Chapter 4. Just Enough RDF
Now that you have an understanding of semantics and of how you might build a simple triplestore on your preferred platform, we’re going to introduce you to the world of data formats and semantic standards. At this point, you may have a few unanswered questions after reading the previous chapter:
How do I know which predicates (verbs) to use?
How do I know whether a value in my data refers to a floating-point number or a string representing the number?
Why is “San Francisco, CA” represented as
San_Francisco_Californiaand not something else?How will other people know what representations I used?
Are comma-separated triples really the best way to store and share data?
These questions are concerned with maintaining and sharing a large set of semantic data. In this chapter, we’ll introduce the following few concepts to help solve these problems:
URIs and strong keys, so you can be sure you’re talking about the same thing as someone else
RDF serializations, which have parsers for every popular language and are the standard way to represent and share semantic data
The SPARQL language, the standard way of querying semantic data
The use of semantic web formats goes far beyond what we can cover here, so consider these concepts as the highlights—the pieces you really need in order to get started building semantic applications.
What Is RDF?
Hopefully, by this point you’ve seen that structuring data into graphs is easy, and a good idea as well. But now that you’ve got your data loaded into a graph, how do you share it and make it available to other people? This is where the W3C’s Resource Description Framework (RDF) comes into play. RDF provides a standard way of expressing graphs of data and sharing them with other people and, perhaps more importantly, with machines. Because it is a W3C “Recommendation” (an industry standard by any other measure), a large collection of tools and services has emerged around RDF. This chapter introduces just enough of the RDF standards to allow you to take advantage of these tools while avoiding much of the complexity. We’ll be using the Python RDFLib library, but much like the variations in DOM APIs, you should be able to use what you learn in this chapter with any RDF API, as the principles remain the same across libraries.
The history of RDF goes back to 1990, when Tim Berners-Lee wrote a proposal that led to the development of the World Wide Web. In the original proposal, there were different types of links between documents, which made the hypertext easier for computers to comprehend automatically. Typed links were not included in the first HTML spec, but the ideas resurfaced in the Meta Content Framework (MCF), a system for describing metadata and organizing the Web that was developed by Ramanathan Guha while he was at Apple and Netscape in the late 1990s, with an XML representation developed with Tim Bray. The W3C was looking for a generic metadata representation, and many of the ideas in MCF found their way into the first RDF W3C Recommendation in 1999. Since then, the standards have been revised, and today’s software and tools reflect these improvements.
The RDF Data Model
RDF is a language for expressing data models using statements expressed as triples. Just as we’ve seen in previous chapters, each statement is composed of a subject, a predicate, and an object. RDF adds several important concepts that make these models much more precise and robust. These additions play an important role in removing ambiguity when transmitting semantic data between machines that may have no other knowledge of one another.
URIs As Strong Keys
You may recall from Chapter 1 that when we wanted to join multiple tables of relational data together, we needed to find a shared identifier between the two tables that allowed us to map the tables together. These shared identifiers are called keys and form the basis for joining relational data.
Similarly, in a graph data structure, we need to assign unique
identifiers to each of the nodes so that we can refer to them
consistently across all the triples that describe their relationships.
Up to this point, we have been using strings to label the nodes in our
graphs, and we have been careful to use unique names whenever there was
a chance of overlap. For instance, we used a clever naming convention to
disambiguate different places with the same name in the
places_triples dataset, in order that IDs such as
San_Francisco_California versus
San_Francisco_Chile would be distinct.
But for larger applications and when we are coordinating multiple
datasets, it can become increasingly difficult to guarantee unique and
consistent identifiers for each node. An example of this would be if we
tried to merge a database of old classic films with our film database
from Chapter 2. The classic film database
would likely have an entry for Harrison Ford, the handsome star of
silent classics such as Oh, Lady, Lady. If the ID
for this actor was harrison_ford, then when we merged
the two databases, we might sadly discover that the actor who played Han
Solo and Indiana Jones was killed as the result of a car accident in
1957.
Resources
To avoid these types of ambiguities, RDF conceptualizes anything (and everything) in the universe as a resource. A resource is simply anything that can be identified with a Universal Resource Identifier (URI). And by design, anything we can talk about can be assigned a URI. You are probably most familiar with URLs (Universal Resource Locators), or the strings used to specify how web pages (among other things) are retrieved. URLs are a subset of URIs that identify where digital information can be retrieved. While URLs tell you where to find specific information, they also provide a unique identifier for the information. URIs generalize this concept further by saying that anything, whether you can retrieve it electronically or not, can be uniquely identified in a similar way. See Figure 4-1.
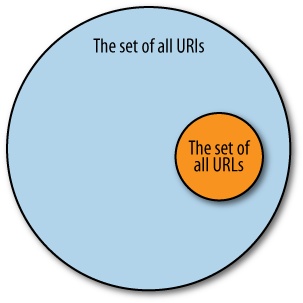
Since URIs can identify anything as a resource, the subject of an RDF statement can be a resource, the object in an RDF statement can be a resource, and predicates in RDF statements are always resources. The URI for a resource represented in an RDF statement is called the URI reference (abbreviated URIref) for that graph node. The subtlety of using the phrase “URI reference” is easy to miss. That is, the node in the graph isn’t the thing the URI identifies; rather, the URI is the identifier for something that is itself being represented as a node in a graph. Thus we say the graph node has a reference, which is the thing identified by the URI.
URIs are a useful way of getting around the need for an omniscient data architect. By allowing distributed organizations to create names for the things they are interested in, we can avoid the problem of two groups choosing the same name for different entities. URIs are simply strings, composed of a scheme name followed by a colon, two slashes (://), and a scheme-specific identifier. The scheme identifies the protocol for the URI, while the scheme-specific identifier is used by the protocol of the scheme to uniquely identify the resource. Almost all the URIs we will encounter use the “http” or “https” scheme for identifying things. As we have experienced with URLs, the scheme-specific part of these identifiers typically takes the form of a hostname, an optional port identifier, and a hierarchical path. If organizations stick to creating identifiers using hostnames under their control, then there is no chance of two organizations constructing the same identifier for two different things. Similarly, organizations themselves can split up their own identifier creation efforts among different hostnames and/or different hierarchical paths, thus making distributed resource naming work at any scale.
Because URIs uniquely identify resources (things in the world), we consider them strong identifiers. There is no ambiguity about what they represent, and they always represent the same thing, regardless of the context we find them in.
It is important to note that URIs are not URLs (although every URL is a URI). Practically speaking, this means that you shouldn’t assume URIs will produce any information if you type the identifier into a web browser. That said, making digital information about the resource available at that address is considered good practice, as we will see in the section Linked Data.
It is common in RDF to shorten URIs by assigning a namespace to the base URI and writing only the distinctive
part of the identifier. For instance, rdf is
frequently used as a moniker for the base URI
http://www.w3.org/1999/02/22-rdf-syntax-ns#, allowing
predicates such as
http://www.w3.org/1999/02/22-rdf-syntax-ns#type to be
abbreviated as rdf:type.
Blank Nodes
You may have noticed that in our discussion about URIrefs and resources, we hedged our language and didn’t say, “All RDF subjects are resources.” That’s because you may find situations where you don’t know the URI of the thing you would like to reference or where there is no identifier available (and you are not in a good position to construct one). In either case, just because we don’t have a URI for the item doesn’t mean we can’t talk about it. For these situations, RDF provides “anonymous” or blank nodes.
Blank nodes are graph nodes that represent a subject (or object) for which we would like to make assertions, but have no way to address with a proper URI. For instance, as we will see in Chapter 5, many social network APIs don’t issue strong URIs for the members of their community, even though they have a good deal to say about them. Instead, the social network uses a blank node to represent the member, and the facts about that member are connected to the blank node. See Figure 4-2.
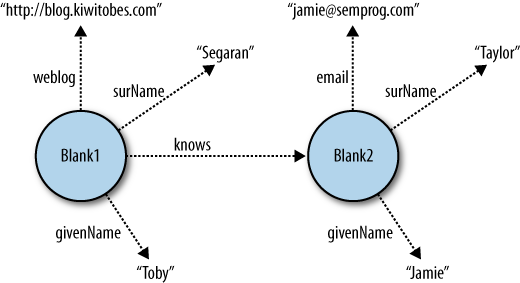
In triple representations, blank node IDs are written
_:id, where id is an arbitrary,
graph-specific local identifier. Most RDF APIs handle this by issuing an
internal ID for the node that is only valid in the local graph and can’t
be used as a strong key between graphs. Using our previous triple
expression format, we can write the graph in Figure 4-2 as:
(_:ax1, "weblog", "http://blog.kiwitobes.com") (_:ax1, "surName", "Segaran") (_:ax1, "givenName", "Toby") (_:ax1, "knows", _:zb7) (_:zb7, "surName", "Taylor") (_:zb7, "givenName", "Jamie") (_:zb7, "email", "jamie@semprog.com")
And though neither of the nodes has a strong external identifier, from the context of data connected to the nodes it is clear that the Toby Segaran who writes the Kiwitobes blog knows the Jamie Taylor with the email address jamie@semprog.com.
