Chapter 3.
Learning HTTP
In the previous chapter, we went through a few examples of HTTP transactions and outlined the structure that all HTTP follows. For the most part, all web software will use an exchange similar to the HTTP we showed you in Chapter 2, Demystifying the Browser. But now it's time to teach you more about HTTP. Chapter 2 was like the “Spanish for Travelers” phrasebook that you got for your trip to Madrid; this chapter is the textbook for Spanish 101, required reading if you want course credit.
HTTP is defined by the HTTP specification, distributed by the World Wide Web Consortium (W3C) at www.w3.org. If you are writing commercial-quality HTTP applications, you should go directly to the spec, since it defines which features need to be supported for HTTP compliance. However, reading the spec is a tedious and often unpleasant experience, and readers of this book are assumed to be more casual writers of HTTP clients, so we've pared it down a bit to make HTTP more accessible for the spec-wary. This chapter includes:
- Review of the structure of HTTP transactions. This section also serves as a sort of road map to the rest of the chapter.
- Discussion of the request methods clients may use. Beyond GET, HEAD, and POST, we also give examples of the PUT, DELETE, TRACE, and OPTIONS methods.
- Summary of differences between various versions of HTTP. Clients and servers must declare which version of HTTP they use. For the most part, what you'll see is HTTP 1.0, but at least you'll know what that means. We also cover HTTP 1.1, the newest version of HTTP to date.
- Listing of server response codes, and discussion of the more common codes. These codes are the first indication of what to do with the server's response (if any), so robust client programs should be prepared to intercept them and interpret them properly.
- Coverage of HTTP headers for both clients and servers. Headers give clients the opportunity to declare who they are and what they want, and they give servers the chance to tell clients what to expect.
This is one of the longest chapters in this book, and no doubt you won't read it all in one sitting. Furthermore, if you use LWP, then you can go pretty far without knowing more than a superficial amount of HTTP. But it's all information you should know, so we recommend that you keep coming back to it. Although a few key phrases will help you get around town, fluency becomes very useful when you find yourself lost in the outskirts of the city.
Structure of an HTTP Transaction
All HTTP transactions follow the same general format, as shown in Figure 3-1.
Figure 3-1.
Structure of HTTP transactions
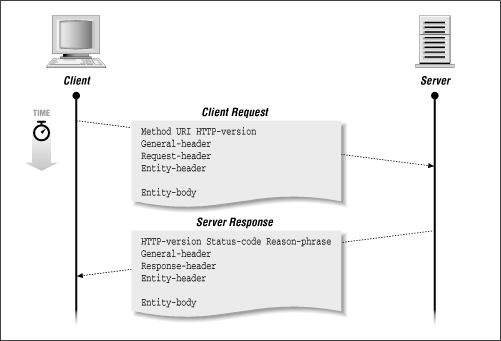
HTTP is a simple stateless protocol, in which the client makes a request, the server responds, and the transaction is then finished. The client initiates the transaction as follows:
- First, the client contacts the server at a designated port number (by default, 80). Then it sends a document request by specifying an HTTP command (called a method), followed by a document address and an HTTP version number. For example:
GET /index.html HTTP/1.0
Here we use the GET method to request the document /index.html using version 1.0 of HTTP. Although the most common request method is the GET method, there is also a handful of other methods that are supported by HTTP, and essentially define the scope and purpose of the transaction. In this chapter, we talk about each of the commonly used client request methods, and show you examples of their use.
There are three versions of HTTP: 0.9, 1.0, and 1.1. At this writing, most clients and servers conform to HTTP 1.0. But HTTP 1.1 is on the horizon, and, for reasons of backward compatibility, HTTP 0.9 is still honored. We will discuss each version of HTTP and the major differences between them.
- Next, the client sends optional header information to inform the server of the client's configuration and document preference. All header information is given line by line, each line with a header name and value. For example, a client can send its name and version number, or specify document preferences:[1]
User-Agent: Mozilla/1.1N (Macintosh; I; 68K) Accept: */* Accept: image/gif Accept: image/x-xbitmap Accept: image/jpeg
To end the header section, the client sends a blank line.
There are many headers in HTTP. We will list all the valid headers in this chapter, but give special attention to several groupings of headers that may come in especially handy. Appendix A contains a more complete listing of HTTP headers.
- When applicable, the client sends the data portion of the request. This data is often used by CGI programs via the POST method, or used to supply document information using the PUT method. These methods are discussed later in this chapter.
The server responds as follows:
- The server replies with a status line with the following three fields: the HTTP version, a status code, and description of the status. For example:
HTTP/1.0 200 OK
This indicates that the server uses version 1.0 of HTTP in its response, and a status code of 200 indicates that the client's request was successful and the requested data will be supplied after the headers.
We will give a listing of each of the status codes supported by HTTP, along with a more detailed discussion of the status codes you are most likely to encounter.
- The server supplies header information to tell the client about itself and the requested document. For example:
Date: Saturday, 20-May-95 03:25:12 GMT Server: NCSA/1.3 MIME-version: 1.0 Content-type: text/html Last-modified: Wednesday, 14-Mar-95 18:15:23 GMT Content-length: 1029
The header is terminated with a blank line.
- If the client's request is successful, the requested data is sent. This data may be a copy of a file, or the response from a CGI program. If the client's request could not be fulfilled, the data may be a human-readable explanation of why the server couldn't fulfill the request.
Given this structure, a few questions come to mind:
- What request methods can a client use?
- What versions of HTTP are available?
- What headers can a client supply?
- What sort of response codes can you expect from a server, and what do you do with them?
- What headers can you expect the server to return, and what do you do with them?
We'll try to answer each of these questions in the remainder of this chapter, in approximate order. The exception to this order is client and server headers, which are discussed together, and discussed last. Many headers are shared by both clients and servers, so it didn't make sense to cover them twice; and the use of headers for both requests and responses is so closely intertwined in some cases that it seemed best to present it this way.
Client Request Methods
A client request method is a “command” or “request” that a web client issues to a server. You can think of the method as the declaration of what the client's intentions are. There are exceptions, of course, but here are some generalizations:
- You can think of a GET request as meaning that you just want to retrieve a document.
- A HEAD request means that you just want some information about the document, but don't need the document itself.
- A POST request says that you're providing some information of your own (generally used for fill-in forms).
- PUT is used to provide a new or replacement document to be stored on the server.
- DELETE is used to remove a document on the server.
- TRACE asks that proxies declare themselves in the headers, so the client can learn the path that the document took (and thus determine where something might have been garbled or lost).
- OPTIONS is used when the client wants to know what other methods can be used for that document (or for the server at large).
We'll show some examples of each of these seven methods. Other HTTP methods that you may see (LINK, UNLINK, and PATCH) are less clearly defined, so we don't discuss them in this chapter. See the HTTP specification for more information on those methods.
GET: Retrieve a Document
The GET method requests a document from a specific location on the server. This is the main method used for document retrieval. The response to a GET request can be generated by the server in many ways. For example, the response could come from:
- A file accessible by the web server
- The output of a CGI script or server language like NSAPI or ISAPI
- The result of a server computation, like real-time decompression of online files
- Information obtained from a hardware device, such as a video camera
In this book, we are more concerned about the data returned by a request than with the way the server generated the data. From a client's point of view, the server is a black box that takes in a method, URL, headers, and entity-body as input and generates output that clients process.
