Chapter 11. DOM Population
WHAT DOES THE BROWSER DO ONCE IT RECEIVES A RESPONSE FROM THE SERVER? SEVERAL OPTIONS ARE covered in this chapter. XML Data Island explains how you can store an XML document within the web page’s DOM instead of converting it into a custom data structure. It also touches on some browser-specific features that let you tie the document’s value to the display. XML responses are also the primary concern of Browser-Side XSLT, explaining how an XML document can be converted to XHTML for inclusion on the page, or modified for uploading back to the server. Browser-Side Templating is not XML-specific; it brings to JavaScript the embedded scripting template concept popular in many server environments, such as JSPs and PHP scripts.
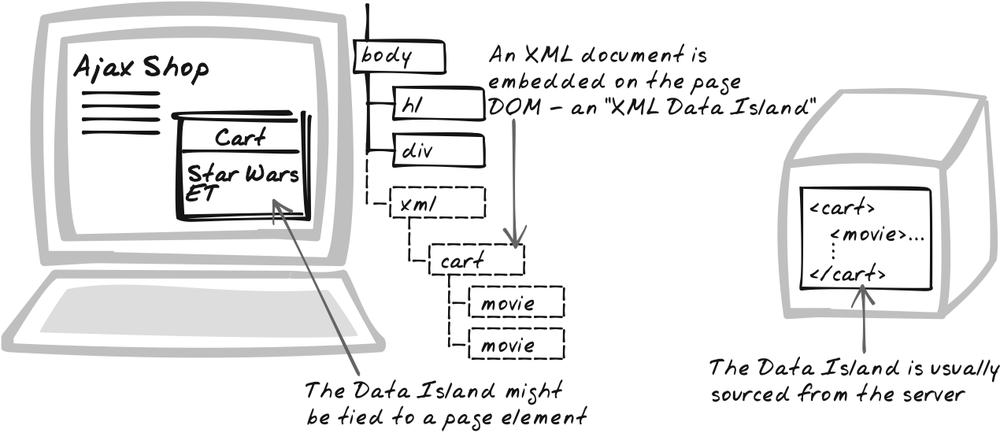
XML Data Island
⊙ Data, DOM, Storage, XBL, XML
Developer Story
Dave’s demographics viewer stores each table of statistics as an XML document. A big cache of XML documents is held within the page, one for each table. The user can rearrange the tables and switch them between visible and hidden, but all the XML metadata remains on the page. To render the tables, Dave exploits the browser’s ability to translate XML into HTML tables.
Problem
How can you render incoming XML and retain the data?
Forces
Many Ajax Apps receive XML Messages and must convert them into HTML.
The incoming data often has to be retained as well.
Solution
Retain XML responses as XML Data
Islands—nodes within the HTML DOM. Strictly speaking, an
XML Data Island is an XML document embedded in a standard XHTML
document, usually within an <xml> tag. Say the initial page
looks like this:
<html>
<head>
...
</head>
<body>
<h1>Top Score</h1>
<p>Here's the ... </p>
...
<xml id="scoreData"></xml>
</body>
</html>After an XMLHttpRequest Call (Chapter 6) brings the browser an XML Message (Chapter 9), the message is retained in the tag, using techniques described in a moment. The result is a web page DOM like this:
<html>
<head>
...
</head>
<body>
<h1>Top Scores</h1>
<p>Here's the ... </p>
...
<xml id="scoreData">
<score>
<title>Galaga"</title>
<player>AAA</player>
<score>999610</score>
<score>
</xml>
</body>
</html>How do you do something like that in JavaScript? You might
assume it’s pretty trivial, given that HTML itself is XML (or close
enough to it). But unfortunately, it’s not as easy as you’d expect
and also is browser-dependent. If you have the XML string, you can
set scoreData element’s innerHTML as the string value. If you have
only a DOM node, you can convert it to an XML string by inspecting
its innerHTML property. However,
this won’t work on all browsers and might lead to portability
problems as browsers interpret the string in different ways. An
alternative is to avoid string manipulation and directly graft one
DOM node onto another. The document object has two useful methods
here: cloneNode( ) and importNode( ). Again, there are plenty of
portability issues to consider—see Peter-Paul Koch’s discussion
(http://www.quirksmode.org/blog/archives/2005/12/xmlhttp_notes_c.html).
In most cases, the easiest, most portable, solution will be to use a
library like Sarissa (http://sarissa.sourceforge.net).
In a more general sense, this pattern involves retaining XML Messages regardless of how you store them. While the DOM is a convenient place for storage and has some value-added features described below, you could also save the XML in a normal JavaScript variable. The key characteristic of the pattern is that you’re retaining the XML Message and using it as a data structure, rather than transforming it into a custom JavaScript object.
