


Artificial intelligence (AI) will have a huge impact on health care. It is currently moving out of the laboratory and into real-world applications for health care and medicine. Many startups are using modern data and AI technologies to tackle problems related to workflow optimization and automation, demand forecasting, treatment and care, diagnostics, drug discovery, personalized medicine, and many other areas. Some of these companies are beginning to speak publicly about their AI initiatives; our upcoming Artificial Intelligence conferences in San Jose and London have a strong roster of speakers who will describe applications of AI in health and medicine.
AI’s transition to the real world can be challenging. This article highlights new projects and tools that can alleviate and address these challenges. We’re not trying to be comprehensive; our goal is to raise awareness of some of the bottlenecks that workers in health care and medicine will face as they adopt AI. We will focus on recent progress in foundational topics that the health care and medical communities care about: access to high-quality labeled data, developing ML models that cut across organizations, and data markets and networks.
AI’s footprint in health care
While it’s important to distinguish reality from hype (and there is a lot of hype), we see many companies making significant investments in health care. According to a 2019 World Intellectual Patent Office (WIPO) report, “Life and Medical Sciences” is the third-highest field for patent applications (the top two are “Telecommunications” and “Transportation”), with roughly 40,000 patent applications:
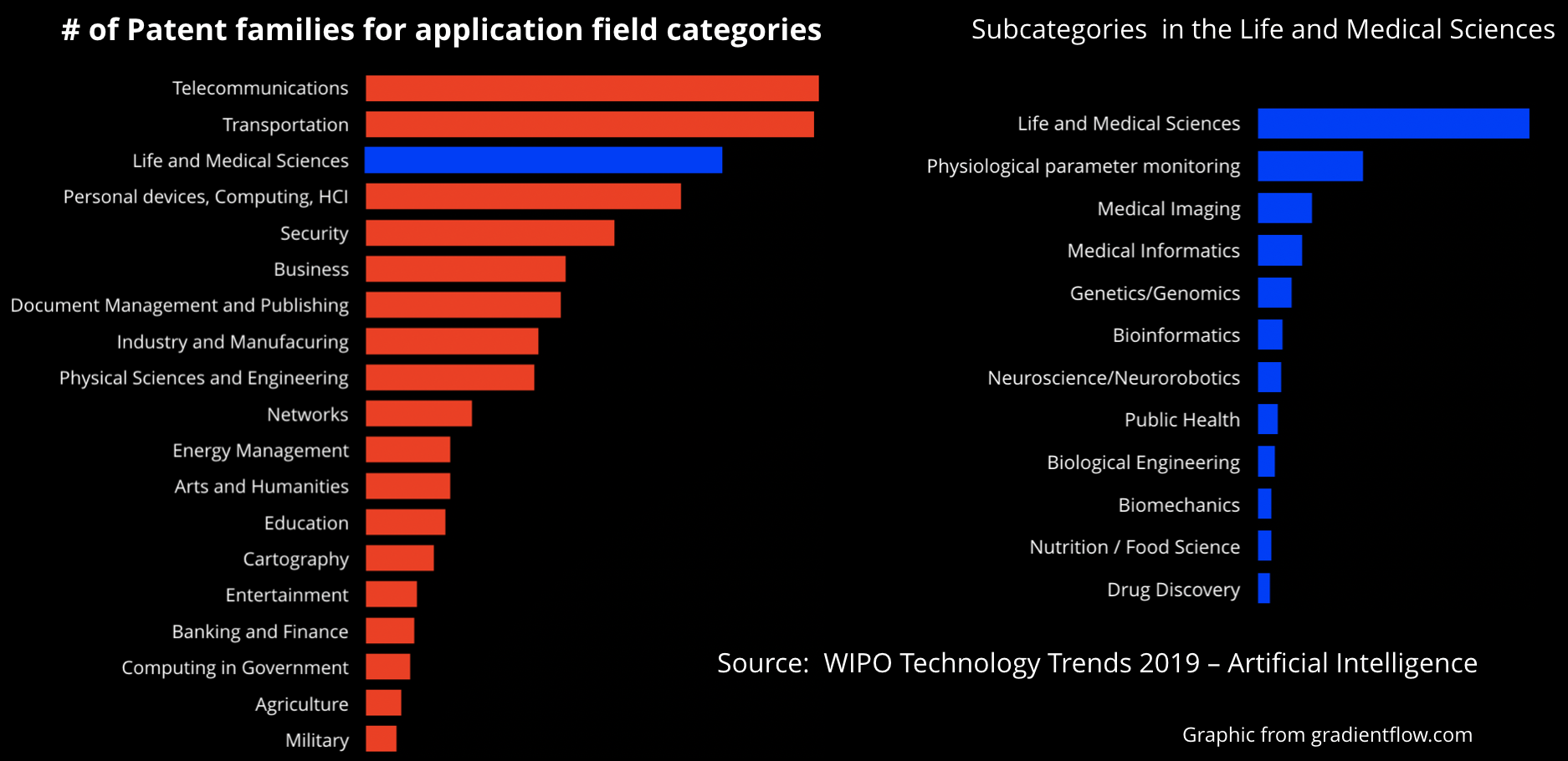
This focus on AI is important for several reasons. First, in most countries (and in many parts of the US), there is a shortage of doctors. Using AI to make a first pass at diagnostics can reduce the workload on medical staff, who are already overburdened. Second, there’s a lot of evidence that machine learning (ML) can augment medical professionals, including radiologists. Third, interest in continual health monitoring, using consumer devices like the Apple Watch, is exploding, but don’t expect a doctor or a nurse to be monitoring your data feed. If you’re about to have a heart attack or a stroke, it will be AI that analyzes the data, notes the abnormality, and generates the alarm. In health care, as in other industries, AI is the only way to scale services to match demand.
Data quality and labeling
