The programmer of the 21st century has a lot to worry about.
For one thing, useful software is far more complex than ever before. No longer is it acceptable to simply, present a simple terminal-based command prompt or a character-based user interface; users now demand rich, graphical user interfaces with all sorts of visual goodies. Data can seldom be structured to fit in flat files in a local filesystem; instead, the use of a relational database is often required to support the query and reporting requirements that computer users have come to depend on, as well as the ongoing transformations that shape and reshape long-lived data. A single computer once sufficed for application deployment, on which data sharing was accomplished using files or the clipboard; now most computers on the planet are wired for networking, and the software deployed on them must not only be network-aware, but must also be ready to adapt to changing network conditions. In short, building software has moved beyond being a craft that can be practiced by skilled individuals in isolation; it has become a group activity, based on ever more sophisticated underlying infrastructure.
Programmers no longer have the luxury of being able to complete an entire project from scratch, using tools that are close to the processor, such as assemblers or C compilers. Few have the time or the patience to write intermediate infrastructure, even for things as simple as an HTTP implementation or an XML parser, much less the skills to tune this infrastructure to acceptable levels of performance and quality. As a result, great emphasis is now placed on reusable code and on reusable components. The operating system plus a few libraries no longer suffices as a toolkit. Today’s programmer, like it or not, relies on code from many different sources that works together correctly and reliably, in support of his applications.
Component software, a development methodology in which independent pieces of code are combined to create application programs, has arisen in response to this trend. By combining components from many sources, programs can be built more quickly and efficiently. However, this technique places new demands on programming tools and the software development process. Reliance on components that were created by untrusted or unknown developers, for example, makes it essential to have stringent control over the execution and verification of code at runtime. In our era of ubiquitous network connectivity, complex component-based software is often updated on-the-fly without local intervention and sometimes maliciously. Ask any virus victim about the necessity of preserving the sanctity of her computers and data, or talk to an unsophisticated computer user about the baffling loss of stability that comes from installing and uninstalling applications on his system, and you will discover that component-based software often contributes as much to the problem as to the solution.
For many years, the business promises of component software and its expected efficiencies were offset by the complexity of combining components from many sources in a safe way. Within the last 10 years, however, we have seen the successful commercialization of virtual execution environments that host managed components . Managed components are simply software parts that can be developed and deployed independently, yet safely coexist within applications. They are “managed” because of their need for a virtual execution environment that provides runtime and execution services. These environments, to match component requirements, focus on presenting an organizational model that is geared towards safe cooperation and collaboration, rather than on exposing the physical resources of the processors and operating systems on which they are implemented.
Virtual execution environments and managed components, such as the ones abstractly portrayed in Figure 1-1, provide advantages to three different software communities: programmers, those who build programming tools and libraries, and those who administer software built to run within them. To programmers using managed components to build complex applications, the presence of tools and libraries translates to less time spent on integration and communications tasks and more productivity. To tool builders such as compiler writers, the presence of supporting infrastructure and a high-definition, carefully specified virtual machine translates to more time available for building tools and less time worrying about infrastructure and interoperability. Finally, administrators and computer users reap the benefits and control that come from using a single runtime infrastructure and packaging model, both of which are independent of processor and operating system specifics.
The ECMA Common Language Infrastructure (CLI) is a standardized specification for a virtual execution environment. It describes a data-driven architecture , in which language-agnostic blobs of data are brought to life as self-assembling, typesafe software systems. The data that drives this process, called metadata , is used by developer tools to describe both the behavior of the software as well as its in-memory characteristics. The CLI execution engine uses this metadata to enable managed components from many sources to be loaded together safely. CLI components coexist under strict control and surveillance, yet they can interact and have direct access to resources that need sharing. It is a model that balances control and flexibility.
Note
ECMA, the European Computer Manufacturers Association, is a standards body that has existed for many years. Besides issuing standards on its own, ECMA also has a strong relationship with ISO, the International Standards Organization, and based on this relationship, the CLI specification has been approved as ISO/IEC 23271:2003, with an accompanying technical report designated as ISO:IEC 23272:2003. The C# standard has also been approved, and has become ISO/IEC 23270:2003.
