Chapter 9. Compression and Filtering
One of PNG's strengths, particularly in comparison to the GIF and TIFF image formats, is its compression. As I noted in Chapter 1, “An Introduction to PNG”, a primary motivation driving the design of the Portable Network Graphics format was to create a replacement for GIF that was not only free but also an improvement over it in essentially all respects. As a result, PNG compression is completely lossless--that is, the original image data can be reconstructed exactly, bit for bit--just as in GIF and most forms of TIFF.[67]
I wrote a longer, more technically detailed chapter on PNG compression for the
Lossless Compression Handbook, edited by Khalid Sayood and published in December 2002 by Academic Press (now Elsevier Science). It includes more rigorous test data, as well. A near-final draft is available in PDF format at the following link:
I will update it to the final version and convert it to HTML format when time permits.
9.1. Filtering
We'll look at the compression engine itself shortly, but PNG's performance is not due solely to an improved compression algorithm. PNG also supports a precompression step called filtering. Filtering is a method of reversibly transforming the image data so that the main compression engine can operate more efficiently. As a simple example, consider a sequence of bytes increasing uniformly from 1 to 255. Since there is no repetition in the sequence, it compresses either very poorly or not at all. But a trivial modification of the sequence--namely, leaving the first byte alone but replacing each subsequent byte by the difference between it and its predecessor--transforms the sequence into an extremely compressible set of 255 identical bytes, each having the value 1.
As a real-life example of this (though still not particularly realistic), consider the image known as 16million.png. This 24-bit, 512 × 32,768 RGB image contains one pixel of every possible color--more than 16 million of them altogether. As raw data, it therefore requires 48 MB to store. Simple PNG-style compression with no filtering brings it down to 36 MB, only a 25% reduction in size. But with filtering turned on, the same compression engine reduces it to 115,989 bytes, more than 300 times better than the nonfiltered case, for a total compression factor of 434![68] Zowie.
Actual image data is rarely that perfect, but filtering does improve compression in grayscale and truecolor images, and it can help on some palette images as well. PNG supports five types of filters, and an encoder may choose to use a different filter for each row of pixels in the image.
Table 9-1 lists the five filter types.
The last method requires some explanation. Invented by Alan Paeth, the Paeth predictor is computed by first calculating a base value, equal to the sum of the corresponding bytes to the left and above, minus the byte to the upper left. (For example, the base value might equal 228 + 228 - 227 = 229.) Then the difference between the base value and each of the three corresponding bytes is calculated, and the byte that gave the smallest absolute difference--that is, the one that was closest to the base value--is used as the predictor and subtracted from the target byte to give the filtered value. In case of ties, the corresponding byte to the left has precedence as the predicted value, followed by the one directly above. Note that all calculations to produce the Paeth predictor are done using exact integer arithmetic. The final filter calculation, on the other hand, is done using base-256 modular arithmetic; this is true for all of the filter types.
Though the concept is simple, there are quite a few subtleties in the actual mechanics of filtering. Most important among these is that filtering always operates on bytes, not pixels. For images with pixels smaller than eight bits, this means that the filter algorithms actually operate on more than one pixel at a time; for example, in a 2-bit palette or grayscale image, there are four pixels per byte. This approach improves the efficiency of decoders by avoiding bit-level manipulations.
At the other end of the spectrum, large pixels (e.g., 24-bit RGB or 64-bit RGBA) are also operated on as bytes, but only corresponding bytes are compared. For any given byte, the corresponding byte to its left is the one offset by the number of bytes per pixel. This means that red bytes in a truecolor image are compared with red bytes, green with green, and blue with blue. If there's an alpha channel, the alpha bytes are always compared; if the sample depth is 16 bits, upper (most significant) bytes are compared with upper bytes in the same color channel, and lower bytes are compared with lower. In other words, similar values will always be compared and operated on, in hopes of improving compression efficiency. Consider an RGB image, for example; the red, green, and blue values of any given pixel may be quite different, but neighboring pairs of red, green, and blue will often be similar. Thus the transformed bytes will tend to be close to zero even if the original bytes weren't. This is the real point of filtering: most of the transformed bytes will cluster around zero, thus giving the compression engine a smaller, more predictable range of byte values to cope with.
What about edges? If the “corresponding byte” to the left or above doesn't exist, the algorithm does not wrap around and use bytes from the other side of the image; instead, it treats the missing byte as zero. The wraparound method was, in fact, considered, but aside from the fact that one cannot wrap the top edge of the image without completely breaking the ability to stream and progressively display a PNG image, the designers felt that only a few images would benefit (and minimally, at that), which did not justify the potential additional complexity.
