June 2012
Beginner to intermediate
260 pages
6h 28m
English
This chapter introduces several clustering methods and shows how to use them for clustering images for finding groups of similar images. Clustering can be used for recognition, for dividing data sets of images, and for organization and navigation. We also look at using clustering for visualizing similarity between images.
K-means is a very simple clustering algorithm that tries to partition the input data in k clusters. K-means works by iteratively refining an initial estimate of class centroids as follows:
Initialize centroids μi, i = 1 . . . k, randomly or with some guess.
Assign each data point to the class ci of its nearest centroid.
Update the centroids as the average of all data points assigned to that class.
Repeat 2 and 3 until convergence.
K-means tries to minimize the total within-class variance
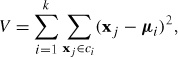
where xj are the data vectors. The algorithm above is a heuristic refinement algorithm that works fine for most cases, but it does not guarantee that the best solution is found. To avoid the effects of choosing a bad centroid initialization, the algorithm is often run several times with different initialization centroids. Then the solution with lowest variance V is selected.
The main drawback of this algorithm is that the number of clusters needs to be decided beforehand, and an inappropriate choice will give poor clustering results. The ...