The CLI specification is available on the web sites mentioned in the Preface, and is also included on the CD that accompanies this book. It consists of five large “partitions” plus documentation for its programming libraries. At the time that the CLI was standardized, a programming language named C# was also standardized as a companion effort. C# exploits most of the features of the CLI, and it is the easy-to-learn, object-oriented language in which we have chosen to implement most of the small examples in this book. Formally, the C# and CLI specifications are independent (although the C# specification does refer to the CLI specification), but practically, both are intertwined, and many people consider C# to be the canonical language for programming CLI components.
Virtual execution in the CLI occurs under the control of its execution engine, which hosts components (as well as code that is not component-based) by interpreting the metadata that describes them at runtime. Code that runs in this way is often referred to as managed code, and it is built using tools and programming languages that produce CLI-compatible executables. There is a carefully-specified chain of events that is used to load metadata from packaging units called assemblies and convert this metadata into executable code that is appropriate for a machine’s processor and operating system. A simplified version of this chain of events is shown schematically in Figure 1-2 and will form the basis of the rest of this book. It is also described in Partition I of the CLI specification in great detail. (Section 8, describing the Common Type System, and section 11, describing the Virtual Execution System, are particularly good background sources.)
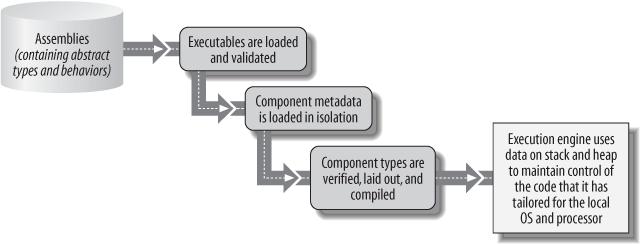
Figure 1-2. Each step in the CLI-loading sequence is driven by metadata annotations computed during the previous step
In some ways, the CLI execution engine is similar to an operating system, since it is a privileged piece of code that provides services (such as loading, isolation, and scheduling) as well as managed resources (such as memory and IO) for code that is executing under its control. Furthermore, in both the CLI and in operating systems, services can either be explicitly requested by programs or else made available as an ambient part of the execution model. (Ambient services are services that are always running within an execution environment. They are important because they define a large part of the runtime computational model for a system.)
In other ways, the CLI resembles the traditional toolchain of compiler, linker, and loader, as it performs in-memory layout, compilation, and symbol resolution. The CLI specification takes pains to describe in detail not only how managed software should work, but also how unmanaged software can coexist safely with managed software, enabling seamless sharing of computing resources and responsibilities. Its combination of system and tool infrastructure is what makes it a unique and powerful new technology for building component-based software.
Behind the CLI specification and execution model are a core set of concepts. These key ideas were folded into the design of the CLI both as abstractions and as concrete techniques that enable developers to organize and partition their code. One way to think of them is as a set of design rules :
Expose all programmatic entities using a unified type system.
Package types into completely self-describing, portable units.
Load types in a way that they can be isolated from each other at runtime, yet share resources.
Resolve intertype dependencies at runtime using a flexible binding mechanism that can take version, culture-specific differences (such as calendars or character encodings), and administrative policy into account.
Represent type behavior in a way that can be verified as typesafe, but do not require all programs to be typesafe.
Perform processor-specific tasks, such as layout and compilation, in a way that can be deferred until the last moment, but do not penalize tools that do these tasks earlier.
Execute code under the control of a privileged execution engine that can provide accountability and enforcement of runtime policy.
Design runtime services to be driven by extensible metadata formats so that they will gracefully accommodate new inventions and future changes.
We’ll touch on a few of the most important ideas here, and revisit them in detail as we progress through the book.
The CLI categorizes the world into types, which programmers use to organize the structure and behavior of the code that they write. The component model used to describe types is powerfully simple: a type describes fields and properties that hold data, as well as methods and events that describe its behavior (all of which will be discussed in detail in Chapter 3). State and behavior can exist at either the instance level, in which components share structure but not identity, or at the type level, in which all instances (within an isolation boundary) share a single copy of the data or method dispatch information. Finally, the component model supports standard object-oriented constructs, such as inheritance, interface-based polymorphism, and constructors.