You may also find situations where it is useful to create a data model that uses a node in an RDF graph to simply group a set of statements together. For instance, while describing a building, it is often helpful to group together its street address, municipality, administrative region, and postal code as a unit that represents the building’s mailing address. To do this, we would need a graph node, which represents the abstract concept of the building’s address. While we could provide a URIref for this mailing address, we would almost never need to refer to this grouping node outside the context of the current graph. See Figure 4-3.
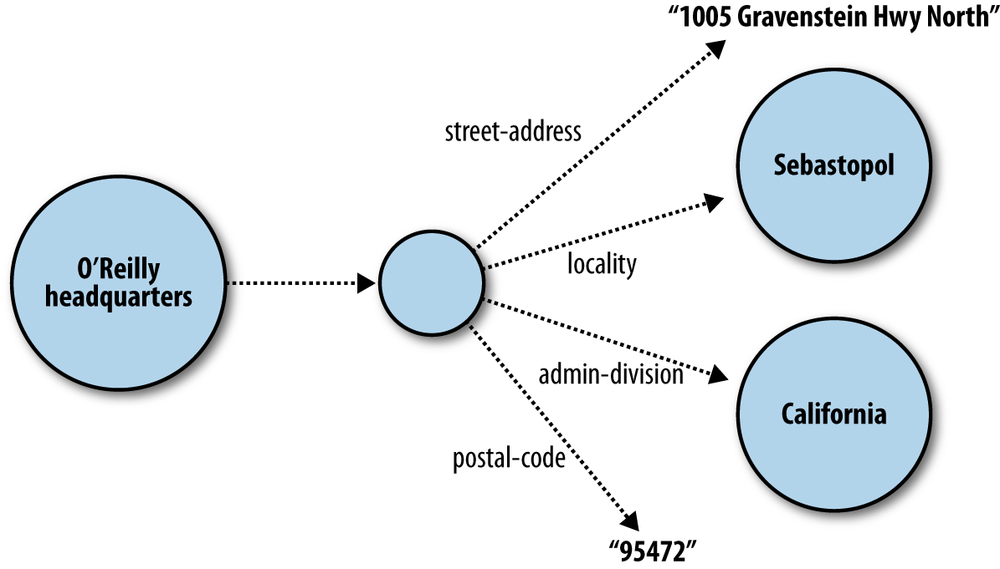
Literal Values
RDF uses literal values in the same way our earlier graph examples
did, to express names, dates, and other types of values about a
subject. In RDF, a literal value can optionally have a language
(e.g., English, Japanese) or a type (e.g., integer, boolean, string)
associated with it. Type URIs from the XML schema spec are commonly used
to indicate literal types; for example,
http://www.w3.org/2001/XMLSchema#int or
xsd:int for an integer value. ISO 639 codes are used
to specify the language; for example, en for English
or ja for Japanese.
RDF Serialization Formats
While the data model that RDF uses is very simple, the serialized representation tends to get complicated when an RDF graph is saved to a file or sent over a network because of the various methods used to compact the data while still leaving it readable. These compaction mechanisms generally take the form of shortcuts that identify multiple references to a graph node using a shared but complex structure.
The good news is that you really don’t have to worry about the complexities of the serialization formats, as there are open source RDF libraries for just about every modern programming language that handle them for you. (We believe the corollary is also true: if you are thinking about the serialization format and you aren’t in the business of writing an RDF library, then you should probably find a better library.) Because of this we won’t go into too much detail, but it is important to understand the basics so you can use the most appropriate format and debug the output.
We’ll be covering four serialization formats here: N-Triples, the simplest of notations; N3, a compaction of the N-Triple format; RDF/XML, one of the most frequently used serialization formats; and finally, “RDF in attributes” (known as RDFa), which can be embedded in other serialization formats such as XHTML.
Note
There are many books and online resources that cover these output formats in great detail. If you are interested in reading further about them, you can look at the complete RDF specification at http://www.w3.org/RDF/ or in the O’Reilly book Practical RDF by Shelley Powers.
A Graph of Friends
In order to compare the different serialization formats, let’s first build a simple graph that we can use throughout the examples to observe how the various serializations fold relationships together.
For this example graph, we’ll model a small part of Toby’s social sphere—in particular, how he knows the other authors of this book. In our graph we will not only include information about the people Toby knows, but we’ll also describe other relationships that can be used to uniquely identify Toby. This will include things like the home page of his blog, his email address, his interests, and any other names he might use.
These clues about Toby’s identity are important to help differentiate “our Toby” from the numerous other Tobys in the world. Human names are hardly unique, but by providing a collection of attributes about the person, hopefully we can pinpoint the individual of interest and obtain a strong identifier (URI) that we can use for future interaction.
As you might have discerned, the network of social relationships that people have with one another naturally lends itself to a graphical representation. So it is probably no surprise that machine-readable graphs of friends have coevolved with RDF, making social graphs one of the most widely available RDF datasets on the public Internet. Over time, the relationships expressed in these social graphs have settled into a collection of well-known predicates, forming a vocabulary of expression known as “Friend of a Friend” or simply FOAF.
Not surprisingly, the core FOAF vocabulary—the set of
predicates—has been adopted and extended to describe a number of common
“things” available on the Internet. For instance, FOAF provides a
predicate for identifying photographs that portray the subject of the
statement. While FOAF deals primarily with people, the formal definition
of FOAF states that the foaf:depiction predicate can
be used for graphics portraying any resource (or “thing”) in the
world.
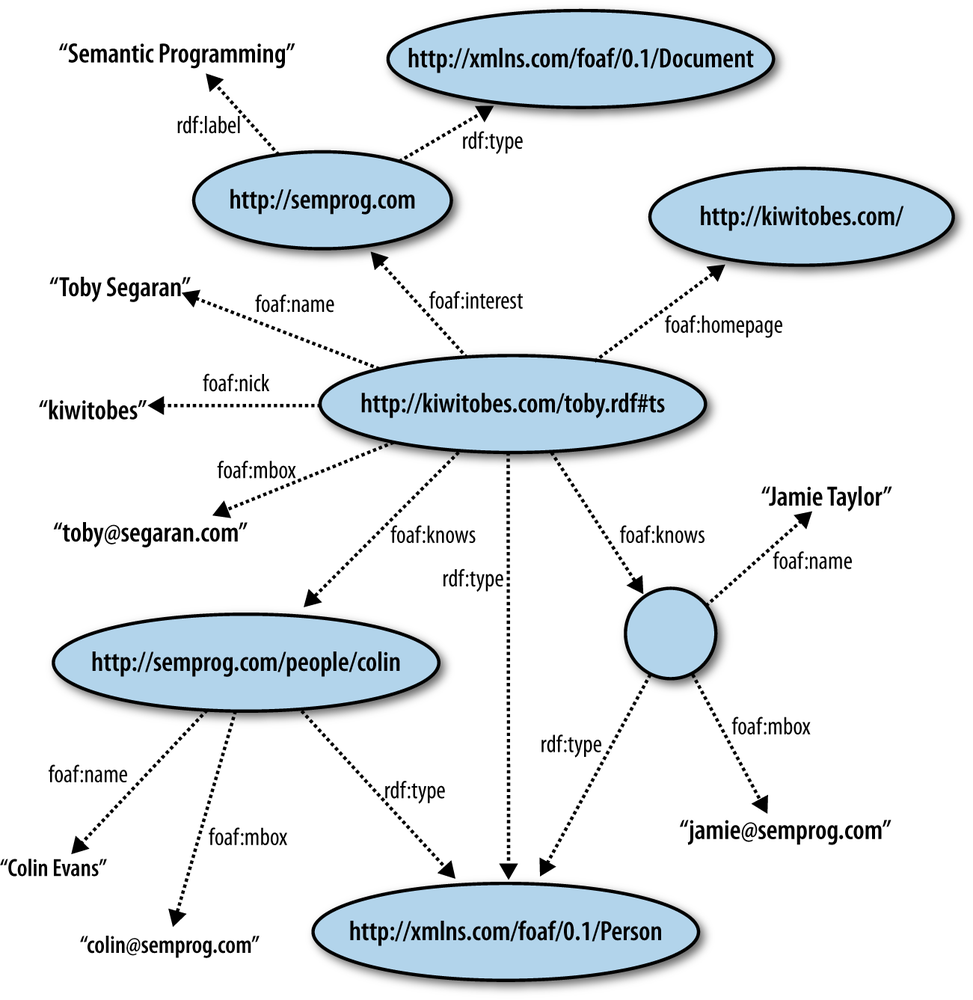
Figure 4-4 represents the small slice of Toby’s social world that we will concern ourselves with over the next few examples. With this graph in mind, let’s look at how this knowledge can be represented using different notations.
