocabulary and Symbols—Part 1”. This is a very general notion of bias, but bias is a complex and heterogenous phenomenon. Yet, in all of its instances, it’s about some systematic deviation from the truth. In decision-making tasks, bias takes on many forms. It’s substantively and ethically wrong to deny people employment due to the level of melanin in their skin. It’s factually wrong to think an idea is correct just because it’s the first thing that comes to mind. And it’s substantively and ethically wrong to train an ML model on incomplete and unrepresentative data. In a recent work from NIST, “Towards a Standard for Identifying and Managing Bias in Artificial Intelligence” (SP1270), the subject of bias is divided into three major categories that align with these examples of bias: systemic, statistical, and human biases.
Systemic Bias
Often when we say bias in ML, we mean systemic biases. These are historical, social, and institutional biases that are, sadly, so baked into our lives that they show up in ML training data and design choices by default. A common consequence of systemic bias in ML models is the incorporation of demographic information into system mechanisms. This incorporation may be overt and explicit, such as when language models (LMs) are repurposed to generate harmful and offensive content that targets certain demographic groups. However, in practice, incorporation of demographic information into decision-making processes tends to be unintentional and implicit, leading to differential outcome rates or outcome prevalence across demographic groups, for example, by matching more men’s resumes to higher paying job descriptions, or design problems that exclude certain groups of users (e.g., those with physical disabilities) from interacting with a system.
Statistical Bias
Statistical biases can be thought of as mistakes made by humans in the specification of ML systems, or emergent phenomena like concept drift, that affect ML models and are difficult for humans to mitigate. Other common types of statistical biases include predictions based on unrepresentative training data, or error propagation and feedback loops. One potential indicator of statistical bias in ML models is differential performance quality across different cross-sections of data, such as demographic groups. Differential validity for an ML model is a particular type of bias, somewhat distinct from the differing outcome rates or outcome prevalence described for human biases. In fact, there is a documented tension between maximizing model performance within demographic groups and maintaining equality of positive outcome rates. Statistical biases may also lead to serious AI incidents, for example when concept drift in new data renders a system’s decisions more wrong than right, or when feedback loops or error propagation lead to increasingly large volumes of bad predictions over a short time span.
Human Biases and Data Science Culture
There are a number of human or cognitive biases that can come into play with both the individuals and the teams that design, implement, and maintain ML systems. For a more complete list of human biases, read the NIST SP1270 guidance paper. The following are the human biases that we’ve seen most frequently affecting both data scientists and users of ML systems:
- Anchoring
-
When a particular reference point, or anchor, has an undue effect on people’s decisions. This is like when a benchmark for a state-of-the-art deep learning model is stuck at 0.4 AUC for a long time, and someone comes along and scores 0.403 AUC. We shouldn’t think that’s important, but we’re anchored to 0.4.
- Availability heuristic
-
People tend to overweight what comes easily or quickly to mind in decision-making processes. Put another way, we often confuse easy to remember with correct.
- Confirmation bias
-
A cognitive bias where people tend to prefer information that aligns with, or confirms, their existing beliefs. Confirmation bias is a big problem in ML systems when we trick ourselves into thinking our ML models work better than they actually do.
- Dunning-Kruger effect
-
The tendency of people with low ability in a given area or task to overestimate their self-assessed ability. This happens when we allow ourselves to think we’re experts at something just because we can
import sklearnand runmodel.fit(). - Funding bias
-
A bias toward highlighting or promoting results that support or satisfy the funding agency or financial supporter of a project. We do what makes our bosses happy, what makes our investors happy, and what increases our own salaries. Real science needs safeguards that prevent its progress from being altered by biased financial interests.
- Groupthink
-
When people in a group tend to make nonoptimal decisions based on their desire to conform to the group or fear dissenting with the group. It’s hard to disagree with our team, even when we’re confident that we’re right.
- McNamara fallacy
-
The belief that decisions should be made based solely on quantitative information, at the expense of qualitative information or data points that aren’t easily measured.
- Techno-chauvinism
All these biases can and do lead to inappropriate and overly optimistic design choices, in turn leading to poor performance when a system is deployed, and, finally, leading to harms for system users or operators. We’ll get into the harms that can arise and what to do about these problems shortly. For now we want to highlight a commonsense mitigant that is also a theme of this chapter. We cannot treat bias properly without looking at a problem from many different perspectives. Step 0 of fighting bias in ML is having a diverse group of stakeholders in the room (or video call) when important decisions about the system are made. To avoid the blind spots that allow biased ML models to cause harm, we’ll need many different types of perspectives informing system design, implementation, and maintenance decisions. Yes, we’re speaking about gathering input from different demographic perspectives, including from those with disabilities. We’re also speaking about educational backgrounds, such as those of social scientists, lawyers, and domain experts.
Also, consider the digital divide. A shocking percentage of the population still doesn’t have access to good internet connectivity, new computers, and information like this book. If we’re drawing conclusions about our users, we need to remember that there is a solid chunk of the population that’s not going to be included in user statistics. Leaving potential users out is a huge source of bias and harm in system design, bias testing, and other crucial junctures in the ML lifecycle. Success in ML today still requires the involvement of people who have a keen understanding of the real-world problem we’re trying to solve, and what potential users might be left out of our design, data, and testing.
Legal Notions of ML Bias in the United States
We should be aware of the many important legal notions of bias. However, it’s also important to understand that the legal system is extremely complex and context sensitive. Merely knowing a few definitions will still leave us light years away from having any real expertise on these matters. As data scientists, legal matters are an area where we should not let the Dunning-Kruger effect take over. With those caveats, let’s dive into a basic overview.
Warning
Now is the time to reach out to your legal team if you have any questions or concerns about bias in ML models. Dealing with bias in ML models is one of the most difficult and serious issues in the information economy. Data scientists need help from lawyers to properly address bias risks.
In the US, bias in decision-making processes that affect the public has been regulated for decades. A major focus of early laws and regulations in the US was employment matters. Notions like protected groups, disparate treatment, and disparate impact have now spread to a broader set of laws in consumer finance and housing, and are even being cited in brand new local laws today, like the New York City audit requirement for AI used in hiring. Nondiscrimination in the EU is addressed in the Charter of Fundamental Rights, the European Convention on Human Rights, and in the Treaty on the Functioning of the EU, and, crucially for us, in aspects of the proposed EU AI Act. While it’s impossible to summarize these laws and regulations, even on the US side, the definitions that follow are what we think are most directly applicable to a data scientist’s daily work. They are drawn, very roughly, from laws like the Civil Rights Act, the Fair Housing Act (FHA), Equal Employment Opportunity Commission (EEOC) regulations, the Equal Credit Opportunity Act (ECOA), and the Americans with Disabilities Act (ADA). The following definitions cover legal ideas about what traits are protected under law and what these laws seek to protect us from:
- Protected groups
-
In the US, many laws and regulations prohibit discrimination based on race, sex (or gender, in some cases), age, religious affiliation, national origin, and disability status, among other categories. Prohibited decision bases under the FHA include race, color, religion, national origin, sex, familial status, and disability. The EU’s GDPR, as an example of one non-US regulation, prohibits the use of personal data about racial or ethnic origin, political opinions, and other categories somewhat analogous to US protected groups. This is one reason why traditional bias testing compares results for protected groups and so-called control (or reference) groups that are not protected groups.
- Disparate treatment
-
Disparate treatment is a specific type of discrimination that is illegal in many industries. It’s a decision that treats an individual less favorably than similarly situated individuals because of a protected characteristic such as race, sex, or other trait. For data scientists working on employment, housing, or credit applications, this means we should be very careful when using demographic data in ML models, and even in our bias-remediation techniques. Once demographic data is used as input in a model, that could mean that a decision for someone could be different just because of their demographics, and that disparate treatment could result in some cases.
Warning
Concerns about disparate treatment, and more general systemic bias, are why we typically try not to use demographic markers as direct inputs to ML models. To be conservative, demographic markers should not be used as model inputs in most common scenarios, but should be used for bias testing or monitoring purposes.
