May 2022
Intermediate to advanced
408 pages
11h 25m
English
In 2017, researchers at Google published a paper that proposed a novel neural network architecture for sequence modeling.1 Dubbed the Transformer, this architecture outperformed recurrent neural networks (RNNs) on machine translation tasks, both in terms of translation quality and training cost.
In parallel, an effective transfer learning method called ULMFiT showed that training long short-term memory (LSTM) networks on a very large and diverse corpus could produce state-of-the-art text classifiers with little labeled data.2
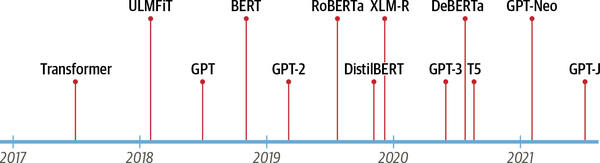
These advances were the catalysts for two of today’s most well-known transformers: the Generative Pretrained Transformer (GPT)3 and Bidirectional Encoder Representations from Transformers (BERT).4 By combining the Transformer architecture with unsupervised learning, these models removed the need to train task-specific architectures from scratch and broke almost every benchmark in NLP by a significant margin. Since the release of GPT and BERT, a zoo of transformer models has emerged; a timeline of the most prominent entries is shown in Figure 1-1.
But we’re getting ahead of ourselves. To understand what is novel about transformers, we first need to explain:
The encoder-decoder framework
Attention mechanisms
Transfer learning
In this chapter we’ll introduce the core concepts that underlie ...
Read now
Unlock full access