After the client uses the GET method in its request, the server responds with a status line, headers, and data requested by the client. If the server cannot process the request, due to an error or lack of authorization, the server usually sends an explanation in the entity-body of the response.
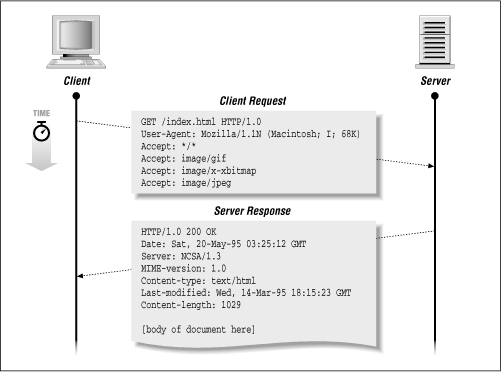
Figure 3-2 shows an example of a successful request. The client sends:
GET /index.html HTTP/1.0 User-Agent: Mozilla/1.1N (Macintosh; I; 68K) Accept: */* Accept: image/gif Accept: image/x-xbitmap Accept: image/jpeg
The server responds with:
HTTP/1.0 200 OK Date: Sat, 20-May-95 03:25:12 GMT Server: NCSA/1.3
MIME-version: 1.0
Content-type: text/html
Last-modified: Wed, 14-Mar-95 18:15:23 GMT
Content-length: 1029
(body of document here)
HEAD: Retrieve Header Information
The HEAD method is functionally like GET, except that the server will reply with a response line and headers, but no entity-body. The headers returned by the server with the HEAD method should be exactly the same as the headers returned with a GET request. This method is often used by web clients to verify the document's existence or properties (like Content-length or Content-type), but the client has no intention of retrieving the document in the transaction. Many applications exist for the HEAD method, which make it possible to retrieve:
- Modification time of a document for caching purposes
- Size of the document, to do page layout, to estimate arrival time, or to skip the document and retrieve a smaller version of the document
- Type of the document, to allow the client to examine only documents of a certain type
- Type of server, to allow customized server queries
It is important to note that most of the header information provided by a server is optional, and may not be given by all servers. A good design in web clients is to allow flexibility in the server response and to take default actions when desired header information is not given by the server.
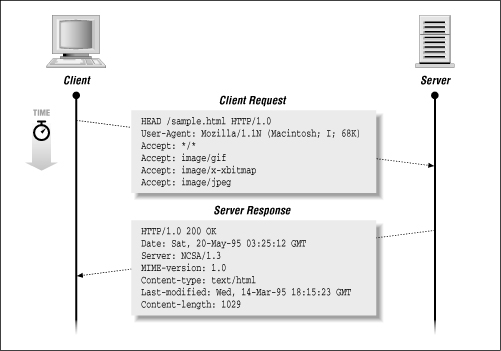
Figure 3-3 shows an example HTTP transaction using the HEAD method. The client sends:
HEAD /sample.html HTTP/1.0 User-Agent: Mozilla/1.1N (Macintosh; I; 68K) Accept: */* Accept: image/gif Accept: image/x-xbitmap Accept: image/jpeg
The server responds with:
HTTP/1.0 200 OK Date: Sat, 20-May-95 03:25:12 GMT Server: NCSA/1.3 MIME-version: 1.0 Content-type: text/html Last-modified: Wed, 14-Mar-95 18:15:23 GMT Content-length: 1029
(Note that the server does not return any data after the headers.)
POST: Send Data to the Server
The POST method allows the client to specify data to be sent to some data-handling program that the server can access. It can be used for many applications. For example, POST could be used to provide input for:
- CGI programs
- Gateways to network services, like an NNTP server
- Command-line interface programs
- Annotation of documents on the server
- Database operations
In practice, POST is used with CGI programs that happen to interface with other resources like network services and command line programs. In the future, POST may be directly interfaced with a wider variety of server resources.
In a POST request, the data sent to the server is in the entity-body of the client's request. After the server processes the POST request and headers, it may pass the entity-body to another program (specified by the URL) for processing. In some cases, a server's custom Application Programming Interface (API) may handle the data, instead of a program external to the server.
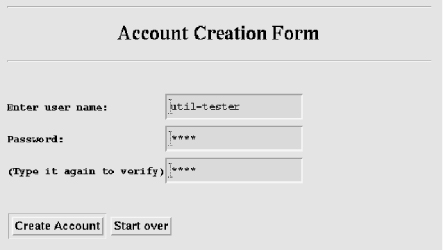
POST requests should be accompanied by a Content-type header, describing the format of the client's entity-body. The most commonly used format with POST is the URL-encoding scheme used for CGI applications. It allows form data to be translated into a list of variables and values. Browsers that support forms send the data in URL-encoded format. For example, given the HTML form of:
<title>Create New Account</title>
<center><hr><h1>Account Creation Form</h2><hr></center>
<form method=“post” action=“/cgi-bin/create.pl”>
<pre>
<b>
Enter user name:<INPUT NAME=“user” MAXLENGTH=“20” SIZE=“20”>
Password: <INPUT NAME=“pass1” TYPE=“password”
MAXLENGTH=“20” SIZE=“20”>
(Type it again to verify) <INPUT NAME=“pass2” TYPE=“password”
MAXLENGTH=“20” SIZE=“20”>
</b>
</pre>
<INPUT TYPE=“submit” VALUE=“Create account”>
<input type=“reset” value=“Start over”>
</form>
the browser view looks like that in Figure 3-4.
Let's insert some values and submit the form. As the username, “util-tester” was entered. For the password, “1234” was entered (twice). Upon submission, the client sends:
POST /cgi-bin/create.pl HTTP/1.0 Referer: file:/tmp/create.html User-Agent: Mozilla/1.1N (X11; I; SunOS 5.3 sun4m) Accept: */* Accept: image/gif Accept: image/x-xbitmap Accept: image/jpeg Content-type: application/x-www-form-urlencoded Content-length: 38 user=util-tester&pass1=1234&pass2=1234
Note that the variables defined in the form have been associated with the values entered by the user. This information is passed to the server in URL-encoded format, described below.
The server determines that the client used a POST method, processes the URL, executes the program associated with the URL, and pipes the client's entity-body to a program specified at the address of /cgi-bin/create.pl. The server maps this “web address” to the location of a program, usually in a designated CGI directory (in this case, /cgi-bin). The CGI program then interprets the input as CGI data, decodes the entity body, processes it, and returns a response entity-body to the client:
HTTP/1.0 200 OK Date: Sat, 20-May-95 03:25:12 GMT Server: NCSA/1.3 MIME-version: 1.0 Content-type: text/html Last-modified: Wed, 14-Mar-95 18:15:23 GMT Content-length: 95 <title>User Created</title> <h1>The util-tester account has been created</h2>
URL-encoded format
Using the POST method is not the only way that forms send information. Forms can also use the GET method, and append the URL-encoded data to the URL, following a question mark. If the <FORM> tag had contained the line method=“get” instead of method=“post”, the request would have looked like this:
GET /cgi-bin/create.pl?user=util-tester&pass1=1234&pass2=1234 HTTP/1.0 Referer: file:/tmp/create.html User-Agent: Mozilla/1.1N (X11; I; SunOS 5.3 sun4m) Accept: */* Accept: image/gif Accept: image/x-xbitmap Accept: image/jpeg
This is one reason that the data sent by a CGI program is in a special format: since it can be appended to the URL itself, it cannot contain special characters such as spaces, newlines, etc. For that reason, it is called URL-encoded.
