
 Pillars (source: Pixabay)
Pillars (source: Pixabay) In this post, I share slides and notes from a keynote I gave at the Strata Data Conference in London earlier this year. I will highlight the results of a recent survey on machine learning adoption, and along the way describe recent trends in data and machine learning (ML) within companies. This is a good time to assess enterprise activities, as there are many indications a number of companies are already beginning to use machine learning. For example, in a July 2018 survey that drew more than 11,000 respondents, we found strong engagement among companies: 51% stated they already had machine learning models in production.
With all the hype around AI, it can be tempting to jump into use cases involving data types with which you aren’t familiar. We found that companies that have successfully adopted machine learning do so either by building on existing data products and services, or by modernizing existing models and algorithms. Here are some typical ways organizations begin using machine learning:
- Build upon existing analytics use cases: e.g., one can use existing data sources for business intelligence and analytics, and use them in an ML application.
- Modernize existing applications such as recommenders, search ranking, time series forecasting, etc.
- Use ML to unlock new data types—e.g., images, audio, video.
- Tackle completely new use cases and applications.
Consider deep learning, a specific form of machine learning that resurfaced in 2011/2012 due to record-setting models in speech and computer vision. While we continue to read about impressive breakthroughs in speech and computer vision, companies are beginning to use deep learning to augment or replace existing models and algorithms. A famous example is Google’s machine translation system, which shifted from “stats focused” approaches to TensorFlow. In our own conferences, we see strong interest in training sessions and tutorials on deep learning for time series and natural language processing—two areas where organizations likely already have existing solutions, and for which deep learning is beginning to show some promise.
Machine learning is not only appearing in more products and systems, but as we noted in a previous post, ML will also change how applications themselves get built in the future. Developers will find themselves increasingly building software that has ML elements. Thus, many developers will need to curate data, train models, and analyze the results of models. With that said, we are still in a highly empirical era for ML: we need big data, big models, and big compute.
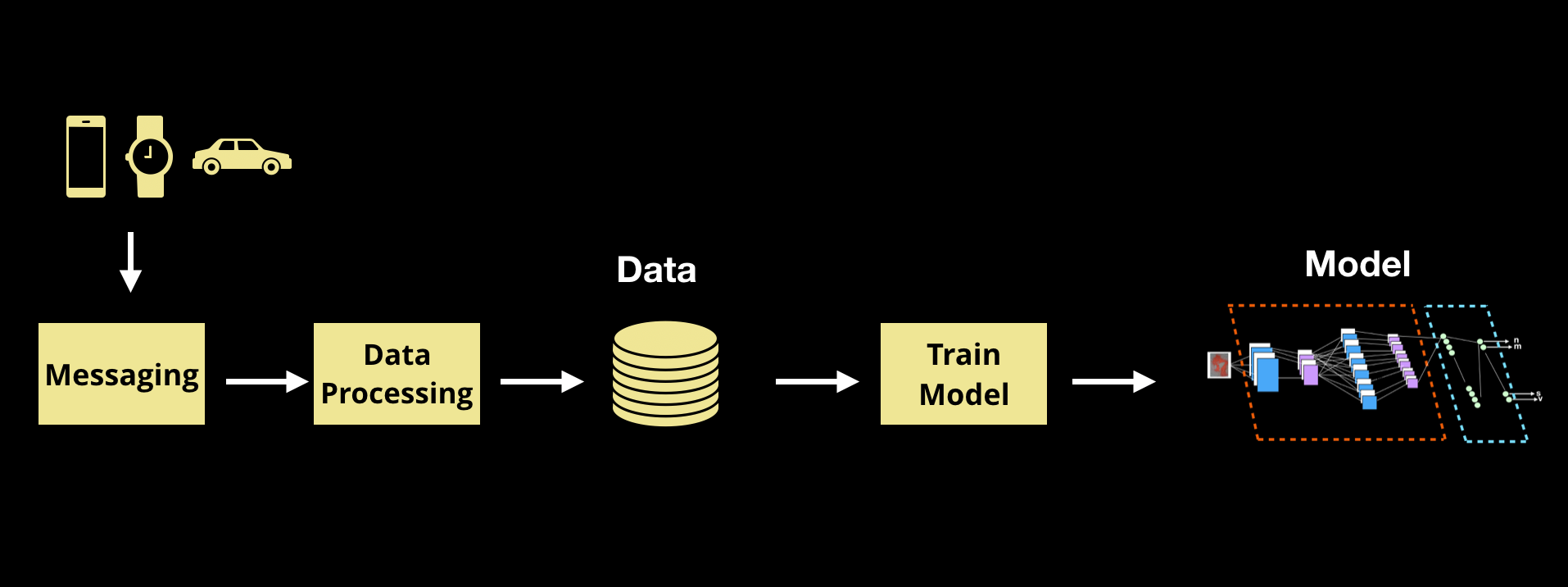
If anything, deep learning models are even more data hungry than previous algorithms favored by data scientists. Data is key to machine learning applications, and getting data flowing, cleaned, and in usable form is going to be key to sustaining a machine learning practice.