Since the first days of the Strata Data Conference, we’ve been saying that most of the work in data isn’t playing with fancy algorithms; the hard part is acquiring high-quality data, cleaning it so that it’s usable, and labeling it. In a recent post, Ihab Ilyas and Ben Lorica described some of the challenges faced by companies that need to assemble and maintain high-quality data.
The saying goes, “Garbage in, garbage out,” but making sure the data coming into your algorithm isn’t garbage is a big job. As DJ Patil and Hilary Mason write in Data Driven, “Cleaning the data is often the most taxing part of data science, and is frequently 80% of the work.” In his keynote at O’Reilly’s AI Conference in New York in 2019, Christopher Ré noted that we’ve developed tools that make it easier to build models, we’re developing better tools for deploying AI, and more and more data sets suitable for training are becoming publicly available. We’re getting a lot better at automating the “hard” parts of developing AI, and that automation is an important part of democratization. But Ré pointed out that cleaning and labeling data hasn’t been democratized. It’s still a task that requires a lot of human time and expertise.
Medical data comes in many forms: images, audio, unstructured text, and occasionally even structured data. Regardless of the form, the problems that affect medical data aren’t fundamentally different from the problems in other industries: missing data, corrupt values, suspicious outliers, typographic errors, lack of labels, and more. It’s common for data from different silos to be contradictory. Deciding what to do with that data is difficult: a leading data scientist once told us about a cancer data set in which the strongest correlation for a cancer diagnosis was the location where the image was taken. The problem turned out to be the scanners; the scanners at every radiology facility were calibrated differently. What would it take to correct a data set like this? Data sets for training algorithms are large and can’t be edited manually. Tens of thousands, if not millions, of samples used to train deep learning algorithms are more than any human can handle.
While it doesn’t solve all the problems of data cleaning, Holoclean is a big step forward. It is an open source, machine-learning-based system for automatic error detection and repair. Holoclean has been deployed by multiple financial services and the census bureaus of several countries. Researchers have also used Holoclean on data sets related to health care (a hospital data set used in data cleaning benchmarks) and public health (a food inspection data set).