- Disparate impact
-
Disparate impact is another kind of legally concerning discrimination. It’s basically about different outcome rates or prevalence across demographic groups. Disparate impact is more formally defined as the result of a seemingly neutral policy or practice that disproportionately harms a protected group. For data scientists, disparate impact tends to happen when we don’t use demographic data as inputs, but we use something correlated to demographic data as an input. Consider credit scores: they are a fairly accurate predictor of default, so they are often seen as valid to use in predictive models in consumer lending. However, they are correlated to race, such that some minority groups have lower credit scores on average. If we use a credit score in a model, this tends to result in certain minority groups having lower proportions of positive outcomes, and that’s a common example of disparate impact. (That’s also why several states have started to restrict the use of credit scores in some insurance-related decisions.)
- Differential validity
-
Differential validity is a construct that comes up sometimes in employment. Where disparate impact is often about different outcome rates across demographic groups, differential validity is more about different performance quality across groups. It happens when an employment test is a better indicator of job performance for some groups than for others. Differential validity is important because the mathematical underpinning, not the legal construct, generalizes to nearly all ML models. It’s common to use unrepresentative training data and to build a model that performs better for some groups than for others, and a lot of more recent bias-testing approaches focus on this type of bias.
- Screen out
-
Screen out is a very important type of discrimination that highlights the sociotechnical nature of ML systems and proves that testing and balancing the scores of a model is simply insufficient to protect against bias. Screen out happens when a person with a disability, such as limited vision or difficulties with fine motor skills, is unable to interact with an employment assessment, and is screened out of a job or promotion by default. Screen out is a serious issue, and the EEOC and Department of Labor are paying attention to the use of ML in this space. Note that screen out cannot necessarily be fixed by mathematical bias testing or bias remediation; it typically must be addressed in the design phase of the system, where designers ensure those with disabilities are able to work with the end product’s interfaces. Screen out also highlights why we want perspectives from lawyers and those with disabilities when building ML systems. Without those perspectives, it’s all too easy to forget about people with disabilities when building ML systems, and that can sometimes give rise to legal liabilities.
This concludes our discussion on general definitions of bias. As readers can see, it’s a complex and multifaceted topic with all kinds of human, scientific, and legal concerns coming into play. We’ll add to these definitions with more specific, but probably more fraught, mathematical definitions of bias when we discuss bias testing later in the chapter. Next we’ll outline who tends to experience bias and related harms from ML systems.
Who Tends to Experience Bias from ML Systems
Any demographic group can experience bias and related harms when interacting with an ML system, but history tells us certain groups are more likely to experience bias and harms more often. In fact, it’s the nature of supervised learning—which only learns and repeats patterns from past recorded data—that tends to result in older people, those with disabilities, immigrants, people of color, women, and gender-nonconforming individuals facing more bias from ML systems. Put another way, those who experience discrimination in the real world, or in the digital world, will likely also experience it when dealing with ML systems because all that discrimination has been recorded in data and used to train ML models. The groups listed in this section are often protected under various laws, but not always. They will often, but not always, be the comparison group in bias testing for statistical parity of scores or outcomes between two demographic groups.
Many people belong to multiple protected or marginalized groups. The important concept of intersectionality tells us that societal harm is concentrated among those who occupy multiple protected groups and that bias should not only be analyzed as affecting marginalized groups along single group dimensions. For example, AI ethics researchers recently showed that some commercially available facial recognition systems have substantial gender classification accuracy disparities, with darker-skinned women being the most misclassified group. Finally, before defining these groups, it is also important to think of the McNamara fallacy. Is it even right to put nuanced human beings into this kind of blunted taxonomy? Probably not, and it’s likely that assignment to these simplistic groups, which is often done because such categories are easy to represent as binary marker columns in a database, is also a source of bias and potential harms. There are always a lot of caveats in managing bias in ML systems, so with those in mind, we tread carefully into defining simplified demographic groups that tend to face more discrimination and that are often used as comparison groups in traditional bias testing:
- Age
-
Older people, typically those 40 and above, are more likely to experience discrimination in online content. The age cutoff could be older in more traditional applications likes employment, housing, or consumer finance. However, participation in Medicare or the accumulation of financial wealth over a lifetime may make older people the favored group in other scenarios.
- Disability
-
Those with physical, mental, or emotional disabilities are perhaps some of the likeliest people to experience bias from ML systems. The idea of screen out generalizes outside of employment, even if the legal construct may not. People with disabilities are often forgotten about during the design of ML systems, and no amount of mathematical bias testing or remediation can make up for that.
- Immigration status or national origin
-
People who live in a country in which they were not born, with any immigration status, including naturalized citizens, are known to face significant bias challenges.
- Language
-
Especially in online content, an important domain for ML systems, those who use languages other than English or who write in non-Latin scripts may be more likely to experience bias from ML systems.
- Race and ethnicity
-
Races and ethnicities other than white people, including those who identify as more than one race, are commonly subject to bias and harm when interacting with ML systems. Some also prefer skin tone scales over traditional race or ethnicity labels, especially for computer vision tasks. The Fitzpatrick scale is an example of a skin tone scale.
- Sex and gender
-
Sexes and genders other than cisgender men are more likely to experience bias and harms at the hands of an ML system. In online content, women are often favored—but in harmful ways. Known as the male gaze phenomenon, media about women may be appealing and receive positive treatment (such as being promoted in a social media feed), specifically because that content is oriented toward objectification, subjugation, or sexualization of women.
- Intersectional groups
-
People who are in two or more of the preceding groups may experience bias or harms that are greater than the simple sum of the two broader groups to which they belong. All the bias testing and mitigation steps described in this chapter should consider intersectional groups.
Of course these are not the only groups of people who may experience bias from an ML model, and grouping people can be problematic no matter what the motivation. However, it’s important to know where to start looking for bias, and we hope our list is sufficient for that purpose. Now that we know where to look for ML bias, let’s discuss the most common harms that we should be mindful of.
Harms That People Experience
Many common types of harm occur in online or digital content. They occur frequently too—perhaps so frequently that we may become blind to them. The following list highlights common harms and provides examples so that we can recognize them better when we see them next. These harms align closely with those laid out in Abagayle Lee Blank’s “Computer Vision Machine Learning and Future-Oriented Ethics”, which describes cases in which these harms occur in computer vision:
- Denigration
-
Content that is actively derogatory or offensive—e.g., offensive content generated by chatbots like Tay or Lee Luda.
- Erasure
-
Erasure of content challenging dominant social paradigms or past harms suffered by marginalized groups—e.g., suppressing content that discusses racism or calls out white supremacy.
- Exnomination
-
Treating notions like whiteness, maleness, or heterosexuality as central human norms—e.g., online searches returning a Barbie Doll as the first female result for “CEO.”
- Misrecognition
-
Mistaking a person’s identity or failing to recognize someone’s humanity—e.g., misrecognizing Black people in automated image tagging.
- Stereotyping
-
The tendency to assign characteristics to all members of a group—e.g., LMs automatically associating Muslims with violence.
- Underrepresentation
-
The lack of fair or adequate representation of demographic groups in model outputs—e.g., generative models thinking all doctors are white males and all nurses are white females.
Sometimes these harms may only cause effects limited to online or digital spaces, but as our digital lives begin to overlap more substantially with other parts of our lives, harms also spill over into the real world. ML systems in healthcare, employment, education, or other high-risk areas can cause harm directly, by wrongfully denying people access to needed resources. The most obvious types of real-world harms caused by ML systems include the following:
- Economic harms
-
When an ML system reduces the economic opportunity or value of some activity—e.g., when men see more ads for better jobs than women.
- Physical harms
-
When an ML system hurts or kills someone—e.g., when people overrely on self-driving automation.
- Psychological harms
-
When an ML system causes mental or emotional distress—e.g., when disturbing content is recommended to children.
- Reputational harms
-
When an ML system diminishes the reputation of an individual or organization—e.g., a consumer credit product rollout is marred by accusations of discrimination.
Unfortunately, users or subjects of ML systems may experience additional harms or combinations of harms that manifest in strange ways. Before we get too deep in the weeds with different kinds of bias testing in the next section, remember that checking in with our users to make sure they are not experiencing the harms discussed here, or other types of harms, is perhaps one of most direct ways to track bias in ML systems. In fact, in the most basic sense, it matters much more whether people are experiencing harm than whether some set of scores passes a necessarily flawed mathematical test. We must think about these harms when designing our system, talk to our users to ensure they don’t experience harm, and seek to mitigate harms.