It’s easy enough to do this, but what’s the point? Here are three applications:
- Transforming XML Data Islands to and from HTML
XML Data Islands are traditionally an IE-specific capability. From IE5, you can tie HTML controls to an embedded XML document. When the XML data changes, the HTML is also updated. And when the HTML changes—if the control is mutable—the XML is updated. In IE, to tie an HTML element to a data island, you indicate the XML data island, preceded by a
#and the field within that island. So to create aninputfield based on theplayerfield above:<input type="text" datasrc="#scoreData" datafld="player">
Now, this is an IE-specific function, but Firefox has its own alternative: eXtensible Binding Language (XBL) (http://www.zdnetasia.com/techguide/webdev/0,39044903,39236695,00.htm). The idea is similar, but the updating behavior isn’t automatic. With Mozilla, you have to create an XBL document that explicitly states how HTML controls relate to the XML.
Even without these browser-specific capabilities, it’s still fairly straightforward to make the transformation using a technology like Browser-Side XSLT (see later in this chapter).
- Retaining XML for later use
Sometimes it’s useful to retain the response for later use. For example, you can keep it to build up a Browser-Side Cache (Chapter 13). Another application is for validation—the browser might receive a raw XML document containing some form fields, then augment it with user responses before uploading it back to the server.
To store a response for later use, you could wrap it into a custom data structure. But that requires some coding effort and also complicates things a bit by adding a new data structure. When the response is an XML Message, you have an alternative: just keep the XML. While it may not be the optimal format, it’s still a structured format that you can query quite easily.
- Including an XML document on initial page load
The initial page load sequence sometimes requires an XML document. For example, the XML document might describe the initial data to be viewed or it might be a stylesheet for Browser-Side XSLT. You could go through the motions of extracting it with a further XMLHttpRequest Call, but it would be faster to load the XML as part of the initial page load. An XML Data Island is an easy way to do this. Just output the XML content wrapped inside an
<xml>tag. Alternatively, IE lets you specify a URL in thesrcattribute.
Real-World Examples
PerfectXML Demo
Darshan Singh’s IE demo (http://www.perfectxml.com/articles/xml/islandex.htm) is explained in the corresponding PerfectXML article (http://www.perfectxml.com/articles/xml/msxml30.asp). It’s a straightforward table, populated by an XML Data Island embedded in the corresponding HTML. The demo works in IE only.
Mozilla.org demo
Thad Hoffman’s Mozilla demo (http://www.mozilla.org/xmlextras/xmldataislands/example1.html) is explained in a corresponding mozilla.org article (http://www.mozilla.org/xmlextras/xmldataislands/): corresponding mozilla.org article. It simulates IE’s behavior, using standard XML parsing in JavaScript, to convert XML to HTML. The demo works only in Mozilla or Firefox.
TechRepublic demo
Philip Perkin’s example explains how to use Mozilla’s answer to XML Data Islands, eXtensible Binding Language (XBL); see Figure 11-2 (http://techrepublic.com.com/5100-3513_11-5810495.html). The code’s online and there’s a demo available (http://www.phillipweb.com/mozilla/mozilla_xbl.htm).

Code Refactoring: AjaxPatterns XML Data Island Sum
This example adds a very simple caching mechanism to the Basic Sum Demo (http://ajaxify.com/run/sum). The most recent XML response is retained as an XML Data Island, so if the user tries to resubmit the query, no server call occurs. In the absence of an XML Data Island, the script would need to retain the call and response in a custom data format. But retaining it as XML means no data format has to be created. Instead of manually navigating the document with the standard DOM API, the Interactive Website Framework (IWF) library (http://iwf.sourceforge.net) is used. IWF lets you treat the DOM object more like a custom data structure—as the following code shows, it lets you drill down using tag names rather than generic XML names.
