May 2025
Intermediate to advanced
278 pages
4h 26m
Japanese
この作品はAIを使って翻訳されている。ご意見、ご感想をお待ちしている:translation-feedback@oreilly.com
説明は真空の中では存在し得ない。AIがなぜそのように行動したのかを理解するために、私たち自身、同僚、監査役、コンシューマによって消費され、利用され、行動される。説明可能性(とインタプリタビリティ)がなければ、マシンラーニング(ML)は情報と予測の一方通行になってしまう。あるパラグラフをある言語から別の言語に翻訳するなど、MLが驚異的なことをするのを目にすることはあっても、テクノロジーを明確に信頼することは稀である。
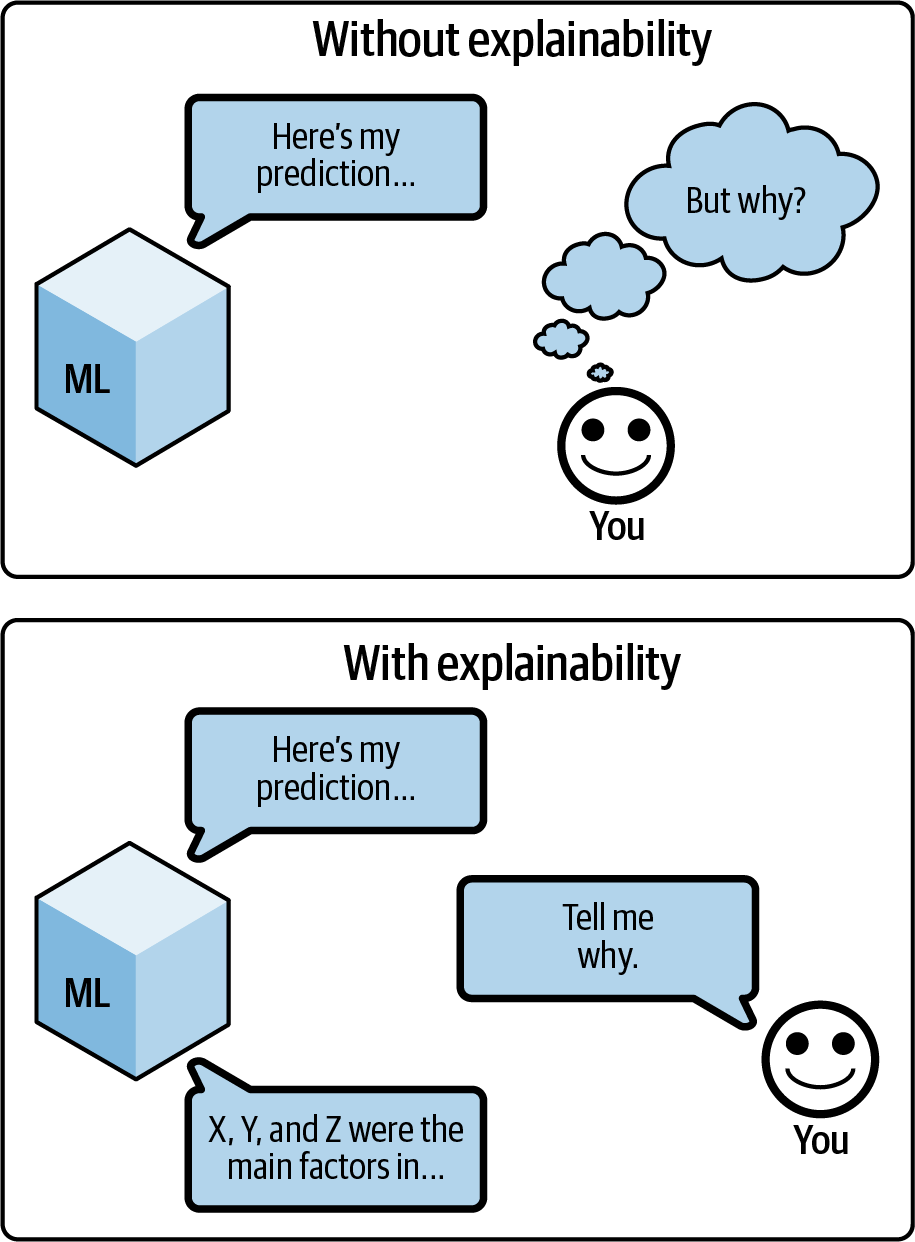
基本的に、私たちは使用するすべてのAIと協力関係にある。マシン学習をあなたの同僚に例えてみよう。この同僚が素晴らしい仕事をしたとしても、私たちが彼らにタスクを実行するように頼んだとき、彼らは別の部屋に行ってしまい、答えを持って戻ってきたかと思うと、またすぐに出て行ってしまい、私たちの質問に答えたり、私たちが言ったことに答えたりすることはなかったとしたら、一緒に仕事をするのは難しいと感じるだろう!この無言の同僚問題は、図7-1のように、MLシステムとユーザの間で双方向の対話を始めることによって、説明可能性が解決しようとするものである。しかし、この対話は、説明可能性がいかに斬新であるかを考えると、非常に限定的なものである。
この章では、様々なMLコンシューマグループのニーズと、それぞれのグループに最適な「説明可能なAI(XAI)」を設計する際に留意すべき点を検討する。また、どのように説明を表示するか、そして、異なるタイプのビジュアライゼーション間のトレードオフを探る。どんな説明も完璧ではないので、説明がどのように誤解されるかという一般的な落とし穴や、これらの問題を軽減するために説明可能性を先回りして設計する方法についても議論する。最後に、説明が作成され伝達された後に何が起こるのか、説明の後に取られる行動にも踏み込んで議論する。
第2章では、、誰が説明を消費するのかについて述べた:MLの実務者、可観測性、エンドユーザである。これらのグループはそれぞれ説明に対するニーズが異なり、マシン学習に関する知識のレベルも異なるので、彼らをすべて同じように扱うことはできない。これらのグループをよりよく理解するために、専門知識と意図の観点から分類することができる。専門知識とは、MLそのものがどのように動作するか、MLが動作する広範な環境、あるいはMLの入力特徴(or推論)に対する付加的な要因のことである。意図とは、説明を受けたコンシューマがどのような反応を示すかによって定義される。
専門知識には一般的に3つのタイプがある:
Read now
Unlock full access