With an eye toward the growing importance of machine learning, we recently completed a data infrastructure survey that drew more than 3,200 respondents. Our goal was twofold: (1) find out what tools and platforms people are using, and (2) determine whether or not companies are building the foundational tools needed to sustain their ML initiatives. Many respondents signaled that they were using open source tools (Apache Spark, Kafka, TensorFlow, PyTorch, etc.) and managed services in the cloud.
One of the main questions we asked was: what are you currently building or evaluating?
- Not surprisingly, data integration and ETL were among the top responses, with 60% currently building or evaluating solutions in this area. In an age of data-hungry algorithms, everything really begins with collecting and aggregating data.
- An important part of getting your data ready for machine learning is to normalize, standardize, and augment it with other data sources. 52% of survey respondents indicated they were building or evaluating solutions for data preparation and cleaning. These include human-in-the-loop systems for data preparation: these are tools that allow domain experts to train automated systems to do data preparation and cleaning at scale. In fact, there is an exciting new research area called data programming, which unifies techniques for the programmatic creation of training sets.
- You also need solutions that let you understand what data you have and who can access it. About a third of the respondents in the survey indicated they are interested in data governance systems and data catalogs. Some companies are beginning to build their own solutions, and several will be presenting them at Strata Data in NYC this coming Fall—e.g., Marquez (WeWork) and Databook (Uber). But this is also an area where startups—Alation, Immuta, Okera, and others—are beginning to develop interesting offerings.
- 21% of survey respondents said they are building or evaluating data lineage solutions. In the past, we got by with a casual attitude toward data sources. Discussions of data ethics, privacy, and security have made data scientists aware of the importance of data lineage and provenance. Specifically, companies will need to know where the data comes from, how it was gathered, and how it was modified along the way. The need to audit or reproduce ML pipelines is increasingly a legal and security issue. Fortunately, we are beginning to see open source projects (including DVC, Pachyderm, Delta Lake, DOLT) that address the need for data lineage and provenance. At recent conferences, we’ve also had talks from companies that have built data lineage systems—Intuit, Lyft, Accenture, and Netflix, among others—and there will be more presentations on data lineage solutions at Strata Data in New York City this coming fall.
