What are model governance and model operations?
A look at the landscape of tools for building and deploying robust, production-ready machine learning models.
 Tools (source: picjumbo_com via Pixabay)
Tools (source: picjumbo_com via Pixabay)
Our surveys over the past couple of years have shown growing interest in machine learning (ML) among organizations from diverse industries. A few factors are contributing to this strong interest in implementing ML in products and services. First, the machine learning community has conducted groundbreaking research in many areas of interest to companies, and much of this research has been conducted out in the open via preprints and conference presentations. We are also beginning to see researchers share sample code written in popular open source libraries, and some even share pre-trained models. Organizations now also have more use cases and case studies from which to draw inspiration—no matter what industry or domain you are interested in, chances are there are many interesting ML applications you can learn from. Finally, modeling tools are improving, and automation is beginning to allow new users to tackle problems that used to be the province of experts.
With the shift toward the implementation of machine learning, it’s natural to expect improvement in tools targeted at helping companies with ML. In previous posts, we’ve outlined the foundational technologies needed to sustain machine learning within an organization, and there are early signs that tools for model development and model governance are beginning to gain users.

Learn faster. Dig deeper. See farther.
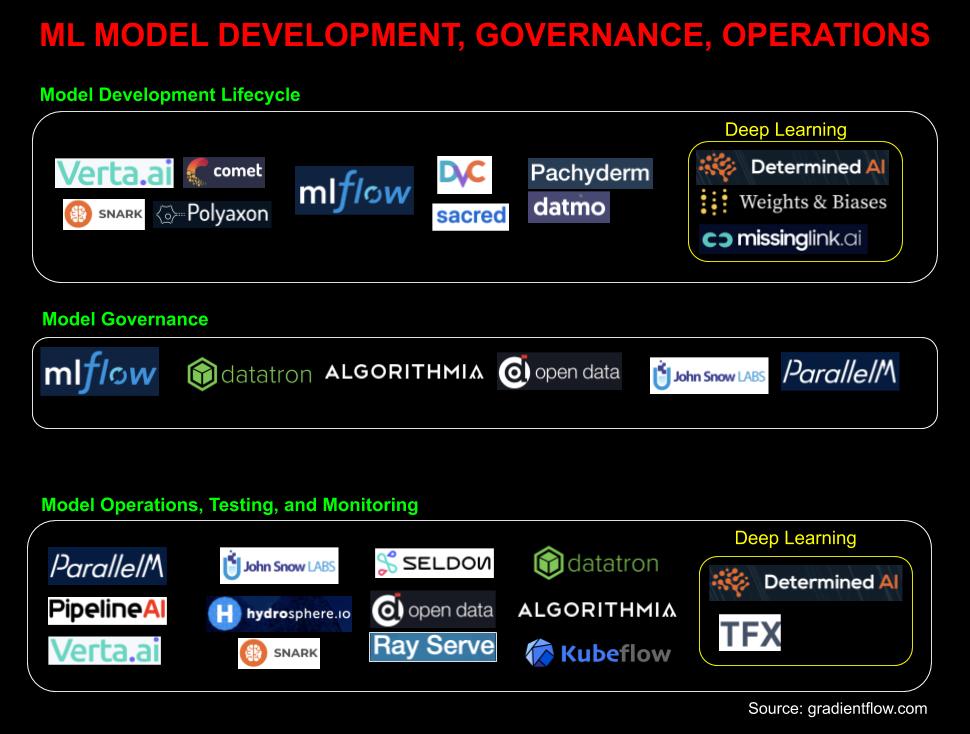
Model development
One sure sign that companies are getting serious about machine learning is the growing popularity of tools designed specifically for managing the ML model development lifecycle, such as MLflow and Comet.ml. Why aren’t traditional software tools sufficient? In a previous post, we noted some key attributes that distinguish a machine learning project:
- Unlike traditional software where the goal is to meet a functional specification, in ML the goal is to optimize a metric.
- Quality depends not just on code, but also on data, tuning, regular updates, and retraining.
- Those involved with ML usually want to experiment with new libraries, algorithms, and data sources—and thus, one must be able to put those new components into production.
The growth in adoption of tools like MLflow indicates that new tools are in fact very much needed. These ML development tools are designed specifically to help teams of developers, machine learning engineers, and data scientists collaborate, manage, and reproduce, ML experiments. Many tools in this category let users to systematically conduct modeling experiments (e.g., hyperparameter tuning, NAS) while emphasizing the ease with which one can manage, track, and reproduce such experiments.
Model governance
We are also beginning to come across companies that acknowledge the need for model governance tools and capabilities. Just as companies have long treated data as assets, as ML becomes more central to an organization’s operations, models will be treated as important assets. More precisely, models built or tuned for specific applications (in reality, this means models + data) will need to be managed and protected:
- A database for authorization and security: who has read/write access to certain models
- A catalog or a database that lists models, including when they were tested, trained, and deployed
- A catalog of validation data sets and the accuracy measurements of stored models
- Versioning (of models, feature vectors, data) and the ability to roll out, roll back, or have multiple live versions
- Metadata and artifacts needed for a full audit trail
- Who approved and pushed the model out to production, who is able to monitor its performance and receive alerts, and who is responsible for it
- A dashboard that provides custom views for all principals (operations, ML engineers, data scientists, business owners)
Model operations, testing, and monitoring
As machine learning proliferates in products and services, we need a set of roles, best practices, and tools to deploy, manage, test, and monitor ML in real-world production settings. There are some initial tools aimed at model operations and testing—mainly for deploying and monitoring ML models—but it’s clear we are still in the early stages for solutions in these areas.