The structure of a type is captured as metadata that is always available to the execution engine, to programmers, and to other types. Metadata is very important because it enables types from many people, places, and platforms to coexist peacefully, while remaining independent. By default, the CLI loads types only as they are needed; linkages are evaluated, resolved, and compiled on demand. All references within a type to other types are symbolic, which means that they take the form of names that can be resolved at runtime rather than being precomputed addresses or offsets. By relying on symbolic references, sophisticated versioning mechanisms can be constructed, and independent forward-versioning of types can be achieved within the binding logic of the execution engine.
A type can inherit structure and behavior from another type, using classic object-oriented, single-inheritance semantics. All methods and fields of the base type are included in the derived type’s definition, and instances of the derived type can stand in for instances of the base type. Although types may have only one base type, they may additionally implement any number of interfaces. All types extend the base type, System.Object, either directly or through their parents’ lineage.
The CLI component model augments the concepts of field and method by exposing two higher-level constructs for programmers: properties and events. Properties allow types to expose data whose value can be retrieved and set via arbitrary code rather than via direct memory access. From a plumbing perspective, properties are strictly syntactic sugar, since they are represented as methods internally, but from a semantics perspective, properties are a first-class element of a type’s metadata, which translates to more consistent APIs and to better development tools.
Events are used by types to notify external observers of interesting occurrences within their implementations (for example, notification of data becoming available or of internal state changes). To enable external observers to register interest in an event, CLI delegates encapsulate the information necessary to perform a callback. When registering an event callback, a programmer creates one of two kinds of delegate: either a static delegate that
encapsulates a pointer to a static method of a type, or an instance delegate that associates an object reference with a method on which that object will be called back. Delegates are typically passed as arguments to event registration methods; when the type wants to raise an event, it simply performs a callback on its registered delegates.
Types, from a minimalist perspective, are a hierarchal way to organize programming modules using fields to hold data and methods to express behavior. Above this simple, yet complete, model, properties, events, and other constructs provide additional structure with which to build the shared programming libraries and runtime services that distinguish the CLI.
Types in the CLI are built from fields and methods at the lowest level, but how are fields and methods themselves defined? The CLI specification defines a processor-agnostic intermediate language for describing programs, as well as a common type system that provides the basic datatypes for this intermediate language. Together, these two entities form an abstract computing model. The specification embellishes this abstract model with rules that describe how it can be transformed into native instruction streams and memory references; these transformations are designed to be efficient and to capture and accurately represent the semantics of many different programming languages. The intermediate language, its types, and the rules for transformation form a broad, language-independent way to represent programs.
The intermediate language defined in the CLI specification is called the Common Intermediate Language (CIL). It has a rich set of opcodes, not tied to any existing hardware architecture, which drive a simple-to-understand abstract stack machine. Likewise, the Common Type System (CTS), defines the base set of types that embody standardized cross-language interoperability. To fully realize the benefits of this language-agnostic world, high-level compilers need to agree on both the CIL instruction set and its matching set of datatypes. Without this agreement, different languages might choose different mappings; for example, how big is a C# int, and how does it relate to a Visual Basic Integer? Is that the same as a C++ long? By matching the instruction set to the types, these choices are made considerably simpler; choices about exactly which instructions and types to use are, of course, in the hands of compiler implementers, but the presence of a well-thought-out specification means that making these choices is considerably more straightforward. By using this approach, the resulting code can interoperate with code and frameworks written in other languages, which results in more effective reuse. Chapter 3 discusses the CLI type system in great detail, while Chapter 5 covers CIL and how it is converted into native instructions.
With its type system and its abstract computational model, the CLI enables the idea that software components, written at different times by different parties, can be verified, loaded, and used together to build applications. Within the CLI, individual components are packaged into units called assemblies , which can be dynamically loaded into the execution engine on demand either from local disk, across a network, or even created on-the-fly under program control.
Assemblies define the component model semantics for the CLI. Types cannot exist outside of assemblies; conversely, the assembly is the only mechanism through which types can be loaded into the CLI. Assemblies are in turn made up of one or more modules — a packaging subunit in which information resides—plus a chunk of metadata describing the assembly called the assembly manifest . While assemblies can be made up of multiple modules, most often an assembly will consist of one module.
