How companies can navigate the age of machine learning
To become a “machine learning company,” you need tools and processes to overcome challenges in data, engineering, and models.
 Guillaume Brouscon, Compass card (source: Berkeley.edu on Wikimedia Commons)
Guillaume Brouscon, Compass card (source: Berkeley.edu on Wikimedia Commons)
Over the last few years, the data community has focused on gathering and collecting data, building infrastructure for that purpose, and using data to improve decision-making. We are now seeing a surge in interest in advanced analytics and machine learning across many industry verticals.
In this post, I share slides and notes from a talk I gave this past September at Strata Data NYC offering suggestions to companies interested in adding machine learning capabilities. The information stems from conversations with practitioners, researchers, and entrepreneurs at the forefront of applying machine learning across many different problem domains.

Learn faster. Dig deeper. See farther.
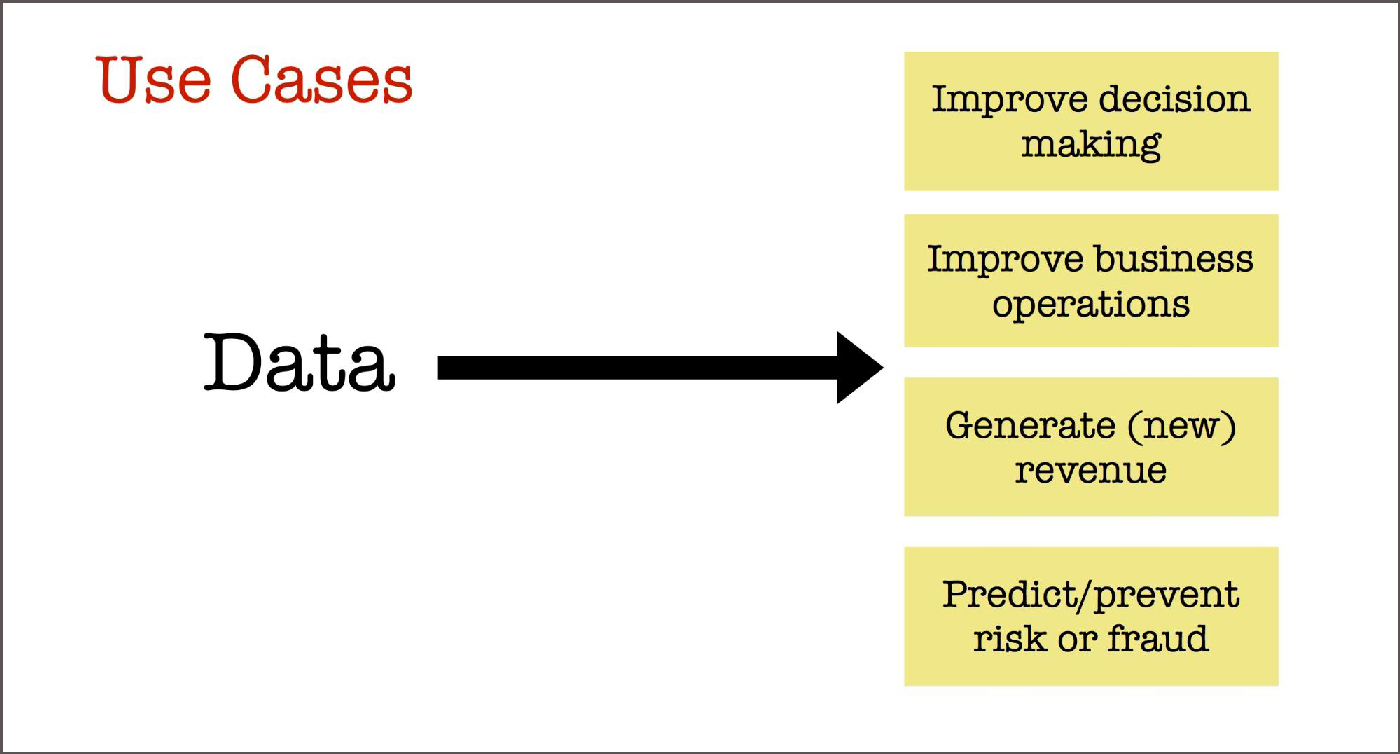
As with any technology or methodology, a successful machine learning project begins with identifying the right use case. There are many possible applications of machine learning—recommenders and reducing customer churn, for example—but a useful taxonomy for applications is as follows:
- applications that improve decision-making
- applications that lead to improvements in business operations
- applications that generate revenue
- applications that can help predict or prevent fraud or risk
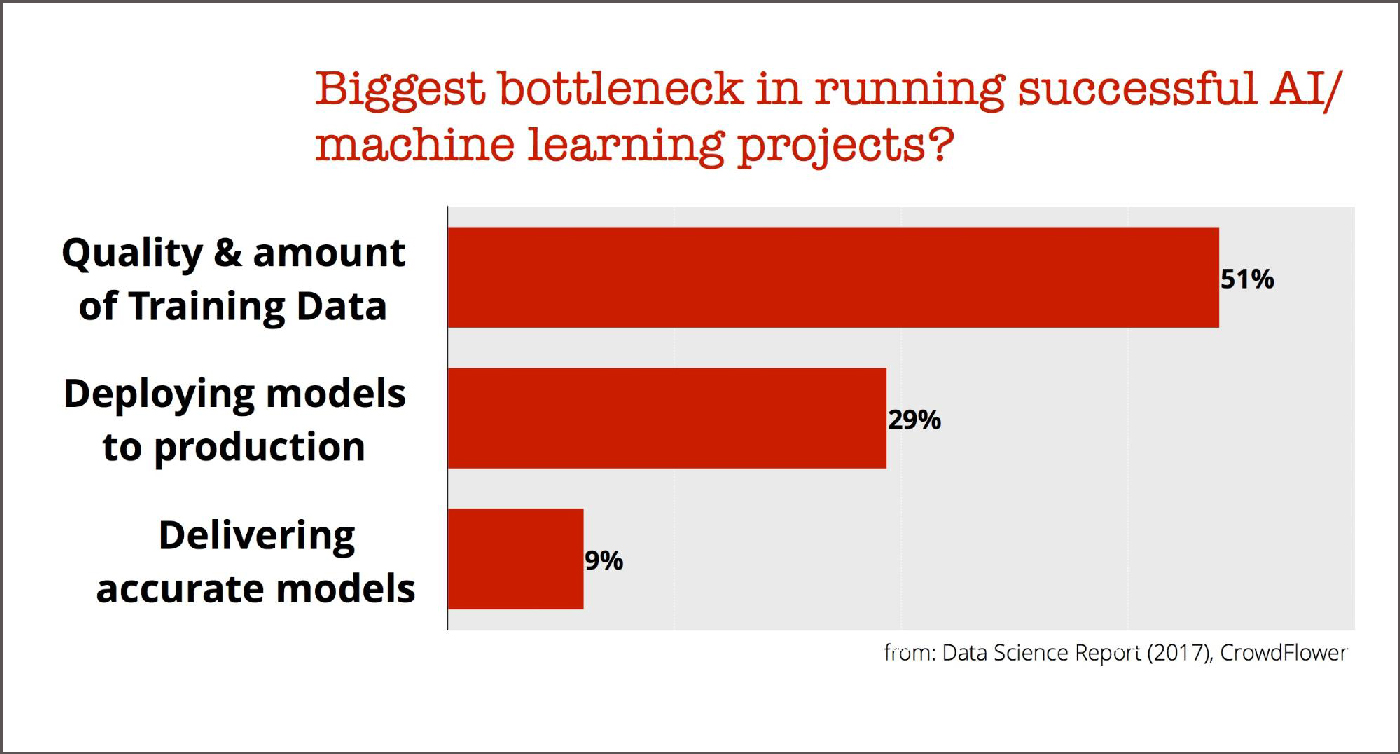
In order to become a “machine learning company,” it’s useful to familiarize yourself with the key obstacles you’ll face as you begin to deploy models. If you consult leading practitioners, three things usually come up:
- Data: Most applications today rely on supervised learning, so everything begins with good quality labeled (training) data sets.
