Chapter 4. Managing Model Development
Model development is the aspect that is most unchanged by the introduction of rendezvous systems, containers, and a DataOps-style of development, but the rendezvous style does bring some important changes.
One of the biggest differences is that in a DataOps team, model development goes on cheek-by-jowl with software development, and operations with much less separation between data scientists and others. What that means is that data scientists must take on some tasks relative to packaging and testing models that are a bit different from what they may be used to. The good news is that doing this makes deployment and management of the model smoother, so the data scientists are distracted less often by deployment problems.
Investing in Improvements
Over time, systems that use machine learning heavily can build up large quantities of hidden technical debt. This debt takes many forms, including data coupling between models, dead features, redundant inputs, hidden dependencies, and more. Most important, this debt is different from the sort of technical debt you find in normal software, so the software and ops specialists in a DataOps team won’t necessarily see it and data scientists, who are typically used to working in a cloistered and sterilized environment won’t recognize it either because it is an emergent feature of real-world deployments.
A variety of straightforward things can help with this debt. For instance, you should schedule regular efforts to do leave-one-out analysis of all input variables in your model. Features that don’t add performance are candidates for deletion. If you have highly collinear features, it is important to make time to decide if the variables really both need to be referenced by the model. Many times, one of the variables has a plausible causal link with the desired output, while the other may be a spurious and temporary correlation.
Build One to Throw Away
When you build feature extraction pipelines, use caution. The iterative and somewhat nondirected way that feature extraction is developed means that your feature extraction code will eventually become a mess. Don’t expect deep learning to fix all your sins, either. Deep learning can take massive amounts of data to learn to recognize features. However, if you combine domain-specific features with a deep learning model, you can likely outperform a raw deep learning system alone.
Given that your feature extraction code is going to become messy, you might as well just plan to throw it away at some point and develop a cleaned-up version. Of course, retaining live data using a decoy model is a great way to build a test suite for the replacement.
Annotate and Document
It may sound like a parent telling you to take your vitamins and wear galoshes, but annotating and documenting both current and potential model features and documenting signal sources and consumers pays huge dividends, far in excess of the return for doing the same sort of thing for normal code. It is often really difficult to get a team to do this annotation well, but since your mom and dad want you to do it, you might as well get started.
Gift Wrap Your Models
One of the most difficult things to debug in a production model is when it produces slightly, but importantly, different results due to a difference in the development and production environments. Happily, this problem should largely be a thing of the past thanks to container technology. It is now possible to build a container that freezes the environment for your models—an environment you certify as correct in development—and pass through to production, completely unchanged. Moreover, it is possible to equip the base container with scaffolding that fetches all input data from an input stream and returns results to the output stream, while maintaining all pertinent metrics. All that is left is to select the right container type and insert a model.
The result is a packaging process that doesn’t overly distract from data science sorts of tasks and thus is more likely to be done reliably by data scientists or engineers. The result is also a package that can immutably implement a model to be deployed in any setting.
For stateless models, it really is that simple. For models with state persisted outside the model (external state) it’s also that simple. For models with internal state, you have to be able to configure the container at runtime with the location of a snapshot for the internal state so you can roll forward the state from their. If the internal state is based on a relatively small window, no snapshot is necessary and you can simply arrange to process enough history on startup to re-create the state.
Other Considerations
During development, the raw and input streams can be replicated into a development environment, as shown in Figure 4-1.
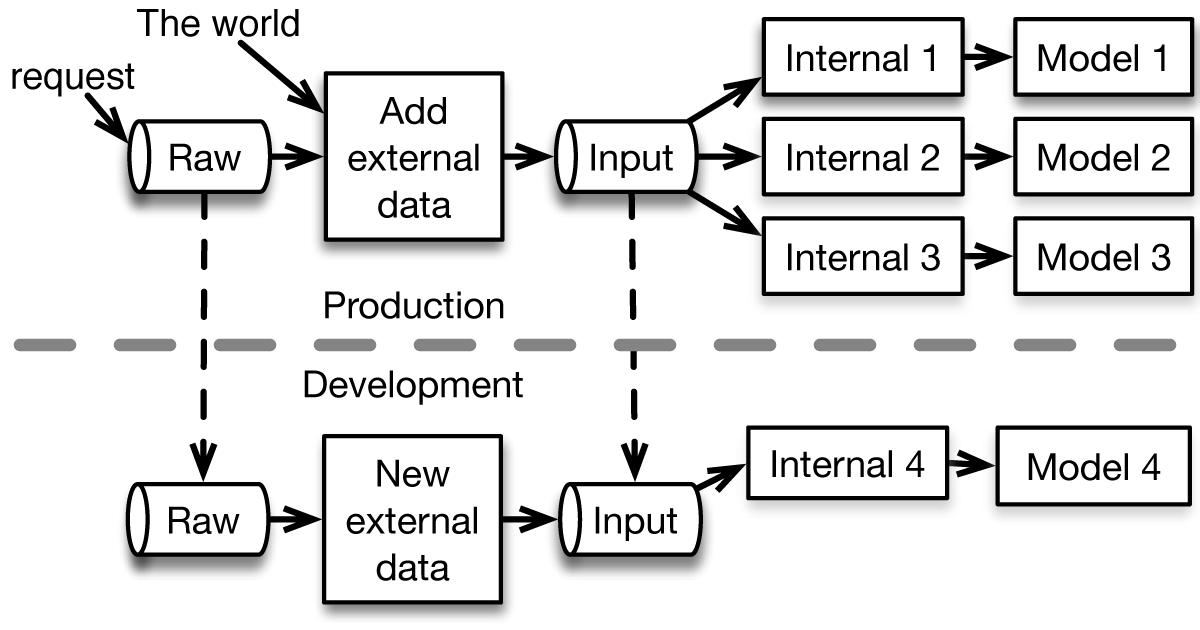
Figure 4-1. Stream replication can be used to develop models in a completely realistic environment without risking damage to the production environment.
If the external data available in the production environment is suitable for the new model, it is easiest to replicate just the input stream to avoid replicating the external data injector. On the other hand, if the new model requires a change to the external data injector, you should replicate the raw stream, instead. In either case, a new model, possibly with new internal state management can be developed entirely in a development environment but with real data presented in real time. This ability to faithfully replicate the production environment can dramatically decrease the likelihood of models being pulled from production due to simple configuration or runtime errors.
Get Machine Learning Logistics now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

