In the most general sense, delivering XML documents over the Web is much the same as serving any other type of document—a client application makes a request over a network to a server for a given resource, the server then interprets that request (URI, headers, content), returns the appropriate response (headers, content), and closes the connection. However, unlike serving HTML documents or MP3 files, the intended use for an XML document is not apparent from the format (or content type) itself. Further processing is usually required. For example, even though most modern web browsers offer a way to view XML documents, there is no way for the browser to know how to render your custom grammar visually. Simply presenting the literal markup or an expandable tree view of the document’s contents usually communicates nothing meaningful to the user. In short, the document must be transformed from the markup grammar that best fits your needs into the format that best fits the expectations of the requesting client.
This separation between the source content and the form in which it
will be presented (and the need to transform one into the other) is
the heart and soul of XML publishing. Not
only does making a clear distinction between content and presentation
allow you to use the grammar that best captures your content, it
provides a clear and logical path toward reusing that content in
novel ways without altering the data’s source.
Suppose you want to publish the poems from the collection mentioned
in the previous section as HTML. You simply transform the documents
from the poemsfrag grammar into the grammar that
an HTML browser expects. Later, if you decide that PDF or PostScript
is the best way to deliver the content, you only need to change the
way the source is transformed, not the source itself. Similarly, if
your XML expresses more record-oriented data—generated from the
result of an SQL query, for example—the separation between
content and presentation offers a way to provide the data through a
variety of interfaces just by changing the way the markup is
transformed.
Although there are many ways to transform XML content, the most common is to pass the document—together with a stylesheet document—into a specialized processor that transforms or renders the data based on the rules set forth in the stylesheet. Extensible Stylesheet Language Transformations (XSLT) and Cascading Stylesheets (CSS) are two popular variations of this model. Putting aside features offered by various stylesheet-based transformative processors for later chapters, you still need to decide where the transformation is to take place.
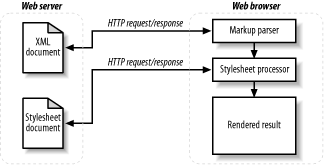
In the client-side processing model, the remote application,
typically a web browser, is responsible for transforming the
requested XML document into the desired format. This is usually
achieved by extracting the URL for the appropriate stylesheet from
the href attribute of an
xml-stylesheet processing instruction or
link element contained in the document, followed
by a separate request to the remote server to fetch that stylesheet.
The stylesheet is then
applied to the XML document using the client’s
internal processor and, assuming no errors occur along the way, the
result of the transformation is rendered in the browser. (See Figure 1-1.)
Using the client-side approach has several benefits. First, it is
trivial to set up a web server to deliver XML documents in this
manner—perhaps adding a few lines to the
server’s
mime.conf file to
ensure that the proper content type is part of the outgoing response.
Also, since the client handles all processing, no additional XML
tools need to be installed and configured on the server. There is no
additional performance hit over and above serving static HTML pages,
since documents are offered up as is, without additional processing
by the server.
Client-side processing also has weaknesses. It assumes that the user at the other end of the request has an appropriate browser installed that can process and render the data correctly. Years of working around browser idiosyncrasies have taught web developers not to rely too heavily on client-side processing. The stakes are higher when you expect the browser to be solely responsible for extracting, transforming, and rendering the information for the user. Developers lose one of the important benefits of XML publishing, namely, the ability to repurpose content for different types of client devices such as PDAs, WAP phones, and set-top boxes. Many of these platforms cannot or do not implement the processors required to transform the documents into the proper format.
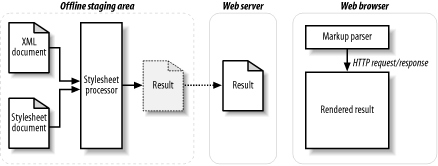
Using preprocessed transformations, the appropriate stylesheets are applied to the source content offline. Only the results of those transformations are published. Typically, a staging area is used, where the source content is transformed into the desired formats. The results are copied from there into the appropriate location on the publicly available server, as shown in Figure 1-2.
On the plus side, transforming content into the correct format ahead of time solves potential problems that can arise from expecting too much from the requesting client. That is to say, for example, that the browser gets the data that it can cope with best, just as if you authored the content in HTML to begin with, and you did not introduce any additional risk. Also, as with client-side transformations, no additional tools need to be installed on the web-server machine; any vanilla web server can capably deliver the preprocessed documents.
On the down side, offline preprocessing adds at least one additional step to publishing every document. Each time a document changes, it must be retransformed and the new version published. As the site grows or the number of team members increases, the chances of collision and missed or slow updates increase. Also, making the same content available in different formats greatly increases complexity. A simple text change, for example, requires a content transformation for each format, as well as a separate URL for each variation of every document. Scripted automation can help reduce some costs and risks, but someone must write and maintain the code for the automation process. That means more time and money spent. In any case, the static site that results from offline preprocessing lacks the ability to repurpose content on the fly in response to the client’s request.
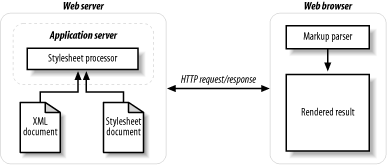
In the server-side runtime processing model, all XML data is parsed and then transformed on the server machine before it is delivered to the client. Typically, when a request is received, the web server calls out via a server extension interface to an external XML parser and stylesheet processor that performs any necessary transformations on the data before handing it back to the web server to deliver to the client. The client application is expected only to be able to render the delivered data, as shown in Figure 1-3.
Handling all processing dynamically on the server offers several
benefits. It is a given that a scripting engine or other application
framework will be called on to process the XML data. As a result, the
same methods that can be used from within that framework to capture
information about a given request (HTTP cookies, URL parameters,
POSTed form data, etc.) can be used to determine
which transformations occur and on which documents. In the same way,
access to the user agent and accept headers gives the developer the
opportunity to detect the type of client making the connection and to
transform the data into the appropriate format for that device. This
ability to transform documents differently, based on
context, provides the dynamic server-side
processing model a level of flexibility that is simply impossible to
achieve when using the client-side or preprocessed approaches.
Server-side XML processing also has its downside. Calling out to a scripting engine, which calls external libraries to process the XML, adds overhead to serving documents. A single transformation from Simplified DocBook to HTML may not require a lot of processing power. However, if that transformation is being performed for each request, then performance may become an issue for high traffic sites. Depending on the XML interface used, the in-memory representation of a given document is 10 times larger than its file size on disk, so parsing large XML documents or using complex stylesheets to transform data can cause a heavy performance hit. In addition, choosing to keep the XML processing on the server may also limit the number of possible hosting options for a given project. Most service providers do not currently offer XML processing facilities as part of their basic hosting packages, so developers must seek a specialty provider or co-locate a server machine if they do not already host their own web servers.
Comparing these three approaches to publishing XML content, you can generally say that dynamic server-side processing offers the greatest flexibility and extensibility for the least risk and effort. The cost of server-side processing lies largely in finding a server that provides the necessary functionality—a far more manageable cost, usually, than that of working around client-side implementations beyond your control or writing custom offline processing tools.
Get XML Publishing with AxKit now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

