The quest for high-quality data
Machine learning solutions for data integration, cleaning, and data generation are beginning to emerge.
 Observation (source: PublicDomainPictures.net)
Observation (source: PublicDomainPictures.net)
“AI starts with ‘good’ data” is a statement that receives wide agreement from data scientists, analysts, and business owners. There has been a significant increase in our ability to build complex AI models for predictions, classifications, and various analytics tasks, and there’s an abundance of (fairly easy-to-use) tools that allow data scientists and analysts to provision complex models within days. As model building become easier, the problem of high-quality data becomes more evident than ever. A recent O’Reilly survey found that those with mature AI practices (as measured by how long they’ve had models in production) cited “Lack of data or data quality issues” as the main bottleneck holding back further adoption of AI technologies.
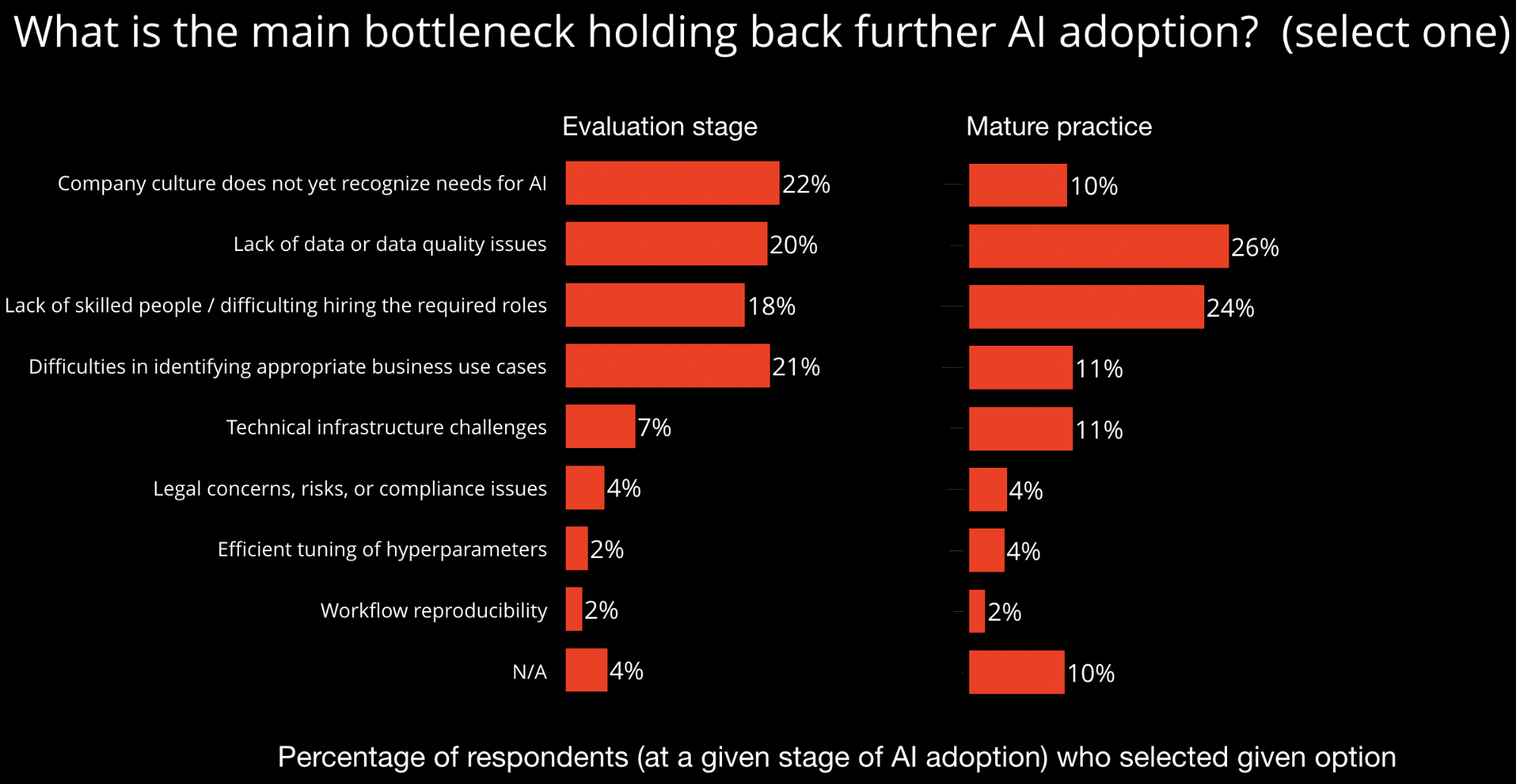
Even with advances in building robust models, the reality is that noisy data and incomplete data remain the biggest hurdles to effective end-to-end solutions. The problem is even more magnified in the case of structured enterprise data. These data sets are often siloed, incomplete, and extremely sparse. Moreover, the domain knowledge, which often is not encoded in the data (nor fully documented), is an integral part of this data (see this article from Forbes). If you also add scale to the sparsity and the need for domain knowledge, you have the perfect storm of data quality issues.