The URL-encoded format, identified with a Content-type of application/x-www-form-urlencoded format by clients, is composed of a single line with variable names and values concatenated together. The variable and value are separated by an equal sign (=), and each variable/value pair is separated by an ampersand symbol (&). In the example given above, there are three variables: user, pass1, and pass2. The values (respectively) are: util-tester, 1234, and 1234. The encoding looks like this:
user=util-tester&pass1=1234&pass2=1234
When the client wants to send characters that normally have special meanings, like the ampersand and equal sign, the client replaces the characters with a percent sign (%) followed by an ASCII value in hexadecimal (base 16). This removes ambiguity when a special character is used. The only exception, however, is the space character (ASCII 32), which can be encoded as a plus sign (+) as well as %20. Appendix B, Reference Tables, contains a listing of all the ASCII characters and their CGI representations.
When the server retrieves information from a form, the server passes it to a CGI program, which then decodes it from URL-encoded format to retrieve the values entered by the user.
File uploads with POST
POST isn't limited to the application/x-www-form-urlencoded content type. For example, consider the following HTML:
<form method=“post” action=“post.pl” enctype=“multipart/form-data”> Enter a file to upload:<br> <input name=“thefile” type=“file”><br> <input name=“done” type=“submit”> </form>
This form allows the user to select a file and upload it to the server. Notice that the <form> tag contains an enctype attribute, specifying an encoding type of multipart/form-data instead of the default, application/x-www-form-urlencoded. This encoding type will be used by the browser as the content type when the form is submitted. As an example, suppose I create a file called hi.txt with the contents of “hi there” and put it in c:/temp/. I use the HTML form to include the file and then hit the submit button. My browser sends this:
POST /cgi-bin/post.pl HTTP/1.0 Referer: http://hypothetical.ora.com/clinton/upload.html Connection: Keep-Alive User-Agent: Mozilla/3.01Gold (WinNT; U) Host: hypothetical.ora.com Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */* Content-type: multipart/form-data; boundary=---------------------------11512135131576 Content-Length: 313 -----------------------------11512135131576 Content-Disposition: form-data; name=“done” Submit Query -----------------------------11512135131576 Content-Disposition: form-data; name=“thefile”; filename=“c:\temp\hi.txt” Content-Type: text/plain hi there -----------------------------11512135131576--
The entity-body of the request is a multipart Multipurpose Internet Mail Extensions (MIME) message. See RFC 1867 for more details.
PUT: Store the Entity-Body at the URL
When a client uses the PUT method, it requests that the included entity-body should be stored on the server at the requested URL. With HTML editors, it is possible to publish documents onto the server with a PUT method. Revisiting the PUT example in Chapter 2, we see an HTML editor with some sample HTML in the editor (see Figure 3-5).
The user saves the document in C:/temp/example.html and publishes it to http://publish.ora.com/ (see Figure 3-6).
Figure 3-6.
Publishing the document
When the user presses the OK button, the client contacts publish.ora.com at port 80 and then sends:
PUT /example.html HTTP/1.0 Connection: Keep-Alive User-Agent: Mozilla/3.0Gold (WinNT; I) Pragma: no-cache Host: publish.ora.com Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */* Content-Length: 307 <!DOCTYPE HTML PUBLIC “-//W3C//DTD HTML 3.2//EN”> <HTML> <HEAD> <TITLE></TITLE> <META NAME=“Author” CONTENT=“”> <META NAME=“GENERATOR” CONTENT=“Mozilla/3.0Gold (WinNT; I) [Netscape]”> </HEAD> <BODY> <H2>This is a header</H2> <P>This is a simple html document.</P> </BODY> </HTML>
The server stores the client's entity-body at /example.html and then responds with:
HTTP/1.0 201 Created Date: Fri, 04 Oct 1996 14:31:51 GMT Server: HypotheticalPublish/1.0 Content-type: text/html Content-length: 30 <h1>The file was created.</h2>
You might have noticed that there isn't a Content-type header sent with the browser's request in this example. It's bad style to omit the Content-type header. The originator of the information should describe what content type the information is. Other applications, like AOLpress for example, include a Content-type header when publishing data with PUT.
In practice, a web server may request authorization from the client. Most webmasters won't allow any arbitrary client to publish documents on the server. When prompted with an “authorization denied” response code, the browser will typically ask the user to enter relevant authorization information. After receiving the information from the user, the browser retransmits the request with additional headers that describe the authorization information.
DELETE: Remove URL
Since PUT creates new URLs on the server, it seems appropriate to have a mechanism to delete URLs as well. The DELETE method works as you would think it would.
A client request might read:
DELETE /images/logo22.gif HTTP/1.1
The server responds with a success code upon success:
HTTP/1.0 200 OK Date: Fri, 04 Oct 1996 14:31:51 GMT Server: HypotheticalPublish/1.0 Content-type: text/html Content-length: 21 <h1>URL deleted.</h2>
Needless to say, any server that supports the DELETE method is likely to request authorization before carrying through with the request.
TRACE: View the Client's Message Through the Request Chain
The TRACE method allows a programmer to see how the client's message is modified as it passes through a series of proxy servers. The recipient of a TRACE method echoes the HTTP request headers back to the client. When the TRACE method is used with the Max-Forwards and Via headers, a client can determine the chain of intermediate proxy servers between the original client and web server. The Max-Forwards request header specifies the number of intermediate proxy servers allowed to pass the request. Each proxy server decrements the Max-Forwards value and appends its HTTP version number and hostname to the Via header. A proxy server that receives a Max-Forwards value of 0 returns the client's HTTP headers as an entity-body with the Content-type of message/http. This feature resembles traceroute, a UNIX program used to identify routers between two machines in an IP-based network. HTTP clients do not send an entity-body when issuing a TRACE request.
Figure 3-7 shows the progress of a TRACE request. After the client makes the request, the first proxy server receives the request, decrements the Max-Forwards value by one, adds itself to a Via header, and forwards it to the second proxy server. The second proxy server receives the request, adds itself to the Via header, and sends the request back, since Max-Forwards is now 0 (zero).
OPTIONS: Request Other Options Available for the URL

When a client request contains the OPTIONS method, it requests a list of options for a particular resource on the server. The client can specify a URL for the OPTIONS method, or an asterisk (*) to refer to the entire server. The server then responds with a list of request methods or other options that are valid for the requested resource, using the Allow header for an individual resource, or the Public header for the entire server. Figure 3-8 shows an example of the OPTIONS method in action.
Figure 3-8.
An OPTIONS request
Versions of HTTP
On the same line where the client declares its method, it also declares the URL and the version of HTTP that it conforms to. We've already discussed the available request methods, and we assume that you're already familiar with the URL. But what about the HTTP version number? For example:
GET /products/toothpaste/index.html HTTP/1.0
In this example, the client uses HTTP version 1.0.
In the server's response, the server also declares the HTTP version:
HTTP/1.0 200 OK
By specifying the version number in both the client request and server response, the client and server can communicate on a common denominator, or in the worst case scenario, recognize that the transaction is not possible due to version conflicts. (For example, an HTTP/1.0 client might have a problem communicating with an HTTP/0.9 server.) If a server is capable of understanding a version of HTTP higher than 1.0, it should still be able to reply with a format that HTTP/1.0 clients can understand. Likewise, clients that understand a superset of a server's HTTP should send requests compliant with the server's version of HTTP.