- Engineering: How do you take a prototype and productionize it? How do you monitor a model after it gets deployed to production?
- Models: While modern machine learning libraries have made it easier to fit models to your data, what challenges remain?
I’ll go over each of this challenges in the remainder of this post.

In building labeled data sets for training your machine learning models, it’s important to use data to which you already have access. With new data sources constantly coming online, data integration is an ongoing exercise for most companies—your current investments in data infrastructure may even give you access to enough data to get started. You might also be able to enrich your existing data sets with public (open) data or data that you can purchase from third-party providers.

The good news is that the machine learning community is aware that training data is a major bottleneck. Researchers have been working on techniques that let you get started with less training data (weak supervision) or which allow you to use knowledge from one problem and use it in another setting (transfer learning).

With the growing importance of data, there are some startups and companies exploring data exchanges. Data exchanges make it possible for organizations to share some data with each other while preserving privacy and confidentiality. There are also parallel research efforts to develop secure machine learning algorithms. There are applications—fraud detection in consumer finance, for example—where shared learning on confidential data might prove valuable if privacy and security can be guaranteed.
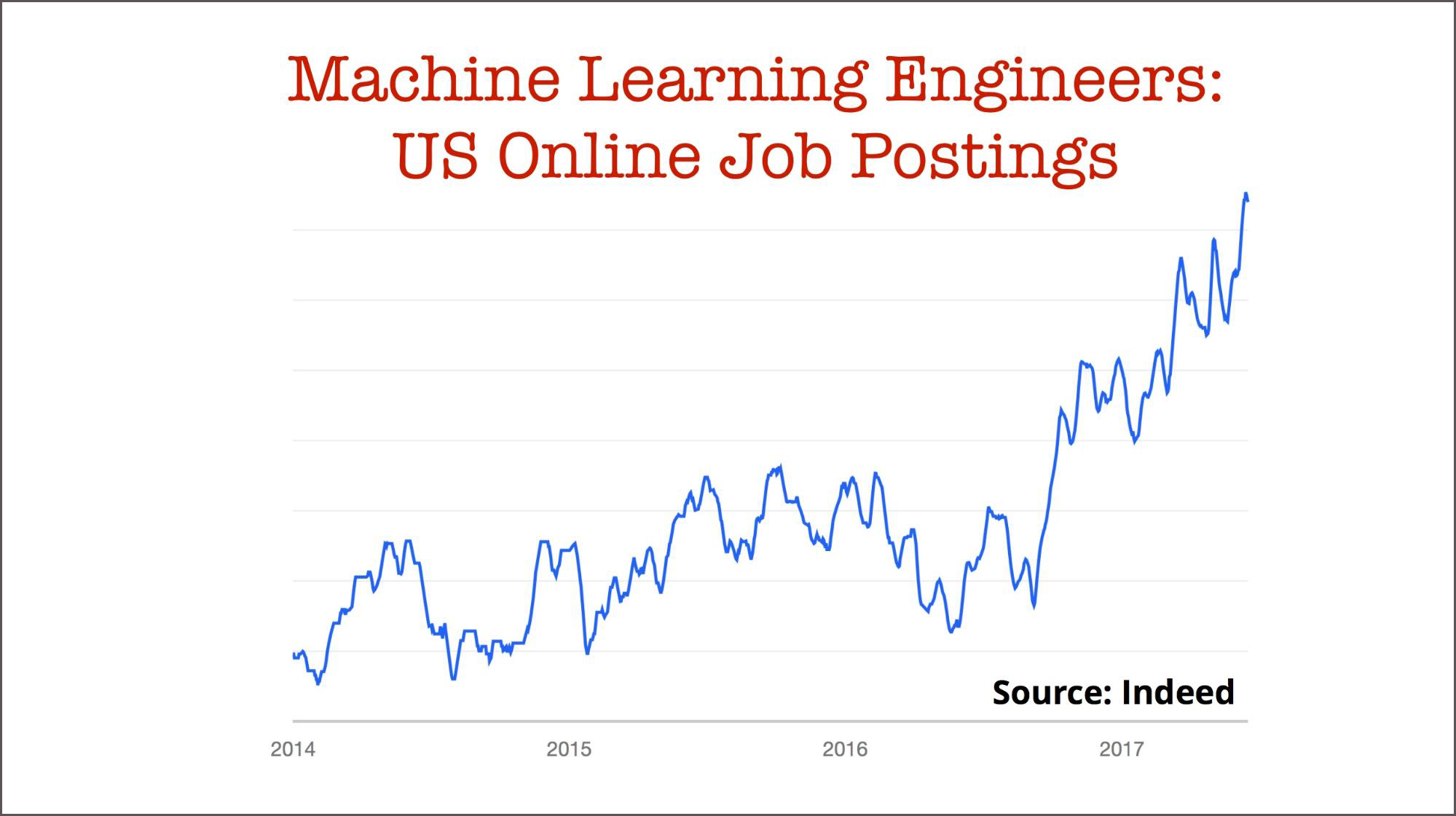
Earlier this year, we observed that companies were beginning to carve out a new role dedicated to productionizing machine learning models and monitoring their behavior afterward. But is this new role of machine learning engineer really necessary?