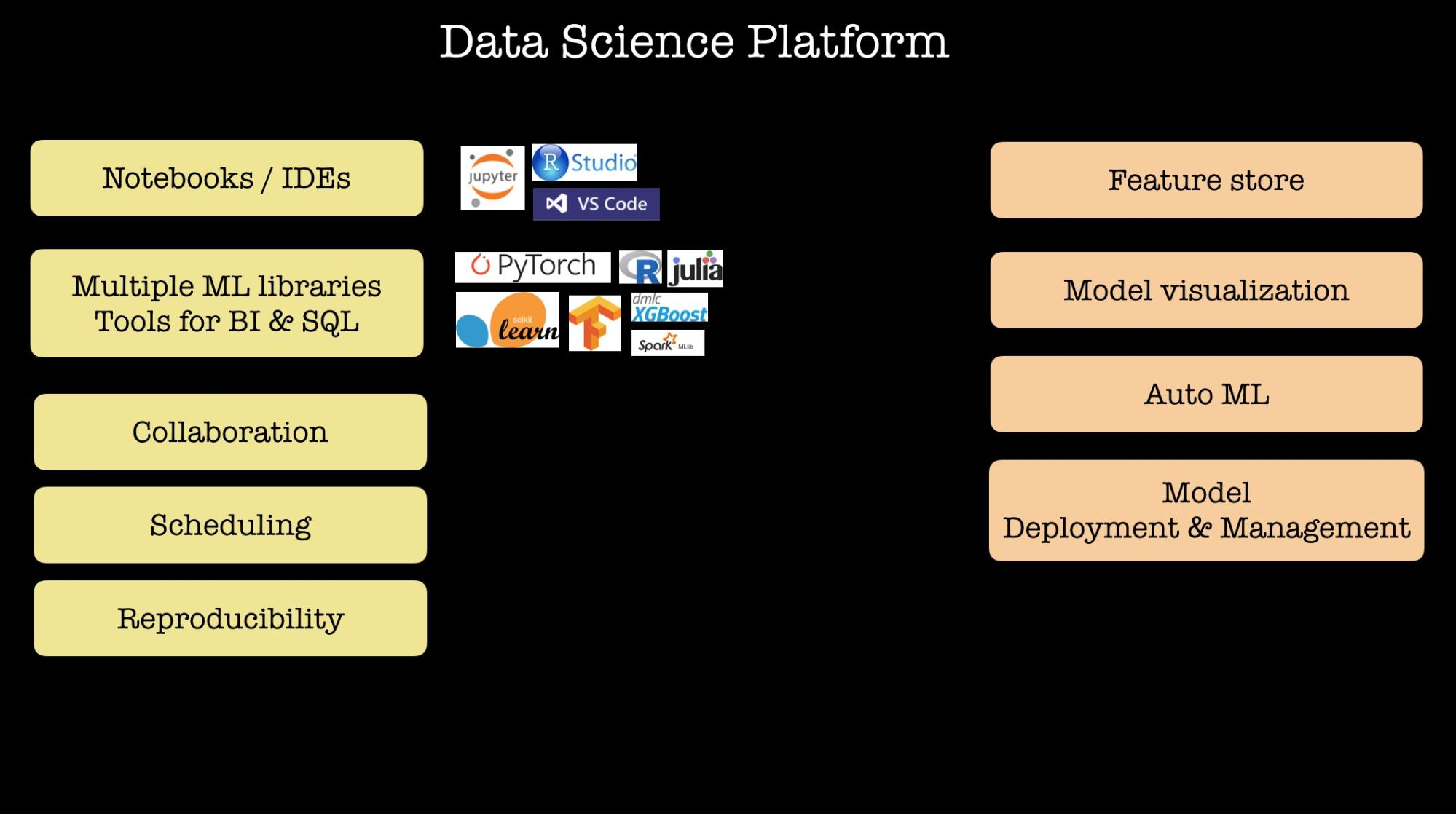
- As the number of data scientists and machine learning engineers grow within an organization, tools have to be standardized, models and features need to be shared, and automation starts getting introduced. 58% of survey respondents indicated they are building or evaluating data science platforms. Our Strata Data conference consistently features several sessions on how companies built their internal data science platforms, specifically in regard to what tradeoffs and design choices they made, and what lessons they’ve learned along the way.
What about the cloud? In our recent survey, we found a majority are already using a public cloud for portions of their data infrastructure, and more than a third have been using serverless. We have had many training sessions, tutorials, and talks on serverless at recent conferences: including a talk by Eric Jonas on a recent paper laying out the UC Berkeley view on serverless, followed by a talk by Avner Braverman on the role of serverless in AI and data applications.
Companies are just getting started building machine learning applications, and I believe the use of machine learning will continue to grow over the next few years for a couple of reasons:
- 5G is beginning to be rolled out, and 5G will lead to the development of machine-to-machine applications, many of which will incorporate ML.
- Specialized hardware for machine learning (specifically, deep learning) will come online: we are already seeing new hardware for model inference for edge devices and servers. Sometime in Q3/Q4 of 2019, specialized hardware for training deep learning models will become available. Imagine systems that will let data scientists and machine learning experts run experiments at a fraction of the cost and a fraction of the time. This new generation of specialized hardware for machine learning training and inference will allow data scientists to explore and deploy many new types of models.