Interlacing is also a bit of a wrench in the works. For the purposes of filtering, each interlace pass is treated as a separate image with its own width and height. For example, in a 256 × 256 interlaced image, the passes would be treated as seven smaller images with dimensions 32 × 32, 32 × 32, 64 × 32, 64 × 64, 128 × 64, 128 × 128, and 256 × 128, respectively.[69] This avoids the nasty problem of how to define corresponding bytes between rows of different widths.
So how does an encoder actually choose the proper filter for each row? Testing all possible combinations is clearly impossible: even a 20-row image would require testing over 95 trillion combinations, where “testing” would involve filtering and compressing the entire image. A simpler approach, though still computationally expensive, is to incrementally test-compress each row, save the smallest result, and repeat for the next row. This amounts to filtering and compressing the entire image five times, which may be a reasonable trade-off for an image that will be transmitted and decoded many times.
But users often have barely enough patience to wait for a single round of compression, so the PNG development group has come up with a few rules of thumb (or heuristics) for choosing filters wisely. The first rule is that filters are rarely useful on palette images, so don't even bother with them. Note, however, that one has considerable freedom in choosing how to order entries in the palette itself, so it is possible that a particular method of ordering would actually result in image data that benefits significantly from filtering. No one has yet proven this, however, and the most likely approaches would involve doing statistics on every pair of pixels in the image. Such approaches would be quite expensive for larger images.
Filters are also rarely useful on low-bit-depth (grayscale) images, although there have been rare cases in which promoting such an image to 8 bits and then filtering has been effective. In general, however, filter type None is best.
For grayscale and truecolor images of 8 or more bits per sample, with or without alpha channels, dynamic filtering is almost always beneficial. The approach that has by now become standard is known as the minimum sum of absolute differences heuristic and was first proposed by Lee Daniel Crocker in February 1995. In this approach, the filtered bytes are treated as signed values--that is, any value over 127 is treated as negative; 128 becomes -128 and 255 becomes -1. The absolute value of each is then summed, and the filter type that produces the smallest sum is chosen. This approach effectively gives preference to sequences that are close to zero and therefore is biased against filter type None.
A related heuristic--still experimental at the time of this writing--is to use the weighted sum of absolute differences. The theory, to some extent based on empirical evidence, is that switching filters too often can have a deleterious effect on the main compression engine. A better approach might be to favor the most recently used filter even if its absolute sum of differences is slightly larger than that of other filters, in order to produce a more homogeneous data stream for the compressor--in effect, to allow short-term losses in return for long-term gains. The standard PNG library contains code to enable this heuristic, but a considerable amount of experimentation is yet to be done to determine the best combination of weighting factors, compression levels, and image types.
One can also imagine heuristics involving higher-order distance metrics (e.g., root-mean-square sums), sliding averages, and other statistical methods, but to date there has been little research in this area. Lossless compression is a necessity for many applications, but cutting-edge research in image compression tends to focus almost exclusively on lossy methods, since the payoff there is so much greater. Even within the lossless domain, preconditioning the data stream is likely to have less effect than changing the back-end compression algorithm itself. So let's take a look at that next.
9.2. The Deflate Compression Algorithm
In some ways compression is responsible for the very existence of the Portable Network Graphics format (recall Chapter 1, “An Introduction to PNG”), and it is undoubtedly one of the most important components of PNG. The PNG specification defines a single compression method, the deflate algorithm, for all image types.
Part of the LZ77 class of compression algorithms, deflate was defined by PKWARE in 1991 as part of the 1.93a beta version of their PKZIP archiver. Independently implemented by Jean-loup Gailly and Mark Adler, first for Info-ZIP's Zip and UnZip utilities and shortly thereafter for the GNU gzip utility, the deflate algorithm is battle-tested and today is probably the most commonly used file-compression algorithm on the Internet. Although it is not the best-compressing algorithm known,[70] deflate has a very desirable mix of characteristics: high reliability, good compression, good encoding speed, excellent decoding speed, minimal overhead on incompressible data, and modest, well-defined memory footprints for both encoding and decoding.