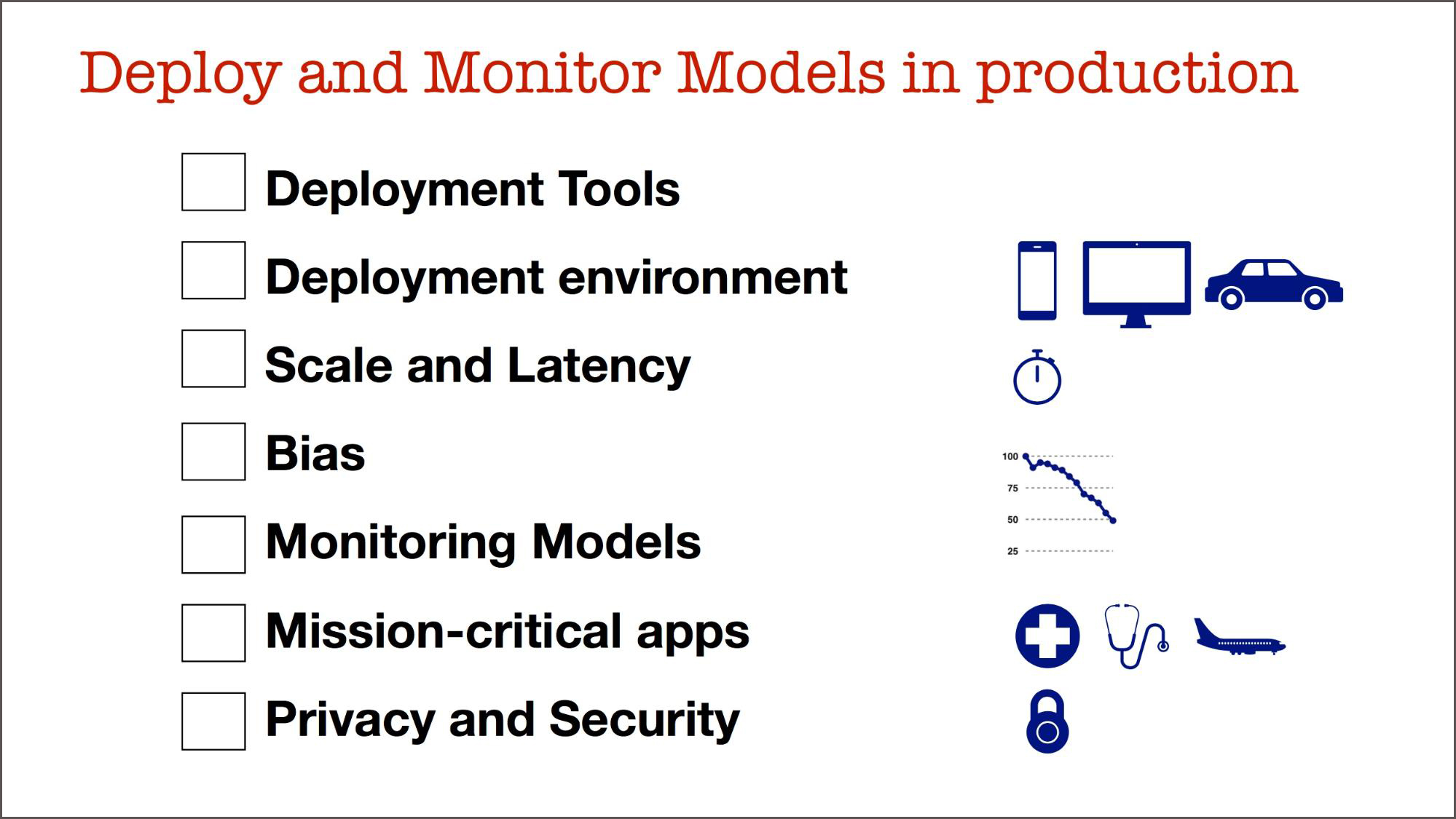
The answer for an increasing number of companies is: yes, such a specialist is required. If you create a checklist of the things you need to be aware of to productionize and monitor models, you’ll end up with an extensive set of tools and techniques. I refer you to a previous post on “The current state of applied data science” for details.
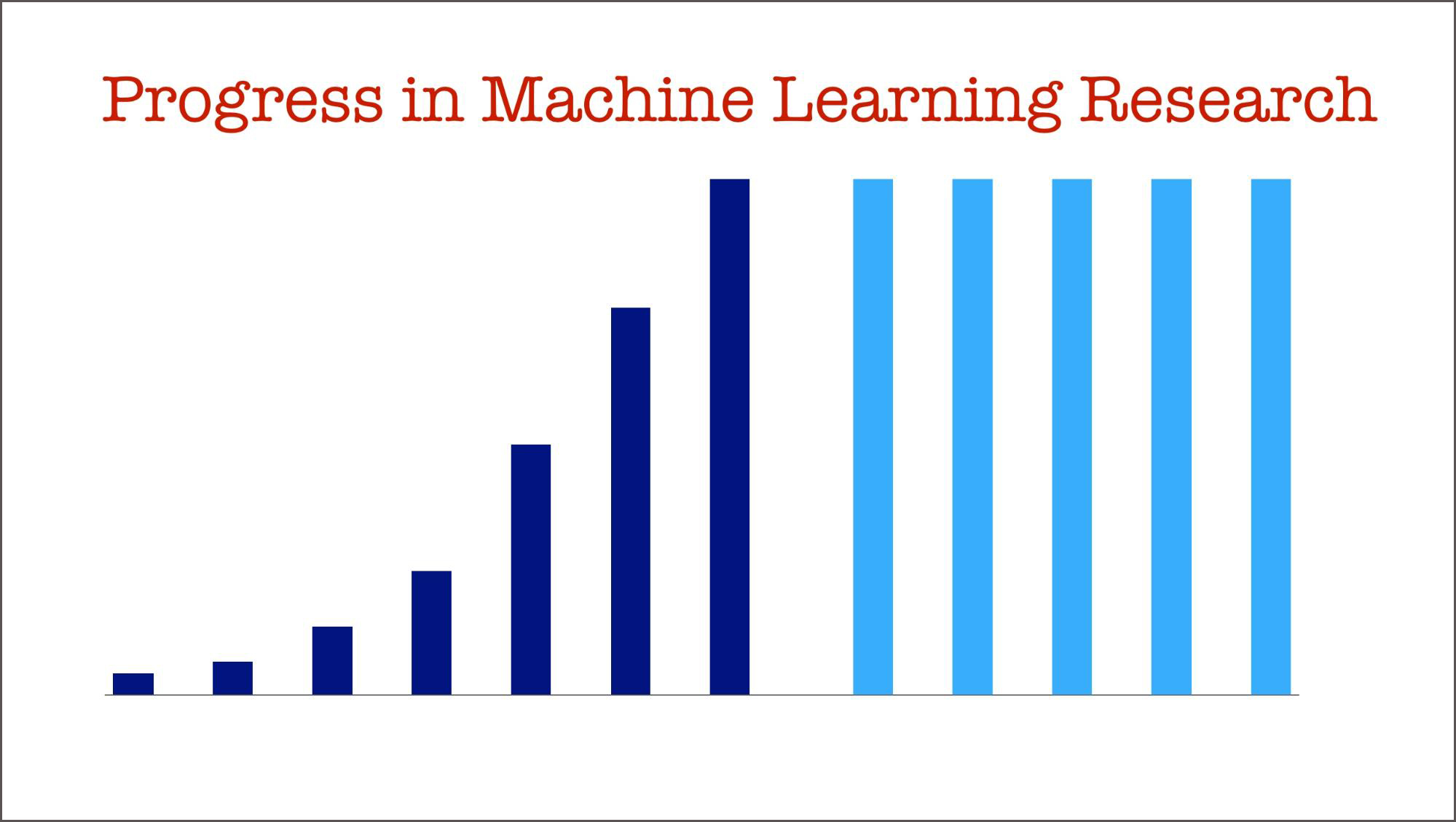
Research in machine learning is progressing at a rapid rate. It’s fair to say that most companies cannot keep up with all the new techniques and tools that researchers are releasing. Consider the following thought experiment: imagine that over the next five years, progress stalls (extremely unlikely, but humor me for a second). I contend that there are enough tools to keep companies busy for an extended period.

