Chapter 20. Spark Streaming Sinks
After acquiring data through a source represented as a DStream and applying a series of transformations using the DStream API to implement our business logic, we would want to inspect, save, or produce that result to an external system.
As we recall from Chapter 2, in our general streaming model, we call the component in charge of externalizing the data from the streaming process a sink. In Spark Streaming, sinks are implemented using the so-called output operations.
In this chapter, we are going to explore the capabilities and modalities of Spark Streaming to produce data to external systems through these output operations.
Output Operations
Output operations play a crucial role in every Spark Streaming application. They are required to trigger the computations over the DStream and, at the same time, they provide access to the resulting data through a programmable interface.
In Figure 20-1 we illustrate a generic Spark Streaming job that takes two streams as input, transforms one of them, and then joins them together before writing the result to a database. At execution time, the chain of DStream transformations that end on that output operation becomes a Spark job.
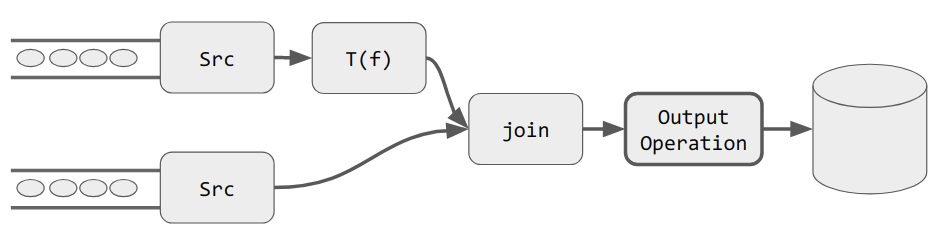
Figure 20-1. A Spark Streaming job
This job is attached to the Spark Streaming scheduler. In turn, the scheduler triggers the execution of the defined job at each batch interval, ...
Get Stream Processing with Apache Spark now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