There are a couple of early indicators that ML will continue to grow within companies, both point to the growing number of companies interested in productionizing machine learning. First, while we read a lot of articles in the press about data scientists, a few years ago a new role dedicated to productionizing ML began to emerge.
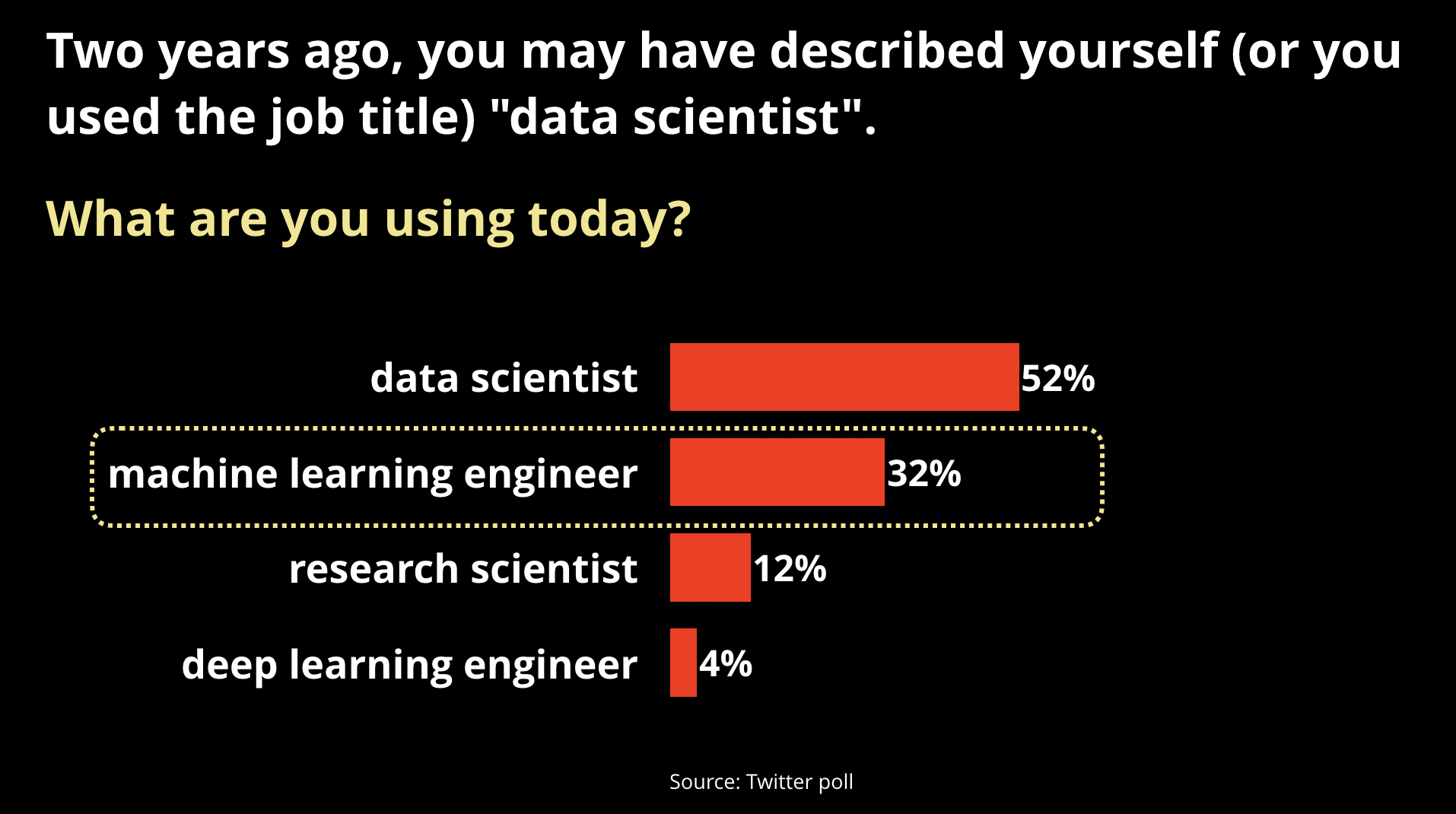
Machine learning engineers sit between data science and engineering/ops, they tend to be higher paid than data scientists, and they generally have stronger technical and programming skills. As my Twitter poll above suggests, there seem to be early indications that data scientists are “rebranding” themselves into this new job title.

