Chapter 1. Why Should I Migrate to Amazon Web Services?
I wondered whether putting such a loaded question as the first chapter of my book was a good idea. The actual list of reasons to migrate to AWS could be as long as this book, but like Simon Sinek says, “Always start with why.”1 Thus, I felt it prudent. The biggest roadblock you will encounter is people’s reluctance toward change. Migrating to AWS from your current platform is a change to the way people operate and the skills required. A sound narrative around the why will allow you to inspire the people around you and deliver better results while removing reluctance. This chapter will delve into many technological and business benefits gained by migrating to the cloud. With this information, you can provide the why to the upper levels of management and staff.
As you read this chapter, I encourage you to think about the situations your company is experiencing and how these benefits relate.
A way that has worked well in the past for communicating the why to coworkers is through a set of frequently asked questions (FAQ). Later in this chapter, we will walk through building out your FAQ to communicate the why to upper management and staff. You can accomplish this by anticipating the questions they will be asking and constructing answers based on the benefits your company will realize. By completing this exercise, you will gain acceptance and lessen detractors. You are increasing the probability of success and efficacy of the transition.
Cloud Technology Benefits
AWS offers several benefits with the latest cutting-edge technologies. However, not all these technologies and their benefits apply to every company. Instead of walking through every benefit, we will walk through the technical benefits that apply to every company. They may not be flashy, but they create a solid base on which you build your infrastructure. By taking advantage of these benefits while you migrate to AWS, you will reap enough capital and time savings to fund the testing of more advanced technologies. I have been able to save companies millions of dollars using these methods, which they can then reinvest in innovation. I agree that automatically transcribing customer support calls and analyzing for customer sentiment is an awesome and powerful tool for your business. However, I believe that migration is one of the crawl-before-you-walk situations. As a manager, your primary concern is to ensure that your migration meets your business needs and regulations. Implementing the latest cutting-edge AI is secondary; after all, the infrastructure you have today is what pays the bills and provides your current customer value.
Scalability and Dynamic Consumption
When you migrate to AWS, you need to focus on diverging your thinking from how you used to operate on-premises infrastructure. Many of the conventional design patterns and operational processes are anti-patterns in the cloud. For scalability and consumption, many of these anti-patterns show up early in your migration. It is best to identify and move past them quickly. Changing your existing thought process around on-premises scalability will immediately afford you cost savings and agility when comparing it to scalability in the cloud. Before we cover these new patterns and why the on-premises patterns are anti-patterns, we will walk through the scalability AWS offers you. Again, as you read, it might make sense to jot down some notes about your applications and how these scaling methods might improve your capabilities.
Vertical scaling
Vertical scaling is the practice of adding compute and memory to a server to increase the performance available to the workload. I liken it to being Amish and plowing my field. I am plowing a new row, but the soil gets hard. To complete my plowing, I unhitch my quarter horse, go to the barn, and get a bigger draft horse. Vertical scaling is not a novel idea for the cloud. It has been there the whole time in your data center, and in my experience, it is the go-to method of improving performance and increasing capacity. However, with migrating to AWS comes some key differences.
When you have your infrastructure running in AWS, you have a pay-as-you-go dynamic consumption model instead of a prepaid model. I like to explain it like the tides: the moon’s gravity pulls on the earth and raises the water level of the ocean as it passes. This analogy mirrors the usage of your infrastructure throughout the day—the pull on your resource load ebbs and flows. Just like the tide, you end up with a high and low watermark. The difference with the cloud is that you only pay for what you use; you only must buy at the low watermark. Then you incrementally pay for more consumption during the high usage times. On-premises, you have to prepurchase at the high watermark. To complicate the issue further, you must forecast your consumption for the life of the hardware, which will be over or under the actual consumption. Underutilized resources are a drain on your company’s funding, and over-utilized resources provide a poor user experience. The purchase of on-premises equipment in my analogy can be pictured like building a dock. If you place the dock too high, you will have to put in ladders for people to get to their boats. If you place the dock too low, they will be sloshing around in the water. AWS is a floating dock and eliminates both issues; it rises and lowers, providing optimal conditions. Figure 1-1 shows what prepaid purchasing and consumption looks like over its lifetime.
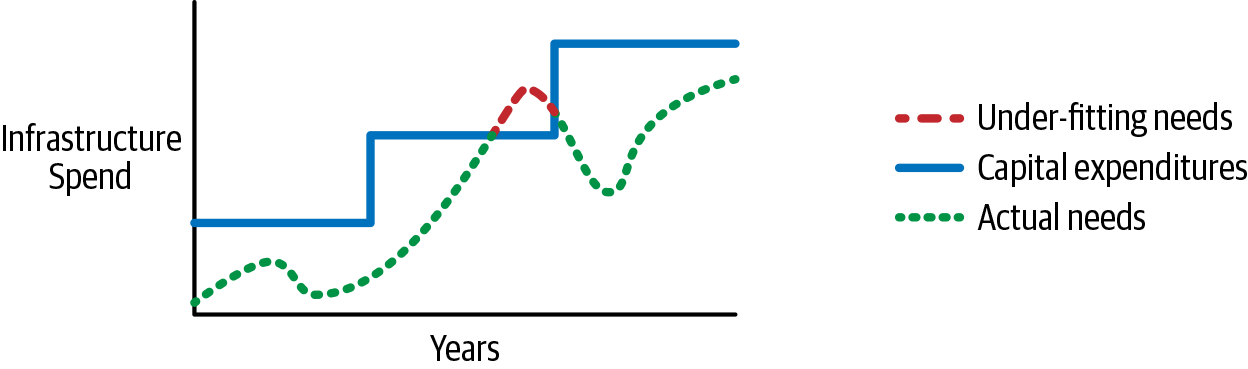
Figure 1-1. Infrastructure costs over time
Figure 1-1 does an excellent job of showing how the purchase of on-premises equipment under- or over-fits your company’s needs. If you compare the dotted line, which stands for your need, and the solid line, which represents your capital expenditures, you will see how far the gap between them ebbs and flows. At one point, the demand exceeds the capacity of the infrastructure, indicated where the line is dashed, meaning that you do not have enough capacity to service customers. I would say not having enough capacity is not common. Most people, including me, buy more than they need, so a situation like that never arises. Having consistently underperforming IT resources is a good reason for your manager to ask you to empty your desk. The important thing this graph shows is how you must purchase not only for the high watermark, but also for well above it. The overage ensures enough capacity, and all the space between the dotted and solid lines is wasted capital. The dynamic ability of AWS eliminates this overage and lost capital, allowing you to use those funds for other business needs.
If you think back in your recent history, you may remember a conversation much like the following scenario.
This is a prevalent scenario, both on-premises and in the cloud. There are a few things I would like to draw attention to that will change after you migrate to AWS. First, instance is AWS nomenclature for a server or virtual machine from the Elastic Compute Cloud (EC2) service, and these terms can be used interchangeably. However, I will use instance whenever I am talking about a server in AWS, and server or virtual machine to indicate a server on-premises. The second is the statement “memory usage is within limits.” When working with instance sizing in AWS, you cannot adjust CPU and memory separately. You must find the smallest instance that meets the memory or CPU target, and whichever is not your target goes along for the ride. In this example, the CPU capacity is your target. When you increase by two more CPUs in AWS, your memory will increase as well. Third, it may be better to use horizontal scaling instead, to spin up more instances when needed to address the load instead of making a permanent vertical change. We will discuss horizontal scaling in the next section.
Note
AWS offers a capability called Optimize CPUs for Amazon EC2 instances. This capability allows you to set the number of CPUs when you launch an instance. The setting cannot be modified later and does not alter the run rate of the instance. These limitations may not be immediately evident when reading the documentation and make it appear that AWS operates like on-premises capabilities. The primary reason for the Optimize CPUs function is for the software licensing base on CPU count and edge-use cases when CPU is low while also requiring high RAM.
Let’s take a look at another possible scenario.