As an LZ77-derived algorithm, deflate is fundamentally based on the concept of a sliding window. One begins with the premise that many types of interesting data, from binary computer instructions to source code to ordinary text to images, are repetitious to varying degrees. The basic idea of a sliding window is to imagine a window of some width immediately preceding the current position in the data stream (and therefore sliding along as the current position is updated), which one can use as a kind of dictionary to encode subsequent data. For example, if the text of this chapter is the data stream, then the current position at the very instant you read this is here. Preceding that point is a little more than 13,000 bytes of text, which includes, among other things, six copies of the fragment “or example” (whoa, there's another one!). Instead of encoding such strings as literal text, deflate replaces each with a pair of numbers indicating its length (in this case, 10 bytes) and the distance back to one of the previous instances (perhaps 950 bytes between the fifth and sixth). The greater the length of the string, the greater the savings in encoding it as a pointer into the window.
There are various ways to implement LZ77; the approach used by deflate is a “greedy” algorithm originally devised by James Storer and Thomas Szymanski--hence its name, LZSS. LZSS employs a look-ahead buffer and finds the longest match for the buffer within the sliding window. If the match exceeds a given threshold length, the string is encoded as a length/distance pair and the buffer is advanced a corresponding amount. If the longest match is not sufficiently long, the first character in the look-ahead buffer is output as a literal value, and the buffer is advanced by one. Either way, the algorithm continues by seeking the longest match for the new contents of the buffer.
The deflate algorithm is actually a bit more clever than the preceding description would suggest. Rather than simply storing the length/distance pairs and literal bytes as is, it further compresses the data by Huffman-encoding the LZ77 output. This approach is generically referred to as LZH; deflate's uniqueness lies in its method of combining literals and lengths into a single Huffman tree, its use of both fixed and dynamic Huffman codes, and its division of the output stream into blocks so that regions of incompressible data can be stored as is, rather than expanding significantly, as can happen with the LZW algorithm.
The PNG specification further dictates that the deflate data stream must conform to the zlib 1.0 format. In particular, the size of the sliding window must be a power of 2 between 256 bytes and 32 kilobytes, inclusive, and a small zlib header and trailer are required. The latter includes a 32-bit checksum on the uncompressed data; recall that the compressed stream is already covered by PNG's 32-bit CRC value in each IDAT chunk.
More detailed explanation of the deflate algorithm and the zlib data format is beyond the scope of this book, but the full zlib and deflate specifications are available from http://www.zlib.org/zlib_docs.html. In addition, a reference such as The Data Compression Book, by Mark Nelson and Jean-loup Gailly, is invaluable for understanding many compression algorithms, including LZ77 and LZSS.
Practically speaking, independent implementation of the deflate algorithm is both difficult and unnecessary. Almost every PNG implementation available today makes use of the freely available zlib compression library, and the examples in Part III, Programming with PNG, do so as well.
[71] For now I merely note that zlib supports ten compression levels (including one with no compression at all), differing in the algorithms used to find matching strings and in the thresholds for terminating the search prematurely.
As an aside, note that the efficiency of the compression engine increases as more data is processed, with peak efficiency being reached when there is sufficient data to fill the sliding window. This occurs mainly because there are fewer strings available in the “dictionary,” but also, initially, because those strings that do exist are limited in length--obviously, they cannot be any longer than the amount of data in the window. Thus, for example, when 25% of the compressed data has been received, it may correspond to only 20% of the pixels. But because of data buffering in network protocols and applications, any large disparities due to the truly low-efficiency encoding at startup will tend to be washed out at the 512-byte level (or higher). That is, even though the first 50 bytes might represent only 1% compression, those bytes generally will not be available until after the 512th byte has been received, by which point the compression efficiency may have reached 10% or better. And since this is generally true of most compression algorithms, including those used by both GIF and PNG, it is reasonable to compare (as I did in Chapter 1, “An Introduction to PNG”) the appearance of the uncompressed pixels at an instant when equal amounts of compressed data have been received.
9.2.1. A Final Word on Patents
As mentioned at the end of Chapter 7, “History of the Portable Network Graphics Format”, Stac has reportedly claimed that the deflate algorithm is covered by two of their patents. In fact, there are a number of patents that can be infringed upon by a compliant deflate implementation, including one held by PKWARE itself that involves sorted hash tables. But the deflate specification includes a section on implementing the algorithm without infringing,[72] and, of course, zlib itself follows that prescription. While these things are never 100% certain unless and until they are tested in court, developers and users can be reasonably confident that the use of zlib and its implementation of the deflate algorithm is not subject to licensing fees.
9.3. Real-World Comparisons
The only convincing way to demonstrate the compression benefits of one image format over another is to do an actual comparison of the two on a set of real images. The problem is choosing the set of images--what works for one person may not work for another. What I've done here is to gather together results from a number of real-world tests performed over the past few years. Readers can expect to achieve similar results on similar sets of images, but keep in mind that one can always choose a particular set of images for which the results will be dramatically different. I'll explain that remark after we see a few cases.