While there are similarities among the different versions of HTTP, there are many differences, both subtle and glaring. Much of this discussion may not make sense to you if you aren't already familiar with HTTP headers (which are discussed at the end of this chapter). Still, let's go over some of the highlights.
HTTP 0.9
Version 0.9 is the simplest instance of the HTTP protocol. Under HTTP 0.9, there's only one way a client can request something, and only one way a server responds. The web client connects to a server at port 80 and specifies a method and document path, as follows:
GET /hello.html
The server then returns the entity-body for /hello.html and closes the TCP connection. If the document doesn't exist, the server just sends nothing, and the web browser will just display . . . nothing. There is no way for the server to indicate whether the document is empty or whether it doesn't exist at all. HTTP 0.9 includes no headers, version numbers, nor any opportunity for the server to include any information other than the requested entity-body itself. You can't get much simpler than this.
Since there are no headers, HTTP 0.9 doesn't have any notion of media types, so there's no need for the client or server to communicate document preferences or properties. Due to the lack of media types, the HTTP 0.9 world was completely text-based. HTTP 1.0 addressed this limitation with the addition of media types.
In practice, there is no longer any HTTP 0.9 software currently in use. For compatibility reasons, however, web servers using newer versions of HTTP need to honor requests from HTTP 0.9 clients.
HTTP 1.0
As an upgrade to HTTP 0.9, HTTP 1.0 introduced media types, additional methods, caching mechanisms, authentication, and persistent connections.
By introducing headers, HTTP 1.0 made it possible for clients and servers to exchange “metainformation” about the document or about the software itself. For example, a client could now specify what media it could handle with the Accept header and a server could now declare its entity-body's media type with the Content-type header. This allowed the client to know what kind of data it was receiving and deal with it accordingly. With the introduction of media types, graphics could be embedded into text documents.
HTTP 1.0 also introduced simple mechanisms to allow caching of server documents. With the Last-modified and If-Modified-Since headers, a client could avoid the retransmission of cached documents that didn't change on the server. This also allowed proxy servers to cache documents, further relieving servers from the burden of transmitting data when the data is cached.
With the Authorization and WWW-Authenticate headers, server documents could be selectively denied to the general public and accessed only by those who knew the correct username and password.
Proxies
Instead of sending a request directly to a server, it is often necessary for a client to send everything through a proxy. Caching proxies are used to keep local copies of documents that would normally be very expensive to retrieve from distant or overloaded web servers. Proxies are often used with firewalls, to allow clients inside a firewall to communicate beyond it. In this case, a proxy program runs on a machine that can be accessed by computers on both the inside and outside of the firewall. Computers on the inside of a firewall initiate requests with the proxy, and the proxy then communicates to the outside world and returns the results back to the original computer. This type of proxy is used because there is no direct path from the original client computer to the server computer, due to imposed restrictions in the intermediate network between the two systems.
There is little structural difference between the request that a proxy receives and the request that the proxy server passes on to the target server. Perhaps the only important difference is that in the client's request, a full URL must be specified, instead of a relative URL. Here is a typical client request that a client would send to a proxy:
GET http://www.ora.com/index.html HTTP/1.0 User-Agent: Mozilla/1.1N (Macintosh; I; 68K) Accept: */* Accept: image/gif Accept: image/x-xbitmap Accept: image/jpeg
The proxy then examines the URL, contacts www.ora.com, forwards the client's request, and then returns the response from the server to the original client. When forwarding the request to the web server, the proxy would convert http://www.ora.com/index.html to /index.html.
HTTP 1.1
HTTP 1.1's highlights include a better implementation of persistent connections, multihoming, entity tags, byte ranges, and digest authentication.
“Multihoming” means that a server responds to multiple hostnames, and serves from different document roots, depending on which hostname was used. To assist in server multihoming, HTTP 1.1 requires that the client include a Host header in all transactions.
Entity tags simplify the caching process by representing each server entity with a unique identifier called an entity tag. The If-match and If-none-match headers are used to compare two entities for equality or inequality. In HTTP 1.0, caching is based on an entity's document path and modification time. Managing the cache becomes difficult when the same document exists in multiple locations on the server. In HTTP 1.1, the document would have the same entity tag at each location. When the document changes, its entity tag also changes. In addition to entity tags, HTTP 1.1 includes the Cache-control header for clients and servers to specify caching behavior.
Byte ranges make it possible for HTTP 1.1 clients to retrieve only part of an entity from a server using the Range header. This is particularly useful when the client already has part of the entity and wishes to retrieve the remaining portion of the entity. So when a user interrupts a browser and the transfer of an embedded image is interrupted, a subsequent retrieval of the image starts where the previous transfer left off. Byte ranges also allow the client to selectively read an index of a document and jump to portions of the document without retrieving the entire document. In addition to these features, byte ranges also make it possible to have streaming multimedia, which are video or audio clips that the client reads selectively, in small increments.
In addition to HTTP 1.0's authentication mechanism, HTTP 1.1 includes digest authentication. Instead of sending the username and password in the clear, the client computes a checksum of the username, password, document location, and a unique number given by the server. If a checksum is sent, the username and password are not communicated between the client and server. Since each transaction is given a unique number, the checksum varies from transaction to transaction, and is less likely to be compromised by “playing back” authorization information captured from a previous transaction.
Persistent connections
One of the most significant differences between HTTP 1.1 and previous versions of HTTP is that persistent connections have become the default behavior in HTTP 1.1. In versions previous to HTTP 1.1, the default behavior for HTTP transactions is for a client to contact a server, send a request, and receive a response, and then both the client and server disconnect the TCP connection. If the client needs another resource on the server, it has to reestablish another TCP connection, request the resource, and disconnect.
In practice, a client may need many resources on the same server, especially when many images are embedded within the same HTML page. By connecting and disconnecting many times, the client wastes time in network overhead. To remedy this, some HTTP 1.0 clients started to use a Connection header, although this header never appeared in the official HTTP 1.0 specification. This header, when used with a keep-alive value, specifies that the network connection should remain after the initial transaction, provided that both the client and server use the Connection header with the value of keep-alive.
These “keep-alive” connections, or persistent connections, became the default behavior under HTTP 1.1. After a transaction completes, the network connection remains open for another transaction. When either the client or server wishes to end the connection, the last transaction includes a Connection header with a close parameter.
Heed the Specifications
While this book gives you a good start on learning how HTTP works, it doesn't have all the details of the full HTTP specifications. Describing all the caveats and details of HTTP 1.0 and 1.1 is, in itself, the topic of a separate book. With that in mind, if there are any questions still lingering in your mind after reading this chapter and Appendix A, HTTP Headers, I strongly recommend that you look at the formal protocol specifications at http://www.w3.org/. The formal specifications are, well, formal. But after reading this chapter, reading the protocol specs won't be that hard, since you already have many of the concepts that are talked about in the specs.
Server Response Codes
Now that we've discussed the client's method and version numbers, let's move on to the server's responses. (We'll save discussion of client headers for last, so we can talk about them in conjunction with the related response headers.)
The initial line of the server's response indicates the HTTP version, a three-digit status code, and a human-readable description of the result. Status codes are grouped as follows:
| Code Range | Response Meaning |
| 100-199 | Informational |
| 200-299 | Client request successful |
| 300-399 | Client request redirected, further action necessary |
| 400-499 | Client request incomplete |
| 500-599 | Server errors |
HTTP defines only a few specific codes in each range, although these ranges will become more populated as HTTP evolves.