In this situation, AWS can shine by reducing your costs of operation. As mentioned before, while on-premises, you must purchase equipment to meet your high watermark, so you have already committed funding to operate your environment. Allocating more CPU power to address batch processing is irrelevant to the costs of operation. However, in AWS, you are purchasing at the low watermark, and it is best to stay there.
You may be wondering how you address the performance issue. It is best to solve this scenario by using temporary vertical scaling. You know when this workload will come up, and you know it is only temporary. It would not make sense to increase the capacity to address the batch process permanently. Using scheduled events or third-party software, you can schedule the scaling up of this server before the workload and then scale it back down after it completes the work. Temporary scaling would give you the most cost-effective operation.
Horizontal scaling
Although vertical scaling adds more capacity to a single server, horizontal scaling allows you to add more servers to meet the load for your application. Using my Amish analogy again, if the soil got too hard, I would hitch a second horse to finish my plowing instead of getting a bigger horse. Again, with the AWS pay-as-you-go model, you can gain significant cost reduction by using horizontal scaling. To achieve horizontal scaling, AWS offers two crucial services, Elastic Load Balancing and AWS Auto Scaling.
Tip
Always start with horizontal scaling and work back from there to find technical reasons why it will not work. Only then revert to vertical scaling.
Warning
Windows servers that are attached to a domain require special consideration. These servers need special scripting to add and remove themselves to the domain during horizontal scaling events.
Elastic Load Balancing
You may remember I had said that vertical scaling was typically the go-to method of scaling on-premises. To implement horizontal scaling on-premises, you would have to buy a load balancer. The increased capital, maintenance, and care-and-feeding soft costs are a significant deterrent to using load balancers for capacity needs. Implementing on-premises load balancers is seen more often when there is a specific high-availability concern, or there is limited ability to scale vertically. With load balancing, the dynamic consumption in AWS again provides a considerable advantage. You only pay for the load balancing you need, so there are no up-front costs. You will also benefit from a serverless technology. The Elastic Load Balancing in AWS does not have any servers you need to maintain or patch, reducing your soft costs. As you can see, load balancing in AWS is more attractive, making horizontal scaling for performance more accessible.
Note
The term serverless means a lot of things to different people and companies. In the context I use it, as represented in this book, it refers to any service that doesn’t require you to manage servers or infrastructure. Obviously, there are servers somewhere doing the work; you just don’t need to care about them.
AWS Auto Scaling
While the Elastic Load Balancing service provides the network connectivity between the users of your application and the servers, the AWS Auto Scaling service contains the needed logic to control the expansion and contraction of the server pool. Without this expansion and contraction, your costs would again be static and less efficient. Auto Scaling has multiple triggers available to add and remove capacity from your application server pool. You can use CPU usage, memory usage, and disk input/output operations per second (IOPS) for a needs-based option. Another option, if you know when your load will occur, is auto-scaling using a schedule. The AWS Auto Scaling service also allows you to set a minimum number of servers and can act as a high-availability orchestrator, ensuring that a minimum amount of compute is available to service your customers. The way you look at availability and disaster recovery (DR) also changes, but I will touch on that later in “Disaster Recovery/Business Continuity”.
Let us take a second to think back to the conversation with Tom about the CPU capacity needs for the meme generator application in “Scenario 1-1”. In this scenario, it makes perfect sense to switch from a vertical scaling solution used on-premises to horizontal scaling in the cloud. Using this method will produce the best experience for your customers while supplying your company with the best cost consumption available. When CPU usage rises as more people generate memes, the auto-scaling service adds a server to meet the load. When the server is online and available, auto-scaling will add it to the load balancer to service customers’ requests. The process works in reverse when load drops, returning to your baseline settings. There are a few caveats to using horizontal scaling, though. Your servers need to be stateless. Stateless means that no specific configuration or data lives on the server, and the server can be deleted with no adverse effects on the overall operation. Another caveat might be that you need preconfigured instance images created to reduce instance launch time.
Geographic Diversity
Now that we have covered scalability, let us cover another key AWS benefit: geographic diversity. Think about your data center(s). Where are they? How far apart are they? How many are there? If you manage a smaller operation, then the answer is probably few, and if you have more than one, they are probably not far apart. I can tell you from my experience that my data centers at one company were only seven miles apart. Not exactly geographically diverse, but better than the solution was before, having a single data center. If you are a large enterprise, you probably have two or more data centers, and they are most likely farther apart. However, how close are they to your users? How is the remote office in Brazil connected to your data center in New York?
I have migrated many Fortune 500 companies and a few smaller companies to AWS. Throughout my experience, I can tell you that no matter what your configuration is, when you migrate to AWS, you can do it better. AWS has impressive geographic diversity, and you can use that to your advantage for high-availability and disaster recovery concerns and bring the services closer to your customers for a faster user experience. To highlight how you can take advantage of this capability, we will walk through how AWS deploys its infrastructure. There are regions and availability zone (AZ) concepts, as shown in Figure 1-2. AWS provides a website with an interactive globe detailing its regions, network connectivity, and points of presence.
Tip
Do not try to extend your company into many regions for the sake of diversity. There should be a compelling business reason, because there may be additional costs associated with it.
Regions
AWS regions are a collection of availability zones that have data centers in a geographic area. The concept of regions is very foreign when compared to on-premises operations. On-premises you don’t have the ability to create a comparable infrastructure design. You don’t have the economy of scale to create such a vast infrastructure.
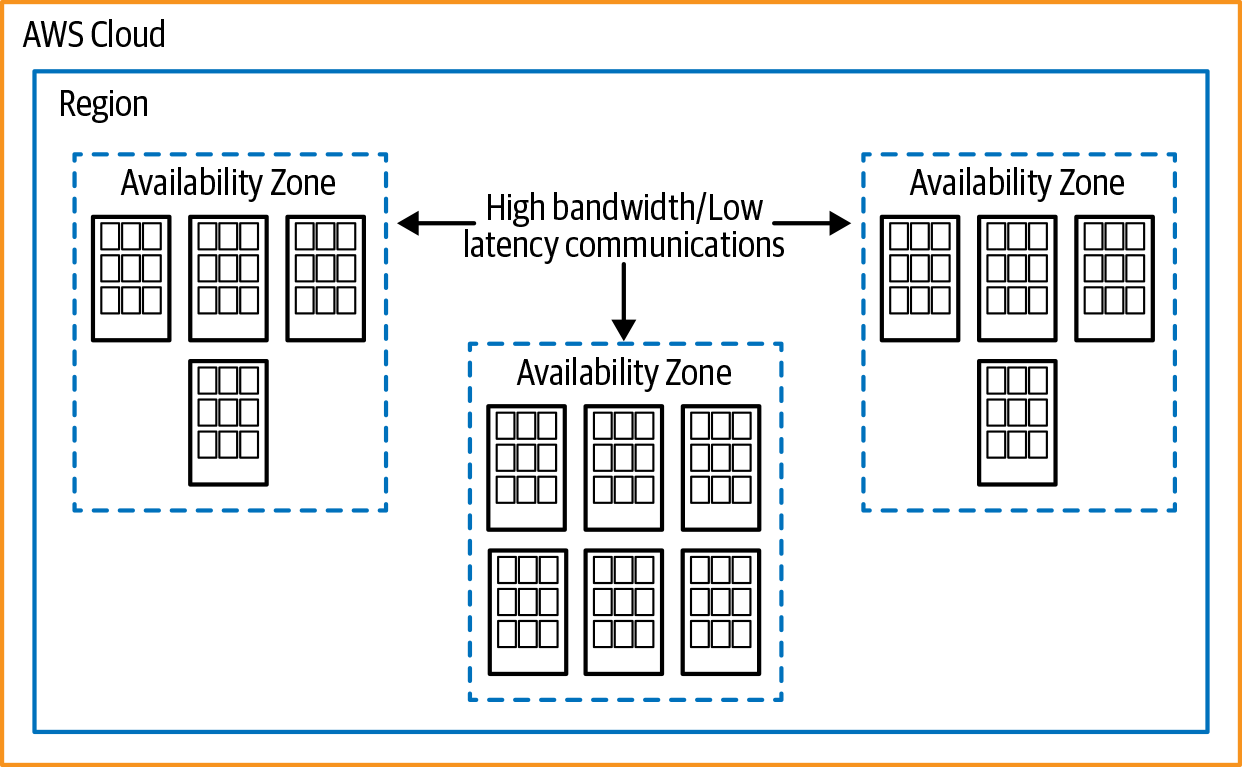
To help understand the concept, we can draw a similarity to how the United States is segmented. A region could represented by an individual state. Within a state there are counties (parishes if you live in Louisiana, or boroughs in Alaska), and they represent availability zones. The last aspect of a region in AWS is the data centers; you can think of these as the cities within a county. At the time of writing, the AWS infrastructure consists of the regions shown in Table 1-1.
