Chapter 4. Apache Flink Implementation
Flink is an open source stream-processing engine (SPE) that does the following:
-
Scales well, running on thousands of nodes
-
Provides powerful checkpointing and save pointing facilities that enable fault tolerance and restartability
-
Provides state support for streaming applications, which allows minimization of usage of external databases for streaming applications
-
Provides powerful window semantics, allowing you to produce accurate results, even in the case of out-of-order or late-arriving data
Let’s take a look how we can use Flink’s capabilities to implement the proposed architecture
Overall Architecture
Flink provides a low-level stream processing operation, ProcessFunction, which provides access to the basic building blocks of any streaming application:
-
Events (individual records within a stream)
-
State (fault-tolerant, consistent)
-
Timers (event time and processing time)
Implementation of low-level operations on two input streams is provided by Flink’s low-level join operation, which is bound to two different inputs (if we need to merge more than two streams it is possible to cascade multiple low-level joins; additionally side inputs, scheduled for the upcoming versions of Flink, would allow additional approaches to stream merging) and provides individual methods for processing records from each input. Implementing a low-level join typically follows the following pattern:
-
Create and maintain a state object reflecting the current state of execution.
-
Update the state upon receiving elements from one (or both) input(s).
-
Upon receiving elements from one or both input(s) use the current state to transform data and produce the result.
Figure 4-1 illustrates this operation.
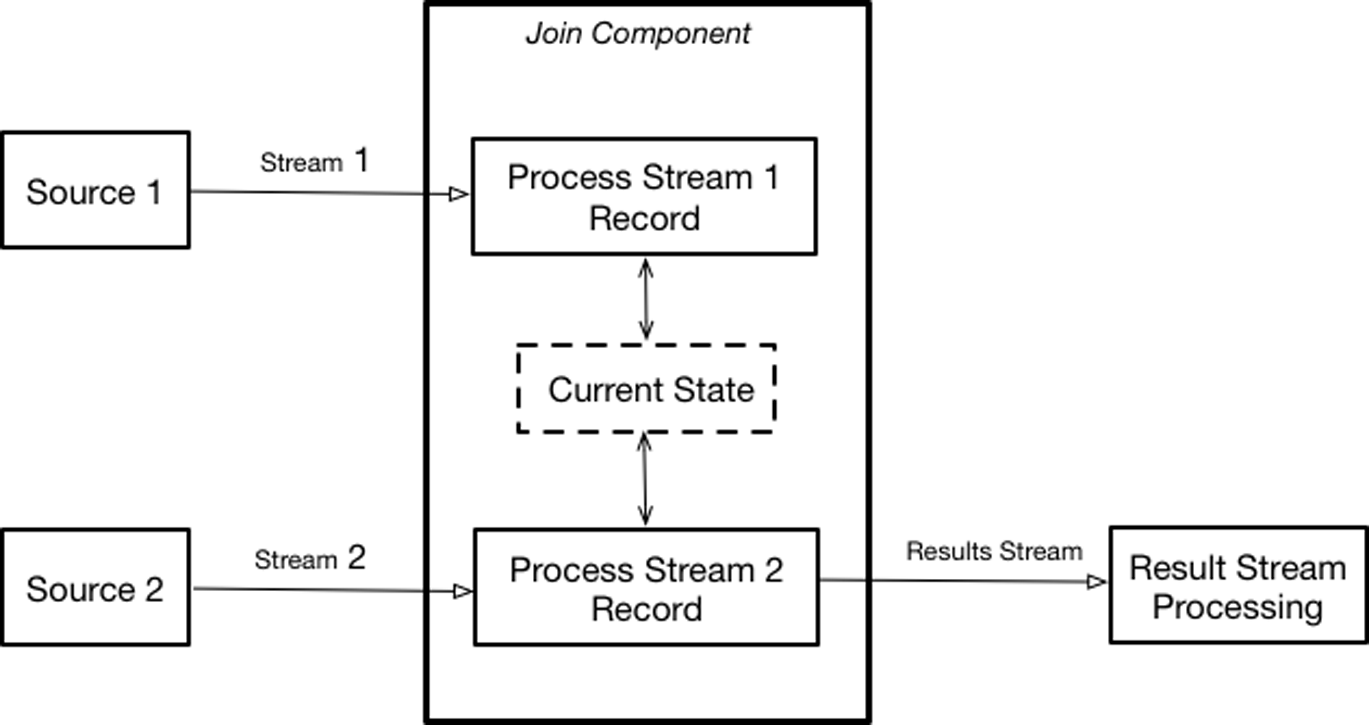
Figure 4-1. Using Flink’s low-level join
This pattern fits well into the overall architecture (Figure 1-1), which is what I want to implement.