Some minor changes are made to the XML format for easier parsing, leading to the following data format (http://ajaxify.com/run/sum/xml/dataIsland/sumXML.php?figure1=4&figure2=6):
<sum>
<inputs>
<figure1>4</figure1>
<figure2>6</figure2>
<figure3></figure3>
</inputs>
<outputs>10</outputs>
</sum>To the initial HTML, a placeholder has been introduced to retain the most recent XML response—the XML Data Island:
<xml id="sumResponse"></xml>
The XML is retrieved as a plain-text document and IWF is used to transform it into a special DOM-like format for convenient parsing. The IWF document is interrogated to get the sum, which is injected onto the DOM status element as before. Finally, the XML Data Island is populated with the XML response in its plain-text format (as opposed to a DOM object). The XML response includes the input figures as well as the resulting sum, so we’ll be able to use it later on to decide whether the figures have changed since the last response.
function onSumResponse(xml, headers, callingContext) {
var doc = new iwfXmlDoc(xml);
$("sum").innerHTML = doc.sum.outputs[0].getText( )
$("sumResponse").innerHTML = xml;
}The XML Data Island is used to decide whether a call is necessary. To make the effect more visible, the status area is blanked as soon as the user clicks submit. It’s repopulated with the retained value if it turns out the current data is the same as the previous query:
function submitSum( ) {
$("sum").innerHTML = "---";
var figures = {
figure1: $("figure1").value,
figure2: $("figure2").value,
figure3: $("figure3").value
}
var sumResponseXML = $("sumResponse").innerHTML;
if (sumResponseXML!="") {
doc = new iwfXmlDoc(sumResponseXML);
var alreadyStoredInDOM = (
figures.figure1 == doc.sum.inputs[0].figure1[0].getText( )
&& figures.figure2 == doc.sum.inputs[0].figure2[0].getText( )
&& figures.figure3 == doc.sum.inputs[0].figure3[0].getText( )
);
if (alreadyStoredInDOM) {
// No need to fetch - just retrieve the sum from the DOM
$("sum").innerHTML = doc.sum.outputs[0].getText( );
return;
}
}
ajaxCaller.get("sumXML.phtml", figures, onSumResponse, false, null);
}Alternatives
Browser-Side XSLT
Browser-Side XSLT (see the next pattern) is a more general way to transform XML into HTML. In addition, the patterns are related insofar as Browser-Side XSLT can use an XML Data Island to store stylesheets.
Browser-Side Templating
Browser-Side Templating (see later) is a general technique for converting XML or other data formats into HTML.
Browser-Side Cache
XML Data Island can be used to store a Browser-Side Cache (Chapter 13).
Metaphor
The name itself is the metaphor: an island of data amid a pool of HTML content.
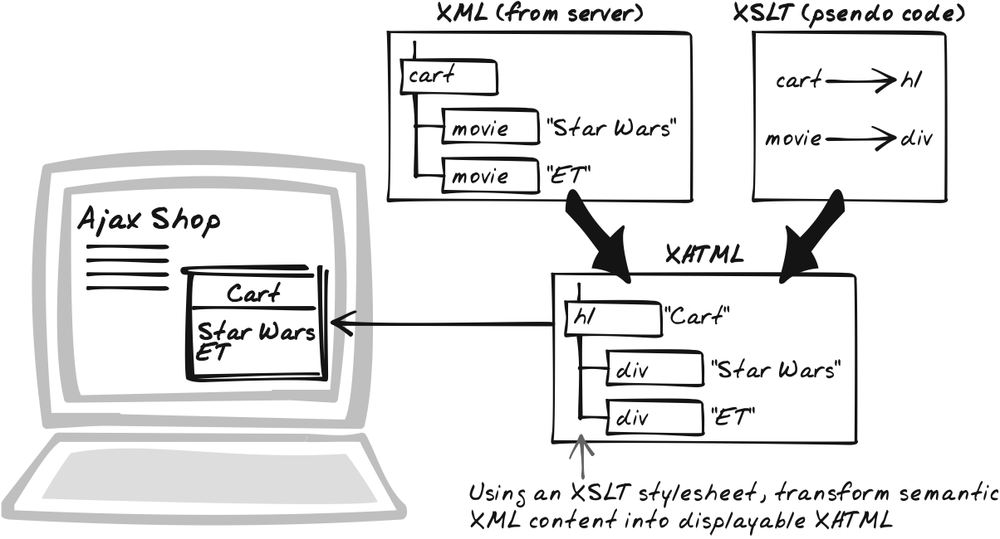
Browser-Side XSLT
⊙⊙ Presentation, Render, Style, Stylesheet, Transform, View, XML, XPath, XSLT
Developer Story
Dave has just received a request to change the weather portlet on the homepage. The image must now be on the bottom, not the top, and the wording should be more precise. The browser receives periodic weather updates in the form of an XML specification, and it uses Browser-Side XSLT to get HTML for the portlet. The stylesheet is embedded inside the static homepage HTML file. So Dave just has to tweak the XSLT to get all the browsers rendering the new design.
Forces
Many Web Services (Chapter 6) output XML Messages (Chapter 9), and Ajax clients have to convert them into HTML.
While modern browsers provide good support for XML parsing via the JavaScript’s DOM support, the direct interface is lengthy and tedious to use.