N-Triples
N-Triple notation is a very simple but verbose serialization, similar to what we have been using in our triple data files up to this point. Because of their simplicity, N-Triples were used by the W3C Core Working Group to unambiguously express various RDF test-case data models while developing the updated RDF specification. This simplicity also makes the N-Triple format useful when hand-crafting datasets for application testing and debugging.
Each line of output in N-Triple format represents a single
statement containing a subject,
predicate, and object followed by a dot. Except for blank nodes and
literals, subjects, predicates,
and objects are expressed as absolute URIs enclosed in angle brackets.
Subjects and objects representing anonymous nodes are represented as
_:name, where name is an
alphanumeric node name that starts with a letter. Object literals are
double-quoted strings that use the backslash to escape double-quotes,
tabs, newlines, and the backslash
character itself. String literals in N-Triple notation can optionally specify their language when
followed by @lang, where lang is
an ISO 639 language code. Literals
can also provide information about their datatype when followed by
^^type, where type is commonly an
XSD (XML Schema Definition) datatype.
The extension .nt is typically used when N-Triples are stored in a file, and
when they are transmitted over HTTP, the mime type
text/plain is used. The official N-Triple format is
documented at http://www.w3.org/TR/rdf-testcases/#ntriples.
Our FOAF graph (as shown in Figure 4-4) can be represented in N-Triple format as:
<http://kiwitobes.com/toby.rdf#ts> <http://xmlns.com/foaf/0.1/homepage>
<http://kiwitobes.com/>.
<http://kiwitobes.com/toby.rdf#ts> <http://xmlns.com/foaf/0.1/nick> "kiwitobes".
<http://kiwitobes.com/toby.rdf#ts> <http://xmlns.com/foaf/0.1/name> "Toby Segaran".
<http://kiwitobes.com/toby.rdf#ts> <http://xmlns.com/foaf/0.1/mbox>
<mailto:toby@segaran.com>.
<http://kiwitobes.com/toby.rdf#ts> <http://xmlns.com/foaf/0.1/interest>
<http://semprog.com>.
<http://kiwitobes.com/toby.rdf#ts> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://xmlns.com/foaf/0.1/Person>.
<http://kiwitobes.com/toby.rdf#ts> <http://xmlns.com/foaf/0.1/knows> _:jamie .
<http://kiwitobes.com/toby.rdf#ts> <http://xmlns.com/foaf/0.1/knows>
<http://semprog.com/people/colin>.
_:jamie <http://xmlns.com/foaf/0.1/name> "Jamie Taylor".
_:jamie <http://xmlns.com/foaf/0.1/mbox> <mailto:jamie@semprog.com>.
_:jamie <http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://xmlns.com/foaf/0.1/Person>.
<http://semprog.com/people/colin> <http://xmlns.com/foaf/0.1/name> "Colin Evans".
<http://semprog.com/people/colin> <http://xmlns.com/foaf/0.1/mbox>
<mailto:colin@semprog.com>.
<http://semprog.com/people/colin> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://xmlns.com/foaf/0.1/Person>.
<http://semprog.com> <http://www.w3.org/2000/01/rdf-schema#label>
"Semantic Programming".
<http://semprog.com> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://xmlns.com/foaf/0.1/Document>.N3
While N-Triples are conceptually very simple, you may have noticed a lot of repetition in the output. The redundant information takes additional time to transmit and parse. While it’s not a problem when working with small amounts of data, the additional information becomes a liability when working with large amounts of data. By adding a few additional structures, N3 condenses much of the repetition in the N-Triple format.
In an RDF graph, every connection between nodes represents a triple. Since each node may participate in a large number of relationships, we could significantly reduce the number of characters used in N-Triples if we used a short symbol to represent repeated nodes. We could go further, recognizing that many of the URIs used in a specific model frequently come from related URIs. In much the same way that XML provides a namespace mechanism for generating short Qualified Name (qnames) for nodes, N3 allows us to define a URI prefix and identify entity URIs relative to a set of prefixes declared at the beginning of the document. The statement:
@prefix semperp: <http://semprog.com/people/>.
allows us to shorten the absolute URI for Colin from
<http://semprog.com/people/colin> to
semperp:colin.
Since each node in an RDF graph is a potential subject about which
we may have many things to say, it is not uncommon to see the same
subject repeat many (many) times in N-Triple output. N3 reduces this
repetition by allowing you to combine multiple statements about the same
subject by using a semicolon (;) after the first
statement, so you only need to state the predicate and object for other
statements using the same subject. The following statement says that
Colin knows Toby and that Colin’s email address is
colin@semprog.com (note how
semperp:colin, the subject, is only stated
once):
semperp:colin foaf:knows <http://kiwitobes.com/toby.rdf#ts>;
foaf:mbox "colin@semprog.com".N3 also provides a shortcut that allows you to express a group of statements that share a common anonymous subject (blank node) without having to specify an internal name for the blank node. As discussed earlier, mailing addresses are frequently modeled with a blank node to hold all the components of the address together. W3C has defined a vocabulary for representing the data elements of the vCard interchange format that includes predicates for modeling street addresses. For instance, to specify the address of O’Reilly, you could write:
[ <http://www.w3.org/2006/vcard/ns#street-address> "1005 Gravenstein Hwy North" ;
<http://www.w3.org/2006/vcard/ns#locality> "Sebastopol, California"
].Because it is important to explicitly state that an entity is of a
certain type, N3 allows you to use the letter a as a
predicate to represent the RDF “type” relationship represented by the
URI
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>.
Another predicate for which N3 provides a shortcut is
<http://www.w3.org/2002/07/owl#sameAs>. OWL
(Web Ontology Language) is a vocabulary for defining precise relationships between model elements. We
will have more to say about OWL in Chapter 6,
but even when models don’t use the precision of OWL, you will frequently
see the owl:sameAs predicate to express that two URIs
refer to the same entity. The sameAs predicate is
used so frequently that the authors of N3 designated the symbol
= as shorthand for it.
Because N-Triples are a subset of N3, any library capable of reading N3 will also read N-Triples. The FOAF graph (Figure 4-4) in N3 would read:
@prefix foaf: <http://xmlns.com/foaf/0.1/>.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>.
@prefix semperp: <http://semprog.com/people/>.
@prefix tobes: <http://kiwitobes.com/toby.rdf#>.
tobes:ts a foaf:Person;
foaf:homepage <http://kiwitobes.com/>;
foaf:interest <http://semprog.com>;
foaf:knows semperp:colin,
[ a foaf:Person;
foaf:mbox <mailto:jamie@semprog.com>;
foaf:name "Jamie Taylor"];
foaf:mbox <mailto:toby@segaran.com>;
foaf:name "Toby Segaran";
foaf:nick "kiwitobes".
<http://semprog.com> a foaf:Document;
rdfs:label "Semantic Programming".
semperp:colin a foaf:Person;
foaf:mbox <mailto:colin@semprog.com>;
foaf:name "Colin Evans". RDF/XML
The original W3C Recommendation on RDF covered both a description of RDF as a data model and XML as an expression of RDF models. Because of this, people sometimes refer to RDF/XML as RDF, but it is important to recognize that it is just one possible representation of an RDF graph. RDF/XML is sometimes criticized for being difficult to read due to all the abbreviated structures it provides; still, it is one of the most frequently used formats, so it’s useful to have some familiarity with its layout.
Conceptually, RDF/XML is built up from a series of smaller descriptions, each of which traces a path through an RDF graph. These paths are described in terms of the nodes (subjects) and the links (predicates) that connect them to other nodes (objects). This sequence of “node, link, node” is repeatable, forming a “striped” structure (think of a candy cane, with nodes being red stripes and predicates being white stripes). Since each node encountered in these descriptions has a strong identifier, it is possible to weave the smaller descriptions together to learn the larger RDF graph structure. See Figure 4-5.