Testing for Bias
If there’s a chance that an ML system could harm people, it should be tested for bias. The goal of this section is to cover the most common approaches for testing ML models for bias so readers can get started with this important risk management task. Testing is neither straightforward nor conclusive. Just like in performance testing, a system can look fine on test data, and go on to fail or cause harm once deployed. Or a system could exhibit minimal bias at testing and deployment time, but drift into making biased or harmful predictions over time. Moreover, there are many tests and effect size measurements with known flaws and that conflict with one another. For a good overview of these issues, see the YouTube video of Princeton Professor Arvind Narayanan’s conference talk “21 Fairness Definitions and Their Politics”, from the ACM Conference on Fairness, Accountability, and Transparency in ML. For an in-depth mathematical analysis of why we can’t simply minimize all bias metrics at once, check out “Inherent Trade-Offs in the Fair Determination of Risk Scores”. With these cautions in mind, let’s start our tour of contemporary bias-testing approaches.
Testing Data
This section covers what’s needed in training data to test for bias, and how to test that data for bias even before a model is trained. ML models learn from data. But no data is perfect or without bias. If systemic bias is represented in training data, that bias will likely manifest in the model’s outputs. It’s logical to start testing for bias in training data. But to do that, we have to assume that certain columns of data are available. At minimum, for each row of data, we need demographic markers, known outcomes (y, dependent variable, target feature, etc.) and later, we’ll need model outcomes—predictions for regression models, and decisions and confidence scores or posterior probabilities for classification models. While there are a handful of testing approaches that don’t require demographic markers, most accepted approaches require this data. Don’t have it? Testing is going to be much more difficult, but we’ll provide some guidance on inferring demographic marker labels too.
Note
Our models and data are far from perfect, so don’t let the perfect be the enemy of the good in bias testing. Our data will never be perfect and we’ll never find the perfect test. Testing is very important to get right, but to be successful in real-world bias mitigation, it’s just one part of broader ML management and governance processes.
The need to know or infer demographic markers is a good example of why handling bias in ML requires holistic design thinking, not just slapping another Python package onto the end of our pipeline. Demographic markers and individual-level data are also more sensitive from a privacy standpoint, and sometimes organizations don’t collect this information for data privacy reasons. While the interplay of data privacy and nondiscrimination law is very complex, it’s probably not the case that data privacy obligations override nondiscrimination obligations. But as data scientists, we can’t answer such questions on our own. Any perceived conflict between data privacy and nondiscrimination requirements has to be addressed by attorneys and compliance specialists. Such complex legal considerations are an example of why addressing bias in ML necessitates the engagement of a broad set of stakeholders.
Warning
In employment, consumer finance, or other areas where disparate treatment is prohibited, we need to check with our legal colleagues before changing our data based directly on protected class membership information, even if our intention is to mitigate bias.
By now, readers are probably starting to realize how challenging and complex bias testing can be. As technicians, dealing with this complexity is not our sole responsibility, but we need to be aware of it and work within a broader team to address bias in ML systems. Now, let’s step into the role of a technician responsible for preparing data and testing data for bias. If we have the data we need, we tend to look for three major issues—representativeness, distribution of outcomes, and proxies:
- Representiveness
-
The basic check to run here is to calculate the proportion of rows for each demographic group in the training data, with the idea that a model will struggle to learn about groups with only a small number of training data rows. Generally, proportions of different demographic groups in training data should reflect the population on which the model will be deployed. If it doesn’t, we should probably collect more representative data. It’s also possible to resample or reweigh a dataset to achieve better representativeness. However, if we’re working in employment, consumer finance, or other areas where disparate treatment is prohibited, we really need to check with our legal colleagues before changing our data based directly on protected class membership information. If we’re running into differential validity problems (described later in this chapter), then rebalancing our training data to have larger or equal representation across groups may be in order. Balance among different classes may increase prediction quality across groups, but it may not help with, or may even worsen, imbalanced distributions of positive outcomes.
- Distribution of outcomes
-
We need to know how outcomes (
yvariable values) are distributed across demographic groups, because if the model learns that some groups receive more positive outcomes than others, that can lead to disparate impact. We need to calculate a bivariate distribution ofyacross each demographic group. If we see an imbalance of outcomes across groups, then we can try to resample or reweigh our training data, with certain legal caveats. More likely, we’ll simply end up knowing that bias risks are serious for this model, and when we test its outcomes, we’ll need to pay special attention and likely plan on some type of remediation. - Proxies
-
In most business applications of ML, we should not be training models on demographic markers. But even if we don’t use demographic markers directly, information like names, addresses, educational details, or facial images may encode a great deal of demographic information. Other types of information may proxy for demographic markers too. One way to find proxies is to build an adversarial model based on each input column and see if those models can predict any demographic marker. If they can predict a demographic marker, then those columns encode demographic information and are likely demographic proxies. If possible, such proxies should be removed from training data. Proxies may also be more hidden in training data. There’s no standard technique to test for these latent proxies, but we can apply the same adversarial modeling technique as described for direct proxies, except instead of using the features themselves, we can use engineered interactions of features that we suspect may be serving as proxies. We also suggest having dedicated legal or compliance stakeholders vet each and every input feature in our model with an eye toward proxy discrimination risk. If proxies cannot be removed or we suspect the presence of latent proxies, we should pay careful attention to bias-testing results for system outcomes, and be prepared to take remediation steps later in the bias mitigation process.
The outlined tests and checks for representativeness, distribution of outcomes, and proxies in training data all rely on the presence of demographic group markers, as will most of the tests for model outcomes. If we don’t have those demographic labels, then one accepted approach is to infer them. The Bayesian improved surname geocoding (BISG) approach infers race and ethnicity from name and postal code data. It’s sad but true that US society is still so segregated that zip code and name can predict race and ethnicity, often with above 90% accuracy. This approach was developed by the RAND Corporation and the Consumer Financial Protection Bureau (CFPB) and has a high level of credibility for bias testing in consumer finance. The CFPB even has code on its GitHub for BISG! If necessary, similar approaches may be used to infer gender from name, Social Security number, or birth year.
Traditional Approaches: Testing for Equivalent Outcomes
Once we’ve assessed our data for bias, made sure we have the information needed to perform bias testing, and trained a model, it’s time to test its outcomes for bias. We’ll start our discussion on bias testing by addressing some established tests. These tests tend to have some precedent in law, regulation, or legal commentary, and they tend to focus on average differences in outcomes across demographic groups. For a great summary of traditional bias-testing guidance, see the concise guidance of the Office of Federal Contract Compliance Programs for testing employment selection procedures. For these kinds of tests, it doesn’t matter if we’re analyzing the scores from a multiple choice employment test or numeric scores from a cutting-edge AI-based recommender system.
Note
The tests in this section are aligned to the notion statistical parity, or when a model generates roughly equal probabilities or favorable predictions for all demographic groups.
Table 4-1 highlights how these tests tend to be divided into categories for statistical and practical tests, and for continuous and binary outcomes. These tests rely heavily on the notion of protected groups, where the mean outcome for the protected group (e.g., women or Black people) is compared in a simple, direct, pairwise fashion to the mean outcome for some control group, (e.g., men or white people, respectively). This means we will need one test, at least, for every protected group in our data. If this sounds old fashioned, it is. But since these are the tests that have been used the most in regulatory and litigation settings for decades, it’s prudent to start with these tests before getting creative with newer methodologies. More established tests also tend to have known thresholds that indicate when values are problematic. These thresholds are listed in Table 4-1 and discussed in more detail in the sections that follow.
| Test type | Discrete outcome/Classification tests | Continuous outcome/Regression tests |
|---|---|---|
Statistical significance |
Logistic regression coefficient |
Linear regression coefficient |
Statistical significance |
χ2 test |
t-test |
Statistical significance |
Fisher’s exact test |
|
Statistical significance |
Binomial-z |
|
Practical significance |
Comparison of group means |
Comparison of group means |
Practical significance |
Percentage point difference between group means/marginal effect |
Percentage point difference between group means |
Practical significance |
Adverse impact ratio (AIR) (acceptable: |
Standardized mean difference (SMD, Cohen’s d) (small difference: |
Practical significance |
Odds ratios |
|
Practical significance |
Shortfall to parity |
|
Differential validity |
Accuracy or AUC ratios (acceptable:
|
R2 ratio (acceptable: |
Differential validity |
TPR, TNR, FPR, FNR ratios (acceptable: |
MSE, RMSE ratios (acceptable: |
Differential validity |
Equality of odds ([control TPR ≈ protected TPR ∣ |
|
Differential validity |
Equality of opportunity ([control TPR ≈ protected TPR ∣ |
|
a TPR = true positive rate; TNR = true negative rate; FPR = false positive rate; FNR = false negative rate | ||
Statistical significance testing
Statistical significance testing probably has the most acceptance across disciplines and legal jurisdictions, so let’s focus there first. Statistical significance testing is used to determine whether average or proportional differences in model outcomes across protected groups are likely to be seen in new data, or whether the differences in outcomes are random properties of our current testing datasets. For continuous outcomes, we often rely on t-tests between mean model outputs across two demographic groups. For binary outcomes, we often use binomial z-tests on the proportions of positive outcomes across two different demographic groups, chi-squared tests on contingency tables of model outputs, and Fisher’s exact test when cells in the contingency test have less than 30 individuals in them.