If a client receives a response code that it does not recognize, it should understand its basic meaning from its numerical range. While most web browsers handle codes in the 100, 200, and 300 ranges silently, some error codes in the 400 and 500 ranges are commonly reported back to the user (e.g., “404 Not Found”).
Informational (100 Range)
Previous to HTTP 1.1, the 100 range of status codes was left undefined. In HTTP 1.1, the 100 range was defined for the server to declare that it is ready for the client to continue with a request, or to declare that it will be switching to another protocol.
Since HTTP 1.1 is still relatively new, few servers are implementing the 100-level status codes at this writing. The status codes currently defined are:
| Code | Meaning |
| 100 Continue: | The initial part of the request has been received, and the client may continue with its request. |
| 101 Switching Protocols: | The server is complying with a client request to switch protocols to the one specified in the Upgrade header field. |
Client Request Successful (200 Range)
The most common response for a successful HTTP transaction is 200 (OK), indicating that the client's request was successful, and the server's response contains the request data. If the request was a GET method, the requested information is returned in the response data section. The HEAD method is honored by returning header information about the URL. The POST method is honored by executing the POST data handler and returning a resulting entity-body.
The following is a complete list of successful response codes:
| Code | Meaning |
| 200 OK | The client's request was successful, and the server's response contains the requested data. |
| 201 Created | This status code is used whenever a new URL is created. With this result code, the Location header (described in Appendix A) is given by the server to specify where the new data was placed. |
| 202 Accepted | The request was accepted but not immediately acted upon. More information about the transaction may be given in the entity-body of the server's response. There is no guarantee that the server will actually honor the request, even though it may seem like a legitimate request at the time of acceptance. |
| 203 Non-Authoritative Information | The information in the entity header is from a local or third-party copy, not from the original server. |
| 204 No Content | A status code and header are given in the response, but there is no entity-body in the reply. Browsers should not update their document view upon receiving this response. This is a useful code for CGI programs to use when they accept data from a form but want the browser view to stay at the form. |
| 205 Reset Content | The browser should clear the form used for this transaction for additional input. Appropriate for data-entry CGI applications. |
| 206 Partial Content | The server is returning partial data of the size requested. Used in response to a request specifying a Range header. The server must specify the range included in the response with the Content-Range header. |
Redirection (300 Range)
When a document has moved, the server might be configured to tell clients where it has been moved to. Clients can then retrieve the new URL silently, without the user knowing. Presumably the client may want to know whether the move is a permanent one or not, so there are two common response codes for moved documents: 301 (Moved Permanently) and 302 (Moved Temporarily).
Ideally, a 301 code would indicate to the client that, from now on, requests for this URL should be sent directly to the new one, thus avoiding unnecessary transactions in the future. Think of it like a change of address card from a friend; the post office is nice enough to forward your mail to your friend's new address for the next year, but it's better to get used to the new address so your mail will get to her faster, and won't start getting returned someday.
A 302 code, on the other hand, just says that the document has moved but will return. If a 301 is a change of address card, a 302 is a note on your friend's door saying she's gone to the movies. Either way, the client should just silently make a new request for the new URL specified by the server in the Location header.
The following is a complete list of redirection status codes:
| Code | Meaning |
| 300 Multiple Choices | The requested URL refers to more than one resource. For example, the URL could refer to a document that has been translated into many languages. The entity-body returned by the server could have a list of more specific data about how to choose the correct resource. The client should allow the user to select from the list of URLs returned by the server, where appropriate. |
| 301 Moved Permanently | The requested URL is no longer used by the server, and the operation specified in the request was not performed. The new location for the requested document is specified in the Location header. All future requests for the document should use the new URL. |
| 302 Moved Temporarily | The requested URL has moved, but only temporarily. The Location header points to the new location. Immediately after receiving this status code, the client should use the new URL to resolve the request, but the old URL should be used for all future requests. |
| 303 See Other | The requested URL can be found at a different URL (specified in the Location header) and should be retrieved by a GET on that resource. |
| 304 Not Modified | This is the response code to an If-Modified-Since header, where the URL has not been modified since the specified date. The entity-body is not sent, and the client should use its own local copy. |
| 305 Use Proxy | The requested URL must be accessed through the proxy in the Location header. |
Client Request Incomplete (400 Range)
Sometimes the server just can't process the request. Either something was wrong with the document, or something was wrong with the request itself. By far, the server status code that web users are most familiar with is 404 (Not Found), the code returned when the requested document does not exist. This isn't because it's the most common code that servers return, but because it's one of the few codes that the client passes to the user rather than intercepting and handling it in its own way.
For example, when the server sends a 401 (Unauthorized) code, the client does not pass the code directly to the user. Instead, it triggers the client to prompt the user for a username and password, and then resend the request with that information supplied. With the 401 status code, the server supplies the WWW-Authenticate header to specify the authentication scheme and realm it needs authorization for, and the client returns the username and password for that scheme and realm in the Authorization header.
When testing clients you have written yourself, watch out for code 400 (Bad Request), indicating a syntax error in your client's request, and code 405 (Method Not Allowed), which declares that the method the client used for the document is not valid. (Along with the 405 code, the server sends an Allow header, listing the accepted methods for the document.)
The 408 (Request Time-out) code means that the client's request wasn't completed, and the server gave up waiting for the client to finish. A client might receive this code if it did not supply the entity-body properly, or (under HTTP 1.1) if it neglected to supply a Connection: Close header.
The following is a complete listing of status codes implying that the client's request was faulty:
| Code | Meaning |
| 400 Bad Request | This response code indicates that the server detected a syntax error in the client's request. |
| 401 Unauthorized | The result code is given along with the WWW-Authenticate header to indicate that the request lacked proper authorization, and the client should supply proper authorization when requesting this URL again. See the description of the Authorization header in this chapter for more information on how authorization works in HTTP. |
| 402 Payment Required | This code is not yet implemented in HTTP. |
| 403 Forbidden | The request was denied for a reason the server does not want to (or has no means to) indicate to the client. |
| 404 Not Found | The document at the specified URL does not exist. |
| 405 Method Not Allowed | This code is given with the Allow header and indicates that the method used by the client is not supported for this URL. |
| 406 Not Acceptable | The URL specified by the client exists, but not in a format preferred by the client. Along with this code, the server provides the Content-Language, Content-Encoding, and Content-type headers. |
| 407 Proxy Authentication Required | The proxy server needs to authorize the request before forwarding it. Used with the Proxy-Authenticate header. |
| 408 Request Time-out | This response code means the client did not produce a full request within some predetermined time (usually specified in the server's configuration), and the server is disconnecting the network connection. |
| 409 Conflict | This code indicates that the request conflicts with another request or with the server's configuration. Information about the conflict should be returned in the data portion of the reply. For example, this response code could be given when a client's request would cause integrity problems in a database. |
| 410 Gone | This code indicates that the requested URL no longer exists and has been permanently removed from the server. |
| 411 Length Required | The server will not accept the request without a Content-Length header supplied in the request. |
| 412 Precondition Failed | The condition specified by one or more If... headers in the request evaluated to false. |
| 413 Request Entity Too Large | The server will not process the request because its entity-body is too large. |
| 414 Request Too Long | The server will not process the request because its request URL is too large. |
| 415 Unsupported Media Type | The server will not process the request because its entity-body is in an unsupported format. |
Server Error (500 Range)
Occasionally, the error might be with the server itself--or, more commonly, with the CGI portion of the server. CGI programmers are painfully familiar with the 500 (Internal Server Error) code, which frequently means that their program crashed. One error that client programmers should pay attention to is 503 (Service Unavailable), which means that their request cannot be performed right now, but the Retry-After header (if supplied) indicates when the client might try again.