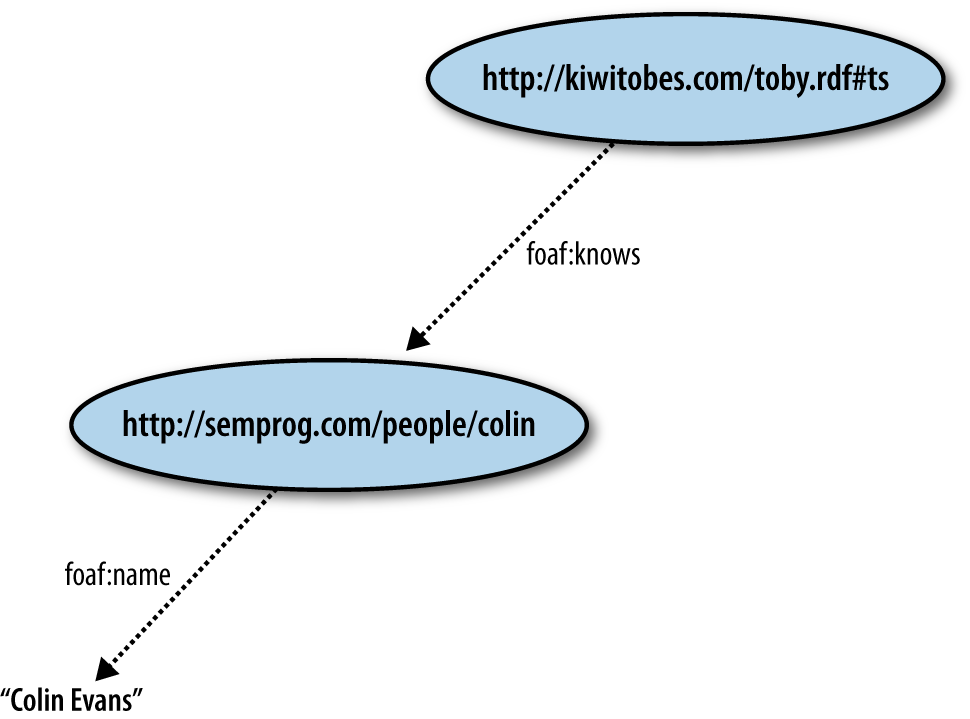
If there is more than one path described in an RDF/XML document,
all the descriptions must be children of a single RDF element; if there
is only one path described, the rdf:RDF element may
be omitted. As with other XML documents, the top-level element is
frequently used to define other XML namespaces used throughout the
document:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"/>
Paths are always described starting with a graph node, using an
rdf:Description element. The URI reference for the node
can be specified in the description element with an
rdf:about attribute. For blank nodes, a local identifier (valid only within the
context of the current document) can be specified using an
rdf:NodeID attribute. Predicate links are specified
as child elements of the rdf:Description node, which
will have their own children representing graph nodes. The simple stripe
representing Colin as a friend of Toby (Figure 4-5) would look like:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foaf="http://xmlns.com/foaf/0.1/">
<rdf:Description rdf:About="http://kiwitobes.com/toby.rdf#ts>
<foaf:knows>
<rdf:Description rdf:About="http://semprog.com/people/colin">
<foaf:name>Colin Evans</foaf:name>
</rdf:Description>
</foaf:knows>
</rdf:Description>
</rdf:RDF>
Literal objects can be specified as the text of an element, or as
an attribute on the rdf:Description element. Let’s
expand the example, adding more information about Colin and about
another friend of Toby’s:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foaf="http://xmlns.com/foaf/0.1/">
<rdf:Description rdf:about="http://kiwitobes.com/toby.rdf#ts>
<foaf:knows>
<rdf:Description rdf:about="http://semprog.com/people/colin">
<foaf:name>Colin Evans</foaf:name>
<foaf:mbox>colin@semprog.com</foaf:mbox>
</rdf:Description>
</foaf:knows>
<foaf:knows>
<rdf:Description foaf:mbox="jamie@semprog.com"/>
</foaf:knows>
</rdf:Description>
</rdf:RDF>
While this is a perfectly reasonable description of Toby’s
relationship to Colin and Jamie, we are still missing the
rdf:type information that states that Toby, Colin,
and Jamie are people. As in the other RDF serializations we have looked
at, RDF/XML provides a shortcut for this very common statement, allowing
you to replace the rdf:Description element with an
element representing the rdf:type for the node. Thus
the sequence of elements:
<rdf:Description rdf:about="http://www.kiwitobes.com/toby.rdf#ts><rdf:type>
<foaf:Person>is compacted into a single rdf:Description
element of the form:
<foaf:Person rdf:about="http://kiwitobes.com/toby.rdf#ts">
The FOAF graph we represented in N-Triples and N3 can now be represented in RDF/XML as:
<rdf:RDF
xmlns:foaf='http://xmlns.com/foaf/0.1/'
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:rdfs='http://www.w3.org/2000/01/rdf-schema#'>
<foaf:Person rdf:about="http://kiwitobes.com/toby.rdf#ts">
<foaf:name>Toby Segaran</foaf:name>
<foaf:homepage rdf:resource="http://kiwitobes.com/"/>
<foaf:nick>kiwitobes</foaf:nick>
<foaf:mbox rdf:resource="mailto:toby@segaran.com"/>
<foaf:interest>
<foaf:Document rdf:about="http://semprog.com">
<rdfs:label>Semantic Programming</rdfs:label>
</foaf:Document>
</foaf:interest>
<foaf:knows>
<foaf:Person rdf:about="http://semprog.com/people/colin">
<foaf:name>Colin Evans</foaf:name>
<foaf:mbox rdf:resource="mailto:colin@semprog.com"/>
</foaf:Person>
</foaf:knows>
<foaf:knows>
<foaf:Person>
<foaf:name>Jamie Taylor</foaf:name>
<foaf:mbox rdf:resource="mailto:jamie@semprog.com"/>
</foaf:Person>
</foaf:knows>
</foaf:Person>
</rdf:RDF>These aren’t the only abbreviated structures RDF/XML provides, but this should be enough to let you read most RDF/XML files.
RDFa
RDFa isn’t a pure serialization format for RDF, but rather a way of annotating XHTML web pages with RDF data. The idea behind RDFa is that you only have to publish your content once, mixing the human-readable and machine-readable content together. This is a similar philosophy to that of Microformats, a simpler, more ad-hoc approach to adding rich semantic annotations to XHTML content.
RDFa uses a small set of XML attributes that are added to existing XHTML content tags in order to specify the semantics behind the information that is displayed. These attributes make the semantic meaning of existing XHTML content clear. The basic processing model is that the subject of a triple is the subject URI identified in a higher-level XHTML element in the DOM tree, and the predicate and object of a statement are lower down on the tree, children of the subject.
Instead of using URIs to describe subjects, predicates, and
objects, many RDFa attributes use Compact URIs (or CURIEs) to reduce the amount of markup.
CURIEs work just like XML Qualified Names (in fact, QNames are a subset of
CURIEs), so everything you know about XML QNames (such as that
foaf:nick actually means
http://xmlns.com/foaf/0.1/nick) applies to CURIEs.
But CURIEs are a bit more accommodating in what the
localpart of the prefix:localpart
expression can contain.
QName construction forbids slashes (/) in the
localpart, thus requiring a separate XML namespace
declaration for every QName using a different part of the path hierarchy. CURIEs relax this constraint,
allowing statements like example:cow and example:places/barn to use one
xmlns declaration—like http://example.org/farm/—to
generate the full URIs http://example.org/farm/cow
and http://example.org/farm/places/barn,
respectively.
CUIREs also allow for localparts that start
with a number. This means that you could define an XML namespace
as:
xmlns:amazonisbn="http://www.amazon.com/exec/obidos/ASIN/"
and then refer to the book Programming the Semantic Web by its ISBN with the CURIE:
amazonisbn:0596153813
CURIEs are great when you are working with predicates because you
can make one xmlns declaration for each vocabulary you are using and
quickly construct CURIEs for any property in the vocabulary. However,
they can be frustrating when you want to talk about a wide range of
subjects or objects (since you have to make an xmlns declaration for
each unique base URI). To alleviate this problem, RDFa allows you to use
full URIs for several of the subject and object attributes. But because
full URIs use a colon to separate the protocol scheme from the
hierarchical part of the URI, parsers could become confused when they
see the http:—did you mean http:
as in http://example.org/cow or
were you writing a CURIE where http is a prefix for
some namespace?
To avoid this confusion, RDFa defines a “safe CURIE” that makes it clear when a colon-separated statement is being used as a CURIE versus as a protocol identifier in a URI. To construct a safe CURIE, simply place your CURIE in square brackets, as in:
[example:place/barn]
Let’s look at the list of attributes used by RDFa, grouping them by the part of the RDF statement that they declare.
This is the attribute to set an RDF subject:
These are the attributes to set an RDF predicate:
These are the attributes to set an RDF object:
RDFa also provides special attributes for specifying datatypes and
making rdf:type statements:
It is important to note that the attribute you use to set the
predicate depends on the type of object in the RDF statement. If the
object is a literal, then the predicate is specified with the property attribute. If, however, the
object is a resource, the rel or rev attribute
is used. Because XHTML is markup for producing human-readable displays,
it may not be convenient to display data in the subject-predicate-object
order of an RDF statement. To handle these situations, RDFa provides the
rev attribute for setting the predicate, which also
indicates that the order of the statement has been reversed (object,
predicate, subject).
Minimally, we can specify RDF triples in a single markup element.