Learn faster. Dig deeper. See farther.
In this post, we shed some light on various efforts toward generating data for machine learning (ML) models. In general, there are two main lines of work toward that goal: (1) clean the data you have, and (2) generate more data to help train needed models. Both directions have seen new advances in using ML models effectively, building on multiple new results from academia.
Data integration and cleaning
One of the biggest pitfalls in dealing with data quality is to treat all data problems the same. Academic research has been more deliberate in describing the different classes of data quality problems. We see two main classes of problems, which have varying degrees of complexity, and often mandate different approaches and tools to solve them. Since they consume a significant amount of time spent on most data science projects, we highlight these two main classes of data quality problems in this post:
- Data unification and integration
- Error detection and automatic repairing/imputation
Data unification and integration
Even with the rise of open source tools for large-scale ingestion, messaging, queuing, and stream processing, siloed data and data sets trapped behind the bars of various business units is the normal state of affairs in any large enterprise. Data unification or integration refers to the set of activities that bring this data together into one unified data context. Schema matching and mapping, record linkage and deduplication, and various mastering activities are the types of tasks a data integration solution performs. Advances in ML offer a scalable and efficient way to replace legacy top-down, rule-based systems, which often result in massive costs and very low success in today’s big data settings. Bottom-up solutions with human-guided ML pipelines (such as Tamr, Paxata, or Informatica—full disclosure: Ihab Ilyas is co-founder of Tamr) show how to leverage the available rules and human expertise to train scalable integration models that work on thousands of sources and large volumes of data. We discussed some of the challenges and enablers in using ML for this class of problems in an earlier post.
The class of data unification problems has its own characteristics in terms of solution complexity: (1) the problem is often quadratic in the size of the input (since we need to compare everything to everything else), and (2) the main ML task is fairly understood and is mainly determining if two “things” are the same. These characteristics have a considerable impact on the design of the solution. For example, a complex sophisticated model for finding duplicates or matching schema is the least of our worries if we cannot even enumerate all possible pairs that need to be checked. Effective solutions for data unification problems tend to be a serious engineering effort to: (1) prune the space of possible candidates; (2) interact effectively with experts to provide training data and validate the machine decision; and (3) keep rich lineage and provenance to track decisions back for auditing, revising, or reusing for future use cases. Due to the nature of the ML task (mainly Boolean classification here), and the richness of structure, most successful models tend to be the good old “shallow” models, such as random forest, with the help of simple language models (to help with strings data). See this article on data integration status for details.
Error detection, repairing and value imputation
Siloed or integrated data is often noisy, missing, and sometimes even has contradicting facts. Data cleaning is the class of data quality efforts that focuses on spotting and (hopefully) repairing such errors. Like data integration, data cleaning exercises often have been carried out with intensive labor work, or ad-hoc rule-based point solutions. However, this class has different complexities and characteristics that affect the design of the solution: the core ML task is often far more complex than a matching task, and requires building models that understand “how data was generated” and “how errors were introduced” to be able to reverse that process to spot and repair errors.
While data cleaning has long been a research topic in academia, it often has been looked at as a theoretical logic problem. This probably explains why none of the solutions have been adopted in industry. The good news is that researchers from academia recently managed to leverage that large body of work and combine it with the power of scalable statistical inference for data cleaning. The open source HoloClean probabilistic cleaning framework is currently the state-of-the-art system for ML-based automatic error detection and repair. HoloClean adopts the well-known “noisy channel” model to explain how data was generated and how it was “polluted.” It then leverages all known domain knowledge (such as available rules), statistical information in the data, and available trusted sources to build complex data generation and error models. The models are then used to spot errors and suggest the “most probable” values to replace.
