May 2025
Intermediate to advanced
366 pages
4h 36m
Chinese
本作品已使用人工智能进行翻译。欢迎您提供反馈和意见:translation-feedback@oreilly.com
在机器学习管道的这一阶段,我们已经检查了数据统计,将数据转换为正确的特征,并训练了模型。 当然,现在是时候将模型投入生产了吗?我们认为,在部署模型之前,还应该有两个额外的步骤:深入分析模型的性能,并检查它是否能在任何已投入生产的模型上有所改进。图 7-1 显示了这些步骤在流程中的位置。
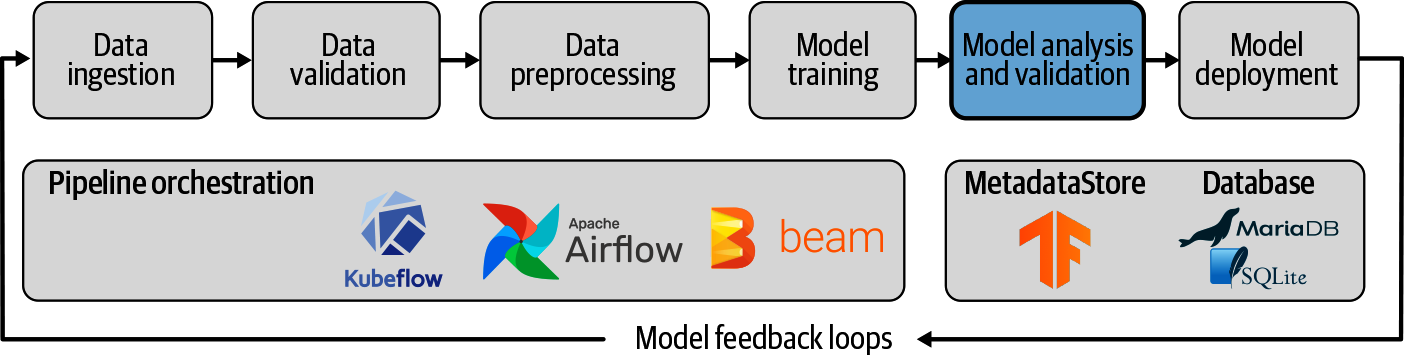
我们在训练一个模型时,会在训练过程中监测其在评估集上的表现,也会尝试各种超参数以获得最佳表现。但在训练过程中,通常只使用一个指标,而这个指标往往就是准确率。
在构建机器学习管道时,我们往往试图回答一个复杂的业务问题,或者试图为一个复杂的现实世界系统建模。单一指标往往不足以说明我们的模型是否能回答这个问题。如果我们的数据集不平衡,或者如果我们模型的某些决策比其他决策具有更高的后果,情况就更是如此。
此外,对整个评估集的性能进行平均的单一指标可能会掩盖很多重要细节。如果您的模型处理的是与人相关的数据,那么是否每个与模型交互的人都能获得相同的体验?你的模型对女性用户的表现是否优于男性用户?日本用户看到的结果是否比美国用户差?这些差异既可能对商业造成损害,也可能对真实的人造成伤害。如果您的模型正在为自动驾驶汽车进行物体检测,那么它是否在所有照明条件下都能正常工作?对整个训练集使用一个指标可能会掩盖重要的边缘和角落情况。在数据集的不同片段中监控指标至关重要。
在部署前、部署后和生产过程中随时监控指标也非常重要。即使您的模型是静态的,进入管道的数据也会随时间发生变化,这往往会导致性能下降。
本章我们将介绍 TensorFlow 生态系统中的下一个软件包:TensorFlow Model Analysis(TFMA),它具备所有这些功能。 我们将向您展示如何获得模型性能的详细指标,如何分割数据以获得不同组的指标,以及如何利用公平性指标和 What-If 工具深入研究模型的公平性。然后,我们将解释如何超越分析,开始解释模型所做的预测。
我们还将介绍部署新模型前的最后一步:验证该模型是否是对之前版本的改进。重要的是,部署到生产中的任何新模型都代表着向前迈进了一步,这样依赖于该模型的任何其他服务都会得到改进。如果新模型在某些方面没有改进,就不值得部署。
我们的模型分析流程始于指标的选择。 正如我们之前所讨论的,我们的选择对于机器学习管道的成功极为重要。好的做法是选择多个对我们的业务问题有意义的指标,因为单一指标可能会掩盖重要的细节。在本节中,我们将回顾分类和回归问题的一些最重要指标。
要计算许多分类指标,首先需要计算评估集中真/假正例和真/假负例的数量。 以我们标签中的任何一类为例:
属于该类并被分类器正确标记为该类的训练示例。例如,如果真实标签是1 ,而预测标签是1 ,那么这个例子就是真阳性。
不属于该类但被分类器错误标为该类的训练示例。例如,如果真实标签是0 ,而预测标签是1 ,那么这个例子就是假阳性。
不属于该类且被分类器正确标为不属于该类的训练示例。 例如,如果真实标签为0 ,而预测标签为 ...
Read now
Unlock full access