Take deep learning, a technique that has been successfully applied to problems in computer vision and speech. Most companies are still in the early stages of applying deep learning to data types they are familiar with (text, time series, structured data) or using it to replace existing models (including their current recommender systems). I expect to see many interesting case studies involving deep neural networks (DNN) over the next few years.

With all the excitement around deep learning, we sometimes forget there are a lot of interesting new data applications that do not rely on neural networks. Always choose the technique that suits your technical and business requirements.
As models get pushed to edge devices, I’m excited about recent work in federated and collaborative learning. Looking ahead to AI, accessible tools for online and continuous learning are going to be essential.

The data community is beginning to appreciate that there’s more to models than just optimizing a quantitative or business metric. Is the model robust against adversarial attacks? In certain applications models need to be explainable and understandable.
- Fairness: Do you understand the distribution of your training data? If you don’t, be aware that past discrimination will likely lead to future discrimination.
- Transparency: As machine learning becomes more prevalent, users are increasingly interested in knowing and having a say into what metric organizations are optimizing for.

As much as the field has progressed in recent years, there’s still a lot that researchers and theoreticians do not know. We are still very much in a “trial-and-error” era. Deep learning may have reduced the need for manual feature engineering, but there are still a lot of decisions that go into building a DNN (including network architecture and the selection of many hyperparameters).
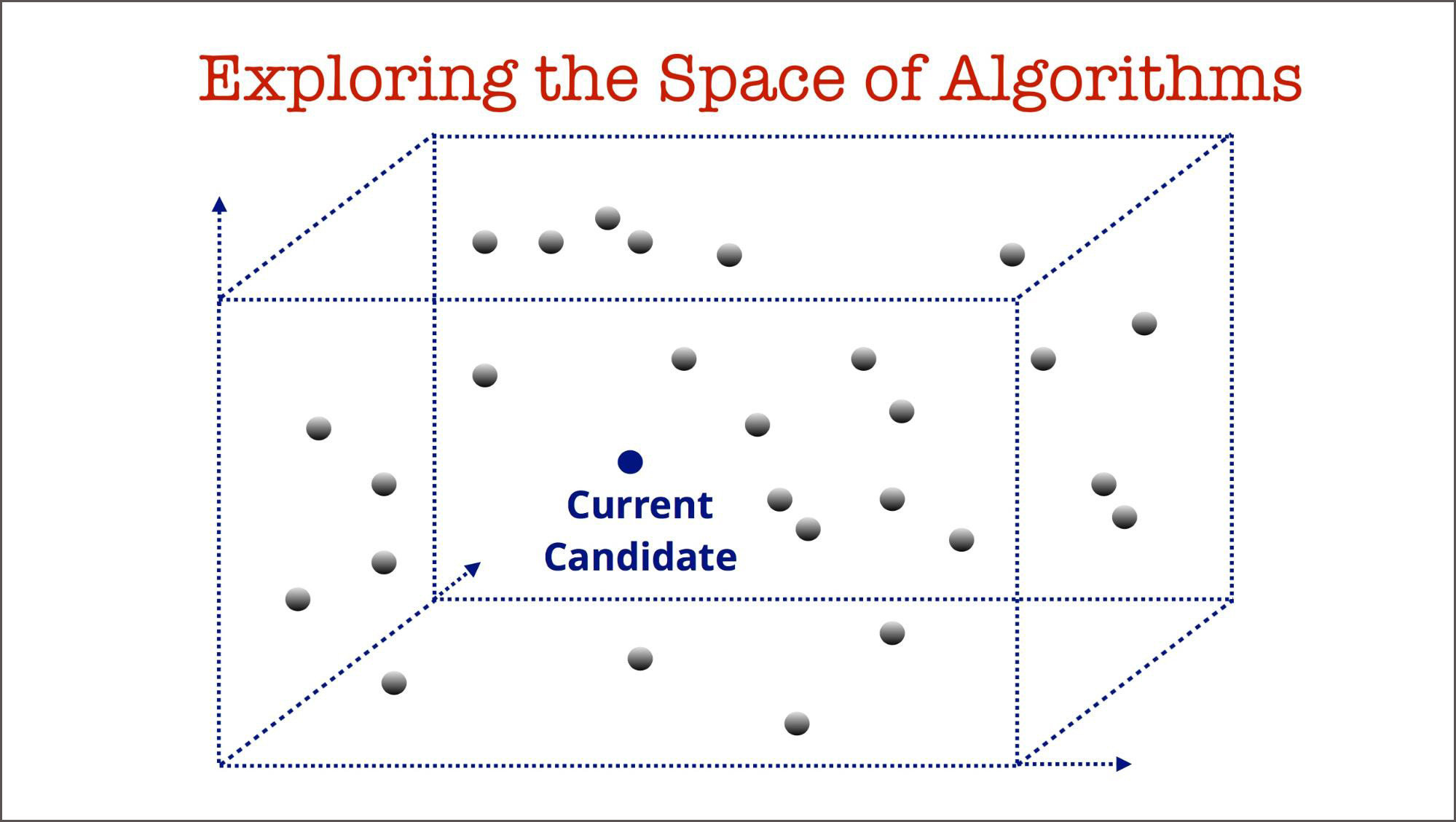
One can think of model building as exploring the space of machine learning algorithms. Companies need to be able to do their exploration in a principled and efficient manner. This means maintaining reproducible pipelines, saving metadata from experiments, tools for collaboration, and taking advantage of recent research results.