Paying attention to scale is a requirement cleaning and integration have in common: building such complex models involves “featurizing” the whole data set via a series of operations—for example, to compute violations of rules, count co-occurrences, or build language models. Hence, an ML cleaning solution would need to be innovative on how to avoid the complexity of these operations. HoloClean, for example uses techniques to prune the domain of database cell and apply judicious relaxations to the underlying model to achieve the required scalability. Older research tools struggled with how to handle the various types of errors, and how to combine the heterogeneous quality input (e.g., business and quality rules, policies, statistical signals in the data, etc.). The HoloClean framework advances the state of the art in two fundamental ways: (1) combining the logical rules and the statistical distribution of the data into one coherent probabilistic model; and (2) scaling the learning and inference process via a series of system and model optimizations, which allowed it to be deployed in census organizations and large commercial enterprises.
Data programming
Increasing the quality of the available data via either unification or cleaning, or both, is definitely an important and a promising way forward to leverage enterprise data assets. However, the quest for more data is not over, for two main reasons:
- ML models for cleaning and unification often need training data and examples of possible errors or matching records. Depending completely on human labeling for these examples is simply a non-starter; as ML models get more complex and the underlying data sources get larger, the need for more data increases, the scale of which cannot be achieved by human experts.
- Even if we boosted the quality of the available data via unification and cleaning, it still might not be enough to power the even more complex analytics and predictions models (often built as a deep learning model).
An important paradigm for solving both these problems is the concept of data programming. In a nutshell, data programming techniques provide ways to “manufacture” data that we can feed to various learning and predictions tasks (even for ML data quality solutions). In practical terms, “data programming” unifies a class of techniques used for the programmatic creation of training data sets. In this category of tools, frameworks like Snorkel show how to allow developers and data scientists to focus on writing labeling functions to programmatically label data, and then model the noise in the labels to effectively train high-quality models. While using data programming to train high-quality analytics models might be clear, we find it interesting how it is used internally in ML models for the data unification and cleaning we mentioned earlier in this post. For example, tools like Tamr leverage legacy rules written by customers to generate a large amount of (programmatically) labeled data to power its matching ML pipeline. In a recent paper, the HoloClean project showed how to use “data augmentation” to generate many examples of possible errors (from a small seed) to power its automatic error detection model.
Market validation
The landscape of solutions we presented here for the quest for high-quality data have already been well validated in the market today.
- ML solutions for data unification such as Tamr and Informatica have been deployed at a large number of Fortune-1000 enterprises.
- Automatic data cleaning solutions such as HoloClean already have been deployed by multiple financial services and the census bureaus of various countries.
- As the growing list of Snorkel users suggests, data programming solutions are beginning to change the way data scientists provision ML models.
As we get more mature in understanding the differences between the various problems of integration, cleaning, and automatic data generation, we will see real improvement in handling the valuable data assets in the enterprise.
Machine learning applications rely on three main components: models, data, and compute. A lot of articles are written about new breakthrough models, many of which are created by researchers who publish not only papers, but code written in popular open source libraries. In addition, recent advances in automated machine learning has resulted in many tools that can (partially) automate model selection and hyperparameter tuning. Thus, many cutting-edge models are now available to data scientists. Similarly, cloud platforms have made compute and hardware more accessible to developers.
Models are increasingly becoming commodities. As we noted in the survey results above, the reality is that a lack of high-quality training data remains the main bottleneck in most machine learning projects. We believe that machine learning engineers and data scientists will continue to spend most of their time creating and refining training data. Fortunately, help is on the way: as we’ve described in this post, we are finally beginning to see a class of technologies aimed squarely at the need for quality training data.
Related content:
- “Three enablers for machine learning in data unification: Trust, legacy, and scale”
- “Software 2.0 and Snorkel”
- Ihab Ilyas on “Why data preparation frameworks rely on human-in-the-loop systems”
- Alex Ratner on “Creating large training data sets quickly”
- Jeff Jonas on “Real-time entity resolution made accessible”
- “Data collection and data markets in the age of privacy and machine learning”