| Region name | Region |
|---|---|
US East (N. Virginia) |
us-east-1 |
US East (Ohio) |
us-east-2 |
US West (N. California) |
us-west-1 |
US West (Oregon) |
us-west-2 |
Africa (Cape Town) |
af-south-1 |
Asia Pacific (Hong Kong) |
ap-east-1 |
Asia Pacific (Mumbai) |
ap-south-1 |
Asia Pacific (Osaka-Local) |
ap-northeast-3 |
Asia Pacific (Seoul) |
ap-northeast-2 |
Asia Pacific (Singapore) |
ap-southeast-1 |
Asia Pacific (Sydney) |
ap-southeast-2 |
Asia Pacific (Tokyo) |
ap-northeast-1 |
Canada (Central) |
ca-central-1 |
China (Beijing) |
cn-north-1 |
China (Ningxia) |
cn-northwest-1 |
EU (Frankfurt) |
eu-west-1 |
EU (Ireland) |
eu-central-1 |
EU (London) |
eu-west-2 |
EU (Milan) |
eu-south-1 |
EU (Paris) |
eu-west-3 |
EU (Stockholm) |
eu-north-1 |
Middle East (Bahrain) |
me-south-1 |
South America (São Paulo) |
sa-east-1 |
Warning
AWS does not offer all services in every region. Refer to the AWS Region Table to ensure that all the services you require are available before migration.
Data proximity
When you are getting ready to migrate to AWS, you will want to think about your users and their location, and select the region closest to them. These could be internal or external users, or both. The benefit AWS brings over conventional on-premises data centers is that you do not have to limit yourself to just one or two regions. You have at your disposal every AWS region across the globe. There are no sunk costs associated with launching a new region like there are with a data center. You do not have to lease space or purchase power conditioning, fire suppression, security, racks, and all the other things needed to launch a data center properly. AWS has taken care of this for you. Because of the multitenant and the pay-as-you-go models, you only need to pay for the infrastructure you use in that region. Let’s look at a few scenarios to help you get an idea of how you might use regions in your migration.
Let us take a second to walk through this scenario as if we were Sam. Most of the corporate users are in Washington, DC. The first thing you want to do is pick an AWS region with proximity to your staff to reduce latency. An obvious choice would be the us-east-1 region in Virginia. Selecting Virginia ensures that the bulk of the internal users have the lowest latency possible. The speed of light is fixed; there is not much we can do to make data transmission faster. Selecting something close like Virginia is not unique to the cloud; her data center is probably within a few hundred miles of the corporate headquarters already. However, when you think about the second statement, how the largest customer is in Seattle, this is where design planning in AWS shifts. AWS has regions all around the US; it would make sense to place some infrastructure to support her biggest client in Seattle. I would choose the us-west-2 region in Oregon as a second deployment location, specifically for her online application. The beautiful part is that Sam need not worry about all the components of a data center. She only has to concentrate on and pay for the servers required for her biggest customer. Deploying in two regions like this on-premises would be costly.
In Bill’s situation, I would recommend starting with latency to find out how the base deployment would look. Since the servers in the offices only serve the local office in which they are located, there will not be much traffic crossing the country. I would recommend that Bill use the us-east-2 region in Ohio for the Chicago servers and us-east-1 for his New York servers. Using this configuration should give his users the lowest latency to their respective servers. Since his company has a website, but it is not an essential customer application, I would suggest that Bill place it in a single region in AWS. Bill can make his website faster for customers by using Amazon CloudFront, a content distribution network (CDN). Using CloudFront will increase performance without the complexity of more servers in other regions. Lastly, Bill has an internally developed application that both offices use. Since this application is privately built, Bill can take advantage of the two regions with some minor reprogramming. This design provides a multimaster (you can write data in both places) and multiregion solution, which would give the best performance and availability.
Brittany has the most straightforward selection process. Her entire user base is located in Columbus, OH. I would suggest she use the us-east-2 region in Ohio to host her infrastructure since a third party hosts her website. Where to locate their site does not affect her decision. Brittany may want to replicate her data to a second region for disaster recovery purposes, but I’ll touch on that in the section “Disaster Recovery/Business Continuity”.
Data locality and privacy regulations
There has been much talk about the General Data Protection Regulation (GDPR) in the European Union (EU). This regulation, along with others, has raised concerns with IT management on how to meet the data sovereignty requirements it imposes. Since AWS has regions located around the globe, it is easy to control data storage sovereignty according to the country where the regulations exist. Data locality is only part of the puzzle. You also may need to validate that the data does not cross borders during transactions. Just storing the data in the correct country does not rubber-stamp all your infrastructure and operations if you have processing outside of the designated region. However, having all the AWS regions available to you gives you a significant advantage over on-premises deployments where you may need to acquire new data centers to meet the regulations.
One important caveat that I want to point out for data sovereignty is that some countries don’t have more than one region. For instance, if you have regulations in Canada that require data to be stored in the country, you will have limited options at this time for multiregion deployment. Currently, AWS only has the Canada central region (ca-central-1). AWS continues to add new regions all the time, and this may not always be the case for Canada, but it is essential to consider your DR requirements for sovereignty. AWS has sufficiently covered the US and EU, but areas like South America and Asia-Pacific may require added consideration. It is important to note that every region has at least two availability zones. For most companies, this may supply enough availability to cover your requirements for DR while maintaining sovereignty.
Availability zones
Thinking back to my state analogy, the cities represented the actual data centers; the counties were the availability zones (AZs) in an AWS region. AZs play a key role in high availability within a region. AWS connects AZs with low-latency fiber-optic networking, allowing data to move between them with ease. The zones are also geographically separated, so an event like a flood or tornado in one zone will not affect the others. To make it easier to visualize, you can think of an availability zone as a single data center. Most regions have three availability zones to choose from for the deployment of infrastructure. To help solidify the concept, let’s walk through a hypothetical AWS region.
The AZs and their separation are a significant benefit over conventional data centers. Many companies have the equivalent of two regions in their on-premises deployment but only a single AZ. A data center will typically be found close to the principal office and then a second in a distant location for disaster recovery purposes. The concept of availability zones rarely exists on-premises. Similar to the shift in thinking with scaling and regions, there also needs to be a shift in thinking on how you address availability in your infrastructure design. Shifting your thought process allows you to take advantage of the benefits of AZs. Let’s look at a scenario to help you get an idea of how you might use AZs in your migration.
Jim has increased his availability, but he has not improved his geographic diversity. If his primary data center goes offline, Jim will still have to failover to the disaster recovery site in California. I don’t know about you, but thinking about DR used to give me heartburn. Our DR was all designed and verified, and we had done failover testing. However, testing is usually just one piece at a time, not an entire data center. Would it all work in the event of a disaster? It should is the answer. I dislike it should. I want sure things, and the best way to have a sure thing in a disaster is to shift your thinking from DR to business continuity (BC). On-premises, Jim would have a challenging time incorporating BC into his application and making it highly available. Business continuity is much easier to achieve in AWS thanks to AZs. Availability zones are geographically diverse within a region, giving them separate power and communication feeds. They are also far enough apart that a tornado would only affect one AZ. Jim could reconfigure his application when he migrates into AWS. He can use two AZs for his SQL server mirror and his web servers. His aim should be to create a highly available and continuous operation if one AZ were to go offline.