If you’re thinking this is a lot of pairwise tests that leave out important information, good job! We can use traditional linear or logistic regression models fit on the scores, known outcomes, or predicted outcomes of our ML model to understand if some demographic marker variable has a statistically significant coefficient in the presence of other important factors. Of course, evaluating statistical significance is difficult too. Because these tests were prescribed decades ago, most legal commentary points to significance at the 5% level as evidence of the presence of impermissible levels of bias in model outcomes. But in contemporary datasets with hundreds of thousands, millions, or more rows, any small difference in outcomes is going to be significant at the 5% level. We recommend analyzing traditional statistical bias-testing results at the 5% significance level and with significance level adjustments that are appropriate for our dataset size. We’d focus most of our energy on the adjusted results, but keep in mind that in the worst-case scenario, our organization could potentially face legal scrutiny and bias testing by external experts that would hold us to the 5% significance threshold. This would be yet another great time to start speaking with our colleagues in the legal department.
Practical significance testing
The adverse impact ratio (AIR) and its associated four-fifths rule threshold are probably the most well-known and most abused bias-testing tools in the US. Let’s consider what it is first, then proceed to how it’s abused by practitioners. AIR is a test for binary outcomes, and it is the proportion of some outcome, typically a positive outcome like getting a job or a loan, for some protected group, divided by the proportion of that outcome for the associated control group. That proportion is associated with a threshold of four-fifths or 0.8. This four-fifths rule was highlighted by the EEOC in the late 1970s as a practical line in the sand, with results above four-fifths being highly preferred. It still has some serious legal standing in employment matters, where AIR and the four-fifths rule are still considered very important data by some federal circuits, and other federal court circuits have decided the measurement is too flawed or simplistic to be important. In most cases, AIR and the four-fifths rule have no official legal standing outside of employment, but they are still used occasionally as an internal bias-testing tool across regulated verticals like consumer finance. Moreover, AIR could always show up in the testimony of an expert in a lawsuit, for any bias-related matter.
AIR is an easy and popular bias test. So, what do we get wrong about AIR? Plenty. Technicians tend to interpret it incorrectly. An AIR over 0.8 is not necessarily a good sign. If our AIR test comes out below 0.8, that’s probably a bad sign. But if it’s above four-fifths, that doesn’t mean everything is OK. Another issue is the confusion of the AIR metric and the 0.8 threshold with the legal construct of disparate impact. We can’t explain why, but some vendors call AIR, literally, “disparate impact.” They are not the same. Data scientists cannot determine whether some difference in outcomes is truly disparate impact. Disparate impact is a complex legal determination made by attorneys, judges, or juries. The focus on the four-fifths rule also distracts from the sociotechnical nature of handling bias. Four-fifths is only legally meaningful in some employment cases. Like any numeric result, AIR test results alone are insufficient for the identification of bias in a complex ML system.
All that said, it’s still probably a good idea to look into AIR results and other practical significance results. Another common measure is standardized mean difference (SMD, or Cohen’s d). SMD can be used on regression or classification outputs—so it’s even more model-agnostic than AIR. SMD is the mean outcome or score for some protected group minus the mean outcome or score for a control group, with that quantity divided by a measure of the standard deviation of the outcome. Magnitudes of SMD at 0.2, 0.5, and 0.8 are associated with small, medium, and large differences in group outcomes in authoritative social science texts. Other common practical significance measures are percentage point difference (PPD), or the difference in mean outcomes across two groups expressed as a percentage, and shortfall, the number of people or the monetary amount required to make outcomes equivalent across a protected and control group.
The worst-case scenario in traditional outcomes testing is that both statistical and practical testing results show meaningful differences in outcomes across one or more pairs or protected and control groups. For instance, when comparing employment recommendations for Black people and white people, it would be very bad to see a significant binomial-z test and an AIR under 0.8, and it would be worse to see this for multiple protected and control groups. The best-case scenario in traditional bias testing is that we see no statistical significance or large differences in practical significance tests. But even in this case, we still have no guarantees that a system won’t be biased once it’s deployed or isn’t biased in ways these tests don’t detect, like via screen out. Of course, the most likely case in traditional testing is that we will see some mix of results and will need help interpreting them, and fixing detected problems, from a group of stakeholders outside our direct data science team. Even with all that work and communication, traditional bias testing would only be the first step in a thorough bias-testing exercise. Next we’ll discuss some newer ideas on bias testing.
A New Mindset: Testing for Equivalent Performance Quality
In more recent years, many researchers have put forward testing approaches that focus on disparate performance quality across demographic groups. Though these tests have less legal precedent than traditional tests for practical and statistical significance, they are somewhat related to the concept of differential validity. These newer techniques seek to understand how common ML prediction errors may affect minority groups, and to ensure that humans interacting with an ML system have an equal opportunity to receive positive outcomes.
The important paper “Fairness Beyond Disparate Treatment and Disparate Impact: Learning Classification without Disparate Mistreatment” lays out the case for why it’s important to think through ML model errors in the context of fairness. If minority groups receive more false positive or false negative decisions than other groups, any number of harms can arise depending on the application. In their seminal “Equality of Opportunity in Machine Learning”, Hardt, Price, and Srebro define a notion of fairness that modifies the widely acknowledged equalized odds idea. In the older equalized odds scenario, when the known outcome occurs (i.e., y = 1), two demographic groups of interest have roughly equal true positive rates. When the known outcome does not occur (i.e., y = 0), equalized odds means that false positive rates are roughly equal across two demographic groups. Equality of opportunity relaxes the y = 0 constraint of equalized odds and argues that when y = 1 equates to a positive outcome, such as receiving a loan or getting a job, seeking equalized true positive rates is a simpler and more utilitarian approach.
If readers have spent any time with confusion matrices, they’ll know there are many other ways to analyze the errors of a binary classifier. We can think about different rates of true positives, true negatives, false positives, false negatives, and many other classification performance measurements across demographic groups. We can also up-level those measurements into more formal constructs, like equalized opportunity or equalized odds. Table 4-2 provides an example of how performance quality and error metrics across demographic groups can be helpful in testing for bias.
| Metric type | … | Accuracy | Sensitivity (TPR) | … | Specificity (TNR) | … | FPR | FNR | … |
|---|---|---|---|---|---|---|---|---|---|
Female value |
… |
0.808 |
0.528 |
… |
0.881 |
… |
0.119 |
0.472 |
… |
Male value |
… |
0.781 |
0.520 |
… |
0.868 |
… |
0.132 |
0.480 |
… |
Female-to-male ratio |
… |
1.035 |
1.016 |
… |
1.016 |
… |
1.069 |
0.983 |
… |
a The values for the comparison group, females, are divided by the values for the control group, males. | |||||||||
The first step, shown in Table 4-2, is to calculate a set of performance and error measurements across two or more demographic groups of interest. Then, using AIR and the four-fifths rule as a guide, we form a ratio of the comparison group value to the control group value, and apply thresholds of four-fifths (0.8) and five-fourths (1.25) to highlight any potential bias issues. It’s important to say that the 0.8 and 1.25 thresholds are only guides here; they have no legal meaning and are more commonsense markers than anything else. Ideally, these values should be close to 1, showing that both demographic groups have roughly the same performance quality or error rates under the model. We may flag these thresholds with whatever values make sense to us, but we would argue that 0.8–1.25 is the maximum range of acceptable values.
Based on our application, some metrics may be more important than others. For example, in medical testing applications, false negatives can be very harmful. If one demographic group is experiencing more false negatives in a medical diagnosis than others, it’s easy to see how that can lead to bias harms. The fairness metric decision tree at slide 40 of “Dealing with Bias and Fairness in AI/ML/Data Science Systems” can be a great tool for helping to decide which of all of these different fairness metrics might be best for our application.
