Chapter 3. Text Representation
In language processing, the vectors x are derived from textual data, in order to reflect various linguistic properties of the text.
Yoav Goldberg
Feature extraction is an important step for any machine learning problem. No matter how good a modeling algorithm you use, if you feed in poor features, you will get poor results. In computer science, this is often called “garbage in, garbage out.” In the previous two chapters, we saw an overview of NLP, the different tasks and challenges involved, and what a typical NLP pipeline looks like. In this chapter, we’ll address the question: how do we go about doing feature engineering for text data? In other words, how do we transform a given text into numerical form so that it can be fed into NLP and ML algorithms? In NLP parlance, this conversion of raw text to a suitable numerical form is called text representation. In this chapter, we’ll take a look at the different methods for text representation, or representing text as a numeric vector. With respect to the larger picture for any NLP problem, the scope of this chapter is depicted by the dotted box in Figure 3-1.
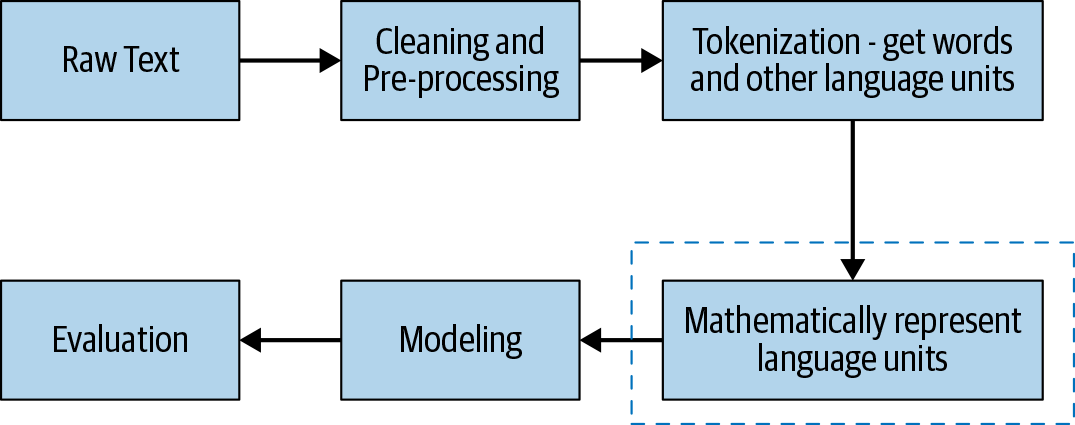
Figure 3-1. Scope of this chapter within the NLP pipeline
Feature representation is a common step in any ML project, whether the data is text, images, videos, or speech. However, feature representation for text is often much more involved as ...
Get Practical Natural Language Processing now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