AZs and disaster recovery
The AWS AZs are one of the most critical changes that help businesses when they migrate to AWS. Disaster recovery on-premises is a hard problem to solve; it never gets the love, attention, and funding it should. It ends up being a drain on resources and a significant source of stress for management. I think back to my days in banking, where DR is critical. It would be so much easier to change the conversation to BC and add some years back onto my life. When you migrate to AWS, I encourage you to pay particular attention to how you can deploy your infrastructure in multiple AZs to achieve business continuity.
I want to bring attention to a design pattern that comes up many times with AZ deployment. You must not fall into the same trap. Many companies deploy and configure two AZs in a region and think they have all the availability they need. Who can fault their logic? They have two deployments; when one fails, the other takes over. I would encourage you to think long-term. What happens when an AZ fails, but it was because of a natural disaster? The failed AZ will not come back online soon. In this situation, you would have to redeploy the second set of infrastructure to another AZ. If you only have set up two AZs and one is now offline, you would have to construct a new AZ deployment. All the while, you are still feeling the pressures of being in a failed state. I recommend deploying at least three AZs from the start, to address any potential AZ failure.
Easy Access to Newer Technologies
With scalability and geographic diversity, we touched on the physical benefits of AWS; now, we are going to cover a logical benefit with easy access to newer technologies. In the early days of AWS, the services were limited to a few such as Simple Storage Service (S3) for object storage and Elastic Compute Cloud (EC2) for compute. AWS now offers dozens of services, from managed database platforms like Relational Database Service (RDS) to AI tools like SageMaker. Access to new technologies allows companies to adopt and expand their capabilities and innovate for their customers more readily. To highlight how access to these technologies can improve any company, I want to show it using a very drastic comparison. The addition of these more advanced services, coupled with the pay-as-you-go model, has changed the ability of small startups to compete with Fortune 500 organizations. Think of a boxing match. In one corner is the startup—small, but fast. In the other corner is the incumbent Fortune company—big, but slow. In this boxing match, the opponents are not evenly matched. The smaller, more agile company can outmaneuver the large incumbent, but its success depends on landing enough punches before the big company can wind up and knock them down.
To give an example of what this might look like, let us look at some technologies AWS can economically provide to startups. An example of a costly technology to implement on-premises is data warehousing and analytics. For a startup to get into analytics, it would have to generate a substantial amount of investment to buy the needed hardware to store and process massive amounts of data. The expenditure of this size takes funding away from vital company functions such as paying staff wages. Day-one operations of a startup doing analytics on-premises could cost tens or hundreds of thousands of dollars for initial hardware expenditures. The procurement of large amounts of hardware by a large incumbent company is easy. Paying hundreds of thousands is not hard; the difficulty for a large company is in the time to execute.
By launching in AWS, this same startup would have easier access to new technologies like analytics for two reasons. The first is that AWS has many advanced technology services available for a startup to choose from in the analytics space. There is Amazon S3 object storage for storing vast amounts of data in a way that is cost effective. Amazon QuickSight offers business intelligence tooling, and services like Amazon Athena and AWS Glue supply data processing and querying capabilities. Offering the services alone is not a special sauce. When you couple these advanced technology services with the pay-as-you-go model, you have the proper ingredients to incite competition by dropping the significant capital expenditure and removing the barrier to entry.
Inexpensive and easy access to these new technologies allows any company to test, experiment, and innovate in ways never before possible. The number one thing preventing companies from experimentation and innovation is the fear of failure. Failure on-premises is a very costly endeavor, leaving extra or specialized hardware and software sitting on shelves instead of cash in the bank. After migrating to AWS, the accessibility of technology and the low cost of failure can enable your company to innovate and deliver improved results for your customers. Let us look at what accessibility to new technologies might look like for your company.
On-premises, Amy would have her work cut out for her to make this request happen. She would need to deploy some servers to do the AI model training. Depending on which machine learning algorithm is selected, Amy may need to buy some specialized hardware to run the computations. Amy will also have to solve the problem of who will program and maintain this AI application, which requires a specialized skill set. All these items create a significant roadblock to adoption. Amy does not have easy access to new technology. However, after Amy’s company migrates to AWS, she would have a much simpler time implementing this request. AWS has a service called Amazon Forecast that does this AI computation. Amy would not have to worry about servers, hardware, or a specialized AI programming skill set to test this technology. Amy could use her current IT staff and programmers to implement a proof of concept (POC) and only pay for the training time in hours, data storage in gigabytes (GB), and generated forecasts ($0.238, $0.088, and $0.60 per 1,000, respectively).
Availability
We have already discussed geographic diversity and scaling and how they can increase your availability. However, these are not the only capabilities AWS offers to enhance your availability. There are many technological ways AWS increases availability, but let us focus on a select few that are most likely to be relevant to your needs.
If you look at the history of AWS, you can see that the offerings continue to be created serverless, like the elastic load balancers we discussed before. Since you are not deploying any servers, you do not control quantity or deployment location. AWS designs these services to be highly available for you, relieving this workload and stress from your life. I am sure you will appreciate less work and stress. You will not be sitting on the beach sipping piña coladas, but it is one less thing to worry about postmigration. The way AWS accomplishes this higher level of availability for these serverless offerings is by fully exploiting the availability zone concept to deliver them. Here are two scenarios detailing how you might use these services in your environment to gain higher availability as opposed to your on-premises configuration.
In Keith’s deployment, there is a better way of architecting this solution in AWS to increase his availability. In this situation, my recommendation would be to move the report files to Amazon S3. S3 is an object store and is perfect for storing data that needs to be downloaded from the internet. S3 is also one of the serverless offerings from AWS and is designed for high availability. S3 replicates your files between all the AZs in a region automatically and provides 11 nines of durability. What are 11 nines of durability? It means there is a 99.999999999% probability your file still exists on the storage. I have heard it is probable that S3 data will outlive humanity. I am not a mathematician, so I cannot validate the claim. However, doing some napkin math, it sounds plausible. By making a few minor alterations to the application, Keith can achieve high availability, almost unimaginable durability, and confidence in the ongoing workload on his staff.
Note
AWS provides 11 nines of durability, not availability. It is important to remember the difference. The AWS service-level agreement (SLA) guarantees that the data exists in storage, not that it is always available to be retrieved. Rest assured, their track record has been pretty darn good.
Kathy’s situation is not unique. I based this scenario on my real-life experience with one of my data centers. Water raining down in a data center is not a good thing, and something you never thought about addressing. Come to think of it, this is the same data center that had part of the wall collapse. Construction workers were removing a pedestrian bridge next door. A crane slammed a massive piece of concrete into the wall. These are the situations when life is stranger than fiction. I could not make this stuff up, and neither can you—that is the point. You cannot think of all the things that can happen to your data center and, like Kathy, it is best to address this in your deployment. For Kathy’s implementation, it would make sense to use the Amazon Elastic File System (EFS) to store the data for her HPC cluster. EFS supports the NFS protocol required for the operation of her cluster and offers redundant data storage across AZs. This service is a serverless offering and does not require any input for this availability.
Increased Security
In keeping with the trend of logical benefits, AWS offers another with increased security. A few years ago, people were fearful regarding the security of their data in the cloud. I can partially understand their reluctance. I say partially because large software as a service (SaaS) providers like Box had a booming business. People were not afraid to put their business data on those platforms. It is ironic to me that those same people feared placing the rest of their data on AWS. For most, the fear of moving their data to AWS has passed. After breaches, large companies have stated that if they were on AWS, the breach would not have happened, or it would have had less impact. Zero trust and least privilege are best practices in AWS. These two methodologies are quite effective in securing your environment. The benefit in AWS is that it makes the implementation of these principles quite easy.