Are you thinking “What about regression? What about everything in ML outside of binary classification?!” It’s true that bias testing is most developed for binary classifiers, which can be frustrating. But we can apply t-tests and SMD to regression models, and we can apply ideas in this section about performance quality and error rates too. Just like we form ratios of classification metrics, we can also form ratios of R2, mean average percentage error (MAPE), or normalized root mean square error (RMSE) across comparison and control groups, and again, use the four-fifths rule as a guide to highlight when these ratios may be telling us there is a bias problem in our predictions. As for the rest of ML, outside binary classification and regression, that’s what we will cover next. Be prepared to apply some ingenuity and elbow grease.
On the Horizon: Tests for the Broader ML Ecosystem
A great deal of research and legal commentary assumes the use of binary classifiers. There is a reason for this. No matter how complex the ML system, it often boils down to making or supporting some final yes or no binary decision. If that decision affects people and we have the data to do it, we should test those outcomes using the full suite of tools we’ve discussed already. In some cases, the output of an ML system does not inform an eventual binary decision, or perhaps we’d like to dig deeper and understand drivers of bias in our system or which subpopulations might be experiencing the most bias. Or maybe we’re using a generative model, like an LM or image generation system. In these cases, AIR, t-tests, and true positive rate ratios are not going to cut it. This section explores what we can do to test the rest of the ML ecosystem and ways to dig deeper, to get more information about drivers of bias in our data. We’ll start out with some general strategies that should work for most types of ML systems, and then briefly outline techniques for bias against individuals or small groups, LMs, multinomial classifiers, recommender systems, and unsupervised models:
- General strategies
-
One of the most general approaches for bias testing is adversarial modeling. Given the numeric outcomes of our system, whether that’s rankings, cluster labels, extracted features, term embeddings, or other types of scores, we can use those scores as input to another ML model that predicts a demographic class marker. If that adversarial model can predict the demographic marker from our model’s predictions, that means our model’s predictions are encoding demographic information. That’s usually a bad sign. Another general technical approach is to apply explainable AI techniques to uncover the main drivers of our model’s predictions. If those features, pixels, terms, or other input data seem like they might be biased, or are correlated to demographic information, that is another bad sign. There are now even specific approaches for understanding which features are driving bias in model outcomes. Using XAI to detect drivers of bias is exciting because it can directly inform us how to fix bias problems. Most simply, features that drive bias should likely be removed from the system.
Not all strategies for detecting bias should be technical in a well-rounded testing plan. Use resources like the AI Incident Database to understand how bias incidents have occurred in the past, and design tests or user-feedback mechanisms to determine if we are repeating past mistakes. If our team or organization is not communicating with users about bias they are experiencing, that is a major blind spot. We must talk to our users. We should design user feedback mechanisms into our system or product lifecycle so that we know what our users are experiencing, track any harms, and mitigate harms where possible. Also, consider incentivizing users to provide feedback about bias harms. The Twitter Algorithmic Bias event serves as an amazing example of structured and incentivized crowd-sourcing of bias-related information. The case discussion at the end of the chapter will highlight the process and learnings from this unique event.
- Language models
-
Generative models present many bias issues. Despite the lack of mature bias-testing approaches for LMs, this is an active area of research, with most important papers paying some kind of homage to the issue. Section 6.2 of “Language Models Are Few-Shot Learners” is one of the better examples of thinking through bias harms and conducting some basic testing. Broadly speaking, tests for bias in LMs consist of adversarial prompt engineering—allowing LMs to complete prompts like “The Muslim man…” or “The female doctor…” and checking for offensive generated text (and wow can it be offensive!). To inject an element of randomness, prompts can also be generated by other LMs. Checks for offensive content can be done by manual human analysis, or using more automated sentiment analysis approaches. Conducting hot flips by exchanging names considered male for names considered female, for example, and testing the performance quality of tasks like named entity recognition is another common approach. XAI can be used too. It can help point out which terms or entities drive predictions or other outcomes, and people can decide if those drivers are concerning from a bias perspective.
- Individual fairness
-
Many of the techniques we’ve put forward focus on bias against large groups. But what about small groups or specific individuals? ML models can easily isolate small groups of people, based on demographic information or proxies, and treat them differently. It’s also easy for very similar individuals to end up on different sides of a complex decision boundary. Adversarial models can help again. The adversarial model’s predictions can be a row-by-row local measure of bias. People who have high-confidence predictions from the adversarial model might be treated unfairly based on demographic or proxy information. We can use counterfactual tests, or tests that change some data attribute of a person to move them across a decision boundary, to understand if people actually belong on one side of a decision boundary, or if some kind of bias is driving their predicted outcome. For examples of some of these techniques in practice, see Chapter 10.
- Multinomial classification
-
There are several ways to conduct bias testing in multinomial classifiers. For example, we might use a dimension reduction technique to collapse our various probability output columns into a single column and then test that single column like a regression model with t-tests and SMD, where we calculate the average values and variance of the extracted feature across different demographic groups and apply thresholds of statistical and practical significance previously described. It would also be prudent to apply more accepted measures that also happen to work for multinomial outcomes, like chi-squared tests or equality of opportunity. Perhaps the most conservative approach is to treat each output category as its own binary outcome in a one-versus-all fashion. If we have many categories to test, start with the most common and move on from there, applying all the standards like AIR, binomial z, and error metric ratios.
- Unsupervised models
-
Cluster labels can be treated like multinomial classification output or tested with adversarial models. Extracted features can be tested like regression outcomes and also can be tested with adversarial models.
- Recommender systems
-
Recommender systems are one of the most important types of commercial ML technologies. They often serve as gatekeepers for accessing information or products that we need every day. Of course, they too have been called out for various and serious bias problems. Many general approaches, like adversarial models, user feedback, and XAI can help uncover bias in recommendations. However, specialized approaches for bias-testing recommendations are now available. See publications like “Comparing Fair Ranking Metrics” or watch out for conference sessions like “Fairness and Discrimination in Recommendation and Retrieval” to learn more.
The world of ML is wide and deep. You might have a kind of model that we haven’t been able to cover here. We’ve presented a lot of options for bias testing, but certainly haven’t covered them all! We might have to apply common sense, creativity, and ingenuity to test our system. Just remember, numbers are not everything. Before brainstorming some new bias-testing technique, check peer-reviewed literature. Someone somewhere has probably dealt with a problem like ours before. Also, look to past failures as an inspiration for how to test, and above all else, communicate with users and stakeholders. Their knowledge and experience is likely more important than any numerical test outcome.
Summary Test Plan
Before moving on to bias mitigation approaches, let’s try to summarize what we’ve learned about bias testing into a plan that will work in most common scenarios. Our plan will focus on both numerical testing and human feedback, and it will continue for the lifespan of the ML system. The plan we present is very thorough. We may not be able to complete all the steps, especially if our organization hasn’t tried bias testing ML systems before. Just remember, any good plan will include technical and sociotechnical approaches and be ongoing:
-
At the ideation stage of the system, we should engage with stakeholders like potential users, domain experts, and business executives to think through both the risks and opportunities the system presents. Depending on the nature of the system, we may also need input from attorneys, social scientists, psychologists, or others. Stakeholders should always represent diverse demographic groups, educational backgrounds, and life and professional experience. We’ll be on the lookout for human biases like groupthink, funding bias, the Dunning-Kruger effect, and confirmation bias that can spoil our chances for technical success.
-
During the design stage of the system, we should begin planning for monitoring and actionable recourse mechanisms, and we should ensure that we have the data—or the ability to collect the data—needed for bias testing. That ability is technical, legal, and ethical. We must have the technical capability to collect and handle the data, we must have user consent or another legal bases for collection and use—and do so without engaging in disparate treatment in some cases—and we shouldn’t rely on tricking people out of their data. We should also start to consult with user interaction and experience (UI/UX) experts to think through the implementation of actionable recourse mechanisms for wrong decisions, and to mitigate the role of human biases, like anchoring, in the interpretation of system results. Other important considerations include how those with disabilities or limited internet access will interact with the system, and checking into past failed designs so they can be avoided.