As more and more medical databases become available, labeling the data to train machine learning models becomes ever more critical. This is true for repositories comprised of medical imaging data, genomics, and other data types. Labeled data has typically been created “by hand”: humans inspect and classify each data item in the set. Data is often labeled when it is created (for example, medical images labeled with a patient ID and a diagnosis); services like Mechanical Turk are often used to classify unlabeled data. Neither approach is adequate. Mechanical Turk is only useful for classifications that don’t require expertise (labeling dogs and cats is fine, finding tumors isn’t), while labels added when the image is created may not be useful in a different context. For example, you might want to use chest X-rays to train an application for detecting broken ribs, in which case labels about lung tumors or pneumonia would be irrelevant. GE has claimed that most medical data never gets analyzed—but this data still may be useful for training if it can be properly tagged.
In addition to Holoclean, Christopher Ré and his collaborators have released an open source data programming tool called Snorkel. Snorkel automates the work of creating training data sets by labeling data programmatically, and then uses machine learning to classify and even transform images.
It’s no surprise that some of the recent applications of Snorkel have been in the life and medical sciences. In a recent project, the creators of Snorkel took a population-scale biomedical repository (the UK Biobank) to build a weakly supervised deep learning model for classifying rare aortic valve malformations using unlabeled cardiac MRI sequences. By using data programming, they were able to automate labeling for roughly 4,000 previously unlabeled MRI sequences, and avoid labeling the sequences by hand.
These early use cases for data programming should inspire others to unlock their own data. The lack of labeled data is also fueling parallel efforts in the area of algorithms. The rise in tools for data programming occurs at a time when other researchers are exploring “small sample learning” (machine learning tools that rely on smaller amounts of labeled data) for biomedical image analysis.
Besides labeling data for use in machine learning, data programming can be used to extract knowledge and information buried within existing data sources. Snorkel has been used to create training data for a machine reading system that automatically collects and synthesizes genetic associations and makes them available in a structured database. Another product of Ré’s lab, GwasKB, is an information extraction system that combs through biomedical literature to extract associations between traits and genomic variants discovered in genome-wide association studies (GWAS).
Overcoming silos with “coopetitive learning”
It’s common for data to be stuck in silos. That problem plagues many kinds of applications: medical, financial, industrial, corporate boundaries, and so on. Sometimes there are good reasons for the silos: privacy, security, and regulatory compliance are a few reasons that come to mind. But often, there isn’t any good reason not to share data. And regardless of the reason, data that is siloed in different organizations, or different groups within the same organization, almost always leads to suboptimal analytic products and services. In medicine, privacy regulations make it difficult to combine data sets from different organizations. But patients have long, complex medical histories, and frequently see many specialists, even for one problem. A comprehensive view of patients’ medical histories yields more accurate models and applications. Similarly, think about financial institutions that are trying to build fraud models. Each company has a portion of any given individual’s activities, but to build a good model for fraud, having all the financial activity in one data set would be a huge help.
At O’Reilly’s Artificial Intelligence Conference in Beijing, Ion Stoica, director of UC Berkeley’s RISELab, described new projects that allowed organizations to cooperate without actually sharing data as “coopetitive learning.” Coopetition means cooperation between competitors who are all hoping to derive mutual benefits. Coopetitive learning allows participants to build models based on a virtual data set that’s larger and richer than anything they could assemble on their own. Coopetitive learning also applies when multiple organizations have sensitive data they cannot share, but that cooperate to compute a global model (based on collective data) that is better than their individual or local models.
Two technologies can be used to implement coopetitive learning:
- Cryptography and secure multi-party computation.
- The use of trusted hardware (including specialized hardware enclaves).
RISELab currently has a few projects that fit under coopetitive learning. Helen is a coopetitive learning platform for linear regression; it uses cryptography to allow multiple partners to build a combined model without sharing the data. RISELab also has an early project for coopetitive analytics that would be appropriate for business intelligence applications.
Federated learning is a related approach to achieving the same goal. In federated learning, cooperating systems build models from their own data, and a subset of users send model-related information to a central site to be combined; the combined model is then sent back to the individual systems. More precisely, no data is shared, only ephemeral, model-related updates from a random set of users. Federated learning is already in production on Android phones, where it’s used in conjunction with differential privacy, to build predictive models for what words a user is typing. Intel is working on using federated learning for medical imaging. This project allows institutions to build shared models without sharing the images themselves. For this application, the size of the image collections is probably as important as patient privacy. Open source tools such as TensorFlow Federated now make it possible for companies to begin experimenting with federated learning.