In the following example, the object is a literal, so we use the
attribute property to state the predicate:
<span xmlns:foaf="http://xmlns.com/foaf/0.1/"
about="http://kiwitobes.com/toby.rdf#ts"
property="foaf:nick"
content="kiwitobes" />When the statement’s object is a resource, we use the attribute
rel to state the predicate:
<span xmlns:foaf="http://xmlns.com/foaf/0.1/"
about="http://kiwitobes.com/toby.rdf#ts"
rel="http://xmlns.com/foaf/0.1/homepage"
href="http://kiwkitobes.com" />But we can also use the XHTML element to display parts of the structure. For instance, we can make the following statement about Toby’s nickname when displaying the string “kiwitobes”:
Toby's nickname is: <span xmlns:foaf="http://xmlns.com/foaf/0.1/"
about="http://kiwitobes.com/toby.rdf#ts"
property="http://xmlns.com/foaf/0.1/nick">kiwitobes</span>Here’s an example of Toby’s FOAF record as a fragment of XHTML annotated with RDFa. The XML attributes and text that an RDFa parser would glean from this XHTML are in bold. The annotations can be made in any tags and are meant to reuse existing XHTML attributes and text that are also being used in the human-readable XHTML content. It can be tricky to figure out how to weave the attributes into existing documents, but the benefit is that all of the data is made available in one place and the concepts being discussed are unambiguously described using strong URIrefs:
<div xmlns:foaf="http://xmlns.com/foaf/0.1/"
about="http://kiwitobes.com/toby.rdf#ts" typeof="foaf:Person">
Name: <span property="foaf:name">Toby Segaran</span><br/>
Nickname: <span property="foaf:nick">kiwitobes</span><br/>
Interests: <a rel="foaf:interest" href="http://semprog.org">
<span property="rdfs:label">Semantic Programming</span></a>
Homepage: <a rel="foaf:homepage" href="http://kiwkitobes.com/">KiwiTobes</a><p/>
Friends:<br/>
<ul rel="foaf:knows">
<li about="http://semprog.com/people/colin"
typeof="foaf:Person" property="foaf:name">Colin Evans</li>
<li typeof="foaf:Person">
<span property="foaf:name">Jamie Taylor</span><br/>
Email: <a rel="foaf:mbox" href="mailto:jamie@semprog.com">
jamie@semprog.com</a><br/>
</li>
</ul>
</div>
Tip
In documents with copious amounts of human markup, it can be
challenging to read RDFa. One way to work your way through the jungle of markup is
to scan for rel, rev, and
property attributes in a markup tag. Once you have
found one of these elements, you know you have found the predicate of
a statement. Then, search backward up the DOM tree to find the subject
of the statement (remember, if you don’t find one, the document itself
is the subject). Then search down the DOM tree to find the next item
that can serve as an object for the statement. Keep in mind that if
the predicate was specified using a rev attribute,
the order of the statement will be reversed.
Because XHTML was designed to be extensible and allows new attributes to be added to markup elements, RDFa was specified as annotations on XHML. In practice, RDFa works perfectly well on HTML, though the markup will not validate against HTML 4.
Because it is easy to wrap templated HTML output with RDFa, and given the prevalence of database-driven websites, the amount of RDFa available on the Web is growing rapidly. A number of prominent sites, including MySpace and popular authoring tools, now have RDFa output capabilities, though it may not be obvious because RDFa doesn’t alter the HTML rendering.
In later chapters we will show how Yahoo! is extracting semantic data from sites using RDFa to enhance search, and we will revisit RDFa as we build more sophisticated semantic applications that not only consume semantic data, but republish their output for use by other semantic services.
RDFa is now a W3C Recommendation, but there have been several other attempts to embed RDF in HTML. One effort was eRDF (“embeddable RDF”), which predates RDFa. eRDF never reached a critical mass, and like other RDF microformats, it generally isn’t supported by RDF tools; still, it’s possible that you may run into it. You can read more about eRDF at http://research.talis.com/2005/erdf/wiki/Main/RdfInHtml.
Introducing RDFLib
The triplestore and query language we developed in Chapters 2 and 3 were useful for understanding how triplestores work. And while we could implement parsers and serializers for the myriad RDF output formats and add all the features you would expect in a full-fledged RDF library, doing so would distract us from our real interest: building semantic applications for the Web.
The good news is that research on semantic web technologies over the past decade has produced a number of excellent open source libraries for managing RDF data. For the remainder of this book we will adopt various RDF libraries and frameworks, introducing you to some of the more popular semantic platforms and allowing us to select the tool best suited for a particular task.
For many of our examples we will utilize RDFLib, a lightweight but functionally complete RDF library. RDFLib is very Pythonic in its approach, allowing applications to access RDF structures through standard Python idioms. You can download RDFLib from http://rdflib.net. To install the library, decompress and unpack the TAR file and make the top-level directory of the project your working directory. At a command prompt, enter:
c:\download\rdflib-2.4.0>python setup.py install
Now that you have RDFLib installed, let’s take it for a test drive and see what we can do with it. Start an interactive Python session and create a graph with the following commands:
>> import rdflib >> from rdflib.Graph import ConjunctiveGraph >> g = ConjunctiveGraph()
Let’s read in an RDF graph from the Web and examine a few of the
ways you can inspect it. The Graph class provides a handy parse method, which not only loads data files into the
graph, but can retrieve them from the Web as well. Grab Colin’s FOAF file
from the semprog
website with the following command:
>> g.parse("http://semprog.com/people/colin", format="nt")You can view the triples that define the graph by iterating over the graph directly:
>> for triple in g: >> ... print triple
Or you can query the triples, just as we did in Chapter 2, by looking for triple patterns using wildcards within a statement:
>> list( g.triples((None,rdflib.URIRef('foaf:knows'),None)) )Colin’s FOAF file was originally in N-Triple format, but perhaps we would like to save it to disk as RDF/XML:
>> outfile = open("colin.xml", "w")
>> outfile.write(g.serialize(format="pretty-xml"))If you open colin.xml in a text editor, you should see a FOAF file similar to the one we examined earlier in the section RDF/XML. Let’s create a new graph and read Colin’s FOAF file in from disk, and then look at the graph serialized as N3:
>> newg = ConjunctiveGraph()
>> newg.parse("colin.xml")
>> newg.serialize(format="n3")We now have two graphs in memory, g and
newg. If everything is working as expected, both graphs
should be identical—the various serializations should not have changed any
of the information in the graphs. To prove this to ourselves, we can make
use of RDFLib’s ability to perform set operations on graphs. To do this,
we will subtract graph g from newg,
which will remove all the triples that appear in g from
newg. If newg and
g are identical, we shouldn’t have any triples in
newg after subtracting g:
>> newg -= g >> len(newg) 0
Actually, RDFLib provides a Graph method that
tests whether two graphs have the same shape (in other words, are
isomorphic). Let’s try that again:
>> g.isomorphic(newg)
False
#we made newg have zero triples in our last test, so let's reload it and try again
>> newg.parse("colin.xml")
>> g.isomorphic(newg)
TrueJust like our triplestore in Chapter 2,
triples can be inserted directly into the graph using tuples. Since we
believe that anyone who reads this book must be a friend, let’s add you to
Colin’s social network. First, we need to add a statement that says you
are a person (you are a person, right?). To do this, you will need to
identify yourself with a URI reference (you can just make up a URI for
now). RDFLib provides a class for creating URI references called
URIRef that takes a string, representing the URI, as an
argument:
>> me = URIRef("http://my.uri.com/goes/here")Next, we need to create a URIref for the predicate
rdf:type. Since we may need to add other URIrefs to the
RDF vocabulary, we will use RDFLib’s Namespace
class to generate this URIref. Once instantiated, the
Namespace class allows you to create URIrefs by
accessing the instance as a dictionary:
>> RDF = rdflib.Namespace("http://www.w3.org/TR/rdf-schema/#")
>> rdf-type-predicate = RDF["type"]Since we are adding new statements to Colin’s FOAF graph, which is
currently in memory and bound to the variable g, the
FOAF namespace must have already been defined. To find out, we can list
all the namespace bindings in the current graph:
>> [ x for x in g.namespaces() ]
[(u'foaf', rdflib.URIRef('http://xmlns.com/foaf/0.1/')),....]The base URI for the FOAF vocabulary has been bound to the
foaf namespace prefix; knowing that, we can go ahead
and assert our statement, declaring you are a person:
>> g.add((me, rdf-type-predicate, foaf["person"]))
Using these same techniques, we can now add a statement declaring you are friend of Colin:
>> g.add(URIRef("http://semprog.com/people/colin"), foaf["knows"], me)And like our triplestore in Chapter 2,
the graph can be queried using tuples where None
indicates a free parameter:
>> list( g.triples((None, foaf["knows"], None)) )
While RDFLib can use Python strings as subjects, predicates, and
objects, some operations will not work if they are not properly typed as
rdflib.URIRef. Since it is so easy to create URIrefs
with RDFLib, and we know that predicates, subjects, and nonliteral objects
should always have URI references, there isn’t any reason for not
constructing them correctly.