Zero trust
Trust security on-premises has mostly remained unchanged for the past few decades. Most networks have a three-zone deployment. An internet zone exists for connecting to the internet and hosting other devices, like firewalls and virtual private network (VPN) controllers. Behind that, there is an edge zone or demilitarized zone (DMZ) that hosts the web servers and email servers.
Further into your network, there is an internal zone that hosts your private servers and data. Some companies deploy a fourth zone where printers and workstations exist, which allows further separation from the private servers. Having zones was a good security design for networks 20 years ago. The problem with this design is that there is a level of trust for each zone. You do not trust the internet, somewhat trust the edge, and fully trust the private zone. This concept sounds good when you think about it, but after all the recent corporate breaches that have occurred, you can see why it is dated. Once you pierce the veil of the edge or internal zones, you can skip around like Dorothy on the yellow brick road. This design implements perimeter security. Break through the perimeter, and there is little to stop you from poking and prodding the rest of the servers until you break into them.
Zero trust is when no server trusts any other server. If you can break into a server in the edge zone, you cannot communicate to any other servers in that zone unless allowed by design. Instead of happy Dorothy, you end up in a cold dark cell, like Al Capone, contemplating your rapidly declining health. Zero trust restricts your blast radius from any attacks, thus making your environment more secure. Nothing says you cannot do this on-premises. I implemented this security for a bank I worked for. It took a long time to implement, and it cost tens of thousands of dollars for the technology and tens of thousands more in employee effort.
AWS Security Groups are a significant benefit to zero trust security and do not cost tens of thousands of dollars. Security groups cost nothing. Security groups are how AWS implements firewalls in AWS. A security group provides an external firewall to your instance or group of instances; it is not a piece of software running on the instance itself. Like a firewall, it controls all the traffic flowing into your instance and blocks anything that you have not explicitly permitted. To make management even easier, you do not have to control traffic by just IP addresses either. Security groups allow you to reference other security groups. This referenceability makes managing security even less burdensome than it is on-premises. When you assign or unassign instances from a security group, the security group automatically adjusts without manual intervention, whereas changing servers and IP addresses on-premises becomes an issue if firewall rules are not updated and become stale. By referencing a security group as a source when a server is added or removed, it is automatically inserted or removed from the security group. This automation ensures that there are no old, static references.
Tip
Make sure your team breaks the habit of using IP addresses for AWS resources and switches to security group references.
Let us look at a scenario where this would happen on-premises.
If John’s servers had been in AWS, most of this attack would have been blocked. The web server compromise would have still occurred—John did not effectively manage the security and remove the vulnerability. However, once the attacker had gotten into the web server, they would not have been able to jump from the server to another server so easily. By implementing zero-trust security group rules, the hacker could not have moved to the other servers in the edge zone. They would not have a way of getting there, and the second that John removed the third database server, it would no longer be in the security group. Therefore, access to the payroll database server would have been blocked as well.
Least privilege
Least privilege is controlling authorization to the smallest level of access to do the work required. You can think of it as security at an airport. As a passenger, you can get through the security checkpoint, but you cannot get on the wrong plane or enter a storage room. The woman who works the counter at Starbucks can get through the security checkpoint and enter the storage room, but she cannot get on any plane or the tarmac. A baggage handler can get on the tarmac and into the baggage processing rooms, but he cannot get onto a plane or into a storage room. This is least privilege: everyone gets the access they need to do their job, nothing more.
AWS considers security job zero, by which they mean that it’s even more important than priority number one. A lot of thought has gone into how access controls work. AWS offers very fine-grained control over the capabilities of each service through a service called Identity and Access Management (IAM). This control allows you, like the airport, to give only the access needed to operate a particular service. The countless permissions AWS services offer are segmented into list, read, tagging, and write. Table 1-2 details the capabilities associated with these permissions.
By using these individual access controls, you can grant access to a minimal subset of actions. Why would you want to do this, and why is it a benefit to security in AWS? It boils back down to blast radius. If an attacker were to gain access to a set of credentials, you want to limit the actions they can perform to limit the amount of damage they can do. Let us look at a scenario without least privilege set up and see what can happen.
A situation like Rob’s is not unique to the cloud. Just like scaling on-premises is possible, so is least privilege. It is just more difficult to implement on-premises. When you are working on-premises, there are dozens of places where you need to implement security: firewalls, switches, hypervisors, and the list continues. It is like an office full of desks, and you need to go around to each desk and lock the drawers. After you migrate and start using AWS services, your task of securing becomes a lot easier. Instead of focusing on securing every desk in the office, you just need to secure the office. IAM works as the door to your infrastructure. Every user passing through that door gets their authorization as they pass through. IAM allows you to assign the list, read, tagging, and write permissions as your users enter, to give you granular control.
Cloud Business Benefits
Although there are significant technical benefits in migrating to AWS, there are a number of business benefits as well. I consider the business benefits significantly more attractive than the technical ones. It is a bit like beginning a relationship. The technical benefits attract you in the first place, whereas the business aspects are the mental attractions that keep the relationship growing and interesting. Although the technical benefits might be a why when you start migrating to AWS, they will quickly become a how after the technical hurdles are resolved. Just like the world of love, the physical side of the equation can wane as it becomes ordinary and expected. Sure, AWS will come out with new services and capabilities to spice up the technical side; however, it all comes back to the business side of the house. You do not implement technology for technology’s sake—there is always a business driver behind it. That is why I want to bring to the forefront the business benefits that migrating to AWS will offer you.
The business benefits are going to have staying power as a why-driver in your business for far longer than any technical driver. Because of the longevity of these motivations, it makes sense to attribute extra time to evaluating and thinking about how they relate directly to your company. Crafting a great why around these benefits will provide a compelling story to drive and maintain motivation in stakeholders and staff for your migration.
Reduced Expenditures and Support
We have already covered the concept of pay as you go and purchasing your infrastructure at the low watermark, so we don’t want to dive into those waters any deeper (pun intended). However, these are not the only ways that AWS can help to reduce your costs relating to IT expenditures. When discussing the benefits of AWS regarding costs, I like to break them down into two buckets. In the first bucket, we have the hard costs associated with running your environment. These are the costs for equipment, software, services, power, fire suppression, and the like. They are very tangible and easy to measure. On the other side of the question, the second bucket contains the soft costs associated with your estate. These costs, such as staff time for patching, racking equipment, performing backups, and others, are tough to measure. These soft costs are the parasite attached to your IT budget that sucks the life out of it. These costs, if saved, would provide your company with more IT funding for innovation and delivering value to your customers.
Hard costs
I just said that hard costs are easy to measure, but now I’m going to qualify that heavily. They are easy to measure if you measure them. When you talk about hardware like servers and switches, I am sure that you have an accurate measure. You purchased them, they are on your books as a depreciating asset, and you can probably tell me exactly how much that costs you. Once you step beyond hardware, things might get a bit trickier. For instance, if you do not have a colocated or dedicated off-site data center, accounting for individual costs becomes difficult. I have detailed two examples here that show just how drastic the difference in cost allocation can be.
Andrea has a pretty easy job. Everything that Andrea needs to run a data center is sold to her with a cute little bow on top. She knows exactly what all these items cost her, and she does not have to worry about accounting for them. AWS does not offer any simplification to Andrea in terms of how she accounts for costs. The cost of running her systems in AWS will also be delivered in one bill with a nice bow on it. Andrea might have some unused capacity in her rack if it is not chock-full of equipment. She may benefit from AWS because she would not have to pay for that extra capacity. When comparing the cost-benefit to AWS, Andrea will have an easy time performing the analysis.
Believe it or not, I run into Jim’s situation all the time. Many companies have no idea what the actual costs are to run their infrastructure. Like Jim, things just grew organically on-premises, and there was no real separation from an accounting perspective. It will be difficult for Jim to make a cost comparison between on-premises expenses and AWS. Since his costs are not attributed directly, Jim will have to make some assumptions. He can base them on the square footage of these data centers or use an industry standard as a baseline. AWS can help in this area by using the total cost of ownership (TCO) tool available online. I have found that the estimates AWS provides are not viewed favorably by some management. They feel it is more marketing material than qualitative data, and would prefer data from an unbiased third party. If you would like to build your estimations by hand, you can use the AWS Pricing Calculator.