Code gets complex and error-prone when you mix HTML generation with application logic. JavaScript is not well-suited to programmatically building up HTML strings from input XML.
Solution
Apply XSLT to convert XML Messages into XHTML. XSLT—Extensible Stylesheet Language Transformations (http://www.w3.org/TR/xslt)—is a language for transforming XML documents into other forms. Here, XML is transformed to XHTML, a type of HTML that conforms to the XML standard. (You could get away with converting to plain-old HTML, but things works better if you stick to XHTML.) XSLT is fairly well-supported in modern browsers and, although browser APIs vary, there are good cross-browser toolkits available.
XSLT is well-suited to rendering XML. An XML document is designed to encapsulate a data object, and an XSLT stylesheet is a strategy for presenting such objects. Previously, XSLT has been used as a server-side technology—the server grabs some XML from a repository or another process and creates a web page by transforming it into XHTML. All that happens on the server. More recently, browsers have incorporated XSLT functionality, so the browser can automatically create an HTML page by marrying together an XML document with an XSLT stylesheet.
Browser-Side XSLT is slightly different. Here, the XML document does not constitute the contents of the entire page, but it does constitute a response from an XMLHttpRequest Call (Chapter 6). The transformation to XHTML can take advantage of the browser’s built-in XSLT support, or alternatively an XSLT processor can be implemented in JavaScript, building on the browser’s more primitive XML features. However the XSLT occurs, you’re unlikely to be implementing it yourself. There are a couple of good cross-browser libraries available, discussed in later in this chapter in "Real-World Examples.”
It’s beyond the scope of this pattern to explain XSLT in any detail; however, here’s a quick overview:
An XSLT stylesheet is itself an XML document.
An XSLT processor transforms an XML document into another form, by parsing the original document and using the stylesheet as the transformation strategy.
XSLT expressions are specified in another language, XPath. Among its capabilities, XPath provides a powerful mechanism for expressing a position within an XML document. For example, the XPath expression
/category/items/categorywill match twice when the following document is processed:<category> <items> <category name="popular"> <!-- XPath expression matches this category node --> ... </category> <category name="extras"> <!-- XPath expression matches this category node --> ... </category> </items> </category>A stylesheet is composed of rules. Each rule has a pattern that defines when it applies, and a template that dictates what will be output each time the pattern is encountered. Continuing with the example, here’s a full rule:
<xsl:template match="/category/items/category"> <div class="category" onclick="retrieveCategory('{@name}')"> <xsl:value-of select="@name"/> </div> </xsl:template>When each node is reached, the template is outputted.
@namerefers to thenameattribute on thecategorytag. So when the processing engine reaches the following XML segment:<category name="extras">
the following XHTML will be output:
<div class="category" onclick="retrieveCategory('{extras}')"> <xsl:value-of select="extras"/> </div>
This discussion has focused on the most obvious application of
Browser-Side XSLT: conversion to HTML for display to the user. You
can also convert the XML to JavaScript too, and then execute it with
the eval( ) method. For example,
it would be possible to build a native JavaScript object by
converting some XML into some code that creates the object.
Decisions
How will you obtain the XSLT stylesheet?
Any Browser-Side XSLT processor requires two things:
An XML document
An XSLT stylesheet
Both are usually passed in to the XSLT processor as plain strings representing the entire document (as opposed to URLs, say). The XML document usually comes from an XMLHttpRequest Call (Chapter 6), but where does the XSLT stylesheet come from? You have a few options.
- Store the stylesheet server side
You can hold the file server side, and then use an independent XMLHttpRequest Call (Chapter 6) to retrieve it. In this case, you’ll probably want to keep the copy in a Browser-Side Cache for later use. Also, if you use an asynchronous call, which is advisable, there’s a potential race condition: you need to ensure the stylesheet is retrieved before any transformation takes place, possibly with a loop that keeps checking for it. The later section "Code Refactoring: AjaxPatterns XSLT Drilldown Demo" demonstrates this approach.
- Handcode the stylesheet as a JavaScript string
You can build up a string in JavaScript, though this leads to messy code that blurs the distinction between logic and presentation. There is one benefit of this approach: the stylesheet is dynamic, so could potentially vary according to the current context.
- Store it inside the initial HTML document
You can tuck the stylesheet somewhere inside the initial HTML document where it won’t be seen by the user. Techniques include:
Make it the content of an invisible textarea.
Store it in an XML Data Island the within document.
