May 2025
Intermediate to advanced
366 pages
4h 36m
Chinese
本作品已使用人工智能进行翻译。欢迎您提供反馈和意见:translation-feedback@oreilly.com
在第 3 章中,我们讨论了如何将各种来源的数据输入到我们的管道中。 在本章中,我们要开始通过验证数据来消费数据,如图 4-1 所示。
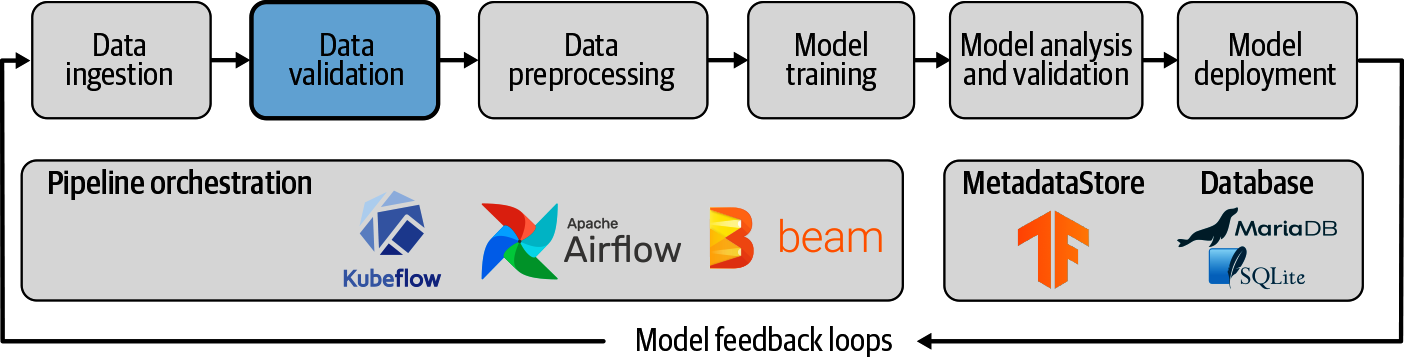
数据是每个机器学习模型的基础,而模型的实用性和性能取决于用于训练、验证和分析模型的数据。可以想象,没有强大的数据,我们就无法建立强大的模型。俗话说:"垃圾进,垃圾出",意思是如果基础数据没有经过整理和验证,我们的模型就无法运行。这正是我们机器学习管道中第一个工作流程步骤:数据验证的目的。
在本章中,我们首先介绍数据验证的概念,然后向您介绍 TensorFlow Extended 生态系统中名为TensorFlow Data Validation(TFDV) 的 Python 软件包。 我们将向您展示如何在数据科学项目中设置该软件包,向您介绍常见用例,并重点介绍一些非常有用的工作流。
数据验证步骤检查管道中的数据是否符合特征工程步骤的预期。它可以帮助你比较多个数据集。它还能突出显示数据是否随时间发生变化,例如,训练数据与提供给模型进行推理的新数据是否存在显著差异。
在本章的最后,我们将第一个工作流程步骤集成到 TFX 管道中。
在机器学习中,我们试图从数据集中的模式中学习,并对这些学习进行归纳总结。这就使数据成为机器学习工作流程的前沿和中心,而数据质量则成为机器学习项目成功的基础。
机器学习管道中的每一步都决定着工作流程是否可以进入下一步,或者是否需要放弃整个工作流程并重新启动(例如,使用更多的训练数据)。数据验证是一个特别重要的检查点,因为它能在数据进入耗时的预处理和训练步骤之前,捕捉到进入机器学习管道的数据变化。
如果我们的目标是自动更新机器学习模型,那么验证数据是必不可少的。 具体来说,当我们说验证时,我们指的是对数据进行三种不同的检查:
检查数据异常。
检查数据模式是否已更改。
检查新数据集的统计数据是否与之前训练数据集的统计数据保持一致。
我们管道中的数据验证步骤会执行这些检查,并突出显示任何故障。如果检测到故障,我们可以停止工作流程,并通过手工方式解决数据问题,例如,策划一个新的数据集。
从数据处理步骤(我们管道中的下一步)参考数据验证步骤也很有用。数据验证会生成有关数据特征的统计数据,并突出显示某个特征是否包含高比例的缺失值,或者某个特征是否高度相关。在您决定哪些特征应包含在预处理步骤中以及预处理的形式时,这是非常有用的信息。
通过数据验证,您可以比较不同数据集的统计数据。这个简单的步骤可以帮助你调试模型问题。例如,数据验证可以比较训练数据和验证数据的统计数据。只需几行代码,它就能让你注意到任何差异。您在训练二元分类模型时,可能会使用 50%正标签和 50%负标签的完美标签分布,但在验证集中,标签分布却不是 50/50。标签分布的这种差异最终会影响验证指标。
在数据集不断增长的今天,数据验证对于确保我们的机器学习模型仍能胜任工作至关重要。由于我们可以对模式进行比较,因此可以快速检测新获得数据集中的数据结构是否发生了变化(例如,当某个特征被废弃时)。它还能检测数据是否开始 ...
Read now
Unlock full access