Persistence with RDFLib
One of the advantages of using RDFLib is that we can load triples into a graph store that will persist across our example applications and command-line sessions. With a persistent graph, we can then write code that will attach to the graph store and make use of the previously loaded triples.
RDFLib uses a simple plug-in framework that facilitates adding new parsers, serializers, and storage systems. While RDFLib supports the use of MySQL and Sleepycat databases for persistence, we will use SQLite as our storage medium to simplify setup. SQLite is a simple, cross-platform database system that runs within an application process and requires no configuration—perfect for our needs. If your system doesn’t have SQLite installed, download and install a SQLite package from http://www.sqlite.org/.
The Python interface for SQLite is called pysqlite and can be downloaded from http://pysqlite.org (which should redirect you to the current home of the project). For Windows, download and run the binary installer appropriate for your version of Python. For all other platforms, download the compressed source TAR file and enter the following at the command prompt (replacing the version number to reflect the file you downloaded):
$ gunzip pysqlite-2.5.0a.tar.gz $ tar xvf pysqlite-2.5.0a.tar $ cd pysqlite-2.5.0 $ python setup.py build $ python setup.py install
To initialize a new persistent RDFLib triplestore called
rdf-test.ts, try the following from an interactive
Python session:
>> import rdflib
>> from rdflib import Literal
>> store = rdflib.plugin.get('SQLite', rdflib.store.Store)('rdf-test.ts')
>> store.open('.', create=True) #create in the current working directory - dot
>> g = rdflib.ConjunctiveGraph(store)
>> semprog = rdflib.Namespace("http://semprog.com/people/")
>> foaf = rdflib.Namespace("http://xmlns.com/foaf/0.1/")
>> g.add((semprog["jamie"], foaf["name"], Literal("Jamie Taylor")))
>> g.add((semprog["jamie"], foaf["mbox"], Literal("jamie@semprog.com")))
>> g.serialize(format="nt") #just to check our work
>> g.commit()
Now quit your Python session (just to prove to yourself that there is no magic happening in your session memory). Then restart your Python interpreter and try reading the triples back from the persistent store:
>> import rdflib
>> store = rdflib.plugin.get('SQLite', rdflib.store.Store)('rdf-test.ts')
>> store.open('.', create=False)
>> g = rdflib.ConjunctiveGraph(store)
>> g.serialize(format="nt")You should see the triples you entered during the first session.
We should point out a few things before we move along. First, the
default for the create parameter in the
open method is create=True, so
when you want to open an existing database, you must explicitly state
create=False. Fortunately, it is an error to create a
database that already exists, so if you forget and try to recreate the
database, you will throw a pysqlite OperationalError, which will prevent the
database from being overwritten. Also, pysqlite supports transactions, which
RDFLib will use when writing to the store. By default, autocommit is
off, which means you must explicitly call commit at the end of your
writes.
Armed with the information from this introduction, you should now be able to navigate RDFLib’s online documentation to find other useful classes and methods if you need to solve more complex problems.
SPARQL
Just as SQL provides a (relatively) standard query language across relational database systems, SPARQL provides a standardized query language for RDF graphs. SPARQL (Simple Protocol and RDF Query Language) is similar to the query language we developed in Chapter 3, with a number of important and powerful additions, including the ability to filter results and construct new graphs based on queries. Like our earlier query language, SPARQL queries attempt to match patterns in the graph and bind wildcard variables as it finds solutions.
Throughout this section we will query a small graph of movie data, represented as follows using N3. This set of statements comes from a larger set of triples derived from Freebase that represents movies released between the years 2000 and 2008. You can download both datasets from http://semprog.com/psw/chapt4/moviedata:
@prefix fb: <http://rdf.freebase.com/ns/> .
<http://rdf.freebase.com/ns/en.hollywood_homicide>
<http://rdf.freebase.com/ns/film.film.directed_by>
<http://rdf.freebase.com/ns/en.ron_shelton> ;
<http://rdf.freebase.com/ns/film.film.starring>
<http://rdf.freebase.com/ns/en.harrison_ford> ,
<http://rdf.freebase.com/ns/en.kurupt> ,
<http://rdf.freebase.com/ns/en.robert_wagner> ;
<http://rdf.freebase.com/ns/film.film.initial_release_date> "2003" .
<http://rdf.freebase.com/ns/en.k_19_the_widowmaker>
<http://rdf.freebase.com/ns/film.film.directed_by>
<http://rdf.freebase.com/ns/en.kathryn_bigelow> ;
<http://rdf.freebase.com/ns/film.film.starring>
<http://rdf.freebase.com/ns/en.harrison_ford> ,
<http://rdf.freebase.com/ns/en.joss_ackland> ;
<http://rdf.freebase.com/ns/film.film.initial_release_date> "2002" .
<http://rdf.freebase.com/ns/en.dark_blue>
<http://rdf.freebase.com/ns/film.film.directed_by>
<http://rdf.freebase.com/ns/en.ron_shelton> ;
<http://rdf.freebase.com/ns/film.film.starring>
<http://rdf.freebase.com/ns/en.kurupt> ,
<http://rdf.freebase.com/ns/en.kurt_russell> ,
<http://rdf.freebase.com/ns/en.dash_mihok> .
<http://rdf.freebase.com/ns/en.the_weight_of_water_2002>
<http://rdf.freebase.com/ns/film.film.directed_by>
<http://rdf.freebase.com/ns/en.kathryn_bigelow> ;
<http://rdf.freebase.com/ns/film.film.starring>
<http://rdf.freebase.com/ns/en.sean_penn> ,
<http://rdf.freebase.com/ns/en.elizabeth_hurley> ;
<http://rdf.freebase.com/ns/film.film.initial_release_date> "2002" .
<http://rdf.freebase.com/ns/en.becoming_dick>
<http://rdf.freebase.com/ns/film.film.directed_by>
<http://rdf.freebase.com/ns/en.bob_saget> ;
<http://rdf.freebase.com/ns/film.film.starring>
<http://rdf.freebase.com/ns/en.robert_wagner> ,
<http://rdf.freebase.com/ns/en.bob_saget> ;
<http://rdf.freebase.com/ns/film.film.initial_release_date> "2000" .
<http://rdf.freebase.com/ns/en.body_of_lies>
<http://rdf.freebase.com/ns/film.film.directed_by>
<http://rdf.freebase.com/ns/en.ridley_scott> ;
<http://rdf.freebase.com/ns/film.film.starring>
<http://rdf.freebase.com/ns/en.russell_crowe> ,
<http://rdf.freebase.com/ns/en.mark_strong> ;
<http://rdf.freebase.com/ns/film.film.initial_release_date> "2008" .
<http://rdf.freebase.com/ns/en.kurt_russell>
<http://rdf.freebase.com/ns/type.object.name> "Kurt Russell" .
<http://rdf.freebase.com/ns/en.dash_mihok>
<http://rdf.freebase.com/ns/type.object.name> "Dash Mihok" .
<http://rdf.freebase.com/ns/en.sean_penn>
<http://rdf.freebase.com/ns/type.object.name> "Sean Penn" .
<http://rdf.freebase.com/ns/en.elizabeth_hurley>
<http://rdf.freebase.com/ns/type.object.name> "Elizabeth Hurley" .
<http://rdf.freebase.com/ns/en.kathryn_bigelow>
<http://rdf.freebase.com/ns/type.object.name> "Kathryn_Bigelow" .
<http://rdf.freebase.com/ns/en.bob_saget>
<http://rdf.freebase.com/ns/type.object.name> "Bob Saget" .
<http://rdf.freebase.com/ns/en.ridley_scott>
<http://rdf.freebase.com/ns/type.object.name> "Ridley Scott" .
<http://rdf.freebase.com/ns/en.russell_crowe>
<http://rdf.freebase.com/ns/type.object.name> "Russell Crowe" .
<http://rdf.freebase.com/ns/en.mark_strong>
<http://rdf.freebase.com/ns/type.object.name> "Mark Strong" .
<http://rdf.freebase.com/ns/en.ron_shelton>
<http://rdf.freebase.com/ns/type.object.name> "Ron Shelton" .
<http://rdf.freebase.com/ns/en.harrison_ford>
<http://rdf.freebase.com/ns/type.object.name> "Harrison Ford" .
<http://rdf.freebase.com/ns/en.robert_wagner>
<http://rdf.freebase.com/ns/type.object.name> "Robert Wagner" .