Real-World Examples
Google Maps
Google Maps (http://maps.google.com) is the most famous application of Browser-Side XSLT, where the technology is used to transform data such as addresses and coordinates into HTML. Based on this work, the Googlers have also released Google AJAXSLT (http://goog-ajaxslt.sourceforge.net), an open source framework for cross-browser XSLT and XPath.
Kupu
Kupu (http://kupu.oscom.org/demo/) is an online word processor (Figure 11-4) that stores content in XML and renders it with Browser-Side XSLT, using the Sarissa framework described shortly (Figure 11-4).

AJAX-S
Robert Nyman’s AJAX-S (http://www.robertnyman.com/ajax-s/) is a slideshow manager, where raw content is maintained in XML, and transformed to slides using Browser-Side XSLT.
Sarissa framework
Sarissa (http://sarissa.sourceforge.net/doc/) is an
open source, cross-browser framework for all things XML. XSLT is
supported as well as XML parsing, XPath queries, and XMLHttpRequest invocation.
Code Refactoring: AjaxPatterns XSLT Drilldown Demo
This refactoring is similar to that performed in Browser-Side Templating but uses XSLT instead of templating. The starting point, the Basic Drilldown Demo (http://ajaxify.com/run/portal/drilldown), converts XML to HTML using a series of JavaScript string concatenations. The callback function, which receives the XML, therefore performs lots of string concatenations as follows:
html+="<div id='categoryName'>" + categoryName + "</div>";
In this refactoring, all that string handling is replaced by an XSLT transformation using the Sarissa library (http://sarissa.sourceforge.net/doc/). One slight complication is the stylesheet—how does the script access it? The solution here is to keep it as a separate file on the server and pull it down on page load:
var xsltDoc;
window.onload = function( ) {
...
ajaxCaller.getXML("./drilldown.xsl",function(response) {xsltDoc = response;});
...
}As was mentioned earlier in "Decisions,” there’s a race condition here, because the XML response may come before the stylesheet. To deal with this, the drilldown callback function keeps looping until the stylesheet is defined:
function onDrilldownResponse(xml) {
if (xsltDoc==null) {
setTimeout(function( ) { onDrilldownResponse(xml); }, 1000);
return;
}
...
}Beyond that, the callback function is simply an invocation of Sarissa’s XSLT processor:
function onDrilldownResponse(xml) {
...
var xsltProc = new XSLTProcessor( );
xsltProc.importStylesheet(xsltDoc);
var htmlDoc = xsltProc.transformToDocument(xml);
var htmlString = Sarissa.serialize(htmlDoc);
$("drilldown").innerHTML = htmlString;
}The only thing left is the stylesheet itself, shown below. I’ll spare a walkthrough. The output here is the same as that in the Basic Drilldown Demo (http://ajaxify.com/run/portal/drilldown), which generates the HTML using manual JavaScript processing.
<?xml version="1.0"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<body>
<xsl:apply-templates/>
</body>
</html>
</xsl:template>
<xsl:template match="/category">
<div id='categoryName'><xsl:value-of select="@name" /></div>
<xsl:if test="@parent!=''">
<div id='parent' onclick='retrieveCategory("{@parent}")'>
Back to <xsl:value-of select="@parent" />
</div>
</xsl:if>
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="/category/items/link">
<div class="link"><a href="{url}"><xsl:value-of select=
"name"/></a></div>
</xsl:template>
<xsl:template match="/category/items/category">
<div class="category"
onclick="retrieveCategory('{@name}')">
<xsl:value-of select="@name"/>
</div>
</xsl:template>
</xsl:stylesheet>Alternatives
Browser-Side Templating
Browser-Side Templating (see the next pattern) is a solution for rendering content in any format—plain-text, XML, and so on. You could extract key variables from an XML Message and render them with a templating engine. Browser-Side Templating is a simpler approach as it builds on existing JavaScript knowledge, while Browser-Side XSLT allows for more powerful transformations and avoids the cumbersome querying of XML in JavaScript.
Related Patterns
XML Message
Browser-Side XSLT is driven by the need to deal with incoming XML Messages (Chapter 9).
Metaphor
Browser-Side XSLT is a strategy for presenting abstract data in a human-readable form. People do this all the time with diagrams. For instance, a family tree is one way to render the abstract set of relationships in a family. A UML diagram is a visual representation of some (real or imagined) code.