To ensure that assemblies aren’t tampered with between the time they were compiled and the time they are loaded, each assembly can be signed using a cryptographic key pair and a hash of the entire assembly, and this signature can be placed into the manifest. The signature is respected by the execution engine, and ensures that assemblies won’t be tampered with and that damaged assemblies won’t be loaded. If a hash generated at runtime from the assembly doesn’t match the hash contained in the assembly’s manifest, the runtime will refuse to load the assembly and raise an exception before the potentially bad code has a chance to do anything.
In many ways, assemblies are to the CLI what shared libraries or DLLs are to an operating system: a means of bounding and identifying code that belongs together. Thanks to the full-fidelity metadata and symbolic binding approach found in the CLI, each component can be loaded, versioned, and executed independently of its neighbors, even if they depend on each other. This is crucial, since platforms, applications, libraries, and hardware change over time. Solutions built from components should continue to work as these components change. Assemblies are discussed in Chapter 3 and Chapter 4.
As important as the ability to group code together into components is the ability to load these components in a way that they can work together and yet be protected from malicious or buggy code that might exist in other components. Operating systems often achieve isolation by erecting protected address spaces and providing communication mechanisms that can bridge them; the address spaces provide protected boundaries, while the communications mechanisms provide channels for cooperation. The CLI has similar constructs for isolating executing code, which consist of application domains and support for remoting .
Assemblies are always loaded within the context of an application domain, and the types that result are scoped by their application domain. For example, static variables defined in an assembly are allocated and stored within the application domain. If the same assembly is loaded into three different domains, three different copies of the type’s data for that assembly are allocated. In essence, application domains are “lightweight address spaces,” and the CLI enforces similar restrictions on passing data between domains as operating systems do between address spaces. Types that wish to communicate across domain boundaries must use special communications channels and behave according to specific rules.
This technique, referred to as remoting, can be used to communicate between application domains running on different physical computers (and running different operating systems on different processors). Just as often, the remoting mechanisms are used to isolate components within domains that exist in a single process on a single machine. Components that wish to participate in remoting can be Serializable, in which case they can be passed from domain to domain, or alternatively can extend the System.MarshalByRefObject type, in which case they can communicate using proxy objects that act as relays. Application domains, remoting, and the details of loading will be covered in Chapter 4.
Because all types and their code live within assemblies, there needs to be a well-defined set of rules describing how the execution engine will discover and use assemblies when their types are needed. Assembly names are formed from a standard set of elements, which consist of an assembly base name, a version number, a culture (for internationalization), and a hash of the public key that represents the distributor of the assembly. Compound names ensure that software built from assemblies will accommodate version changes gracefully. When compiled, each assembly also carries references to the compound names of other assemblies that it was compiled against and remembers the versioning information for each of those assemblies. As a result, when loaded, assemblies request very specific (or semantically-compatible) versions of the assemblies on which they depend. The binding policy used to satisfy these requests can be influenced by configuration settings but is never ignored.
Assemblies are normally found in one of two places: in a machine-wide cache known as the Global Assembly Cache (GAC) or on a URL-based search path. The GAC is effectively a per-machine database of assemblies, each uniquely identified by its four-part name. The GAC can be, but doesn’t have to be, a filesystem directory; a CLI implementation must be able to put multiple versions of the same assembly into the GAC and track them. The search path is essentially a collection of URLs (usually filesystem directories) that are searched when an assembly is requested for loading. The loading process and how it can be implemented is detailed in Chapter 4.
The execution model described by the CLI implies that the act of compiling high-level type descriptions should be separated from the act of turning these type descriptions into processor-specific code and memory structures. This separation introduces a number of important advantages to the computing model, such as the ability to easily adapt code to new operating systems and processors after the fact, as well as the ability to independently version components from many different sources. It also introduces new challenges. For example, because all types are represented using CIL and the CTS, all types must be transformed into native code and memory structures before they can be used; in essence, the entire application must always be recompiled before it can be run, which can be a very expensive proposition.
To amortize the cost of transforming CIL into native code, both in terms of time taken to load and in terms of memory required, types in a CLI-based application are typically not loaded until they are needed, and once a type is loaded, its methods are not translated until they are needed for execution. This process of deferring layout and code generation is referred to as just-in-time (JIT) compilation . The CLI does not absolutely require last-minute JIT compilation to occur, but deferred loading and compilation are implied at some point in an application’s lifecycle, to convert the CIL into native code. One can imagine an installation utility that might perform compilation, for example. The way that JIT compilation can be implemented to conform to the CLI is discussed in Chapter 5.