Another signal that interest in ML is increasing emerges when you look at the traction of new projects like MLflow: in just about 10 months since it launched, we already see strong interest from many companies. As we noted in a previous post, a common use case for MLflow is experiment tracking and management—before MLflow, there weren’t good open source tools for this. Projects like MLflow and Kubeflow (as well as products from companies like comet.ml and Verta.AI) make ML development easier for companies to manage.
MLflow is an interesting new tool, but it is focused on model development. As your machine learning practice expands to many parts of your organization, it becomes clear that you’ll need other specialized tools. In speaking with many companies that have built data platforms and infrastructure for machine learning, a few important factors arise that have to be taken into account as you design your toolchain:
- Support for different modeling approaches and tools: while deep learning has become more important, the reality is that even the leading technology companies use a variety of modeling approaches including SVM, XGboost, and statistical learning methods.
- Duration and frequency of model training will vary, depending on the use case, the amount of data, and the specific type of algorithms used.
- How much model inference is involved in specific applications?

Just like data are assets that require specialized tools (including data governance solutions and data catalogs), models are also valuable assets that will need to be managed and protected. As we noted in a previous post, tools for model governance and model operations will also be increasingly critical: the next big step in the democratization of machine learning is making it more manageable. Model governance and model ops will require solutions that contain items like:
- A database for authorization and security: who has read/write access to certain models
- A catalog or a database that lists models, including when they were tested, trained, and deployed
- Metadata and artifacts needed for audits
- Systems for deployment, monitoring, and alerting: who approved and pushed the model out to production, who is able to monitor its performance and receive alerts, and who is responsible for it
- A dashboard that provides custom views for all principals (operations, ML engineers, data scientists, business owners)
Companies are learning that there are many important considerations that arise with the use of ML. Thankfully, the research community has begun rolling out techniques and tools to address some of the important challenges ML presents, including fairness, explainability, safety and reliability, and especially security and privacy. Machine learning often interacts and impacts users, so companies not only need to put in place processes that will let them deploy ML responsibly, they need to build foundational technologies that will allow them to retain oversight, particularly when things go wrong. The technologies I’ve alluded to above—data governance, data lineage, model governance—are all going to be useful for helping manage these risks. In particular, auditing and testing machine learning systems will rely on many of the tools I’ve described above.
There are real, not just theoretical, risks and considerations. These foundational tools will increasingly be essential and no longer optional. For example, a recent DLA Piper survey provides an estimate of GDPR breaches that have been reported to regulators: more than 59,000 personal data breaches as of February, 2019.