Flink provides two ways of implementing low-level joins, key-based joins implemented by CoProcessFunction, and partition-based joins implemented by RichCoFlatMapFunction. Although you can use both for this implementation, they provide different service-level agreements (SLAs) and are applicable for slightly different use cases.
Using Key-Based Joins
Flink’s CoProcessFunction allows key-based merging of two streams. When using this API, data is partitioned by key across multiple Flink executors. Records from both streams are routed (based on key) to an appropriate executor that is responsible for the actual processing, as illustrated in Figure 4-2.
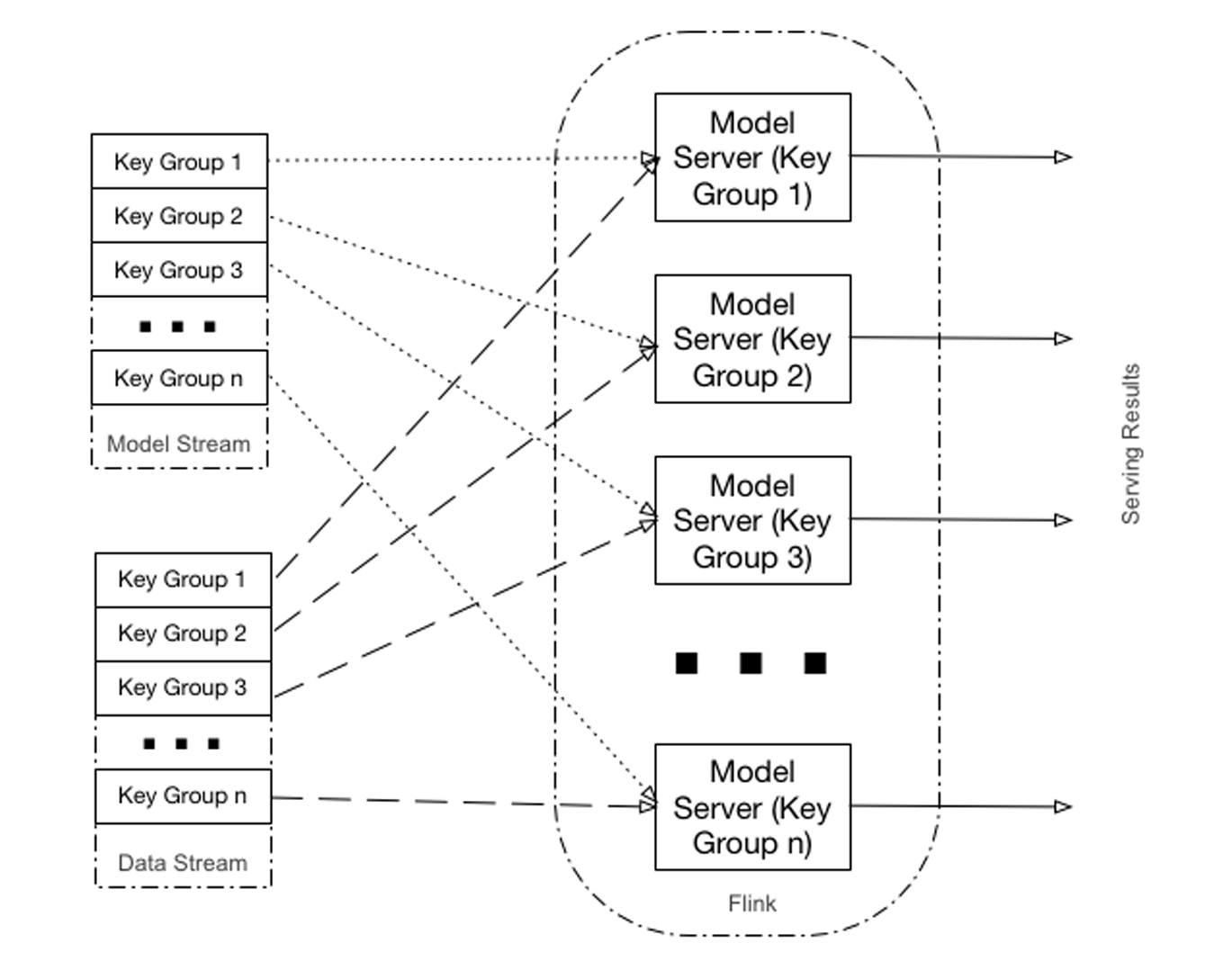
Figure 4-2. Key-based join
Here are the main characteristics of this approach:
-
Distribution of execution is based on key (
dataType, see Examples 3-2 and 3-3). -
Individual models’ scoring (for a given
dataType) is implemented by a separate executor (a single executor can score multiple models), which means that scaling Flink leads to a better distribution of individual models and consequently better parallelization of scorings. -
A given model is always scored by a given executor, which means that depending on the data type distribution of input records, this approach can lead to “hot” executors
Based on this, key-based joins are an appropriate approach for the situations when it is necessary to score multiple data types with relatively even distribution.