For starters, let's look at a small, very unscientifically chosen set of images: seven nonanimated GIF images that happened to be the only ones readily available on my machine one fine day in June 1998.
Table 9-2. Seven Non-Animated, Non-Scientifically Selected GIF Images
| Name | GIF Size |
| linux-penguins | 38,280 |
| linux-tinypeng | 1,249 |
| linux_bigcrash | 298,529 |
| linux_lgeorges | 20,224 |
| linux_rasterman | 4,584 |
| sun-tinylogo | 1,226 |
| techweb-scsi-compare | 27,660 |
| TOTAL | 391,752 |
The images ranged in size from just over a kilobyte to nearly 300 kilobytes (the exact byte sizes are given in Table 9-2) and in dimension from 32 × 32 to 800 × 600. All but the first and last were interlaced. When converted to PNG with the gif2png utility (Chapter 5, “Applications: Image Converters”), preserving interlacing manually and introducing no new text annotations, things improved somewhat; Table 9-3 shows the preliminary results.
Table 9-3. Same Seven GIF Images After Conversion to PNG
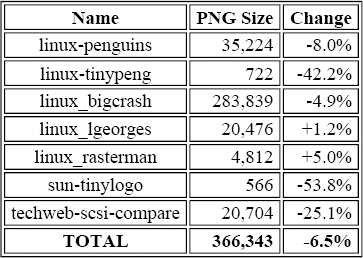
Five of the images shrank when converted to PNG--three of them quite significantly--while two grew. Overall, the set achieved a 6.5% improvement in byte size. Since gif2png uses the standard settings of the libpng reference code, [73] its results may be considered typical of “good” PNG encoders. But the owner of a web site will often be willing to spend a little more time up front on compression in return for additional bandwidth savings in the long run. That's where pngcrush (also discussed in Chapter 5, “Applications: Image Converters”) comes in. Table 9-4 shows its results; the percentages are again relative to the original GIF file sizes.
Table 9-4. Same Seven GIF Images After PNG Conversion and Optimization
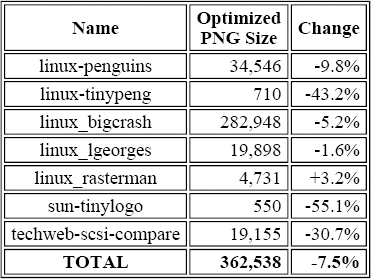
So we see that the current state-of-the-art PNG encoder ekes out another percentage point in the total size, with all but one of the images now smaller than the original. That lone holdout is worth a closer look in this case. I already noted that linux_rasterman.gif was one of the interlaced images; suppose it had not been? The noninterlaced GIF version is 4,568 bytes, only 16 bytes smaller than the original. But the noninterlaced PNG version is either 4,067 bytes (gif2png) or 4,000 bytes (pngcrush)--a savings of 11.0% or 12.4% over the noninterlaced GIF. In other words, PNG's two-dimensional interlacing scheme can have a significant negative impact on compression, particularly for small images. This is an important point to consider when creating images: is interlacing really needed for a 152 × 96 image (as in this case) when the penalty is more than 18% of the file size?
This example may have been instructive, but seven images do not constitute a statistically valid sample.[74] So let's consider a few more data sets. One real-life example comes from the course entitled “Authoring Compelling and Efficient VRML 2.0 Worlds” at the VRML98 conference in Monterey, California. Though the content of the course was otherwise outstanding, one slide comparing image formats for 3D textures was rather alarming from a PNG perspective. It showed the information displayed in Table 9-5, together with the textures themselves (which are omitted here):
Table 9-5. Original PNG, GIF, and JPEG Comparison from VRML98 Course
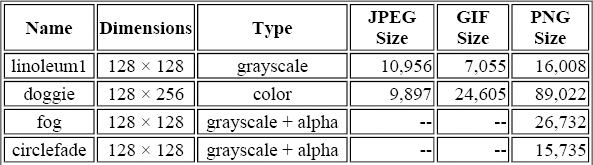

Even with no more details than are shown here, at least one problem is apparent: in row 2, the JPEG image is 24 bits deep, while the GIF is only 8 bits. Judging by the size of the corresponding PNG, one might assume (correctly) that the PNG is also 24 bits. So on the one hand, PNG is being compared with an image of the same depth that uses lossy compression, while on the other it is being compared with an image only one-third as deep, which also amounts to lossy compression. That hurts.