The following is a complete listing of response codes implying a server error:
| Code | Meaning |
| 500 Internal Server Error | This code indicates that a part of the server (for example, a CGI program) has crashed or encountered a configuration error. |
| 501 Not Implemented | This code indicates that the client requested an action that cannot be performed by the server. |
| 502 Bad Gateway | This code indicates that the server (or proxy) encountered invalid responses from another server (or proxy). |
| 503 Service Unavailable | This code means that the service is temporarily unavailable, but should be restored in the future. If the server knows when it will be available again, a Retry-After header may also be supplied. |
| 504 Gateway Time-out | This response is like 408 (Request Time-out) except that a gateway or proxy has timed out. |
| 505 HTTP Version Not Supported | The server will not support the HTTP protocol version used in the request. |
HTTP Headers
Now we're ready for the meat of HTTP: the headers that clients and servers can use to exchange information about the data, or about the software itself.
If the Web were just a matter of retrieving documents blindly, then HTTP 0.9 would have been sufficient for all our needs. But as it turns out, there's a whole set of information we'd like to exchange in addition to the documents themselves. A client might ask the server, “What kind of document are you sending?” Or, “I already have an older copy of this document--do I need to bother you for a new one?”
A server may want to know, “Who are you?” Or, “Who sent you here?” Or, “How am I supposed to know you're allowed to be here?”
All this extra (“meta-”) information is passed between the client and server using HTTP headers. The headers are specified immediately after the initial line of the transaction (which is used for the client request or server response line). Any number of headers can be specified, followed by a blank line and then the entity-body itself (if any).
HTTP makes a distinction between four different types of headers:
- General headers indicate general information such as the date, or whether the connection should be maintained. They are used by both clients and servers.
- Request headers are used only for client requests. They convey the client's configuration and desired document format to the server.
- Response headers are used only in server responses. They describe the server's configuration and special information about the requested URL.
- Entity headers describe the document format of the data being sent between client and server. Although Entity headers are most commonly used by the server when returning a requested document, they are also used by clients when using the POST or PUT methods.
Headers from all three categories may be specified in any order. Header names are case-insensitive, so the Content-Type header is also frequently written as Content-type.
In the remainder of this chapter, we'll list all the headers, and then discuss the ones that are most interesting, in context. Appendix A contains a full listing of headers, with examples for each and additional information on its syntax and purpose when applicable.
| General Headers | |
| Cache-Control | Specifies behavior for caching |
| Connection | Indicates whether network connection should close after this connection |
| Date | Specifies the current date |
| MIME-Version | Specifies the version of MIME used in the HTTP transaction |
| Pragma | Specifies directives to a proxy system |
| Transfer-Encoding | Indicates what type of transformation has been applied to the message body for safe transfer |
| Upgrade | Specifies the preferred communication protocols |
| Via | Used by gateways and proxies to indicate the protocols and hosts that processed the transaction between client and server |
| Request Headers | |
| Accept | Specifies media formats that the client can accept |
| Accept-Charset | Tells the server the types of character sets that the client can handle |
| Accept-Encoding | Specifies the encoding schemes that the client can accept, such as compress or gzip |
| Accept-Language | Specifies the language in which the client prefers the data |
| Authorization | Used to request restricted documents |
| Cookie | Used to convey name=value pairs stored for the server |
| From | Indicates the email address of the user executing the client |
| Host | Specifies the host and port number that the client connected to. This header is required for all clients in HTTP 1.1. |
| If-Modified-Since | Requests the document only if newer than the specified date |
| If-Match | Requests the document only if it matches the given entity tags |
| If-None-Match | Requests the document only if it does not match the given entity tags |
| If-Range | Requests only the portion of the document that is missing, if it has not been changed |
| If-Unmodified-Since | Requests the document only if it has not been changed since the given date |
| Max-Forwards | Limits the number of proxies or gateways that can forward the request |
| Proxy-Authorization | Used to identify client to a proxy requiring authorization |
| Range | Specifies only the specified partial portion of the document |
| Referer | Specifies the URL of the document that contained the link to this one (i.e., the previous document) |
| User-Agent | Identifies the client program |
| Response Headers | |
| Accept-Ranges | Declares whether or not the server accepts range requests, and if so, what units |
| Age | Indicates the age of the document in seconds |
| Proxy-Authenticate | Declares the authentication scheme and realm for the proxy |
| Public | Contains a comma-separated list of supported methods other than those specified in HTTP/1.0 |
| Retry-After | Specifies either the number of seconds or a date after which the server becomes available again |
| Server | Specifies the name and version number of the server |
| Set-Cookie | Defines a name=value pair to be associated with this URL |
| Vary | Specifies that the document may vary according to the value of the specified headers |
| Warning | Gives additional information about the response, for use by caching proxies |
| WWW-Authenticate | Specifies the authorization type and the realm of the authorization |
| Entity Headers | |
| Allow | Lists valid methods that can be used with a URL |
| Content-Base | Specifies the base URL for resolving relative URLs |
| Content-Encoding | Specifies the encoding scheme used for the entity |
| Content-Language | Specifies the language used in the document being returned |
| Content-Length | Specifies the length of the entity |
| Content-Location | Contains the URL for the entity, when a document might have several different locations |
| Content-MD5 | Contains a MD5 digest of the data |
| Content-Range | When a partial document is being sent in response to a Range header, specifies where the data should be inserted |
| Content-Transfer-Encoding | Identifies the transfer encoding used in the document |
| Content-Type | Specifies the media type of the entity |
| Etag | Gives an entity tag for the document |
| Expires | Gives a date and time that the contents may change |
| Last-Modified | Gives the date and time that the entity last changed |
| Location | Specifies the location of a created or moved document |
| URI | A more generalized version of the Location header |
So what do you do with all this? The remainder of the chapter discusses many of the larger topics that are managed by HTTP headers.
Persistent Connections
As we touched on earlier, one of the big changes in HTTP 1.1 is that persistent connections became the default. Persistent connections mean that the network connection remains open during multiple transactions between client and server. Under both HTTP 1.0 and 1.1, the Connection header controls whether or not the network stays open; however, its use varies according to the version of HTTP.
The Connection header indicates whether the network connection will be maintained after the current transaction finishes. The close parameter signifies that either the client or server wishes to end the connection (i.e., this is the last transaction). The keep-alive parameter signifies that the client wishes to keep the connection open. Under HTTP 1.0, the default is to close connections after each transaction, so the client must use the following header in order to maintain the connection for an additional request:
Connection: Keep-Alive
Under HTTP 1.1, the default is to keep connections open until they are explicitly closed. The Keep-Alive option is therefore unnecessary under HTTP 1.1; however, clients must be sure to include the following header in their last transaction:
Connection: Close
or the connection will remain open until the server times out. How long it takes the server to time out depends on the server's configuration ... but needless to say, it's more considerate to close the connection explicitly.
Media Types
One of the most important functions of headers is to make it possible for the client to know what kind of data is being served, and thus be able to process it appropriately. If the client didn't know that the data being sent is a GIF, it wouldn't know how to render it on the screen. If it didn't know that some other data was an audio snippet, it wouldn't know to call up an external helper application. For negotiating different data types, HTTP incorporated Internet Media Types, which look a lot like MIME types but are not exactly MIME types. Appendix B gives a listing of media types used on the Web.