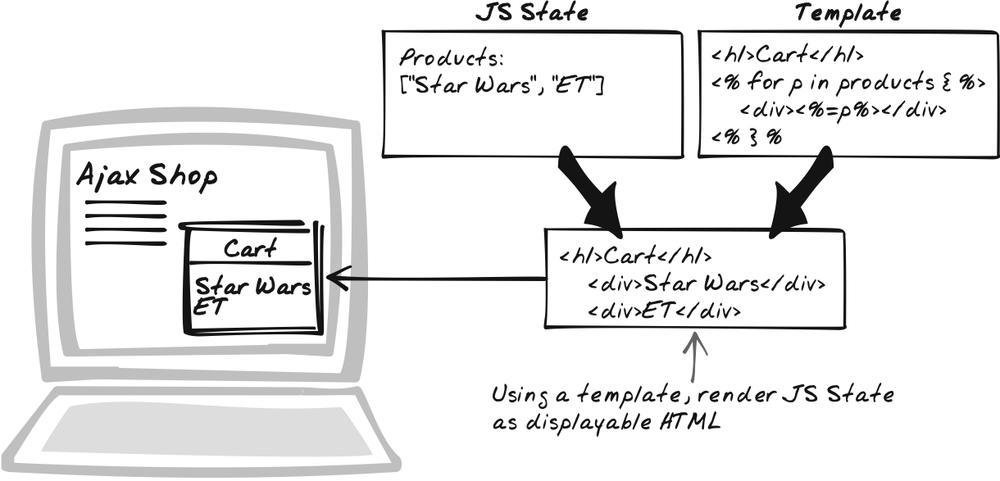
Browser-Side Templating
⊙ Pages, Presentation, Render, Template, Transform, View
Developer Story
Devi has just been assigned to make the user profile
more verbose. The original version takes an XML document about the
user and renders it all with a jungle of JavaScript code that
accumulates a big HTML string amid if-then conditions and loops. Devi decides
the first step is to refactor all that into a Browser-Side Template,
isolating the HTML generation. As a result, introducing the new
content becomes trivial.
Problem
How can you separate presentation from logic?
Forces
Generating HTML in the browser is a good way to isolate all presentation logic in one tier.
To render context-specific information within the browser, you need to rely on a dynamic mechanism. It’s not feasible to just set an element’s
innerHTMLproperty to point to a static HTML page.Code gets complex and error-prone when you mix HTML generation with application logic. JavaScript is not well-suited to programmatically building up HTML strings.
Solution
Produce templates with embedded JavaScript and call on a browser-side framework to render them as HTML. The template contains standard HTML and allows context variables to be substituted in at rendering time, which gives it more flexibility than a static HTML page. In addition, you can also intersperse JavaScript code. For instance, generate an HTML table by running a loop—one iteration for each row.
The templating idea has been used for a long time on the Web, which is evident in frameworks like Perl’s HTML::Mason, Java’s JSPs, and the layout of languages like PHP and ASP. All of these are syntactic sugar of the “killer app” variety. That is, they technically don’t add any new functionality, but make life a whole lot easier for web developers. In the Java world, the standard complement to JSPs is servlets. Here’s how you’d write a message in a servlet:
package com.example.hello;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class HelloServlet extends HttpServlet {
protected void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html");
PrintWriter out = response.getWriter( );
out.println("<html>");
out.println("<head><title>Hi Everyboddeee!</title></head>");
out.println("<body>");
out.println(" Your name is <%context.name %>\""
+ request.getAttribute("name") +
"\".");
out.println("</body></html>");
out.close( );
}
}Not pretty. There are printing commands all over the place, escaped special characters, quote marks, and error handling. What happened to the simplicity of HTML? Code like this is best avoided because it mixes presentation with logic. The following JSP, using the standard JSTL library, achieves the same thing in a more lucid, maintainable style:
<%@ taglib prefix="c" uri="http://java.sun.com/jstl/core" %>
<html>
<head><title>Hi Everyboddeee!</title></head>
<body>
Your name is <c:out value="$name" />.
</body>
</html>With many Ajax Apps, it’s deja vu. Often, the browser receives
a raw response such as a Plain-Text Message
(Chapter 9) or an XML
Message (Chapter 9)
and must then render it as HTML, ruling out server-side templates. A
common approach is to manually traverse the structure
programmatically and create some HTML to be injected via some
element’s innerHTML property. The
old “bucket of print statements” strikes again.
The solution here recapitulates in the browser what all those server-side templating frameworks offer. A templating framework, while not immensely difficult to implement, is probably not the sort of thing you’d want to write yourself. This pattern, then, is only made possible by the fact that frameworks already exist, and some are mentioned in the following examples. Here’s a quick example of a template in Ajax Pages format (http://ajax-pages.sourceforge.net/):
<html>
<head><title>Hi Everyboddeee!</title></head>
<body>
Your name is <%= name %>.
