March 2025
Intermediate to advanced
428 pages
11h 44m
French
Cet ouvrage a été traduit à l'aide de l'IA. Tes réactions et tes commentaires sont les bienvenus : translation-feedback@oreilly.com
Les tokens et embeddings sont deux des concepts centraux de l'utilisation des grands modèles de langage (LLMs). Comme nous l'avons vu dans le premier chapitre, ils sont non seulement importants pour comprendre l'histoire de l'IA linguistique, mais nous ne pouvons pas avoir une idée claire du fonctionnement des LLMs, de la façon dont ils sont construits et de la direction qu'ils prendront à l'avenir sans avoir une bonne idée des tokens et des embeddings, comme nous pouvons le voir dans la figure 2-1.
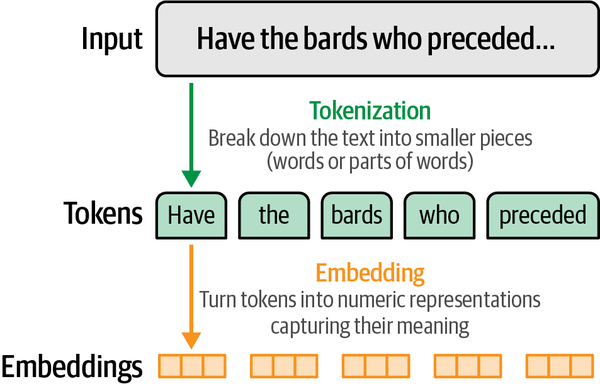
Dans ce chapitre, nous examinons de plus près ce que sont les tokens et les méthodes de tokénisation utilisées pour alimenter les LLMs. Nous nous pencherons ensuite sur la célèbre méthode d'intégration word2vec qui a précédé les LLMs modernes et nous verrons comment elle étend le concept d'intégration de jetons pour construire des systèmes de recommandation commerciaux qui alimentent un grand nombre d'applications que tu utilises. Enfin, nous passons de l'intégration de jetons à l'intégration ...
Read now
Unlock full access