In the heart of this implementation is a DataProcessor class (complete code available here), which you can see in Example 4-1.
Example 4-1. The DataProcessor class
object DataProcessorKeyed {
def apply() = new DataProcessorKeyed
...
}
class DataProcessor extends
CoProcessFunction[WineRecord, ModelToServe, Double]
with CheckpointedFunction
with CheckpointedRestoring[List[Option[Model]]] {
var currentModel : Option[Model] = None
var newModel : Option[Model] = None
@transient private var checkpointedState:
ListState[Option[Model]] = null
override def
snapshotState(context: FunctionSnapshotContext): Unit = {
checkpointedState.clear()
checkpointedState.add(currentModel)
checkpointedState.add(newModel)
}
override def initializeState(context:
FunctionInitializationContext): Unit = {
val descriptor = new ListStateDescriptor[Option[Model]] (
"modelState",new ModelTypeSerializer)
checkpointedState = context.getOperatorStateStore.
getListState (descriptor)
if (context.isRestored) {
val iterator = checkpointedState.get().iterator()
currentModel = iterator.next()
newModel = iterator.next()
}
}
override def restoreState(state: List[Option[Model]]): Unit = {
currentModel = state(0)
newModel = state(1)
}
override def processElement2(model: ModelToServe, ctx:
CoProcessFunction[WineRecord,ModelToServe, Double]#Context,
out: Collector[Double]): Unit = {
import DataProcessorKeyed._
println(s"New model - $model")
newModel = factories.get(model.modelType) match {
case Some(factory) => factory.create (model)
case _ => None
}
}
override def processElement1(record: WineRecord, ctx:
CoProcessFunction[WineRecord,ModelToServe, Double]#Context,
out: Collector[Double]): Unit = {
// See if we have update for the model
newModel match {
case Some(model) => {
// Clean up current model
currentModel match {
case Some(m) => m.cleanup()
case _ =>
}
// Update model
currentModel = Some(model)
newModel = None
}
case _ =>
}
currentModel match {
case Some(model) => {
val start = System.currentTimeMillis()
val quality = model.score(record.asInstanceOf[AnyVal]).
asInstanceOf[Double]
val duration = System.currentTimeMillis() - start
modelState.update(modelState.value()
.incrementUsage(duration))
println(s"Calculated quality - $quality")
}
case _ => println("No model available - skipping")
}
}
}This class has two main methods:
processElement2-
This method is invoked when a new
Modelrecord (ModelToServeclass, described later) arrives. This method just builds a new model to serve, as in Example 2-2 for TensorFlow models or Example 2-6 for PMML models, and stores it in anewModelstate variable. Because model creation can be a lengthy operation, I am separating anewModelstate from acurrentModelstate, so that model creation does not affect current model serving. processElement1-
This is invoked when a new
Datarecord (WineRecordclass) arrives. Here, the availability of a new model is first checked, and if it is available, thecurrentModelis updated with the value ofnewModel. This ensures that the model update will never occur while scoring a record. We then check whether there is currently a model to score and invoke the actual scoring.
In addition to these main methods, the class also implements support for checkpointing of managed state. We do this by adding two additional interfaces to the class:
CheckpointedFunction-
The core interface for stateful transformation functions that maintain state across individual stream records.
CheckpointedRestoring-
The interface providing methods for restoring state from the checkpointing.
These two interfaces are implemented by the following three methods: initializeState, snapshotState, and restoreState.
Example 4-2 shows what the ModelToServe class used by the DataProcessor class looks like.
