In the early days of the commercial Web, otherwise reasonable and intelligent people bought into the notion that simply having a publicly available web site was enough. Enough to get their company noticed. Enough to become a major player in the global market. Enough to capture that magical and vaguely defined commodity called market share. Somehow that would be enough to ensure that consumers and investors would pour out bags of money on the steps of company headquarters. In those heady days, budgets for web-related technologies appeared limitless, and the development practices of the time reflected that—it seemed perfectly reasonable to follow the celebration of a site’s rollout with initial discussions about what the next version of that site would look like and do. (Sometimes, the next redesign was already in the works before the current redesign was even launched.) It did not matter, technically, that a site was largely hardcoded and inflexible, or that the scripts that implemented the dynamic applications were messy and impossible to maintain over time. What mattered was that the project was done quickly. If a few bad choices were made along the way, it was thought, they could always be addressed during the inevitable redesign.
Those days are gone.
The goldrush mentality has receded and companies and other organizations are looking for more from their investment in the Web. Simply having a site out there is not enough (and truly, it never was). The site must do something that measurably adds value to the organization and that value must exceed the cost of developing the site in the first place. In other words, the New Economy had a rather abrupt introduction to the rules of Business As Usual. This industry-wide belt-tightening means that web developers must adjust their approach to production. Companies can no longer afford to write off the time and energy invested in developing a web site simply to replace it with something largely similar. Developers are expected to provide dynamic, malleable solutions that can evolve over time to include new content, dynamic features, and support for new types of client software. In short, today’s developers are being asked to do more with less. They need tools that can cope with major changes to a site or an application without altering the foundation that is already there.
Far from being a story of gloom and doom, the slimming of web budgets has led to a natural and positive reevaluation of the tools and techniques that go into developing and maintaining online media and applications. The need to provide more options with fewer resources is driving the creative development of higher-level application and publishing frameworks that are better able to meet changing requirements over time with a minimum of duplicated effort. Ironically, in many ways, the “dot bomb” was the best thing that could have happened to web software.
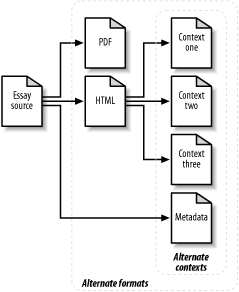
One key concept behind today’s more adaptive web solutions lies in making sure that the content of the site is reusable. By reusable content I mean that the essential information is captured (or available) in a way that lends itself to different uses or views of that data based on the context in which it is being requested. Consider, for example, the task of publishing an informal essay about the life of Jazz great Louis Armstrong. Presuming you will only be publishing this document via the Web, you still have a variety of choices about the form in which the document will be available. You could publish it in HTML for faster downloading or PDF for finer control over the visual layout. If you limit the choice to HTML, you still have many choices to make—what links, ad banners, and other supporting content will you include? Does the data include a generic boilerplate that is the same for every page on the site, or will you attempt to provide a more intimate sense of context by providing links to other related topics? If you want to offer a sense of context, how do you decide what is related? Do you frame the essay in the context of influential Jazz musicians, prominent African Americans, or famous natives of New Orleans? Given that each of these contexts is arguably valid, what if you want to present all three and let the user decide which navigational path suits her interests best? You could also say that the essay’s metadata (its title, author’s name, abstract summary, etc.) is really just another way of looking at the same document, albeit a highly selective and filtered one. Each of these choices represents nothing more than an alternative contextual view of the same content (the Armstrong essay). All that really changes is the way in which that content is presented.
Figure 1-1 shows a simple representation of your essay and some of its possible alternate views. How could you hit all of these targets? Obviously, you could hand-author the document in each of the various formats and contexts, but that would be time-consuming and unrealistic for all but the tiniest of sites. Ideally, what you want is a system that:
Stores the data in a rich and meaningful way so users can access it easily at various levels of detail
Provides an easy way to add alternate (expanded or filtered) views of that data without requiring changes to the source document (or, in the case of dynamic content, the code that generates it)
Although many web-development frameworks offer the ability to create sites in a modular fashion through reusable components, most focus largely on automating redundancy through the inclusion of common content blocks and use of code macros. These systems recognize the value of separating content from logic, but they are typically designed to construct documents in only one target format. That is, the templates, widgets, and content (or content-generating code) are all focused on constructing a single kind of document (usually HTML). Rendering the same content in multiple formats is cumbersome and often requires so much duplication at the component level that modularity becomes more burden than blessing. One technology, however, is firmly rooted in the ideas of generating context-specific representations of rich content sources through both modular construction and data transformation—that technology is XML.