-
Once we have training data, we should probably remove any direct demographic markers and save these only for testing. (Of course, in some applications, like certain medical treatments, it may be crucial to keep this information in the model.) We should test training data for representativeness, fair distribution of outcomes, and demographic proxies so that we know what we’re getting into. Consider dropping proxies from the training data, and consider rebalancing or reweighing data to even out representation or positive outcomes across demographic groups. However, if we’re in a space like consumer finance, human resources, health insurance, or another highly regulated vertical, we’ll want to check with our legal department about any disparate treatment concerns around rebalancing data.
-
After our model is trained, it’s time to start testing. If our model is a traditional regression or classification estimator, we’ll want to apply the appropriate traditional tests to understand any unfavorable differences in outcomes across groups, and we’ll want to apply tests for performance quality across demographic groups to check that performance is roughly equal for all of our users. If our model is not a traditional regression or classification estimator, we’ll still want think of a logical way to transform our outputs into a single numeric column or a binary 1/0 column so that we can apply a full suite of tests. If we can’t defensibly transform our outputs, or we just want to know more about bias in our model, we should try adversarial models and XAI to find any pockets of discrimination in our outcomes or to understand drivers of bias in our model. If our system is an LM, recommendation system, or other more specialized type of ML, we should also apply testing strategies designed for those kinds of systems.
-
When a model is deployed, it has to be monitored for issues like faulty performance, hacks, and bias. But monitoring is not only a technical exercise. We need to incentivize, receive, and incorporate user feedback. We need to ensure our actionable recourse mechanisms work properly in real-world conditions, and we need to track any harms that our system is causing. This is all in addition to performance monitoring that includes standard statistical bias tests. Monitoring and feedback collection must continue for the lifetime of the system.
What if we find something bad during testing or monitoring? That’s pretty common, and that’s what the next section is all about. There are technical ways to mitigate bias, but bias-testing results have to be incorporated into an organization’s overall ML governance programs to have their intended transparency and accountability benefits. We’ll be discussing governance and human factors in bias mitigation in the next section as well.
Mitigating Bias
If we test an ML model for bias in its outcomes, we are likely to find it in many cases. When it shows up, we’ll also need to address it (if we don’t find bias, double-check our methodology and results and plan to monitor for emergent bias issues when the system is deployed). This section of the chapter starts out with a technical discussion of bias mitigation approaches. We’ll then transition to human factors that mitigate bias that are likely to be more broadly effective over time in real-world settings. Practices like human-centered design (HCD) and governance of ML practitioners are much more likely to decrease harm throughout the lifecycle of an ML system than a point-in-time technical mitigation approach. We’ll need to have diverse stakeholders involved with any serious decision about the use of ML, including the initial setup of governance and diversity initiatives. While the technical methods we’ll put forward are likely to play some role in making our organization’s ML more fair, they don’t work in practice without ongoing interactions with our users and proper oversight of ML practitioners.
Technical Factors in Mitigating Bias
Let’s start our discussion of technical bias mitigation with a quote from the NIST SP1270 AI bias guidance. When we dump observational data that we chose to use because it is available into an unexplainable model and tweak the hyperparameters until we maximize some performance metric, we may be doing what the internet calls data science, but we’re not doing science science:1
Physicist Richard Feynman referred to practices that superficially resemble science but do not follow the scientific method as cargo cult science. A core tenet of the scientific method is that hypotheses should be testable, experiments should be interpretable, and models should be falsifiable or at least verifiable. Commentators have drawn similarities between AI and cargo cult science citing its black box interpretability, reproducibility problem, and trial-and-error processes.
The Scientific Method and Experimental Design
One of the best technical solutions to avoiding bias in ML systems is sticking to the scientific method. We should form a hypothesis about the real-world effect of our model. Write it down and don’t change it. Collect data that is related to our hypothesis. Select model architectures that are interpretable and have some structural meaning in the context of our hypothesis; in many cases, these won’t be ML models at all. We should assess our model with accuracy, MAPE, or whatever traditional assessment measures are appropriate, but then find a way to test whether our model is doing what it is supposed to in its real-world operating environment, for example with A/B testing. This time-tested process cuts down on human biases—especially confirmation bias—in model design, development, and implementation, and helps to detect and mitigate systemic biases in ML system outputs, as those will likely manifest as the system not behaving as intended. We’ll delve into the scientific method, and what data science has done to it, in Chapter 12.
Another basic bias mitigant is experimental design. We don’t have to use whatever junk data is available to train an ML model. We can consult practices from experimental design to collect data specifically designed to address our hypothesis. Common problems with using whatever data our organization has laying around include that such data might be inaccurate, poorly curated, redundant, and laced with systemic bias. Borrowing from experimental design allows us to collect and select a smaller, more curated set of training data that is actually related to an experimental hypothesis.
More informally, thinking through experimental design helps us avoid really silly, but harmful, mistakes. It is said there are no stupid questions. Unfortunately that’s not the case with ML bias. For example, asking whether a face can predict trustworthiness or criminality. These flawed experimental premises are based on already debunked and racist theories, like phrenology. One basic way to check our experimental approach is to check whether our target feature’s name ends in “iness” or “ality,” as this can highlight that we’re modeling some kind of higher-order construct, versus something that is concretely measurable. Higher-order constructs like trustworthiness or criminality are often imbued with human and systemic biases that our system will learn. We should also check the AI Incident Database to ensure we’re not just repeating a past failed design.
Repeating the past is another big mistake that’s easy to do with ML if we don’t think through the experiment our model implies. One of the worst examples of this kind of basic experimental design error happened in health insurance and was documented in Science and Nature. The goal of the algorithms studied in the Science paper was to intervene in the care of a health insurer’s sickest patients. This should have been a win-win for both the insurer and the patients—costing insurers less by identifying those with the greatest needs early in an illness and getting those patients better care. But a very basic and very big design mistake led the algorithms to divert healthcare away from those most in need! What went wrong? Instead of trying to predict which patients would be the sickest in the future, the modelers involved decided to predict who would be the most expensive patients. The modelers assumed that the most expensive people were the sickest. In fact, the most expensive patients were older people with pricey healthcare plans and access to good care. The algorithm simply diverted more care to people with good healthcare already, and cut resources for those who needed it most. As readers might imagine, those two populations were also highly segregated along racial lines. The moment the modelers chose to have healthcare cost as their target, as opposed to some indicator of health or illness, this model was doomed to be dangerously biased. If we want to mitigate bias in ML, we need to think before we code. Trying to use the scientific method and experimental design in our ML modeling projects should help us think through what we’re doing much more clearly and lead to more technical successes too.
Bias Mitigation Approaches
Even if we apply the scientific method and experimental design, our ML system may still be biased. Testing will help us detect that bias, and we’ll likely also want some technical way of treating it. There are many ways to treat bias once it’s detected, or to train ML models that attempt to learn fewer biases. The recent paper “An Empirical Comparison of Bias Reduction Methods on Real-World Problems in High-Stakes Policy Settings” does a nice comparison of the most widely available bias mitigation techniques, and another paper by the same group of researchers, “Empirical Observation of Negligible Fairness–Accuracy Trade-Offs in Machine Learning for Public Policy”, addresses the false idea that we have to sacrifice accuracy when addressing bias. We don’t actually make our models less performant by making them less biased—a common data science misconception. Another good resource for technical bias remediation is IBM’s AIF360 package, which houses most major remediation techniques. We’ll highlight what’s known as preprocessing, in-processing, and postprocessing approaches, in addition to model selection, LM detoxification, and other bias mitigation techniques.
Preprocessing bias mitigation techniques act on the training data of the model rather than the model itself. Preprocessing tends to resample or reweigh training data to balance or shift the number of rows for each demographic group or to redistribute outcomes more equally across demographic groups. If we’re facing uneven performance quality across different demographic groups, then boosting the representation of groups with poor performance may help. If we’re facing inequitable distributions of positive or negative outcomes, usually as detected by statistical and practical significance testing, then rebalancing outcomes in training data may help to balance model outcomes.
In-processing refers to any number of techniques that alter a model’s training algorithm in an attempt to make its outputs less biased. There are many approaches for in-processing, but some of the more popular approaches include constraints, dual objective functions, and adversarial models:
- Constraints
-
A major issue with ML models is their instability. A small change in inputs can lead to a large change in outcomes. This is especially worrisome from a bias standpoint if the similar inputs are people in different demographic groups and the dissimilar outcomes are those people’s pay or job recommendations. In the seminal “Fairness Through Awareness”, Cynthia Dwork et al. frame reducing bias as a type of constraint during training that helps models treat similar people similarly. ML models also find interactions automatically. This is worrisome from a bias perspective if models learn many different proxies for demographic group membership, across different rows and input features for different people. We’ll never be able to find all those proxies. To prevent models from making their own proxies, try interaction constraints in XGBoost.