<http://rdf.freebase.com/ns/en.kurupt>
<http://rdf.freebase.com/ns/type.object.name> "Kurupt" .SPARQL provides four forms of queries: SELECT, CONSTRUCT, ASK, and DESCRIBE. All of these attempt to find solutions to a graph pattern, and all share similar constructs. While SPARQL is a W3C Recommendation, many semantic platforms support only a few of the SPARQL query forms—however, any semantic platform worth considering should at least support the SELECT form of SPARQL query.
We will describe the uses of and the differences between the four forms, but first let’s look at the common structures while we examine the SELECT form.
SELECT Query Form
SPARQL SELECT queries are very similar to the query language we developed in Chapter 3. As with any SPARQL query, a SELECT query can start with a block of PREFIX declarations, which assign shorthand identifiers for URI namespaces that can be used throughout the query. The sample data we will use comes from Freebase, a large, open semantic database that we will cover in the next chapter. To shorten the Freebase URIs, we add the statement:
PREFIX fb: <http://rdf.freebase.com/ns/>
The initial part of the query can also define a BASE URI to which
all relative URIs are concatenated. The following BASE declaration would
allow us to use a relative URI of
<b006ww0v.rdf> to specify Pete Tong’s BBC
program, which has an absolute URI of
<http://www.bbc.co.uk/programmes/b006ww0v.rdf>:
BASE <http://www.bbc.co.uk/programmes/>
Note that while you can have any number of PREFIX declarations, you can have at most one BASE declaration.
A SELECT query allows you to identify a subset of the variables
used in the graph patterns whose bindings you want returned for each
solution. The SELECT clause is followed by a WHERE clause that specifies the graph pattern to match as
a collection of triples. Variables in the triple pattern are identified
by character strings starting with a question mark (?) or dollar sign
($); there is no difference between the two variable
identifiers.
Example 4-1 shows a query that asks which directors have appeared in their own movies.
PREFIX fb:<http://rdf.freebase.com/ns/>
SELECT ?who ?film
WHERE{
?film fb:film.film.directed_by ?who .
?film fb:film.film.starring ?who .
}This query produces the following results:
| who | film |
fb:en.bob_saget | fb:en.becoming_dick |
OPTIONAL and FILTER Constraints
There may be times when you would like to consider information in the solution if it’s available, but ignore it if it’s not available. This happens frequently when there may be incomplete information about a resource, such as a missing release date in our movie data. SPARQL provides an OPTIONAL clause that allows you to use information in the graph pattern if it’s available, but not eliminate solutions if it’s missing. For instance, in Example 4-2 we want to list all of Ron Shelton’s movies, including the release date if it’s available.
PREFIX fb: <http://rdf.freebase.com/ns/>
SELECT ?film ?reldate
WHERE {
?film fb:film.film.directed_by fb:en.ron_shelton .
OPTIONAL { ?film fb:film.film.initial_release_date ?reldate .}
}
When available, the OPTIONAL clause binds the
?reldate to the solution produced by the required
part of the graph pattern:
| film | reldate |
fb:en.dark_blue | |
fb:en.hollywood_homicide | 2003 |
Graph patterns are useful for determining whether a specific set of relationships exists within a graph, but frequently you will want to constrain solutions based on specific qualities of a subject, predicate, or object. To do this, SPARQL provides FILTER operations that allow you to specify additional constraints on solution bindings. FILTER constraints use a small set of operators, many derived from XPath 2.0, that allow you to test the variables in the graph pattern for specific conditions. When a FILTER returns false (or an error), the solution under consideration is weeded out.
For instance, while the OPTIONAL clause is useful for handling
missing data, you can use OPTIONAL in combination with the
bound FILTER operator to specifically find subjects
that don’t assert a specific relationship. Example 4-3 uses FILTER to find films directed by Ron
Shelton that do not have a release date.
PREFIX fb: <http://rdf.freebase.com/ns/>
SELECT ?film
WHERE {
?film fb:film.film.directed_by fb:en.ron_shelton .
OPTIONAL { ?film fb:film.film.initial_release_date ?reldate .}
FILTER (!bound(?reldate))
}
The result tells us that the dataset does not have a release date
for the film Dark Blue
(fb:en.dark_blue).
SPARQL filter operators also allow you to set up conditions on the qualities of a bound variable’s value. For example, it is frequently useful to know whether a string literal follows a specific pattern. For these types of string comparisons, SPARQL provides a regex operator that takes a bound variable, a regex pattern, and an optional set of flags that allow you to do things like ignore case differences between the pattern and the variable’s value.
Example 4-4 asks which actors have the string “russell” (case insensitive) in their name.
PREFIX fb:<http://rdf.freebase.com/ns/>
SELECT distinct ?who ?film
WHERE {
?film fb:film.film.starring ?star .
?star fb:type.object.name ?who .
FILTER regex(?who, "russell", "i")
}This yields both Russell Crowe and Kurt Russell. The SPARQL regex
operator is defined to be the same as the XPath 2.0
fn:matches operator, which allows us to specify
complex regex patterns. For instance, we could limit the results to
Russell Crowe by requiring “russell” to be at the beginning of the
string using FILTER regex(?who,
"^russell",
"i").
SPARQL provides a wide variety of comparisons operators for filters, allowing you to partition results. For instance, Example 4-5 uses the inequality filter to find movies released after 2002.
PREFIX fb:<http://rdf.freebase.com/ns/>
SELECT ?film ?when
WHERE {
?film fb:film.film.initial_release_date ?when .
FILTER (?when > "2002")
}This returns the following:
| film | when |
fb:en.hollywood_homicide | 2003 |
fb:en.body_of_lies | 2008 |
Multiple Graph Patterns
Up to this point we have been considering only one graph pattern per query, but SPARQL allows you to specify multiple graph patterns within a query using braces to group triples into separate patterns. Without any modifiers, all patterns are evaluated together to produce the solution (as though all the triple patterns had been in the same group). When pattern groupings are provided, the FILTER clauses apply to the graph pattern they are grouped with.
In Example 4-6, we are looking for directors with three-letter first names and actors whose names start with B. Since both constraints must be satisfied, the solution must be someone who is both an actor and director. We have only one director who is also an actor in our dataset (Bob Saget), so the candidates to our solution set are fairly constrained to start with. Happily, Bob Saget is a director with a three-letter first name and an actor whose name starts with B, so he is the solution to this query.
PREFIX fb:<http://rdf.freebase.com/ns/>
SELECT ?name
WHERE {
{
?film fb:film.film.directed_by ?person .
?person fb:type.object.name ?name
filter regex(?name, "^... ", "i")
}
{
?film fb:film.film.starring ?actor .
?actor fb:type.object.name ?name
filter regex(?name, "^b", "i")
}
}Both graph patterns are evaluated together, producing Bob Saget as the solution.
Using the UNION keyword, we can have each pattern in the query evaluated independently and their solutions joined together. This can be useful when multiple solutions are equally useful. See Example 4-7.
PREFIX fb:<http://rdf.freebase.com/ns/>
SELECT ?name
WHERE {
{
?film fb:film.film.directed_by ?director .
?director fb:type.object.name ?name
filter regex(?name, "^... ", "i")
}
UNION
{
?film fb:film.film.starring ?actor .
?actor fb:type.object.name ?name
filter regex(?name, "^b", "i")
}
}In this case, there is no requirement that one name fulfill both patterns, so both the directors “Ron Shelton” and “Bob Saget” are solutions.
It is often useful to determine whether two resources are the same
when considering a solution. Consider the query in Example 4-8, which looks for directors who have worked
with a specific actor, in this case Harrison Ford. The query then asks
who else co-starred in those films. It then finds other films in which
the director and co-stars worked together. For our results, however, we
want to exclude the films in which Harrison Ford worked with the
director and co-stars—we are interested only in what other films the
director and co-stars have made together. To do this, we specify a
FILTER constraint where the ?othermovie and
?movie cannot be the same.
PREFIX fb: <http://rdf.freebase.com/ns/>
SELECT ?othermovie ?director ?costar
WHERE {
?movie fb:film.film.starring fb:en.harrison_ford .
?movie fb:film.film.directed_by ?director .
?movie fb:film.film.starring ?costar .
?othermovie fb:film.film.directed_by ?director .
?othermovie fb:film.film.starring ?costar .
FILTER (?othermovie != ?movie)
}
Running this query tells us that Ron Shelton and Kurupt worked with Harrison Ford on a movie, and they also worked together on another movie.
CONSTRUCT Query Form
In many situations it is useful to get a list of variable bindings back from a query, but there are also situations where you want to construct a new graph from the solution set. While you could always write a bit of code that converts solution bindings into tuples and adds them to a graph, SPARQL provides a query form that does this directly. The new graph is constructed from template triples specified in the CONSTRUCT clause, which replaces the SELECT clause. The WHERE and FILTER clauses work in exactly the same way as the SELECT form.