Example 4-2. The ModelToServe class
object ModelToServe {
def fromByteArray(message: Array[Byte]): Try[ModelToServe] = Try{
val m = ModelDescriptor.parseFrom(message)
m.messageContent.isData match {
case true => new ModelToServe(m.name, m.description,
m.modeltype, m.getData.toByteArray, m.dataType)
case _ => throw new Exception("Not yet supported")
}
}
}
case class ModelToServe(name: String, description: String,
modelType: ModelDescriptor.ModelType,
model : Array[Byte], dataType : String) {}This class unmarshals incoming protobufs of the model definition (Example 3-2) and converts it into the internal format used in the rest of the code.
Similarly, we use the DataRecord class to unmarshal the incoming data definition (Example 3-1), as demonstrated in Example 4-3.
Example 4-3. The DataRecord class
object DataRecord {
def fromByteArray(message: Array[Byte]): Try[WineRecord] = Try {
WineRecord.parseFrom(message)
}
}Implementation of checkpointing also requires serialization support for the Model class, shown in Example 4-4 (complete code available here).
Example 4-4. The ModelTypeSerializer class
class ModelTypeSerializer extends TypeSerializer[Option[Model]] {
...
override def serialize(record: Option[Model],
target: DataOutputView): Unit = {
record match {
case Some(model) => {
target.writeBoolean(true)
val content = model.toBytes()
target.writeLong(model.getType)
target.writeLong(content.length)
target.write(content)
}
case _ => target.writeBoolean(false)
}
}
...
override def deserialize(source: DataInputView): Option[Model] =
source.readBoolean() match {
case true => {
val t = source.readLong().asInstanceOf[Int]
val size = source.readLong().asInstanceOf[Int]
val content = new Array[Byte] (size)
source.read (content)
Some(factories.get(t).get.restore(content))
}
case _ => None
}
...This class leverages utility methods on the model and model factory traits to generically implement serialization/deserialization regardless of the actual model implementation.
Serialization implementation also requires implementation of configuration support, which you can see in Example 4-5 (complete code available here).
Example 4-5. The ModelSerializerConfigSnapshot class
class ModelSerializerConfigSnapshot[T <: Model]
extends TypeSerializerConfigSnapshot{
...
override def write(out: DataOutputView): Unit = {
super.write(out)
// write only the classname to avoid Java serialization
out.writeUTF(classOf[Model].getName)
}
override def read(in: DataInputView): Unit = {
super.read(in)
val genericTypeClassname = in.readUTF
try
typeClass = Class.forName(genericTypeClassname, true,
getUserCodeClassLoader).asInstanceOf[Class[Model]]
catch {
...
}
}
...Overall orchestration of the execution is done using a Flink driver, shown in Example 4-6 (complete code available here).
Example 4-6. Flink driver for key-based joins
object ModelServingKeyedJob {
...
// Build execution Graph
def buildGraph(env : StreamExecutionEnvironment) : Unit = {
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.enableCheckpointing(5000)
// Configure Kafka consumer
val dataKafkaProps = new Properties
dataKafkaProps.setProperty("zookeeper.connect",
ModelServingConfiguration.LOCAL_ZOOKEEPER_HOST)
dataKafkaProps.setProperty("bootstrap.servers",
ModelServingConfiguration.LOCAL_KAFKA_BROKER)
dataKafkaProps.setProperty("group.id",
ModelServingConfiguration.DATA_GROUP)
dataKafkaProps.setProperty("auto.offset.reset", "latest")
val modelKafkaProps = new Properties
modelKafkaProps.setProperty("zookeeper.connect",
ModelServingConfiguration.LOCAL_ZOOKEEPER_HOST)
modelKafkaProps.setProperty("bootstrap.servers",
ModelServingConfiguration.LOCAL_KAFKA_BROKER)
modelKafkaProps.setProperty("group.id",
ModelServingConfiguration.MODELS_GROUP)
modelKafkaProps.setProperty("auto.offset.reset", "latest")
// Create a Kafka consumer
val dataConsumer = new FlinkKafkaConsumer010[Array[Byte]](...
val modelConsumer = new FlinkKafkaConsumer010[Array[Byte]](...
// Create input data streams
val modelsStream = env.addSource(modelConsumer)
val dataStream = env.addSource(dataConsumer)
// Read data from streams
val models = modelsStream.map(ModelToServe.fromByteArray(_))
.flatMap(BadDataHandler[ModelToServe]).keyBy(_.dataType)
val data = dataStream.map(DataRecord.fromByteArray(_))
.flatMap(BadDataHandler[WineRecord]).keyBy(_.dataType)
// Merge streams
Data
.connect(models)
.process(DataProcessor())
}
}The workhorse of this implementation is the buildGraph method. It first configures and creates two Kafka consumers, for models and data, and then builds two input data streams from these consumers. It then reads data from both streams and merges them.
