May 2025
Intermediate to advanced
366 pages
4h 36m
Chinese
本作品已使用人工智能进行翻译。欢迎您提供反馈和意见:translation-feedback@oreilly.com
在过去的 14 章中,我们介绍了机器学习管道的现状,并就如何构建管道提出了建议。 机器学习管道是一个相对较新的概念,在这个领域还有更多的事情要做。在本章中,我们将讨论一些我们认为重要但与当前管道不相适应的内容,同时我们还将考虑机器学习管道的未来发展方向。
在本书中,我们一直假设您已经做过实验,模型架构也基本确定。 不过,我们还是想分享一些关于如何跟踪实验并使实验过程顺利进行的想法。您的实验过程可能包括探索潜在的模型架构、超参数和特征集。但无论您探索的是什么,我们想说的关键一点是,您的实验流程应该与您的生产流程密切配合。
无论您是手动优化模型还是自动调整模型,捕捉和共享优化过程的结果都是至关重要的。团队成员可以快速评估模型更新的进度。同时,模型的作者也能收到已执行实验的自动记录。良好的实验跟踪有助于提高数据科学团队的效率。
实验跟踪还能增加模型的审计线索,并可成为应对潜在诉讼的保障。如果数据科学团队面临在训练模型时是否考虑了边缘情况的问题,实验跟踪可以帮助追踪模型参数和迭代。
实验跟踪工具包括 "权重与偏差"和 "神圣"。图 15-1展示了 "权重与偏差 "的一个应用示例,每个模型训练运行的损失都与训练历时相对应。 我们可以存储每个模型运行的所有超参数。
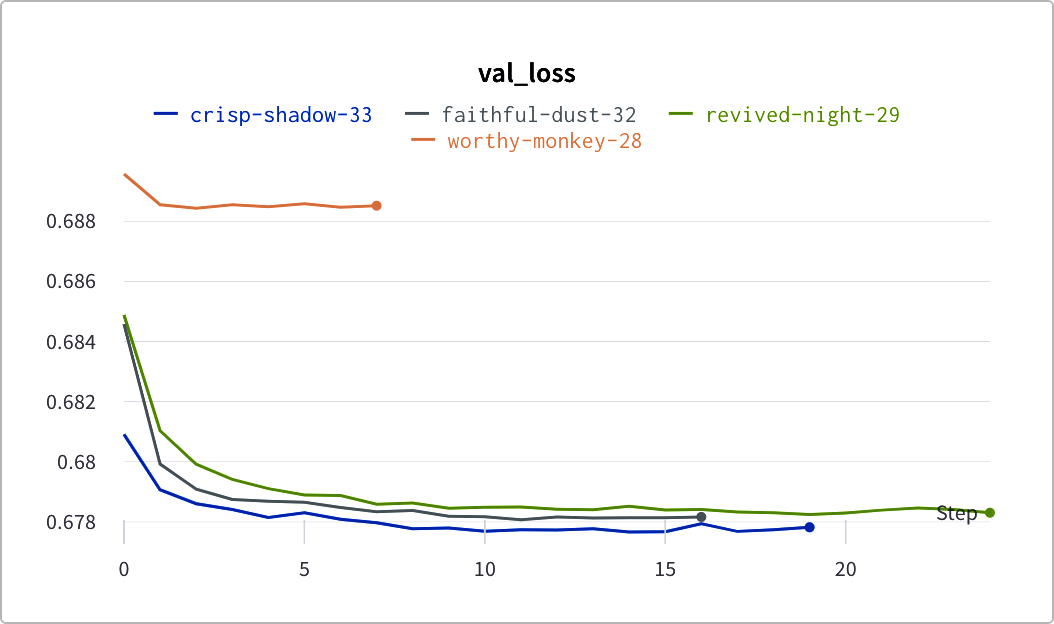
未来,我们希望看到实验和生产流程之间的联系更加紧密,这样数据科学家就可以顺利地从尝试新的模型架构切换到将其添加到管道中。
在软件工程中,有一套成熟的代码版本化和版本管理程序。 对于可能向后不兼容的大型变更,会进行重大版本变更(例如从 0.x 到 1.0)。而较小的功能添加则需要进行小版本变更(从 1.0 到 1.1)。但这在机器学习领域意味着什么呢?从一个 ML 模型到下一个模型,数据的输入格式可能是相同的,预测的输出格式也保持不变,因此不存在破坏性的变化。管道仍在运行,不会出错。但新模型的性能可能与之前的模型完全不同。机器学习管道的标准化需要模型版本化实践。
我们建议采用以下策略进行模型发布管理:
如果输入数据发生变化,模型版本也会有微小变化。
如果超参数发生变化,模型版本也会发生重大变化。这包括网络中的层数或层中的节点数。
如果模型架构完全改变(例如,从递归神经网络 [RNN] 变为变换器架构),这将成为一个全新的管道。
模型验证步骤通过验证新模型的性能是否比之前模型的性能有所提高,来控制是否进行发布。在撰写本文时,TFX 管道在这一步骤中只使用了一个指标。我们预计,验证步骤将来会变得更加复杂,包括其他因素,如推理时间或不同数据片段的准确性。
在本书中,我们介绍了机器学习管道在编写本书时的状况。 但是,未来的机器学习管道会是什么样子呢?我们希望看到的一些功能包括
隐私和公平成为一等公民:在撰写本文时,假设管道不包括保护隐私的 ML。公平性分析包括在内,但 ModelValidator 步骤只能使用总体指标。
第 14 章讨论了 FL 的整合。如果数据预处理和模型训练是在大量单个设备上进行的,那么机器学习管道就需要与我们在本书中描述的管道截然不同。 ...
Read now
Unlock full access






