Chapter 9. Dealing with Few to No Labels
There is one question so deeply ingrained into every data scientist’s mind that it’s usually the first thing they ask at the start of a new project: is there any labeled data? More often than not, the answer is “no” or “a little bit,” followed by an expectation from the client that your team’s fancy machine learning models should still perform well. Since training models on very small datasets does not typically yield good results, one obvious solution is to annotate more data. However, this takes time and can be very expensive, especially if each annotation requires domain expertise to validate.
Fortunately, there are several methods that are well suited for dealing with few to no labels! You may already be familiar with some of them, such as zero-shot or few-shot learning, as witnessed by GPT-3’s impressive ability to perform a diverse range of tasks with just a few dozen examples.
In general, the best-performing method will depend on the task, the amount of available data, and what fraction of that data is labeled. The decision tree shown in Figure 9-1 can help guide us through the process of picking the most appropriate method.
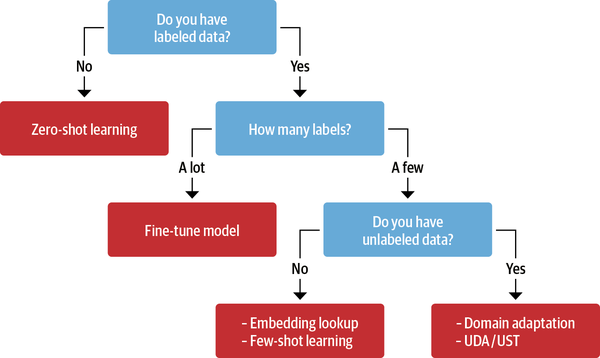
Figure 9-1. Several techniques that can be used to improve model performance in the absence of large amounts of labeled data
Let’s walk through this decision tree step-by-step:
- 1. Do you have labeled data? ...
Get Natural Language Processing with Transformers, Revised Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