This is where the subject of this book, AxKit, comes in. As an XML publishing and application server, AxKit begins with XML’s high-level notion of reusable content and seeks to simplify the tasks associated with creating dynamic, context-sensitive representations from rich XML sources. That is, the fact that you need to deliver the same content in a variety of ways is a given, and part of what AxKit does is to provide a framework to ensure that the core content is transformed correctly for the given situation.
XML and its associated technologies have generated enormous interest. XML pundits describe in florid terms how moving to XML is the first step toward a Utopian new Web, while well-funded marketing departments churn out page after page of ambiguous doublespeak about how using XML is the cure for everything from low visitor traffic to male-pattern baldness. While you may admire visionary zeal on the one hand and understand the simple desire to generate new business on the other, the unfortunate result is that many web developers are confused about what XML is and what it is good for. Here, I clear up a few of the more common fallacies about XML and its use as a web-publishing technology.
- Using XML means having to memorize a pile of complex specifications.
There is certainly no shortage of specifications, recommendations, or white papers that describe or relate to XML technologies. Developing even a cursory familiarity with them all would be a full-time job. The fact is, though, that many of these specifications only describe a single application of XML. Unless that tool solves a specific existing need, there’s no reason for a developer to try to use it, especially if you come to XML from an HTML background. A general introduction to XML’s basic rules, and perhaps a quick tutorial or two that covers XSLT or another transformative tool, are all you need to be productive with XML and a tool such as AxKit. Be sane. Take a pragmatic approach: learn only what you need to deliver on the requirements at hand.
- Moving to XML means throwing away all the tools and techniques that I have learned thus far.
XML is simply a way to capture data, nothing more. No tool is appropriate for all cases, and knowing how to use XML effectively simply adds another tool to your bag of tricks. Additionally (as you will see in Chapter 9), many tools you may be using today can be integrated seamlessly into AxKit’s framework. You can keep doing what worked well in the past while taking advantage of what AxKit may offer in the way of additional features.
- XML is totally revolutionary and will solve all of my publishing problems.
This is the opposite of the previous myth but just as common. Despite considerable propaganda to the contrary, XML offers nothing more than a way to represent information. In itself, XML does not address the issues of archiving, information retrieval, indexing, administration, or any other tasks associated with publishing documents. It may make finding or building tools to perform these tasks simpler, faster, more straightforward, or less ad hoc, but no magic is involved.
- XML is useful only for transferring data structures among web services.
Two popular exchange protocols, SOAP and XML-RPC, use XML to capture data, but suggesting that this is the only legitimate use for XML is simply wrong. In fact, XML was originally intended primarily as a publishing technology. Tools such as SOAP only emerged later when it was discovered that XML was quite handy for capturing complex data in a way that common programming languages could share. To say that XML is only useful for transferring data between applications is a bit like saying that the ASCII text format is only useful for composing email messages—popular, yes; exclusive, no.
- My project only requires documents to be available to web browsers as HTML; using XML would add complexity and overhead without adding value.
It is true—needing to deliver the same content to different target clients is a compelling reason to consider XML publishing, but it is certainly not the only one. Separating the content from its presentation also provides the ability to fundamentally alter the look and feel of an entire site without worrying about the information being communicated getting clobbered in the bargain. Similarly, new site design prototypes can be created using the actual content that will be delivered in production rather than the boilerplate filler that so often only favors the designers’ sense of aesthetics.
As for performance, true XML publishing frameworks such as AxKit offer the ability to cache transformed content—even several views of the same document—and will only reprocess when either the source XML or the stylesheets being applied are modified (or when explicitly configured, reprocess for each request). The latest data available shows that AxKit can deliver cached, transformed content at roughly 90% of the speed (requests per second) offered by serving the same content as static HTML.
Get XML Publishing with AxKit now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