The FlinkKafkaConsumer010 class requires the definition of the deserialization schema. Because our messages are protobuf encoded, I treat Kafka messages as binary blobs. To do this, it is necessary to implement the ByteArraySchema class, as shown in Example 4-7, defining encoding and decoding of Kafka data.
Example 4-7. The ByteArraySchema class
class ByteArraySchema extends DeserializationSchema[Array[Byte]]
with SerializationSchema[Array[Byte]] {
override def isEndOfStream(nextElement:Array[Byte]):Boolean = false
override def deserialize(message:Array[Byte]):Array[Byte] = message
override def serialize(element: Array[Byte]): Array[Byte] = element
override def getProducedType: TypeInformation[Array[Byte]] =
TypeExtractor.getForClass(classOf[Array[Byte]])
}Using Partition-Based Joins
Flink’s RichCoFlatMapFunction allows merging of two streams in parallel. A task is split into several parallel instances for execution with each instance processing a subset of the task’s input data. The number of parallel instances of a task is called its parallelism.
When using this API on the partitioned stream, data from each partition is processed by a dedicated Flink executor. Records from the model stream are broadcast to all executors. As Figure 4-3 demonstrates, each partition of the input stream is routed to the corresponding instance of the model server. If the number of partitions of the input stream is less than Flink parallelism, only some of the model server instances will be utilized. Otherwise, some of the model server instances will serve more than one partition.
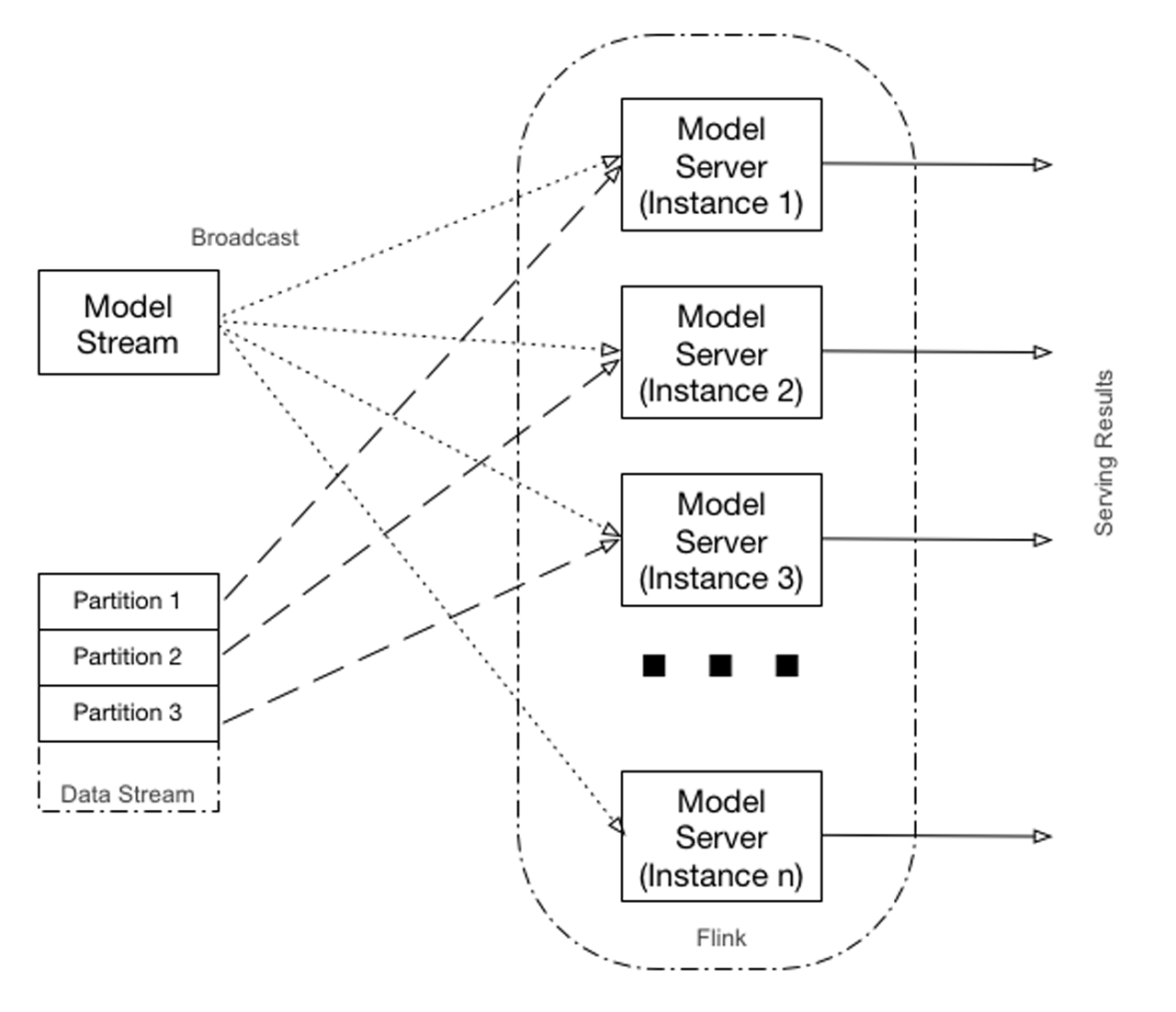
Figure 4-3. Partition-based join
Here are the main characteristics of this approach:
-
The same model can be scored in one of several executors based on the partitioning of the data streams, which means that scaling of Flink (and input data partitioning) leads to better scoring throughput.
-
Because the model stream is broadcast to all model server instances, which operate independently, some race conditions in the model update can exist, meaning that at the point of the model switch, some model jitter (models can be updated at different times in different instances, so for some short period of time different input records can be served by different models) can occur.
Based on these considerations, using global joins is an appropriate approach for the situations when it is necessary to score with one or a few models under heavy data load.
In the heart of this implementation is the DataProcessorMap class, which you can see in action in Example 4-8 (complete code available here).
Example 4-8. The DataProcessMap class
class DataProcessorMap