Here we are creating triples indicating who was employed each year based on our movie data:
PREFIX fb:<http://rdf.freebase.com/ns/>
CONSTRUCT {
?who <http://employment.history/was_employed_in> ?year
}
WHERE {
{
?film fb:film.film.starring ?who .
?film fb:film.film.initial_release_date ?year .
}
UNION
{
?film fb:film.film.directed_by ?who .
?film fb:film.film.initial_release_date ?year .
}
} ASK and DESCRIBE Query Forms
SPARQL provides a simple ASK form that tests whether a pattern can be found in a graph. The ASK keyword replaces the WHERE keyword, and a simple boolean result is returned indicating whether there is a solution for the pattern in the graph. This query asks whether Bob Saget and Harrison Ford have ever appeared in the same movie:
PREFIX fb:<http://rdf.freebase.com/ns/>
PREFIX rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#>
ASK {
?film fb:film.film.starring fb:en.bob_saget .
?film fb:film.film.starring fb:en.harrison_ford .
}DESCRIBE is a quirky but potentially powerful query form that, as the SPARQL specification puts it, returns “the useful information the service has about a resource.” That is, the results are idiosyncratic to the implementation of the query service. In theory, issuing a DESCRIBE query should help you understand the context of the resources returned, but as they say in consumer disclaimers, “Your results may vary.”
In its simplest form, you can ask a query system to describe what it knows about a specific resource:
DESCRIBE <http://rdf.freebase.com/ns/en.harrison_ford>
You can use DESCRIBE just as you would SELECT, but instead of getting a set of solution bindings returned, the system will attempt to provide information about the resources returned in the solution. In this example, we want to DESCRIBE the directors who made movies in 2003:
PREFIX fb:<http://rdf.freebase.com/ns/>
DESCRIBE ?director
WHERE {
?film fb:film.film.initial_release_date "2003" .
?film fb:film.film.directed_by ?director .
}While it may seem unsettling to get arbitrary information back about a set of resources, this type of result fits semantic programming patterns extremely well. Unlike traditional programming patterns where the structure (and meaning) of data queries is known when the program is written, in later chapters we will explore an introspective style of programming where programs react to new information as they discover its structure.
SPARQL Queries in RDFLib
The RDFLib Graph class, of which
ConjunctiveGraph is a subclass, provides a query
method that allows you to run SPARQL queries against your triplestore.
The query method takes a string representing the query and
an optional initNS keyword parameter that contains
a dictionary of namespace mappings. Optionally, you can include the
SPARQL prefix declarations directly in your query:
from rdflib.Graph import ConjunctiveGraph, Namespace
FBNAMESPACE = Namespace("http://rdf.freebase.com/ns/")
g = ConjunctiveGraph()
g.parse("sample-movie-data.n3", format="n3")
results = g.query("""SELECT ?film ?year
WHERE { ?film fb:film.film.initial_release_date ?year. }""", \
initNs={'fb':FBNAMESPACE})
for triple in results:
print tripleYou can also run CONSTRUCT queries using RDFLib. The query method returns a resulting graph that can be serialized and used to construct other graphs:
from rdflib.Graph import ConjunctiveGraph, Namespace
FBNAMESPACE = Namespace("http://rdf.freebase.com/ns/")
g = ConjunctiveGraph()
g.parse("sample-movie-data.n3", format="n3")
results = g.query("""CONSTRUCT {
?who <http://employment.history/was_employed_in> ?year
}
WHERE {
?film fb:film.film.starring ?who .
?film fb:film.film.initial_release_date ?year .
}""", initNs={'fb':FBNAMESPACE}).serialize(format="xml")
print result
Tip
If you are having problems with the CONSTRUCT query in RDFLib,
check the version number of your build by entering an interactive
Python session, importing
RDFLib, and entering rdflib.__version__. If the
version is 2.4.0 or earlier, try downloading a more recent version or
the trunk of the Subversion (SVN) repository.
To download RDFLib using SVN, enter the following on the command line:
$ svn checkout http://rdflib.googlecode.com/svn/trunk/ rdflib-trunk $ cd rdflib-trunk $ python setup.py build
A fresh build of RDFLib will be available in build/lib.<yourplatform-architecture>/rdflib.
You can test the build by changing directories down to the build/lib.<yourplatform-architecture> directory and again firing up an interactive Python session. This time when you import RDFLib you should get the new build (which you can check by printing the version of the library).
While RDFLib returns query results in a Python structure, when you run SPARQL queries on other systems you will frequently get your results packed in an XML structure. The W3C has defined a standard XML query result structure that provides a simple set of XML container elements indicating solution sets and the variable bindings within them. See Example 4-9.
PREFIX fb:<http://rdf.freebase.com/ns/>
Select ?film ?year where{
?film fb:film.film.initial_release_date ?year .
FILTER (?year > "2005")
}Here are the results in SPARQL XML output format:
<?xml version="1.0"?>
<sparql xmlns="http://www.w3.org/2005/sparql-results#">
<head>
<variable name="?film"/>
<variable name="?year"/>
</head>
<results>
<result>
<binding name="year">
<literal>2008</literal>
</binding>
<binding name="film">
<uri>http://rdf.freebase.com/ns/en.body_of_lies</uri>
</binding>
</result>
</results>
</sparql>
SPARQL XML results documents are broken into two parts. The first
part, the head, lists each bound variable used in the
query within its own variable element. The second
part of the document, delineated by a results
element, lists the solution sets returned by the query. Individual
solutions are surrounded by a result element.
In the example just shown, there is only one solution that binds
the variable year to the literal
2008. Optionally, literal elements may also contain
datatype or xml:lang attributes. The solution also binds the
variable film to the object with the URIref http://rdf.freebase.com/ns/en.body_of_lies.
Useful Query Modifiers
SPARQL is a rich query interface that provides a number of optional modifiers that are very useful when developing real applications. For instance, SPARQL supports a simple form of paginating results using the OFFSET, LIMIT, and ORDER BY solution sequence modifiers. To make pagination work, you must first impose an order on the solutions using the modifier ORDER BY. The ORDER BY modifier takes a list of bound variables, sorts the solutions by the first variable, then sorts the resulting solution sequence further using the second bound variable (if specified), and so on. See Example 4-10.
PREFIX fb:<http://rdf.freebase.com/ns/>
SELECT ?name ?year
WHERE{
?movie fb:film.film.initial_release_date ?year .
?movie fb:film.film.starring ?actor .
?actor fb:type.object.name ?name .
} ORDER BY ?year ?nameThis produces a list of actors sorted by the year they worked on a film, and then by name:
| name | year |
| Bob Saget | 2000 |
| Robert Wagner | 2000 |
| Elizabeth Hurley | 2002 |
| Harrison Ford | 2002 |
| Joss Ackland | 2002 |
| Sean Penn | 2002 |
| Harrison Ford | 2003 |
| Kurupt | 2003 |
| Robert Wagner | 2003 |
| Mark Strong | 2008 |
| Russell Crowe | 2008 |
With an order imposed on the solution, you can create pages of specific size using the LIMIT keyword. The OFFSET keyword can then be used to indicate the point in the solution sequence from which to start the next retrieval. If we count pages starting at 1, then in order to obtain the results for page N, specify an OFFSET that is (N-1) * LIMIT. The following code snippet will produce a list of films from our sample dataset, from oldest to newest, paging through the results two solutions at a time:
from rdflib.Graph import ConjunctiveGraph
g = ConjunctiveGraph()
g.parse("sparql-example-data.n3", format="n3")
limit = 2
page = 1
results = True
while results:
print "----page: " + str(page) + "----"
results = g.query("""PREFIX fb:<http://rdf.freebase.com/ns/>
SELECT ?film ?year
WHERE { ?film fb:film.film.initial_release_date ?year. } ORDER BY ?year
LIMIT """ + str(limit) + " OFFSET " + str((page-1)*limit))
for triple in results:
print triple
page += 1This taste of SPARQL should give you enough background to formulate useful queries, but it certainly isn’t an exhaustive tour of all that is possible with SPARQL. Should you find yourself in need of more information, we suggest taking a look at the W3C Recommendation for SPARQL itself. It’s available at http://www.w3.org/TR/rdf-sparql-query/, and as specification documents go, it is surprisingly readable with many useful examples.
One final note. Unlike SQL, SPARQL (currently) only supports read operations on the graph, whereas SQL provides update and insert operations. There is no way to modify a graph using SPARQL. Although this is certainly a limitation, it does mean that you can allow untrusted systems (with some limitations on accessible features) access to query infrastructure without fear of your graph being altered. Exposing a raw query interface to a remote data store is a powerful architectural design, and in later chapters we will build applications that not only run SPARQL queries on a local graph store, but also on SPARQL interfaces provided by remote applications.
Get Programming the Semantic Web now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

