April 2018
Beginner to intermediate
215 pages
5h 36m
English
When we have a labeled dataset, the feature space is strewn with data points from different classes. It is the job of the classifier to separate the data points from different classes. It can do so by producing an output that is very different for data points from one class versus another. For instance, when there are only two classes, then a good classifier should produce large outputs for one class, and small ones for another. The points right on the cusp of being in one class versus another form a decision surface (Figure A-1).
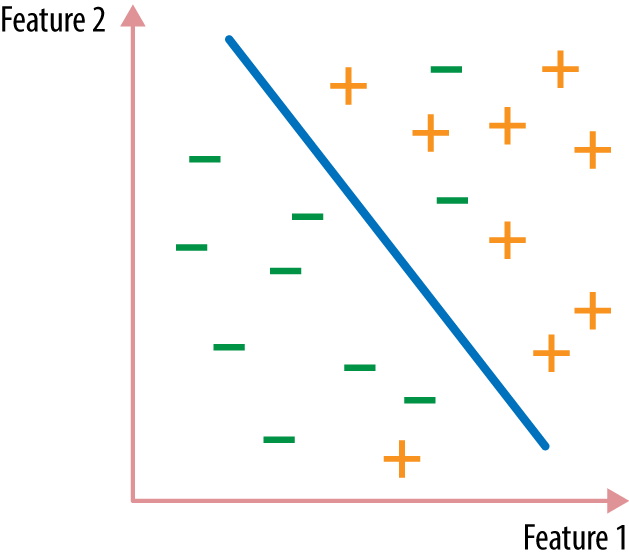
Many functions can be made into classifiers. It’s a good idea to look for the simplest function that cleanly separates the classes, for a few reasons. First of all, it’s easier to find the best simple separator than the best complex separator. Also, simple functions often generalize better to new data, because it’s harder to tailor them too specifically to the training data (a concept known as overfitting). A simple model might make mistakes—like in Figure A-1, where some points are on the wrong side of the divide—but we’re willing to sacrifice some training accuracy in order to have a simpler decision surface that can achieve better test accuracy. The principle of ...
Read now
Unlock full access