extends RichCoFlatMapFunction[WineRecord, ModelToServe, Double]
with CheckpointedFunction
with CheckpointedRestoring[List[Option[Model]]] {
...
override def flatMap2(model: ModelToServe, out: Collector[Double]):
Unit = {
import DataProcessorMap._
println(s"New model - $model")
newModel = factories.get(model.modelType) match{
case Some(factory) => factory.create(model)
case _ => None
}
}
override def flatMap1(record: WineRecord, out: Collector[Double]):
Unit = {
// See if we need to update
newModel match {
case Some(model) => {
// Close current model first
currentModel match {
case Some(m) => m.cleanup();
case _ =>
}
// Update model
currentModel = Some(model)
newModel = None
}
case _ =>
}
currentModel match {
case Some(model) => {
val start = System.currentTimeMillis()
val quality = model.score(record.asInstanceOf[AnyVal])
.asInstanceOf[Double]
val duration = System.currentTimeMillis() - start
}
case _ => println("No model available - skipping")
}
}
}This implementation is very similar to the DataProcessor class (Example 4-1). Following are the main differences between the two:
-
The
DataProcessMapclass extendsRichCoFlatMapFunction, whereas theDataProcessorclass extends theCoProcessFunctionclass. -
The method names are different:
flatMap1andflatMap2versusprocessElement1andprocessElement2. But the actual code within the methods is virtually identical.
Similar to the DataProcessor class, this class also implements support for checkpointing of state.
Overall orchestration of the execution is done using a Flink driver, which differs from the previous Flink driver for key-based joins (Example 4-6) only in how streams are delivered to the executors (keyBy versus broadcast) and processed (process versus flatMap) and joined, as shown in Example 4-9 (complete code available here).
Example 4-9. Flink driver for global joins
// Read data from streams val models = modelsStream.map(ModelToServe.fromByteArray(_)) .flatMap(BadDataHandler[ModelToServe]).broadcast val data = dataStream.map(DataRecord.fromByteArray(_)) .flatMap(BadDataHandler[WineRecord]) // Merge streams Data .connect(models) .flatMap(DataProcessorMap())
Although this example uses a single model, you can easily expand it to support multiple models by using a map of models keyed on the data type.
A rich streaming semantic provided by Flink low-level process APIs provides a very powerful platform for manipulating data streams, including their transformation and merging. In this chapter, you have looked at different approaches for implementing proposed architecture using Flink. In Chapter 5, we look at how you can use Beam for solving the same problem.
Get Serving Machine Learning Models now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