There are three common issues that diminish the value of ML models once they’re in production. The first is concept drift: the accuracy of models in production degrades over time, because of changes in the real world, stemming from a growing disparity between the data they were trained on and the data they are used on. The second is locality: when deploying models to new geographic locations, user demographics, or business customers, it’s often not the case that pre-trained models work at the expected level of accuracy. Measuring online accuracy per customer / geography / demographic group is important both to monitor bias and to ensure accuracy for a growing customer base. The third is data quality: since ML models are more sensitive to the semantics of incoming data, changes in data distribution that are often missed by traditional data quality tools wreak havoc on models’ accuracy.
Beyond the need to monitor that your current deployed models operate as intended, another challenge is knowing that a newly proposed model actually delivers better performance in production. Some early systems allow for the comparison of an “incumbent model” against “challenger models,” including having challengers in “dark launch” or “offline” mode (this means challenger models are evaluated on production traffic but haven’t been deployed to production). Other noteworthy items include:
- Tools for continuous integration and continuous testing of models. A model is not “correct” if it returns a valid value—it has to meet an accuracy bar. There needs to be a way to validate this against a given metric and validation set before deploying a model.
- Online measurement of the accuracy of each model (what’s the accuracy that users are experiencing “in the field”?). Related to this is the need to monitor bias, locality effects, and related risks. For example, scores often need to be broken down by demographics (are men and women getting similar accuracy?) or locales (are German and Spanish users getting similar accuracy?).
- The ability to manage the quality of service for model inference to different customers, including rate limiting, request size limiting, metering, bot detection, and IP geo-fencing.
- Ability to scale (and auto-scale), secure, monitor, and troubleshoot live models. Scaling has two dimensions—the size of the traffic hitting the models and the number of models that need to be evaluated.
Model operations and testing is very much still a nascent field where systematic checklists are just beginning to be assembled. An overview from a 2017 paper from Google lets us gauge how much tooling is still needed for model operations and testing. This paper came with a 28-item checklist that detailed things that need to be accounted for in order to have a reliable, production-grade machine learning system:
- Features and data: seven items that include checks for privacy controls, feature validation, exploring the necessity and cost of a feature, and other data-related tests.
- Tests for model development: seven sanity checks, including checking whether a simpler model will suffice, model performance on critical data slices (e.g., region, age, recency, frequency, etc.), the impact of model staleness, and other important considerations.
- Infrastructure tests: a suite of seven considerations, including the reproducibility of model training, the ease with which models can be rolled back, integration tests on end-to-end model pipelines, model tests via a canary process.
- Monitoring: the authors list a series of seven items to ensure models are working as expected. This includes tests for model staleness, performance metrics (training, inference, throughput), validating that training and serving code generate similar values, and other essential items.
New roles
Discussions around machine learning tend to revolve around the work of data scientists and model building experts. This is beginning to change now that many companies are entering the implementation phase for their ML initiatives. Machine learning engineers, data engineers, developers, and domain experts are critical to the success of ML projects. At the moment, few (if any) teams have checklists as extensive as the one detailed in the 2017 paper from Google. The task of building real-world production-grade ML models still requires stitching together tools and teams that cut across many functional areas. However, as tools for model governance and model operations and testing begin to get refined and become more widely available, it’s likely that specialists (an “ML ops team”) will be tasked to use such tools. Automation will also be an important component, as these tools will need to enable organizations to build, manage, and monitor many more machine learning models.

Demand for tools for managing ML in the enterprise. Source: Ben Lorica, using data from a Twitter poll.
We are beginning to see specialized tools that allow teams to manage the ML model development lifecycle. Tools like MLflow are being used to track and manage machine learning experiments (mainly offline, using test data). There are also new tools that cover aspects of governance, production deployment, serving, and monitoring, but at the moment they tend to focus on single ML libraries (TFX) or modeling tools (SAS Model Manager). The reality is, enterprises will want flexibility in the libraries, modeling tools, and environments they use. Fortunately, startups and companies are beginning to build comprehensive tools for enabling ML in the enterprise.
Related content:
- “Modern Deep Learning: Tools and Techniques” – a new tutorial at the Artificial Intelligence conference in San Jose.
- “Becoming a machine learning company means investing in foundational technologies”
- “Specialized tools for machine learning development and model governance are becoming essential”
- “Lessons learned turning machine learning models into real products and services”
- Harish Doddi: “Simplifying machine learning lifecycle management”
- Ira Cohen: “Applying machine learning for insights into machine learning algorithms”
- Ameet Talwalkar: “Random search and reproducibility for neural architecture search”
- “Deep automation in machine learning”
- “We need to build machine learning tools to augment machine learning engineers”
- “Managing risk in machine learning”