Chapter 6. Tools for Making the Data Lake Platform
Now that you’ve got the frame of a data lake house, it’s time to think about the tools that you need to build up the data lake platform in the cloud. These tools—in various combinations—can be used with your cloud-based data lake. And certain platforms, like Qubole, allow you to use these tools at will depending on the skills of your team and your particular use cases.
The Six-Step Model for Operationalizing a Cloud-Native Data Lake
Figure 6-1 illustrates a step-by-step model for operationalizing the data in your cloud-native data lake platform. In the subsections that follow, we discuss each step and the tools involved.
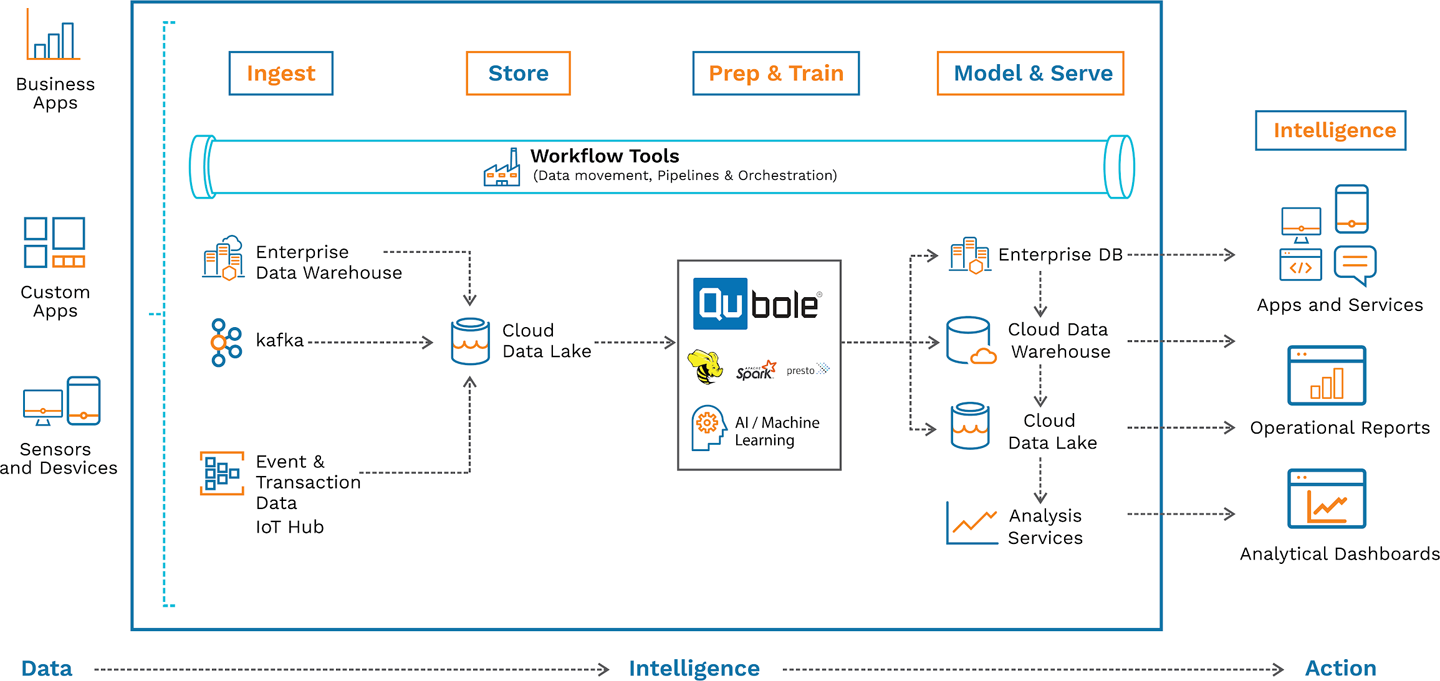
Figure 6-1. The six-step model for operationalizing data
Step 1: Ingest Data
As Chapter 5 discusses, you have various sources of data: applications, transactional systems, and emails, as well as a plethora of streaming data from sensors and the IoT, logs and clickstream data, and third-party information. Let’s focus on streaming data. Why is it so important?
First, it provides the data for the services that depend on the data lake. Data must of course arrive on time and go where it needs to go for these services to work. Second, it can be used to quickly get value from data, whereas batch processing would take too long. Recommendation engines that improve the user experience, network anomaly detection, and ...
Get Operationalizing the Data Lake now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