The most important reason that JIT compilation is built into the CLI execution model is not obvious. The transformation from abstract component to running native code, under the control of the execution engine’s own loader and compiler is what enables the execution engine to maintain control at runtime and run code efficiently, even when calling back and forth between code written in C++ and code written in a managed language. The traditional pipeline of compilation, linking and loading, continues to exist in the CLI, but as we have seen, each toolchain element must make heavy use of clever techniques (such as caching) because deferred use leads to higher runtime costs. These higher costs are well worth bearing because deferral also results in comprehensive control over the behavior of executing components.
Since execution in the CLI is based on the incremental loading of types, and since all types are defined using a platform-neutral intermediate language, the CLI execution engine is constantly compiling and adding new behavior as it runs. CIL is designed to be verifiably typesafe, and since compilation into native code is performed under the control of the privileged execution engine, typesafety can be verified before a new type is given a chance to run. Security policy can also be checked and applied at the time that CIL is transformed into native code, which means that security checks can be injected directly into the code, to be executed on behalf of the system while methods are executing. In short, by deferring the loading, verification, and compilation of components until runtime, the CLI can enforce true managed execution .
Type loading is the trigger that causes the CLI’s toolchain to be engaged at runtime. As part of this loading process, the CLI compiles, assembles, links, validates executable format and program metadata, verifies typesafety, and finally even manages runtime resources, such as memory and processor cycles, on behalf of the components running under its control. The tying together of all of these stages has led the CLI to include infrastructure for name binding, memory layout, compilation and patching, isolation, synchronization, and symbol resolution. Since the invocation of these elements is often deferred until the last possible moment, the execution engine enjoys high-fidelity control over loading and execution policies, the organization of memory, the code that is generated, and the way in which the code interacts with the underlying platform and operating system.
Deferred compilation, linking, and loading facilitate better portability both across target platforms and across version changes. By deferring ordering and alignment decisions, address and offset computation, choice of processor instructions, calling conventions, and of course, linkage to the platform’s own services, assemblies can be much more forward-compatible. A deferred process, driven by well-defined metadata and policy, is very robust.
The execution engine that interprets this metadata is trusted system code, and because of this, security and stability are also enhanced by late loading. Every assembly can have a set of permissions associated with it that define what the assembly is permitted to do. When code in the assembly attempts to execute a sensitive operation (such as attempting to read from or write to a file, or attempting to use the network), the CLI can look at the call stack and walk it to determine if all of the code currently in scope has appropriate rights—if code on the stack doesn’t have correct permissions, the operation can be rejected, and an exception can be thrown. (Exceptions are another mechanism that enables simpler interactions between components; the CLI was designed to not only support a wide range of exception semantics within the execution engine, but also to integrate tightly with exception signaling from the underlying platform.) Managed execution is discussed at length in Chapter 6 and Chapter 7.
CLI components are self-descriptive. A CLI component contains definitions for every member contained within it, and the guaranteed runtime availability of this information is one factor that helps make virtualized execution highly adaptable. Every type, every method, every field, every single parameter on every single method call must be fully described, and the description must be stored within the assembly. Since the CLI defers all sorts of linkages until the moment they are needed, tools and programs that wish to manipulate components or create new ones by working with metadata have a tremendous amount of flexibility. The same kinds of tricks played by the CLI can be used by code built on top of the CLI, which is a windfall for tools and runtime services.
To get information about types, programmers of the CLI can use the reflection services of the execution engine. Reflection provides the ability to examine compile-time information at runtime. For example, given a managed component, developers can discover the structure of the type, including its constructors, fields, methods, properties, events, interfaces, and inheritance relationships. Perhaps more importantly, developers can also add their own metadata to the description, using what are called custom attributes .
Not only is compile-time information available, but it can be used to manipulate live instances. Developers can use reflection to reach into types, discover their structure, and manipulate the contents of the types based on that structural information. For methods, the same is true; developers can invoke methods dynamically at runtime. The capabilities of this metadata-driven style of programming, and how it can be implemented, are touched on in Chapter 3, and examined in more detail in Chapter 8.
Get Shared Source CLI Essentials now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