</body>The JavaScript template is in similar format to the JSP above and follows standard conventions of templates. That is:
Any code is contained inside
<%and%>tags.Any expression to be substituted in the HTML is contained inside
<%=and%>tags.To apply the template, create a processor and pass it a context. With Ajax Pages:
var ajp = new AjaxPages( ); ajp.load("template.ajp"); var processor = ajp.getProcessor( ); element.innerHTML = processor({name: username});
Decisions
How will you obtain the template?
You’ll generally pass the template to the processor as a string, but where does that string come from? The options here are the same as with Browser-Side XSLT (see earlier in this chapter): store it server side; hardcode it as a JavaScript string; and store it inside the HTML document. See the "Decisions" section in Browser-Side XSLT for more details.
Will the template include any code? How much?
Code in templates is somewhat frowned upon because it defeats the purpose of templates as a place to isolate the presentation. Certainly, more complex calculation are best performed in plain JavaScript or on the server side, but if managing the display requires some logic, a template is a reasonable place to put it. Examples include:
- Loops
A collection is passed in to the template. The template outputs the entire collection by looping over the collection. It’s much better for the template to perform the looping, rather than calling JavaScript, because there is usually some HTML before and after the loop. If JavaScript outputted that HTML, there would be too much coupling between the JavaScript and the template.
- Conditionals
if-thenconditions andswitchstatements are sometimes better performed by the template too. However, if the body of each branch is long, you might prefer to include a different template for each.
How to prepare the template’s context?
In the case of Ajax Pages (http://ajax-pages.sourceforge.net/),
you’re allowed to pass in a context variable at rendering time.
That’s usually a good thing, as it provides an alternative to the
template using global variables. The most obvious thing to do is
pass some existing objects to the template, but sometimes the
calling code can prepare some extra information. The aim is to
perform as much processing as possible in the JavaScript code, so
as to avoid any complex logic being performed within the template.
For example, sometimes the template contains a simple if-then condition like this:
<% if (context.credits == 0) { %>
You need more credits!
<% } else { %>
You have <%=context.credits%> credits!
<% } %>The logic isn’t especially complex, but scaling up with this approach can be problematic. As an alternative, let the JavaScript do some processing:
var creditsMessage = credits ?
"You need more credits!" : "You have " + credits + " credits!";The template then gives you a clear picture of the HTML it will generate:
<%= context.creditsMessage %>
Real-World Examples
Ajax Pages framework
Gustavo Ribeiro Amigo’s Ajax Pages (http://ajax-pages.sourceforge.net/) is an open source templating framework. There’s a basic blog demo (http://ajax-pages.sourceforge.net/examples/blog/index.html) on the project homepage (Figure 11-6).
JavaScript Templates framework
JavaScript Templates (JST) (http://trimpath.com/project/wiki/JavaScriptTemplates) is an open source templating framework from TrimPath. JST offers a richer set of functionality at this time, including:
Expression modifiers. The “capitalize” modifier, for instance, occurs in expressions like
${name|capitalize}.A special syntax for loops and conditions.
Macros.
These features may be useful if you’re relying heavily on templating, but there’s also an argument that JavaScript alone is sufficient, so there’s no need to add the burden of learning a second set of similar syntax.
Here’s how a JST template looks:
{for p in products}
<tr>
<td>${p.name|capitalize}</td><td>${p.desc}</td>
<td>$${p.price}</td>
<td>${p.quantity} : ${p.alert|default:""|capitalize}</td>
</tr>
{/for}With the string in a DOM element on the web page, you can apply the template with a one-liner:
element.innerHTML = TrimPath.processDOMTemplate("templateElement", data);Backbase framework
Backbase (http://backbase.com/) is a commercial
framework that extends standard XHTML with Backbase-specific tags
(BXML). It’s a more over-arching framework, as the tags are more
powerful than standard templating engines, with many tags for
widgets and visual effects available; e.g., <b:panel> tag for the user
interface. See the "Real-World Examples" in
Server-Side Code Generation (Chapter 12) for more
details.