While coopetitive learning and federated learning are similar in concept, they have significantly different use cases, and thus they rely on different algorithms and techniques. As the Android application implies, federated learning is most useful when there are many participants—literally millions. It would be useful for health care applications that run on the Apple Watch, for instance. Coopetitive learning is a better match for sharing data between a smaller number of institutions with larger data sets.
Data networks and economics
Given the demand for data and new tools for working with data at scale, we should expect new ways to cooperate to arise. Markets for exchanging data are forming, as are networks for sharing and trading data.
Computable Labs is a startup that is building tools to create data markets; the white paper “Fair value and decentralized governance of data” describes what these markets might look like and how they would work. It addresses issues like the value of data in a market, governance of the market, and protocols for recording provenance and ensuring privacy. A market for data might allow participants, ranging from individuals to institutions, to exchange their data—possibly for money, possibly for other goods and services.
RISELab’s Michael Jordan and his collaborators take the idea of data markets a step further by envisioning new kinds of two-sided markets. These markets are mediated on both sides by artificial intelligence, forming new kinds of intelligent systems that incorporate networks of humans and machines:
Consider the fact that precious few of us are directly connected to the humans who make the music we listen to (or listen to the music that we make), to the humans who write the text that we read (or read the text that we write), or to the humans who create the clothes that we wear (or wear the clothes we create). Making those connections in the context of a new engineering discipline that builds market mechanisms on top of data flows would create new “intelligent markets” that currently do not exist.
Imagine that you’re a diabetic and using a service that recommends recipes based on your medical condition. But you’re also a picky eater and don’t like a lot of the dishes the service recommends. However, you have your own service that can signal to others what you would like to eat. In Jordan’s two-sided market, your recommendation engine would talk to the other engine and negotiate a menu that’s satisfactory to both sides.
Jordan has initiated a new program to research such two-sided markets. This program draws from computer science, statistics, and economics. He discussed some recent results in this new “microeconomics meets machine learning” research program at the Artificial Intelligence Conference in San Jose.
Changing cultures
AI will certainly have a big impact on everything in health care: diagnosis, research, personal medicine, and even logistics. But taking advantage of AI requires some cultural and organizational changes.
We’ve already seen some of these changes in other disciplines, such as finance. People want decisions to be explainable, and in some cases, these explanations are legally mandated. If you’re denied a loan, you want to know why. The same is true of medical decisions: people want to understand the rationale behind any course of treatment. Explainability is only partly a research problem; while progress has been made on explainability, there is still a long way to go. The problem is also cultural: doctors (even more than bankers) have long expected patients to take their word. Medical culture has begun to change, but the change still isn’t complete.
Medical practitioners, along with patients, will also have to develop a culture that allows an AI system to participate as an assistant. Will patients be able to give their medical histories to a computer, without fearing that their privacy will be abused (as it has with social media)? ProjectsByIf, a design consultancy, has compiled a list of design patterns for responsible data sharing. Will doctors be able to collaborate with AI systems in making diagnoses? This is also a cultural shift that requires research into user interfaces and user experience. We are too accustomed to seeing AI systems as oracles that produce answers, not as participants in a discussion.
We will all benefit as medical practitioners implement AI systems: for diagnosis, for treatment planning and intervention, for drug discovery, and much more. As they do so, practitioners will face issues that are common in every industry: collecting and cleaning data, building networks that enable appropriate data sharing, preserving privacy, explaining decisions, and more. These are all exciting research areas for AI developers. But more than that, making progress in these areas requires cultural change: rethinking how we interact with each other, in addition to our intelligent assistants.
Related:
- “Lessons learned building natural language processing systems in health care”
- “Managing machine learning in the enterprise: Lessons from banking and health care”
- “The quest for high-quality data”
- “Acquiring and sharing high-quality data”
- “How AI and machine learning are improving customer experience”
- “Got speech? These guidelines will help you get started building voice applications”
- “AI adoption is being fueled by an improved tool ecosystem”
- “Toward the Jet Age of machine learning”