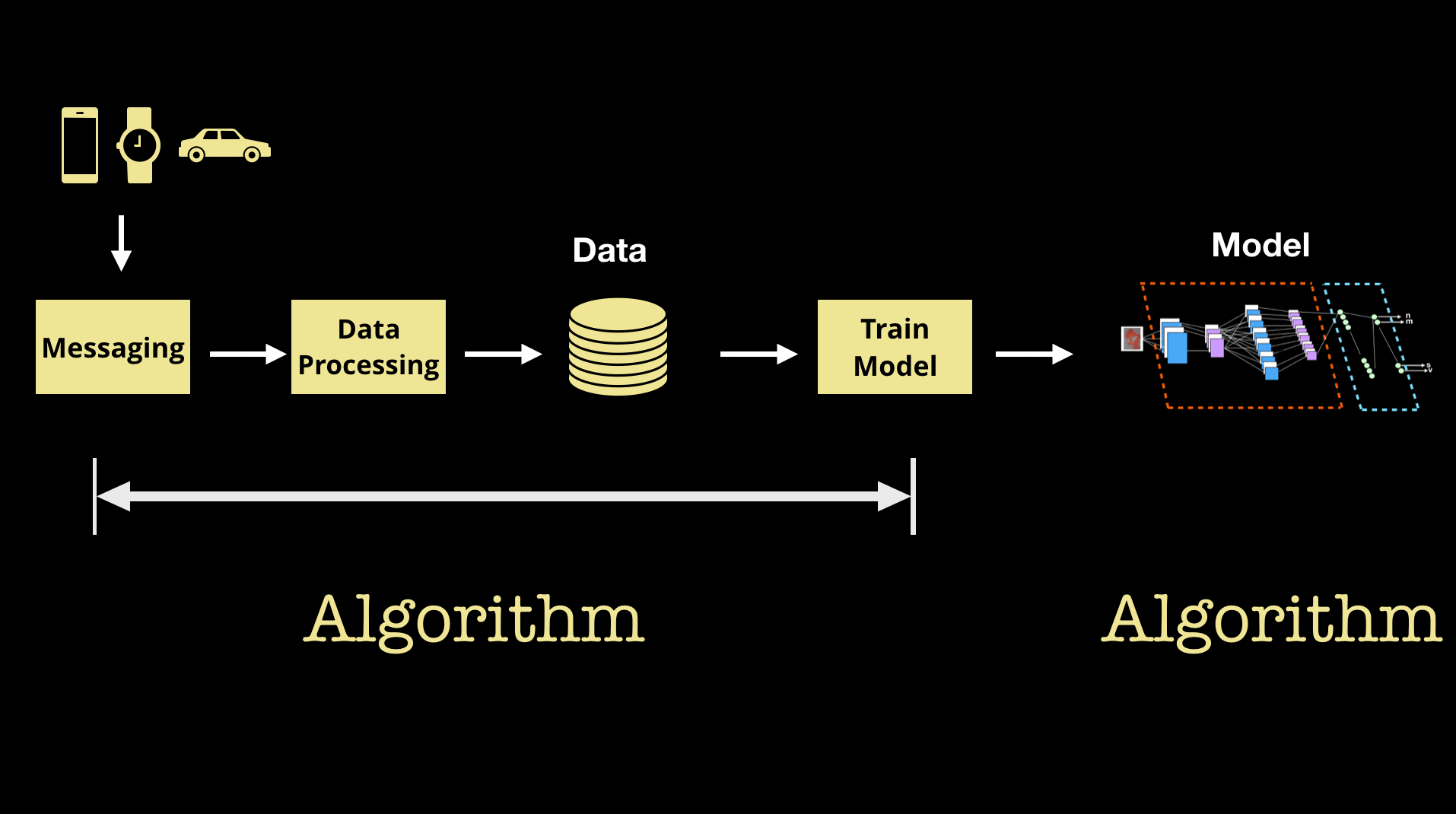
While we tend to think of ML as producing a “model” or “algorithm” that we deploy, auditing ML systems can be challenging, as there are actually two algorithms to keep track of:
- The actual model that one deploys and uses in an application of product
- Another algorithm (the “trainer” and “pipeline”) that uses data to produce the Model that best optimizes some objective function.
So, managing ML really means building a set of tools that can manage a series of interrelated algorithms. Based on the survey results I’ve described above, companies are beginning to build the important foundational technologies—data integration and ETL, data governance and data catalogs, data lineage, model development and model governance—that are important to sustaining a responsible machine learning practice.
But challenges remain, particularly as the use of ML grows within companies that are already having to grapple with many IT, software, and cloud solutions (besides having to manage the essential task of “keeping the lights on”). The good news is that there are early indicators that companies are beginning to acknowledge the need to build or acquire the requisite foundational technologies.
Related resource:
- “Sustaining machine learning in the enterprise”
- “Specialized tools for machine learning development and model governance are becoming essential”
- “Managing risk in machine learning”
- “What are machine learning engineers?”: a new role focused on creating data products and making data science work in production
- “What machine learning means for software development”
- “Deep automation in machine learning”
- “What is hardcore data science—in practice?”: the anatomy of an architecture to bring data science into production
- “Lessons learned turning machine learning models into real products and services”