Note
The AWS Pricing Calculator does not support costing on all AWS services, but its capabilities continue to grow over time.
The economy of scale that AWS offers businesses in hard costs is a substantial benefit. It has more servers than any one company could have. It uses specialized equipment and can drive down acquisition and operational costs. These savings are then transferred to its customers. Even the largest companies in the world, ones with large-scale infrastructures themselves, choose to migrate to AWS and shut down their data centers. The reason is quite simple: they are not in the data center business. Their business is offering some other service or product to their customers. Since data centers are not their business, they cannot have the scale of AWS and thus the cost savings. If these massive companies cannot do it as effectively as AWS, imagine what migration can do for your company.
Soft costs
One of the most exciting benefits of AWS is related to soft costs. When you migrate to AWS, there are a lot of services available to help reduce the soft costs of operating your environment. In addition to eliminating the costs, the services can also help to reduce risk. One of the best services for reducing soft costs postmigration is RDS, a managed database service. This management means that AWS handles patching of the operating system, backup of the databases, and patching the database engine. This automation eliminates much of the effort needed from your staff to perform these functions. Many hours a year of staff time would be dedicated to installing the patches and checking to ensure that backups were occurring. Operations like these are a time suck and provide no value to customers. Customers want their data backed up, but they do not care how it happens, nor are they willing to pay for it. They see it as unavoidable and part of your problem, not theirs. Customers are looking for product capabilities, updates, and bugs fixed. AWS helps you with these non-value-adding functions, like database patching, and frees up the time for your staff to work on those value-adding items that customers want.
This form of soft cost savings is prevalent throughout the platform. If you think about all the items required to run a data center, you will start to see these savings. For instance, running a data center involves battery backup systems. These systems need maintenance and testing. If you run your own data center, these tasks fall on your shoulders to complete. Depending on your risk profile, you could be testing your backup systems every year, quarter, or month. Again, this provides no value to your customers besides them expecting your systems to be online when they need them. You can take this a layer deeper and think about the time required to negotiate contracts for your communications lines and HVAC support contracts. All these items consume your time and effort, and the real cost of this time is tough to quantify. When I think back to my data centers and the time required to manage them, I would have preferred to outsource all of that and worry about running my software. If you are using a colocation data center, many of these are already outsourced for you, and you don’t have to worry about them.
If we take one step above the operational requirements for a data center and start looking at things like network and hypervisors, you’ll see a trend where AWS can save you even more time. For instance, in AWS, you do not need to worry about managing the hypervisor. Patching your VMware environment or Microsoft Hyper-V becomes outdated. The hypervisor is part of the EC2 product you do not have to think about anymore. You consume the EC2 instances. AWS worries about the underlying hardware and operating system and patching. The same holds for elastic load balancing. In your on-premises environment, you would have to patch your load balancer and maintain all security and updating of the hardware when it expires. The same holds for your storage subsystem, because AWS manages the storage subsystem for you. You consume the elastic block store (EBS) volumes. You do not have to worry about managing how much disk capacity is available, how much storage will be needed, or how much maintenance contracts cost.
Note
Reduction of soft costs can easily surpass hard cost savings. Employee salaries are most likely your company’s greatest expenditure. Now this doesn’t meant that you should be handing out pink slips like candy at Halloween, but it does mean that your staff will have more time to add business value.
The last major component we will cover that reduces operations soft costs is the firewall. Firewalls are another critical network communication device that you must manage, patch, and update. By using AWS Security Groups, you eliminate a significant amount of soft costs related to maintaining your environment. In addition, AWS has a networking service called Network ACLs that offers a second layer of security by implementing a Layer 3 firewall.
I could go on about all the capabilities AWS has that can save you these costs. I wanted to highlight a few of the important ones to get you thinking about other areas where your employees use a lot of their time to do mundane tasks—tasks that you can outsource and have managed by somebody else. Your product or service is what your company does best; it is what makes it unique. That is why you are in business. I will repeat that multiple times throughout the book. It is an essential concept, one I want ingrained in your being. It will help you with detractors later. Some staff will be reluctant to make changes, and fearful of obsolescence and additional workload. You will be able to show how their working life will improve by working on more interesting duties that will lessen their reluctance to move forward. I like to say it like this: nobody went to college or training classes to learn to perform monotonous tasks. They learned for another reason—to build a product, to create magnificent databases, or to make good money. I assure you, none of them were dreaming about work a robot could do.
There are many more services available in AWS to help reduce your workload on soft cost tasks that we will not review. There are tools to back up your data, there are tools to apply patches, and there are even tools to manage licenses. When used together, they are a formidable weapon against wasted time and effort. You will have to determine where your company has significant waste in operational tasks and determine whether there is a service or capability that will help to lessen it. Table 1-3 is a list of some additional services that could lessen your soft cost postmigration.
Warning
Do not use soft costs in your business justification unless you can absolutely quantify them. Failure to do so could lead to them being thrown out and possibly jeopardizing your migration. I have seen managers get into sticky situations where upper management thought they were pushing an agenda by providing “fluff” numbers.
No Commitment
When you are building on-premises, it is a lot like buying a new car. You put much effort into the evaluation to make sure it is a good fit. You will be together for the next three to five years, and you’d better make the best of it. It is the second-largest expense you will have after your house. It is a significant commitment that has a major impact on your life. Like with your car, the commitment is what makes businesses apprehensive about trying new things. It is a lot scarier to fail fast when failing costs hard dollars that are hard to recoup. Let’s face it—computer hardware depreciates faster than your last car. A car will at least bottom out somewhere along the curve because it still performs the function of driving from A to B. Not the case with computer hardware; the value can continue to travel right down to zero because the software designed to run on it can no longer run. This depreciation leads to much fear of failing fast. Failing fast means that hardware you buy today might not work as expected with the concept you were testing, and now you have this hardware sitting around collecting dust. Do this a few times, and you have tens or hundreds or thousands of pieces of equipment lying around. What happens? You do not fail fast. You do not want to fail at all, so you do not innovate, and your company gets its lunch handed to it by a startup.
Do not tell my wife of 17 years this, but commitment is bad. At least when it comes to IT. AWS does not have any commitments. You can spin up a server, or test out a business concept or product enhancement. If it does not work out, destroy it and stop paying. Now your ability to test and fail takes a much smaller bite out of your budget. Failing fast means that you spend insignificant amounts of money multiple times until you find something that works and delivers on the product or feature that your customers want. It is like a fresh new product you see on the web that you want to try, but you are afraid it might not deliver on its promises. However, then you see that there is a money-back guarantee if you are not satisfied. Now your fear of failure is gone, so you move forward with your purchase. The no-commitment aspect of AWS is the same warm safety blanket you like to wrap yourself in before trying that new product.
One of the benefits you can take advantage of is around employee testing. Throughout my career, I have had many staff members that loved to tinker and try things out. I see this as an excellent business advantage. People can solve problems in ways never expected or thought of through experimentation. However, it would be best if you put some guardrails around experimentation. You must make sure your data is secure and your costs do not get out of hand. In AWS, you can set up a sandbox account that allows your staff to try new things, learn, and experiment in a controlled manner. You can set spending limits and alarms for this account to keep costs low. From a security aspect, you can prevent access to production data to limit data leakage.
Furthermore, you can run automated cleanup scripts to purge deployed infrastructure to keep costs low and shadow IT to a minimum. All these items provide a safe place where your staff can help you deliver better value to your customers while challenging themselves and staying mentally engaged with their work. It is a win–win all around.
Business Agility
Another business benefit you can leverage when you migrate is business agility, which is exceptionally critical for long-term survival. If you look at the companies that have struggled and failed recently—Sears, Kodak, Toys R Us, and Blockbuster, to name a few—their inability to adapt and change is what sped up their demise. The bottom line is that business agility translates into increased competitiveness, increased ability to adapt to changing market conditions, and increased revenue.
