November 2024
Intermediate to advanced
418 pages
10h 56m
English
A popular application of LLMs is using them for content generation based on both input prompts and externally retrieved information. In this appendix, we will demonstrate how to build a pipeline that leverages a pretrained LLM and a pretrained sentence transformer to generate content based on user input and a set of documents. We’ve explored the building blocks for this throughout the book. Chapter 2 discussed text generation with LLMs and how to use sentence transformers for encoding text. Chapter 6 also contained a project where we built a minimal RAG pipeline.
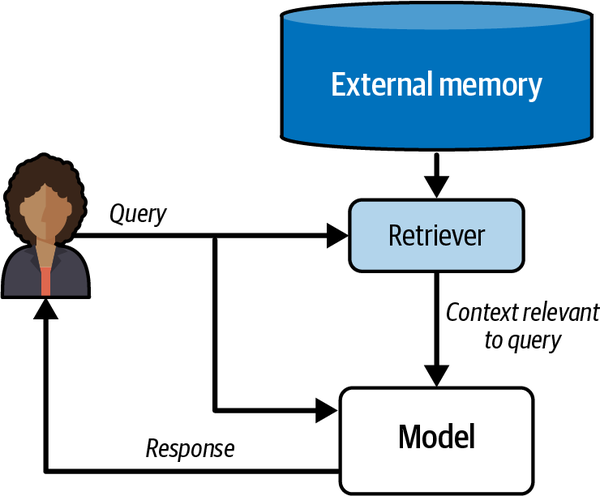
Let’s discuss the components of a RAG system (shown schematically in Figure C-1):
The user inputs a question.
The pipeline retrieves the most similar documents to the question.
The pipeline passes both the question and the retrieved documents to the LLM.
The pipeline generates a response.
As with any ML project, the first step is loading and processing the data. We’ll keep it simple by focusing on a single topic. Imagine we want our model to generate content related to the European Union AI Act, which is unlikely to be part of the LLM’s training data because the model we’ll use was trained before work on the AI Act started. First, we’ll load the document:
importurllib.request# Define the file name ...
Read now
Unlock full access