The way media types work is that the client tells the server which types it can handle, using the Accept header. The server tries to return information in a preferred media type, and declares the type of the data using the Content-Type header.
The Accept header is used to specify the client's preference for media formats, or to tell the server that it can accept unusual document types. If this header is omitted, the server assumes that the client can accept any media type. The Accept header can have three general forms:
Accept: */* Accept: type/* Accept: type/subtype
Using the first form, */*, indicates that the client can accept an entity-body of any media type. The second form, type/*, communicates that an entity-body of a certain general class is acceptable. For example, a client may issue an Accept: image/* to accept images, where the type of image (GIF, JPEG, or whatever) is not important. The third form indicates that an entity-body from a certain type and subtype is acceptable. For example, a browser that can only accept GIF files may use Accept: image/gif.
The client specifies multiple document types that it can accept by separating the values with commas:
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*
Some older browsers send the same line as:
Accept: image/gif Accept: image/x-xbitmap
Accept: image/jpeg Accept: image/pjpeg Accept: */*
When developing a new application, it is recommended that it conform to the newer practice of separating multiple document preferences by commas, with a single Accept header.
In the server's response, the Content-type header describes the type and subtype of the media. If the client specified an Accept header, the media type should conform to the values used in the Accept header. Clients use this information to correctly handle the media type and format of the entity-body.
A client might also use a Content-type header with the POST or PUT method. Most commonly, with many CGI applications, clients use a POST or PUT request with information in the entity-body, and supply a Content-type header to describe what data can be expected in the entity-body.
Client Caching
If we each went to a single document once in a lifetime, or even once a day, life could be much simpler for web programmers. But in reality, we tend to return to the same documents over and over again. Simple clients can just keep retrieving data over and over again, but robust clients will prefer to store local copies of documents to improve efficiency. This is called caching.
On sites with proxy servers, the proxies can also work as caches. So several users on that site might all share the same copy of the document, which the proxy stores locally. If you call up a URL that someone else requested earlier this morning, the proxy can simply give you that copy, meaning that you retrieve the data much faster, help to reduce network traffic, and prevent overburdening the server containing the document's source. It's sort of like carpooling at rush hour: caches do their part to make the web a better place for all of us.[2]
A complication with caching, however, is that the client or proxy needs to know when the document has changed on the server. So for cache management, HTTP provides a whole set of headers. There are two general systems: one based on the age of the document, and a much newer one based on unique identifiers for each document.
Also, when caching, you should pay attention to the Cache-Control and Pragma headers. Some documents aren't appropriate for caching, either for security reasons or because they are dynamic documents (e.g., created on the fly by a CGI script). Under HTTP 1.0, the Pragma header was used with the value no-cache to tell caching proxies and clients not to cache the document. Under HTTP 1.1, the Cache-Control header supplants Pragma, with several caching directives in addition to no-cache. See Appendix A for more information.
If-Modified-Since, et al.
To accommodate client-side caching of documents, the client can use the If-Modified-Since header with the GET method. When using this option, the client requests the server to send the requested information associated with the URL only if it has been modified since a client-specified time.
If the document was modified, the server will give a status code of 200 and will send the document in the entity-body of its reply. If the document was not modified, the server will give a response code of 304 (Not Modified).
An example If-Modified-Since header might read:
If-Modified-Since: Fri, 02-Jun-95 02:42:43 GMT
The same formats accepted for the Date header (listed in Appendix A) are used for the If-Modified-Since header.
If the server returns a code of 304, the document has not been modified since the specified time. The client can use the cached version of the document. If the document is newer, the server will send it along with a 200 (OK) code. Servers may also include a Last-Modified header with the document, to let the user know when the last change was made to the document.[3]
Another related client header is If-Unmodified-Since, which says to only send the document if it hasn't been changed since the specified date. This is useful for ensuring that the data is exactly the way you wanted it to be. For example, if you GET a document from a server, make changes in a publishing tool, and PUT it back to the server, you can use the If-Unmodified-Since header to verify that the changes you made are accepted by the server only if the previous one you were looking at is still there.
If the server contains an Expires header, the client can take it as an indication that the document will not change before the specified time. Although there are no guarantees, it means that the client does not have to ask the server about the last modified date of the document again until after the expiration date.
Entity tags
In HTTP 1.1, a new method of cache management is introduced with entity tags. The problem solved by entity tags is that there may be several copies of the identical document on the server. The client has no way to know that it's the same document--so even if it already has an equivalent, it will request it again.
Entity tags are unique identifiers that can be associated with all copies of the document. If the document is changed, the entity tag is changed--so a more efficient way of cache management is to check for the entity tag, not for the URL and date.
If the server is using entity tags, it sends the document with the ETag header. When the client wants to verify the cache, it uses the If-Match or If-None-Match headers to check against the entity tag for that resource.
Retrieving Content
The Content-length header specifies the length of the data (in bytes) that is returned by the client-specified URL. Due to the dynamic nature of some requests, the Content-length is sometimes unknown, and this header might be omitted.
There are three common ways that a client can retrieve data from the entity-body of the server's response:
- The first way is to get the size of the document from the Content-length header, and then read in that much data. Using this method, the client knows the size of the document before retrieving it, and can allocate a buffer to fit the exact size.
- In other cases, when the size of the document is too dynamic for a server to predict, the Content-length header is omitted. When this happens, the client reads in the data portion of the server's response until the server disconnects the network connection.[4] This is the most flexible way to retrieve data, but the client can make no assumptions about the size until the server disconnects the session.
- Another header could indicate when an entity-body ends, like HTTP 1.1's Transfer-Encoding header with the chunked parameter.
When a client is involved in a client-pull/server-push operation, it may be possible that there is no end to the entity-body. For example, a client program may be reading in a continuous feed of news 24 hours a day, or receiving continuous frames of a video broadcast. In practice, this is rarely done, at least not for long periods of time, since it is an expensive consumer of network bandwidth and connect time. In the event that an endless entity-body is undesirable, the client software should have options to configure the maximum time spent (or data received) from a given entity-body.
Byte ranges
In HTTP 1.1, the client does not have to get the entire entity-body at once, but can get it in pieces, if the server allows it to do so. If the server declares that it supports byte ranges using the Accept-Ranges header:
HTTP/1.1 200 OK [Other headers here] Accept-Ranges: bytes
then the client can request the data in pieces, like so:
GET /largefile.html HTTP/1.1 [Other headers here] Range: 0-65535
When the server returns the specified range, it includes a Content-range header to indicate which portion of the document is being sent, and also to tell the client how long the file is:
HTTP/1.1 200 OK [Other headers here] Content-range: 0-65535/83028576
The client can use this information to give the user some idea of how long she'll have to wait for the document to be complete.
For caching purposes, a client can use the If-Range header along with Range to request an updated portion of the document only if the document has been changed. For example:
GET /largefile.html HTTP/1.1 [Other headers here] If-Range: Mon, 02 May 1996 04:51:00 GMT Range: 0-65535
The If-Range header can use either a last modified date or an entity tag to verify that the document is still the same.
Referring Documents
The Referer header indicates which document referred to the one currently specified in this request. This helps the server keep track of documents that refer to malformed or missing locations on the server.