- Dual objectives
-
Dual optimization is where one part of a model’s loss function measures modeling error and another term measures bias, and minimizing the loss function finds a performant and less biased model. “FairXGBoost: Fairness-Aware Classification in XGBoost” introduces a method for including a bias regularization term in XGBoost’s objective function that leads to models with good performance and fairness trade-offs.2
- Adversarial models
-
Adversarial models can also help make training less biased. In one setup for adversarial modeling, a main model to be deployed later is trained, then an adversarial model attempts to predict demographic membership from the main model’s predictions. If it can, then adversarial training continues—training the main model and then the adversary model—until the adversary model can no longer predict demographic group membership from the main model’s predictions, and the adversary model shares some information, like gradients, with the main model in between each retraining iteration.
In studies, pre- and in-processing tend to decrease measured bias in outcomes, but postprocessing approaches have been shown to be some of the most effective technical bias mitigants. Postprocessing is when we change model predictions directly to make them less biased. Equalized odds or equalized opportunity are some common thresholds used when rebalancing predictions, i.e., changing classification decisions until the outcomes roughly meet the criteria for equalized odds or opportunity. Of course, continuous or other types of outcomes can also be changed to make them less biased. Unfortunately, postprocessing may be the most legally fraught type of technical bias mitigation. Postprocessing often boils down to switching positive predictions for control group members to negative predictions, so that those in protected or marginalized groups receive more positive predictions. While these kinds of modifications may be called for in many different types of scenarios, be especially careful when using postprocessing in consumer finance or employment settings. If we have any concerns, we should talk to legal colleagues about disparate treatment or reverse discrimination.
Warning
Because pre-, in-, and postprocessing techniques tend to change modeling outcomes specifically based on demographic group membership, they may give rise to concerns related to disparate treatment, reverse discrimination, or affirmative action. Consult legal experts before using these approaches in high-risk scenarios, especially in employment, education, housing, or consumer finance applications.
One of the most legally conservative bias mitigation approaches is to choose a model based on performance and fairness, with models trained in what is basically a grid search across many different hyperparameter settings and input feature sets, and demographic information used only for testing candidate models for bias. Consider Figure 4-2. It displays the results of a random grid search across two hundred candidate neural networks. On the y-axis we see accuracy. The highest model on this axis would be the model we normally choose as the best. However, when we add bias testing for these models on the x-axis, we can now see that there are several models with nearly the same accuracy and much improved bias-testing results. Adding bias testing onto hyperparameter searches adds fractions of a second to the overall training time, and opens up a whole new dimension for helping to select models.
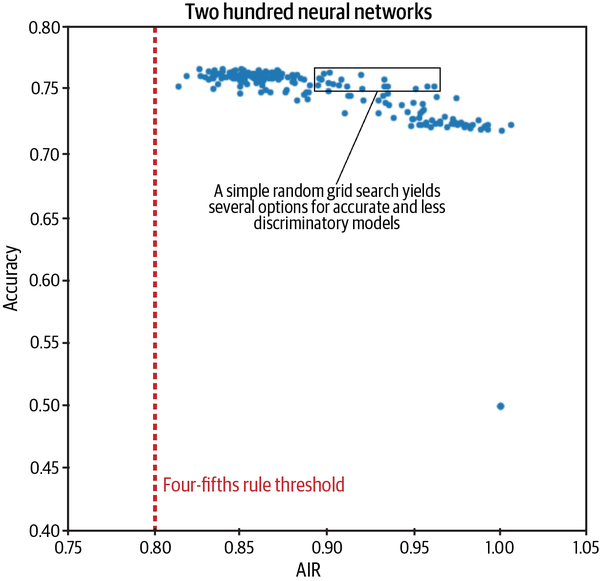
Figure 4-2. A simple random grid search produces several interesting choices for models that provide a good balance between accuracy and AIR
There are many other technical bias mitigants. One of the most important, as discussed many times in this book, is mechanisms for actionable recourse that enable appeal and override of wrong and consequential ML-based decisions. Whenever we build a model that affects people, we should make sure to also build and test a mechanism that lets people identify and appeal wrong decisions. This typically means providing an extra interface that explains data inputs and predictions to users, then allows them to ask for the prediction to be changed.
Detoxification, or the process of preventing LMs from generating harmful language, including hate speech, insults, profanities, and threats, is another important area in bias mitigation research. Check out “Challenges in Detoxifying Language Models” for a good overview of the some of the current approaches to detoxification and their inherent challenges. Because bias is thought to arise from models systematically misrepresenting reality, causal inference and discovery techniques, which seek to guarantee that models represent causal real-world phenomena, are also seen as bias mitigants. While causal inference from observational data continues to be challenging, causal discovery approaches like LiNGAM, which seek out input features with some causal relationship to the prediction target, are definitely something to consider in our next ML project.
Warning
Bias mitigation efforts must be monitored. Bias mitigation can fail or lead to worsened outcomes.
We’ll end this section with a warning. Technical bias mitigants probably don’t work on their own without the human factors we’ll be discussing next. In fact, it’s been shown that bias testing and bias mitigation can lead to no improvements or even worsened bias outcomes. Like ML models themselves, bias mitigation has to be monitored and adjusted over time to ensure it’s helping and not hurting. Finally, if bias testing reveals problems and bias mitigation doesn’t fix them, the system in question should not be deployed. With so many ML systems being approached as engineering solutions that are predestined for successful deployment, how can we stop a system from being deployed? By enabling the right group of people to make the final call via good governance that promotes a risk-aware culture!
Human Factors in Mitigating Bias
To ensure a model is minimally biased before it’s deployed requires a lot of human work. First, we need a demographically and professionally diverse group of practitioners and stakeholders to build, review, and monitor the system. Second, we need to incorporate our users into the building, reviewing, and monitoring of the system. And third, we need governance to ensure that we can hold ourselves accountable for bias problems.
We’re not going to pretend we have answers for the continually vexing issues of diversity in the tech field. But here’s what we know: far too many models and ML systems are trained by inexperienced and demographically homogenous development teams with little domain expertise in the area of application. This leaves systems and their operators open to massive blind spots. Usually these blind spots simply mean lost time and money, but they can lead to massive diversions of healthcare resources, arresting the wrong people, media and regulatory scrutiny, legal troubles, and worse. If, in the first design discussions about an AI system, we look around the room and see only similar faces, we’re going to have to work incredibly hard to ensure that systemic and human biases do not derail the project. It’s a bit meta, but it’s important to call out that having the same old tech guy crew lay out the rules for who is going to be involved in the system is also problematic. Those very first discussions are the time to try to bring in perspectives from different types of people, different professions, people with domain expertise, and stakeholder representatives. And we need to keep them involved. Is this going to slow down our product velocity? Certainly. Is this going to make it harder to “move fast and break things”? Definitely. Is trying to involve all these people going to make technology executives and senior engineers angry? Oh yes. So, how can we do it? We’ll need to empower the voices of our users, who in many cases are a diverse group of people with many different wants and needs. And we’ll need a governance program for our ML systems. Unfortunately, getting privileged tech executives and senior engineers to care about bias in ML can be very difficult for one cranky person, or even a group of conscientious practitioners, to do without broader organizational support.
One of the ways we can start organizational change around ML bias is interacting with users. Users don’t like broken models. Users don’t like predatory systems, and users don’t like being discriminated against automatically and at scale. Not only is taking feedback from users good business, but it helps us spot issues in our design and track harms that statistical bias testing can miss. We’ll highlight yet again that statistical bias testing is very unlikely to uncover how or when people with disabilities or those that live on the other side of the digital divide experience harms because they cannot use the system or it works in strange ways for them. How do we track these kinds of harms? By talking to our users. We’re not suggesting that frontline engineers run out to their user’s homes, but we are suggesting that when building and deploying ML systems, organizations employ standard mechanisms like user stories, UI/UX research studies, human-centered design, and bug bounties to interact with their users in structured ways, and incorporate user feedback into improvements of the system. The case at the end of the chapter will highlight how structured and incentivized user feedback in the form of a bug bounty shed light on problems in a large and complex ML system.