Tip
Agility is the number one benefit of migration. Make sure that you address this in your why FAQ.
I’ve noticed that in all the companies I have helped migrate to AWS, gaining business agility was the most challenging benefit to achieve, yet the most fruitful. It is difficult because there are many people involved—usually different departments, and different teams within departments. They need to cooperate as a cohesive whole to reap the benefits of agility. These teams are traditionally very siloed in a company. Unfortunately, when working with people and these silos, change does not come quickly. Many times, the reluctance to change leads to considerable roadblocks. One reason I find it vital to come up with the why narratives is that it will help move the process along and drive synergies between the silos.
If you were to go back about five years, you would not hear the words business agility mentioned within the context of IT. IT was there to provide the technology services the business required. Typically, you had long cycles for development using waterfall design methodologies, or you were running commercial off-the-shelf software. However, things have changed in recent years. The combination of Agile software development methodology and automated deployment pipelines has changed how the business looks at IT. It is not unheard of today for companies to release ten production updates every day. When you compare that to your on-premises system, you will see the dramatic difference these tools facilitate. AWS has created a suite of products for the automation of the building and deployment of infrastructure and software. However, these services on their own are not especially useful. For instance, AWS CodePipeline allows you to automate the building and deployment of software. Unfortunately, if the software cannot be automatically installed and requires user intervention, an automated deployment pipeline is not extremely useful.
Put another way, agility is the combination of tooling and people process. Unfortunately, as an IT manager, the responsibility will fall to you to address this disconnect. IT will be the central point of contact between all the other teams, divisions, and business units within an organization. This centralization gives the IT manager a unique perspective to create a uniform mode of operation across the entire company. Let’s dive into the following scenario, which shows how agility can affect a company.
I have seen some exceptionally large and successful companies in a comparable situation to Judy’s. They created their internal tooling long before the current wave of technologies. Their competition is newer and was built in a cloud-native state, which gives them several advantages. In Judy’s case, the competitor is using analytics and AI and can push out updates at least weekly. For her company to compete on a level playing field, it will have to implement quite a few changes:
-
Implement a continuous integration and continuous development (CI/CD) pipeline
-
Regression-test two years of changes before updating the production environment
-
Train staff and customers on the two years of changes
Once the update is pushed out to production, they can think about switching to an agile development methodology. All the while, Judy will need to ensure that the mentoring, training, and motivation of the staff is in place to ensure the successful outcome.
Disaster Recovery/Business Continuity
When I started my career, DR was not thought about by many companies. For many years, the extent of my DR plans was a tape backup that was stored in a fireproof safe. The term proof should not have even been used–it was more of a fire delay and did not guarantee that the temperature of the fire would not melt my tapes. As the years progressed, so did the importance of DR. IT moved from just running an accounting system to become a critical part of the business. Today, IT might be your business, and without it, you won’t be in business long. DR is a large part of your current budget and a critical part of your processes.
When companies migrate to AWS, they should try to move the focus from DR to BC. Business continuity is more concerned with operations continuing than recovering from a complete failure. I am sure you will agree with me that continuity is better than recovery. Who wants to recover when it is so much easier to continue? With the capabilities of the AWS infrastructure behind you, it is easier to create a BC plan that can meet your required objectives. Those objectives are the recovery point objective (RPO) and recovery time objective (RTO). To help remember these concepts, I always think about the RPO objective as the sell-by date on my milk. How old can it (the data) get before it is of no use to me? I remember the RTO as how long I take to get to the store to get more milk, or how long I can be offline.
Using AWS AZs in your design allows you to meet near-zero RTO and near-zero RPO by deploying your applications in an active/active or active/passive configuration. Active/active means that your applications are running on at least two servers at the same time. You could do this with a load balancer in front of the servers. Active/passive is similar, but one of the servers is replying to requests at any given time. In case of a failure in an active/passive deployment, the second server takes over for the primary. Congratulations, you now have a near-zero RPO/RTO BC design in AWS. This design will allow you to survive the failure of one AZ and continue operations without interruption. The question you must ask yourself is whether this is enough protection for your business. What if an entire region goes down? If you ask that question and the answer is, That is unacceptable, then there is more BC/DR work to be done.
Using the benefits of AWS regions, you can expand your infrastructure to account for an entire region failure. However, depending on your implementation and your requirements, there can be a significant difference in cost, depending on your implementation. You will need to decide whether your company wants cross-region DR or BC. Cross-region DR is less expensive but has a much higher RTO and RPO, whereas cross-region BC costs more because there must be more active infrastructure running to accommodate the lower RTO/RPO. Let us walk through two scenarios to show how your DR/BC might look after migrating to AWS.
Meeting the district requirements will not be a difficult task to achieve, given the capabilities of AWS. Since there is such a high RTO and RPO, it makes little sense to deploy BC and continue with a DR strategy. Kevin will be able to snapshot (take a copy of the data at the block level) the servers using an automated system called Data Lifecycle Manager (DLM). DLM supports an RPO as low as 2 hours, which is better than the requirement of 168 hours. Since Kevin only has 12 servers, it would not be that hard for him to manually redeploy instances to another AZ within the required RTO of 24 hours. If an AZ failed, Kevin could start up new servers and attach the latest snapshots to them in about six hours, leaving plenty of time to spare. It would be best if Kevin deployed his 12 servers in three AZs. This configuration ensures that only 4 servers could go down at a time instead of 12. Deploying in this configuration would save him four more hours in redeploying instances.
Amelia should look at changing from a DR to a BC thought process. She has enough systems with high business criticality to call for it. By using some of the benefits of AWS, Amelia can deploy her applications to three AZs and use load balancing and auto-scaling to provide availability. By moving her database backend to Amazon RDS, she can benefit from active/passive database availability. With this configuration, Amelia will reduce her RTO/RPO to virtually instantaneous. To add another layer of protection, she can implement DLM with four-hour snapshots and replicate them to another region for DR capability. She can restore her servers if an entire region goes down for an extended period.
BC is not a concept you associate with cost savings, but with AWS and the regions with three AZs, you can cut 25% of your costs while still providing the same level of availability. It depends on the capabilities of your application, but if your applications can support it, you can save a considerable amount. This savings is another benefit of AWS regarding BC.
Jimmy will save some money moving his application to AWS. Let us say that Jimmy’s production server costs $100 a month to run. To meet his availability and BC requirements, Jimmy has a second server in another data center. This server also costs $100 a month to have online to receive database updates and be prepared to serve traffic. Jimmy is paying 200% for his application: 100% to serve the application, and 100% to be available for failover. Since Jimmy is in the United States, he has at least three AZs available to him. When he migrates his servers, he can use auto-scaling and a load balancer to change his application to an active/active cluster instead. In this configuration, Jimmy can deploy three servers that serve 50% of the load, meaning that he will pay $50 a month for each server, bringing his total to $150 instead of $200. In this configuration, Jimmy can have one server or AZ fail and still be able to serve all of his load, even while saving 25% of his ongoing costs.
Decreased Vendor Lock-in
Whenever I hear the words vendor lock-in regarding migrating to AWS, I have to scratch my head. If anything, migrating to AWS opens more options rather than restricting them. When you built out your infrastructure on-premises, you accepted a lot of vendor lock-in. You could change your storage area network (SAN) vendor or server hardware vendor, but you would do that when you had to refresh hardware. When you bought that hardware, you were locked into it for three to five years. It was not like you could buy a SAN from Dell EMC and then a year later buy disk capacity from Hewlett-Packard to expand it. It just does not work that way, and the same goes for your hypervisor. Sure, you can change from VMware to Hyper-V, but the level of effort to accomplish that is high.