For example, if the client opens a connection to www.ora.com at port 80 and sends:
GET /contact.html HTTP/1.0 Accept: */*
the server may respond with:
HTTP/1.0 200 OK Date: Sat, 20-May-95 03:32:38 GMT MIME-version: 1.0 Content-type: text/html <h1>Contact Information</h2> <a href=“http://sales.ora.com/sales.html”> Sales Department</a>
The user clicks on the hyperlink and the client requests “sales.html” from sales.ora.com, specifying that it was sent there from the /contact.html document on www.ora.com:
GET /sales.html HTTP/1.0 Accept: */* Referer: http://www.ora.com/contact.html
It is important to design clients that specify only public locations in the Referer header to other public documents. The client should never specify a private document (i.e., accessible only through proper authentication) when requesting a public document. Even the name of a sensitive document may be considered a security breach.
Client and Server Identification
Clients and servers like to know whom they're talking to. Servers know that different clients have different capabilities, and would like to tailor their content for the best effect. For example, sites with JavaScript content would like to know whether you're a JavaScript-capable client, and serve JavaScript-enhanced HTML when possible. There isn't anything in HTTP that describes which languages the browsers understand,[5] but a server with a properly updated database of browser names could make an informed guess.
Similarly, clients sometimes want to know what kind of server is running. It might know that the latest version of Apache supports byte ranges, or that there's a bug to avoid in a version of some unnamed server. And then there are times when a proxy server would like to block requests from certain browsers--not for the sake of browser-bashing, but usually for the sake of security, when there are known security bugs in a certain version of a browser.
Clients can identify themselves with the User-Agent header. The User-Agent header specifies the name of the client and other optional components, such as version numbers or subcomponents licensed from other companies. The header may consist of one or more names separated by a space, where each name can contain an optional slash and version number. Optional components of the User-Agent might be the type of machine, operating system, or plug-in components of the client program. For example:
User-Agent: Mozilla/1.1N (Macintosh; I; 68K) User-Agent: HTML-checker/1.0
Beware that there have been well-documented instances in which clients have lied about who they are--not out of malice (they claim) but because they had implemented all the features of their competitor, and wanted to make sure that they were served HTML that was tailored for that competitor.
Servers identify themselves using the Server header. The Server header may help clients make inferences about what types of methods and parameters the server can accept, based on the server name and version number.
Authorization
An Authorization header is used to request restricted documents. Upon first requesting a restricted document, the web client requests the document without sending an Authorization header. If the server denies access to the document, the server specifies the authorization method for the client to use with the WWW-Authenticate header, described later in this chapter. At this point, the client requests the document again, but with an Authorization header.
The authorization header is of the general form:
Authorization: SCHEME REALM
The authorization scheme generally used in HTTP is BASIC, and under the BASIC scheme the credentials follow the format username:password encoded in base64. For example, for the username of “webmaster” and a password of “zrqma4v”, the authorization header would look like this:
Authorization: Basic d2VibWFzdGVyOnpycW1hNHY=
When “d2VibWFzdGVyOnpycW1hNHY=” is decoded using base 64, it translates into webmaster:zrqma4v.
Here's a verbose example:
When a client requests information that is secure, the server responds with response code 401 (Unauthorized) and an appropriate WWW-Authenticate header describing the type of authentication required:
GET /sample.html HTTP/1.0 User-Agent: Mozilla/1.1N (Macintosh; I; 68K) Accept: */* Accept: image/gif Accept: image/x-xbitmap Accept: image/jpeg
The server then declares that further authorization is required to access the URL:
HTTP/1.0 401 Unauthorized Date: Sat, 20-May-95 03:32:38 GMT Server: NCSA/1.3 MIME-version: 1.0 Content-type: text/html WWW-Authenticate: BASIC realm=“System Administrator”
The client now seeks authentication information. Interactive GUI-based browsers might prompt the user for a user name and password in a dialog box. Other clients might just get the information from an online file or a hardware device.
The realm of the BASIC authentication scheme indicates the type of authentication requested. Each realm is defined by the web administrator of the site and indicates a class of users: administrators, CGI programmers, registered users, or anything else that separates one class of authorization from another. In this case, the realm is for system administrators. After encoding the data appropriately for the BASIC authorization method, the client resends the request with proper authorization:
GET /sample.html HTTP/1.0 User-Agent: Mozilla/1.1N (Macintosh; I; 68K) Accept: */* Accept: image/gif Accept: image/x-xbitmap Accept: image/jpeg Authorization: BASIC d2VibWFzdGVyOnpycW1hNHY=
The server checks the authorization, and upon successful authentication, sends the requested data:
HTTP/1.0 200 OK Date: Sat, 20-May-95 03:25:12 GMT Server: NCSA/1.3 MIME-version: 1.0 Content-type: text/html Last-modified: Wednesday, 14-Mar-95 18:15:23 GMT Content-length: 1029 [Entity-body data]
In HTTP 1.1, there's also something called Digest authentication. See http://www.w3.org/ for details.
Cookies
Persistent state, client-side cookies were introduced by Netscape Navigator to enable a server to store client-specific information on the client's machine, and use that information when a server or a particular page is accessed again by the client. The cookie mechanism allows servers to personalize pages for each client, or remember selections the client has made when browsing through various pages of a site. Cookies are not part of the HTTP specification; however, their use is so entrenched throughout the Web today that all HTTP programmers should be aware of the Set-Cookie and Cookie headers, even if they choose not to honor them.
Cookies work in the following way: When a server (or CGI program running on a server) identifies a new user, it adds the Set-Cookie header to its response, containing an identifier for that user and other information that the server may glean from the client's input. The client is expected to store the information from the Set-Cookie header on disk, associated with the URL that assigned that cookie. In subsequent requests to that URL, the client should include the cookie information using the Cookie header. The server or CGI program uses this information to return a document tailored to that specific client. The cookies should be stored on the client user's system, so the information remains even when the client has been terminated and restarted.
For example, the client may fill in a form opening a new account. The request might read:
POST /www.whosis.com/order.pl HTTP/1.0 [Client headers here] type=new&firstname=Linda&lastname=Mui
The server stores this information along with a new account ID, and sends it back in the response:
HTTP/1.0 200 OK [Server headers here] Set-Cookie: acct=04382374
The client saves the cookie information along with the URL. For example, a cookies file might contain the line:
www.whosis.com/order.pl acct=04382374
Days or months later, when the client returns to the site to place another order, the client should recognize the URL and append the cookie to its headers:
GET /www.whosis.com/order.pl [Client headers here] Cookie: acct=04382374
The server retrieves the cookie, grabs the customer's data from an internal database, and the order form the client receives may already have her ordering information filled in.
1. More modern clients would just send one Accept header and separate the different values with commas.
2.On the other hand, sometimes it takes longer to pick up everyone in a carpool than it would take to drive to work alone. This sometimes happens with caching proxy servers, where it takes longer to go through the cache than it takes to fetch a new copy of the document. Your mileage will vary.
3.Not to be confused with the Age header. If you make a request to a web server, get a response, and wait 20 seconds, the age of the response is 20 seconds. If you get a document last modified on 02-Jun-95 02:42:43 GMT and has not been modified since, then the last modified date stays the same, even though those 20 seconds go by.
4.This only works in HTTP 1.0. In HTTP 1.1, both client and server need a clear understanding of the request/response length, so they can anticipate where the beginning of the next request/response happens.
5.At least not in HTTP 1.0 or 1.1.
Get Web Client Programming with Perl now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