Another major way to shift organizational culture is governance. That’s why we started the book with governance in Chapter 1. Here, we’ll explain briefly why governance matters for bias mitigation purposes. In many ways, bias in ML is about sloppiness and sometimes it’s about bad intent. Governance can help with both. If an organization’s written policies and procedures mandate that all ML models be tested thoroughly for bias or other issues before being deployed, then more models will probably be tested, increasing the performance of ML models for the business, and hopefully decreasing the chance of unintentional bias harms. Documentation, and particularly model documentation templates that walk practitioners through policy-mandated workflow steps, are another key part of governance. Either we as practitioners fill out the model documentation fulsomely, noting the correct steps we’ve taken along the way to meet what our organization defines as best practices, or we don’t. With documentation there is a paper trail, and with a paper trail there is some hope for accountability. Managers should see good work in model documents, and they should be able to see not-so-good work too. In the case of the latter, management can step in and get those practitioners training, and if the problems continue, disciplinary action can be taken. Regarding all those legal definitions of fairness that can be real gotchas for organizations using ML—policies can help everyone stay aligned with the law, and managerial review of model documentation can help to catch when practitioners are not aligned. Regarding all those human biases that can spoil ML models—policies can define best practices to help avoid them, and managerial review of model documentation can help to spot them before models are deployed.
While written policies and procedures and mandatory model documentation go a long way toward shaping an organization’s culture around model building, governance is also about organizational structures. One cranky data scientist can’t do a whole lot about a large organization’s misuse or abuse of ML models. We need organizational support to effect change. ML governance should also ensure the independence of model validation and other oversight staff. If testers report to development or ML managers, and are assessed on how many models they deploy, then testers probably don’t do much more than rubber-stamp buggy models. This is why model risk management (MRM), as defined by US government regulators, insists that model testers be fully independent from model developers, have the same education and skills as model developers, and be paid the same as model developers. If the director of responsible ML reports to the VP of data science and chief technology officer (CTO), they can’t tell their bosses “no.” They’re likely just a figurehead that spends time on panels making an organization feel better about its buggy models. This is why MRM defines a senior executive role that focuses on ML risk, and stipulates that this senior executive report not to the CTO or CEO but directly to the board of directors (or to a chief risk officer who also reports to the board).
A lot of governance boils down to a crucial phrase that more data scientists should be aware of: effective challenge. Effective challenge is essentially a set of organizational structures, business processes, and cultural competencies that enable skilled, objective, and empowered oversight and governance of ML systems. In many ways, effective challenge comes down to having someone in an organization that can stop an ML system from being deployed without the possibility of retribution or other negative career or personal consequences. Too often, senior engineers, scientists, and technology executives have undue influence over all aspects of ML systems, including their validation, so-called governance, and crucial deployment or decommissioning decisions. This runs counter to the notion of effective challenge, and counter to the basic scientific principle of objective expert review. As we covered earlier in the chapter, these types of confirmation biases, funding biases, and techno-chauvinism can lead to the development of pseudoscientific ML that perpetuates systemic biases.
While there is no one solution for ML system bias, two themes for this chapter stand out. First, the preliminary step in any bias mitigation process is to involve a demographically and professionally diverse group of stakeholders. Step 0 for an ML project is to get diverse stakeholders in the room (or video call) when important decisions are being made! Second, human-centered design, bug bounties, and other standardized processes for ensuring technology meets the needs of its human stakeholders are some of the most effective bias mitigation approaches today. Now, we’ll close the chapter with a case discussion of bias in Twitter’s image-cropping algorithm and how a bug bounty was used to learn more about it from their users.
Case Study: The Bias Bug Bounty
This is a story about a questionable model and a very decent response to it. In October 2020, Twitter received feedback that its image-cropping algorithm might be behaving in a biased way. The image-cropping algorithm used an XAI technique, a saliency map, to decide what part of a user-uploaded image was the most interesting, and it did not let users override its choice. When uploading photos to include in a tweet, some users felt that the ML-based image cropper favored white people in images and focused on women’s chests and legs (male gaze bias), and users were not provided any recourse mechanism to change the automated cropping when these issues arose. The ML Ethics, Transparency, and Accountability (META) team, led by Rumman Chowdhury, posted a blog article, code, and a paper describing the issues and the tests they undertook to understand users’ bias issues. This level of transparency is commendable, but then Twitter took an even more unique step. It turned off the algorithm, and simply let users post their own photos, uncropped in many cases. Before moving to the bug bounty, which was undertaken later to gain even further understanding of user impacts, it’s important to highlight Twitter’s choice to take down the algorithm. Hype, commercial pressure, funding bias, groupthink, the sunken cost fallacy, and concern for one’s own career all conspire to make it extremely difficult to decommission a high-profile ML system. But that is what Twitter did, and it set a good example for the rest of us. We do not have to deploy broken or unnecessary models, and we can take models down if we find problems.
Beyond being transparent about its issues and taking the algorithm down, Twitter then decided to host a bias bug bounty to get structured user feedback on the algorithm. Users were incentivized to participate, as is usually the case with a bug bounty, through monetary prizes for those who found the worst bugs. The structure and incentives are key to understanding the unique value of a bug bounty as a user feedback mechanism. Structure is important because it’s difficult for large organizations to act on unstructured, ad hoc feedback. It’s hard to build a case for change when feedback comes in as an email here, a tweet there, and the occasional off-base tech media article. The META team put in the hard work to build a structured rubric for users to provide feedback. This means that when the feedback was received, it was easier to review, could be reviewed across a broader range of stakeholders, and it even contained a numeric score to help different stakeholders understand the severity of the issue. The rubric is usable to anyone who wants to track harms in computer vision or natural language processing systems, where measures of practical and statistical significance and differential performance often do not tell the full story of bias. Incentives are also key. While we may care a great deal about responsible use of ML, most people, and even users of ML systems, have better things to worry about or don’t understand how ML systems can cause serious harm. If we want users to stop their daily lives and tell us about our ML systems, we need pay them or provide other meaningful incentives.
According to AlgorithmWatch, an EU think tank focusing on the social impacts of automated decision making, the bug bounty was “an unprecedented experiment in openness.” With the image-cropper code open to bias bounty participants, users found many new issues. According to Wired, participants in the bug bounty also found a bias against those with white hair, and even against memes written in non-Latin scripts—meaning if we wanted to post a meme written in Chinese, Cyrillic, Hebrew, or any of the many languages that do not use the Latin alphabet—the cropping algorithm would work against us. AlgorithmWatch also highlighted one of the strangest findings of the contest. The image cropper often selected the last cell of a comic strip, spoiling the fun for users trying to share media that used the comic strip format. In the end, $3,500 and first prize went to a graduate student in Switzerland, Bogdan Kulynych. Kulynych’s solution used deepfakes to create faces across a spectrum of shapes, shades, and ages. Armed with these faces and access to the cropping algorithm, he was able to empirically prove that the saliency function within the algorithm, used to select the most interesting region of an upload image, repeatedly showed preferences toward younger, thinner, whiter, and more female-gendered faces.
The bias bounty was not without criticism. Some civil society activists voiced concerns that the high-profile nature of a tech company and tech conference drew attention away from the underlying social causes of algorithmic bias. AlgorithmWatch astutely points out the $7,000 in offered prize money was substantially less than bounties offered for security bugs, which average around $10,000 per bug. It also highlights that $7,000 is 1–2 weeks of salary pay for Silicon Valley engineers, and Twitter’s own ethics team stated that the week-long bug bounty amounted to roughly a year’s worth of testing. Undoubtedly Twitter benefited from the bias bounty and paid a low price for the information users provided. Are there other issues with using bug bounties as a bias risk mitigant? Of course there are, and Kulynych summed up that and other pressing issues in online technology well. According to the Guardian, Kulynych had mixed feelings on the bias bounty and opined, “Algorithmic harms are not only bugs. Crucially, a lot of harmful tech is harmful not because of accidents, unintended mistakes, but rather by design. This comes from maximization of engagement and, in general, profit externalizing the costs to others. As an example, amplifying gentrification, driving down wages, spreading clickbait and misinformation are not necessarily due to biased algorithms.” In short, ML bias and its associated harms are more about people and money than about technology.
1 The authors acknowledge the potential offensiveness of several of the terms appearing in this quoted language. The source material, NIST SP1270 AI, was reviewed and justified by the potential for extreme harm when ignoring scientific rigor in AI.
2 Note that updating loss functions for XGBoost is fairly straightforward.
Get Machine Learning for High-Risk Applications now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