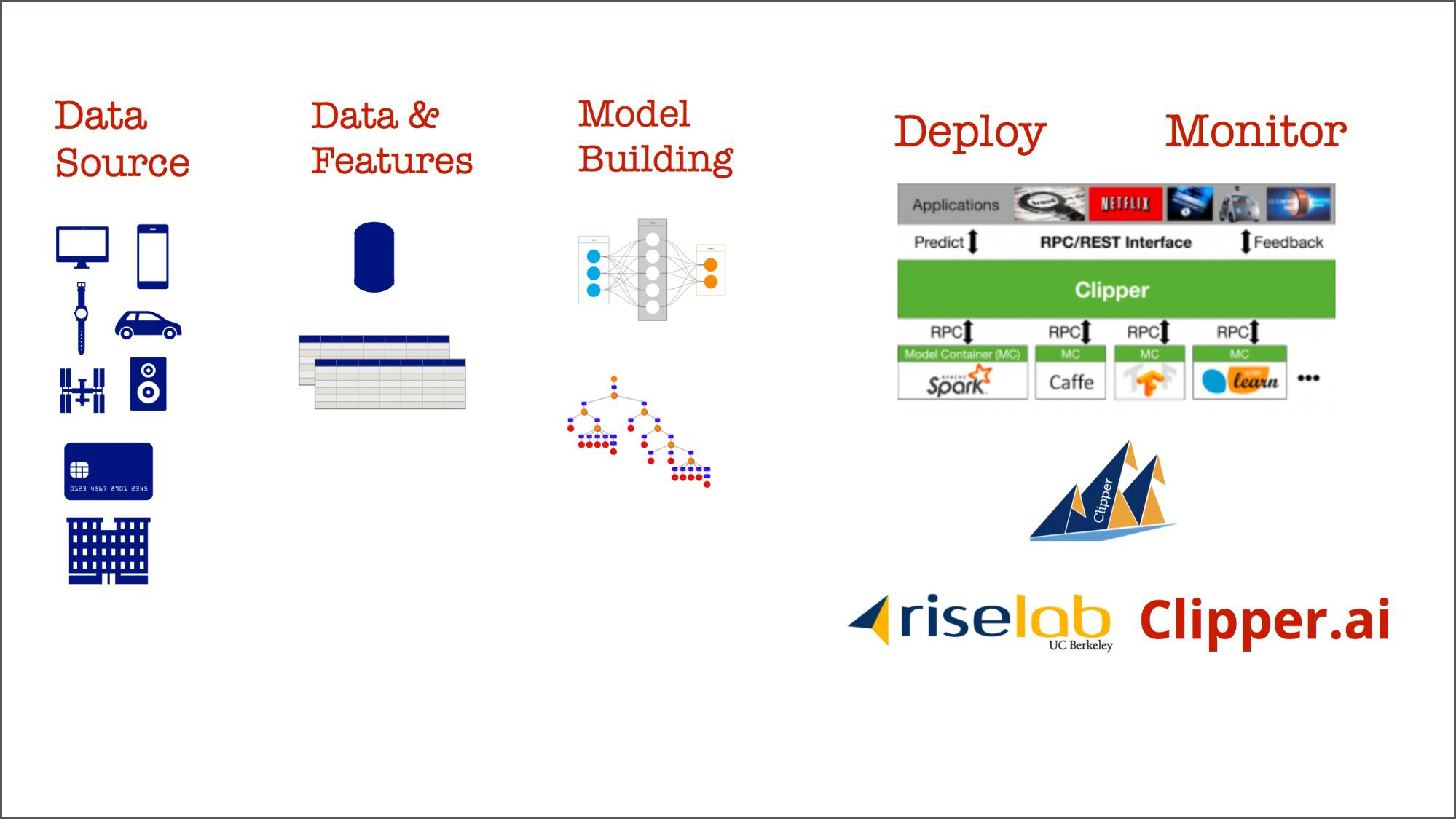
So, what are companies building to make this exploration possible? Most machine learning requires labeled (training) data, so any platform begins with robust data pipelines that feed into data storage systems that data scientists and machine learning engineers can access. Data integration is a non-trivial, ongoing exercise for all companies.
Companies are also enabling data scientists to share features and the data pipelines that produce those features. To give you a sense of the relative importance of features: it’s usually much easier to get companies to tell you what algorithm they’re using; it’s a lot harder to get them to describe what features matter most to their models!
The leading companies let their data scientists use several machine learning libraries. It would be crazy to force your data scientists into using one or two “blessed” libraries. They need to be able to run experiments, and that might mean letting them do so using a variety of libraries.
There are companies that provide tools for productionizing machine learning models and monitoring them after deployment. Companies are also building their own deployment and monitoring tools using open source technologies. If you’re looking for an open source tool for model deployment and monitoring, Clipper is a new project from UC Berkeley’s RISE Lab. It currently lets you easily deploy models written using several popular machine learning libraries. More importantly, the Clipper team is adding model monitoring very shortly. (Several companies will describe how they approach model deployment and monitoring at Strata Data San Jose in March 2018).
To become a “machine learning company,” you need tools and processes to overcome challenges in data, engineering, and models. Companies are just beginning to use and deploy machine learning across their products. Tools continue to be refined, and best practices are just beginning to emerge.