Code Refactoring: AjaxPatterns Templating Drilldown Demo
Initial version
In the Basic Drilldown Demo (http://ajaxify.com/run/portal/drilldown), the Drilldown menu itself is a bunch of HTML generated within JavaScript. The script picks up an XML file containing a specification for the current level and traversed it with standard JavaScript and XML access. See Drilldown (Chapter 14) for details, but as a quick summary, the XML file looks like the following:
<category name="Overviews" parent="All Categories">
<items>
<link>
<url>http://en.wikipedia.org/wiki/AJAX</url>
<name>Wikipedia Article</name>
</link>
<link>
<url>http://www.adaptivepath.com/publications/essays/archives/000385.php
</url>
<name>First Ajax</name>
</link>
<category name="Podcast Overviews" parent="Overviews" />
</items>
</category>The manual HTML generation looks like this:
function onDrilldownResponse(xml) {
var category = xml.getElementsByTagName("category")[0];
var html="";
var categoryName = category.getAttribute("name");
html+="<div id='categoryName'>" + categoryName + "</div>";
//(Much more appending to html)
$("drilldown").innerHTML = html;
}Refactored to render from a template
For all the reasons just described, the HTML
generation in the initial version is messy. The refactoring in
this section introduces a template for the drilldown menu
(http://ajaxify.com/run/portal/drilldown/template).
Instead of the lengthy HTML generation in onDrilldownResponse( ), the method
becomes a simple application of an AjaxPages template:
function onDrilldownResponse(xml) {
var ajp = new AjaxPages( );
ajp.load("category.ajp");
var processor = ajp.getProcessor( );
$("drilldown").innerHTML = processor( {xml: xml} );
}So we’re passing the entire XML string into the template,
and the template’s converting it to HTML. Let’s see how that
template (category.ajp) looks.
First, it performs a little pre-processing on the XML
string:
<%
var category = context.xml.getElementsByTagName("category")[0];
var categoryName = category.getAttribute("name");
var parent = category.getAttribute("parent");
var items = category.getElementsByTagName("items")[0].childNodes;
%>Then, it outputs the HTML. Note that looping and conditions are implemented with regular JavaScript, a fair reason to include JavaScript within a template.
<div id='categoryName'><%=categoryName%></div>
<%
if (parent && parent.length > 0) {
%>
<div id='parent' onclick="retrieveCategory('<%=parent%>')">Back to
<br/>
<%=parent%></div>
<% } %>
<%
for (i=0; i<items.length; i++) {
var item = items[i];
if (item.nodeName=="link") {
var name = item.getElementsByTagName("name")[0].firstChild.nodeValue;
var url = item.getElementsByTagName("url")[0].firstChild.nodeValue;
%>
<div class="link"><a href="<%=url%>"><%= name %>
</a></div>
<%
} else if (item.nodeName=="category") {
var name = item.getAttribute("name");
%>
<div class='category'
onclick="retrieveCategory('<%=name%>')"><%=name%></div>
<%
}
}
%>We now have exactly the same external behavior as before, but the templating approach has helped separate presentation from logic.
Refactored to improve template context
In the previous version, the context consisted of only one thing: the entire XML string. As mentioned earlier in "Decisions,” it’s sometimes worthwhile doing some preparation before passing the context over to the template. In the preceding example, the template begins by extracting out a few convenience variables from the XML. That’s arguably okay, because it means the XML format is coupled only to the template, and not to the JavaScript. However, there’s also an argument that the JavaScript should simplify the template’s work by passing in a richer context. This further refactoring explores that avenue (http://ajaxify.com/run/portal/drilldown/template/prepareContext).
The change is quite small. The XML callback function now
passes in a more detailed context:
function onDrilldownResponse(xml) {
var ajp = new AjaxPages( );
ajp.load("category.ajp");
var processor = ajp.getProcessor( );
var category = xml.getElementsByTagName("category")[0];
$("drilldown").innerHTML = processor({
categoryName: category.getAttribute("name"),
parent: category.getAttribute("parent"),
items: category.getElementsByTagName("items")[0].childNodes
});
}The template no longer needs the convenience variables as it
can now refer to properties of the context:
<div id='categoryName'><%=context.categoryName%></div>
<%
if (context.parent && context.parent.length > 0) {
%>
<div id='parent' onclick="retrieveCategory('<%=context.parent%>')">Back to
<br/>
<%=context.parent%></div>
<%
}
%>
...
<%
for (i=0; i<context.items.length; i++) {
...
%>Alternatives
Browser-Side XSLT
In many cases, the browser receives an XML response. Where the browser is converting XML to HTML, Browser-Side XSLT (see earlier) is a very direct alternative to this Browser-Side Templating. Templating simplifies presentation but still requires parsing of the XML, which can be cumbersome. XSLT simplifies the parsing as well, being designed specifically for the purpose of transforming XML.
Related Patterns
XML Message
Templating is well-suited to transforming an XML Message (Chapter 9) into HTML.
JSON Message
Templating is well-suited to transforming an object from a JSON Message (Chapter 9) into HTML.
Metaphor
Think of a physical template—a document with most content already present, with a few blanks to populate with current values.
Get Ajax Design Patterns now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