When you migrate to AWS, you exchange your hardware for bits and bytes. If you were to upload my server to AWS and have it run there, you could take that server the next day and move it to Azure. By moving to the cloud, you cut the strings to your hardware. There are some costs for outbound data from the cloud providers generating a small cost to move, but those movement costs exist everywhere, even on-premises, so I consider them moot. Converting your systems to purely data makes them more mobile than ever before. Running instances in AWS offers you more mobility benefits than you could ever have on-premises; it all ties back to the pay-as-you-go model and the lack of commitments.
Real vendor lock-in comes into play when you use proprietary services that are only offered by one vendor. I have heard many managers state that they only want to use services available in all the clouds so they have mobility and can change vendors. This mentality does not bode well for your career long-term. Keeping your infrastructure in lockstep with the lowest common denominator ensures that you will never have a competitive advantage in your marketplace. Your competition will move forward with adopting lock-in technologies to add value to their businesses. It is like buying a Corvette and then never leaving first gear. Some amount of lock-in is unavoidable, and when a lock-in situation arises, it is important to ask yourself whether it is good for your business.
Change to Operational Expenditures
A benefit of migrating to AWS and adopting a pay-as-you-go model is that you switch from a capital expenditure to an operating expenditure. On the surface, it is not immediately visible why this is a benefit, and some see it as a negative. If you purchased a server on-premises and depreciate it, meaning to expense the wear and tear of the asset over several years, you end up with a fixed monthly expense for that hardware. After migration, you exchange this form of accounting for a variable operating cost. This change does not seem like a good thing from an accounting perspective; you are going from a fixed monthly expense to a variable expense. Many people prefer a fixed, known variable for expenses, and the addition of a variable expense makes them uneasy.
Even though the expense is variable, I still see it as a benefit over on-premises. To have the benefit of a fixed monthly server expense, you must buy it. The purchase of hardware means that you are drawing down on your cash account, which you then create an asset account for in my accounting system. Once you have the asset account set up, you can divide the total cost of the server by the number of months you plan to keep it. Many companies use 36 months or 3 years as their depreciation schedule. You have to draw down your cash account. That money is gone, and it is not available to do other things like pay staff or buy more advertising. This is not the case in AWS—you do not have that drawdown, and your cash is still available to drive the business forward.
You still may be asking about the variable cost and its unpredictability. I see this as a benefit. It is not always the easiest construct to understand how it is a benefit, so let’s look at the following scenario to get a better understanding.
To explain how Duke’s situation and variable cost is a benefit, let’s break down some numbers. Duke’s platform is running in a steady state with no users at around $850 a month. This cost translates into Duke’s fixed cost for his product. No matter how many users are on the platform, it will cost around $850 a month to produce the product for them to consume. The variable cost is the per-user cost of $0.55. The sum of the variable cost goes up for every user added linearly. Now for the best part: since the cost is based on consumption—the users—the revenue scales linearly as well. These numbers help Duke’s company create predictions about how much it will cost and how much they will make. It will not tell them anything about their market penetration, or how many users did not like the application and canceled the service. However, Duke’s CFO will feel a lot more comfortable with a variable cost knowing that it is tied to their user base. If you were to compare this scenario to Duke running his application on-premises, he would have to buy a large amount of hardware for his expected demand. The cost would be fixed, but it would also be more costly and fixed, even if the company only obtained ten thousand users at launch instead of one hundred thousand.
If you want more predictability in your bill and have a relatively static consumption, you can purchase AWS reserved instances. A reserved instance is a prepaid EC2 instance rather than the pay-as-you-go model and offers you a discounted price. You pay for a reserved instance up front and then amortize the cost over the year. It forms a function remarkably similar to deprecation because you pay up front and then expense back 1/12th of that cost every month. AWS also offers three-year reserved instances, but I frown on those for many reasons I will get to in “Run Rate Modeling”.
Note
Sometimes the pay-as-you-go model does not work for everyone; it limits some capabilities for small and medium businesses to speed up deprecation. Your accountant might want to reduce your tax burden, using IRS Section 179. Before migrating, it will be essential to talk to your account or CFO and determine the right course of action in these circumstances and how to address the issue.
Converting Your Why into an FAQ
In this chapter, we have covered much ground regarding how, with a little change, you can reap a significant number of technical and business benefits by migrating to AWS. I hope that as you read the various scenarios explaining some of these changes, you were able to reflect on your personal experience and draw similarities. You should have a good baseline to build out your FAQ for migrating to AWS, using your notes as a guide.
Why are we building out an FAQ for migration? Well, people will ask questions; it is a given. I like to build out an FAQ ahead of time with answers to questions I feel people are most likely to ask. For one, it shows you have spent much time looking at the project through their eyes. This connection gives them the sense that you feel their pain and understand their viewpoint. Empathy will gain you support quickly. The fact is that, by doing this exercise, you will understand their perspective! The next thing the FAQ does is get the general concerns off the table right away and allow you to get to work faster. I am sure that you do not want to be in more meetings discussing the same detractions repeatedly. As you work and communicate with teams, you may find that you did not capture all the thoughts and ideas that people have. That is OK. It is all part of the process. It will be important to capture their questions and answer those questions as well. The chances are high that someone else in your organization will ask it again.
How to Build the FAQ
The first step to building out your FAQ is to decide on the audience. This audience may be management, a development team, your staff, or a business unit. You will go through this exercise multiple times using a different audience to flush out your FAQ. For the purpose of this exercise, we will use upper management. Now that we have our audience, you need to put yourself in their shoes and think of questions or objections that they might have about migrating to AWS. Let’s step through two questions that you might get from upper management and think about how we would craft a response based on the knowledge we have gained from this chapter.
How much more is AWS going to cost us?
CIO
You can bet you will get asked this question, and it is a very fair question. The problem with this question is that they have a predisposed attitude to think AWS will be more instead of less. It would be an excellent idea to rewrite this question in a more neutral stance. You want people to decide on their own and not be influenced either way by the questions in your FAQ. “How will our infrastructure costs change after migration?” would be a better way to phrase this question.
To answer this question, it would be important to focus on the high- and low-watermark buying aspects of your infrastructure. For added support, you can also include any applications that can save costs through an updated BC model and save 25% of those costs. It is important to draw vision from your company’s inner workings as much as possible to personalize it and make it real for them.
How will this migration affect our staff and operational expenses?
CFO
This is another very common question that comes from upper management. It’s trickier to answer. Technically, your operational costs will go up from an accounting perspective because of the shift from a capex to an opex model for your infrastructure. It might be an excellent idea to separate that into another question and answer for the FAQ. Then you can reword this question into “How will this migration affect our staff’s productivity?” Now you can answer this question with all the soft-cost savings that you have thought about earlier.
The next step in the process is to continue iterating to all the teams and departments your migration to AWS will affect. It will be a time-consuming process, but it will help overall by reducing the friction to change. As you go through more teams, the number of net new questions will decrease because many of the groups will have the same concerns. The viewpoints and motivations for their questions will change depending on their position. Based on this different viewpoint, you might not add another item to the FAQ but add more to the answer to address the additional concern instead.
Wrapping It Up
We covered much ground in this chapter, reviewing the technology and business benefits of migrating to AWS. The fact of the matter is that we just scratched the surface, and there are many more ways to benefit from migration. Again, these are the benefits that universally apply to anyone migrating and were the most important to cover. Every company that I have migrated to the cloud has leveraged AWS to benefit its unique aspect and scenario. AWS could be looked at as the largest Erector Set in the world. It allows you to build a Shannon number of possible solutions.
Note
Claude Shannon was a mathematician who theorized the lower bound of the game tree complexity in chess, which results in about 10120 possible unique games. This number is known as the Shannon number.
By now, you should have a solid understanding of how your company can uniquely leverage the benefits of AWS by relating the scenarios and explanations to your experience. You should have a solid FAQ built that helps to address users’ concerns and move the conversation forward. Lastly, you might have some ideas for what the future holds for additional benefits postmigration.
1 Simon Sinek, Start with Why: How Great Leaders Inspire Everyone to Take Action (New York: Porfolio, 2011).
Get Migrating to AWS: A Manager's Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