As it turned out, there were other problems: the PNG images were created with an image editor not known for its compression capabilities, and some of the PNGs were interlaced even though their GIF counterparts were not. (And since this was a VRML course, I should note that no VRML browser in existence actually uses interlacing to render textures progressively, so there is generally no point in creating such images.) The upshot is that all of these factors--JPEG's lossy compression, mixing 24-bit and 8-bit images, mixing interlaced and noninterlaced images, and using a particularly poor encoder to compress the PNGs--worked against our favorite image format.
After evening the playing field by using the GIFs as the source images for the PNGs, turning off interlacing, and using a combination of conversion and encoding tools (including pngcrush), the results were considerably better for PNG, as shown in Table 9-6.
Table 9-6. Updated PNG, GIF, and JPEG Comparison for VRML98 Course Images
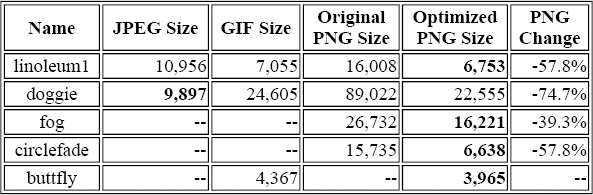
Here, I've marked the smallest version of each image in boldface type; the only one that isn't a PNG is the color JPEG, which is hardly surprising. What is interesting is that the grayscale JPEG (linoleum1.jpg) is larger than both the GIF and optimized PNG versions, despite the presumed benefits of lossy compression. There are at least three reasons for this. First, GIF and PNG both get an automatic factor-of-three savings from the fact that each pixel is only 1 byte deep instead of 3 bytes. Second, JPEG is at a relative disadvantage when dealing with grayscale images, because most of its compression benefits arise from how it treats the color components of an image. Third, this particular image is more artificial than natural, with quite a few relatively sharp features, which makes it particularly ill suited to JPEG-style compression.
But perhaps the most striking feature of
Table 9-6 is just how poorly the original encoder did on its PNG images. Realizable savings of 40% to 75% are unusual, but thanks to poor encoding software, they are not as unusual as one might hope.
As another real example (but one that is perhaps more representative of what a typical web site might expect), the owner of http://www.feynman.com/ found that when he converted 54 nonanimated GIFs to PNGs, the collection grew in size from 270,431 bytes to 327,590 bytes. Insofar as all of the original images had depths of 8 bits or less--and even the worst PNG encoder will, on average, do as well or better than GIF on colormapped PNG images--the most likely explanation for the 21% increase in size is that the conversion utility produced 24-bit RGB PNGs. Indeed, the owner indicated that he had used ImageMagick's convert utility, older versions of which reportedly had the unfortunate habit of creating 24-bit PNGs unless explicitly given the -depth 8 option. (This problem seems to have been fixed in more recent versions, but even current versions include 160 bytes' worth of text and background chunks per image.) When the original GIFs were converted to PNG with gif2png instead, the total size dropped to 215,668 bytes, for a 20% overall savings over GIF. Individually, the GIFs were smaller in 15 of the 54 cases, but never by more than 340 bytes. Of the 39 images in which the PNG version was smaller, one-third of them differed by more than a kilobyte, and one was 14 KB smaller.
For the last GIF comparison, I downloaded the World Wide Web Consortium's icon collection, consisting of 448 noncorrupted GIF images. Of these, 43 had embedded text comments and 39 were interlaced. Most of the images were icon-sized (as would be expected), at 64 × 64 or smaller, but there were a handful of larger images, too. The total size of the files was 1,810,239 bytes. Conversion to PNG via gif2png, handling the interlaced and noninterlaced images separately in order to preserve their status, resulted in a total PNG size of 1,587,337 bytes, or a 12.3% reduction. Additional compression via pngcrush resulted in a total of 1,554,965 bytes, or a 14.1% reduction (relative to the GIF size). Out of the 448 images, PNG won the size comparison in 285 cases, lost in 161 cases, and tied in 2 cases. As in the previous test, however, the magnitude of the differences was the critical factor: GIF won by more than a kilobyte in only 1 case, while PNG won by that amount in 37 cases--4 of which were greater than 10 KB, 1 more than 64 KB. The average difference for the 285 cases in which PNG was smaller was 940 bytes; for the 161 GIF cases, it was a mere 78 bytes.
Finally, I've mentioned an upcoming JPEG standard for lossless compression a couple of times; it's worth a quick look, too. JPEG-LS, as the standard will be known,[75] is based on Hewlett-Packard's LOCO-I algorithm. As this is written, it is implemented in version 0.90 of HP's locoe encoder, available only in binary form for the HP-UX, Solaris, IRIX, and 32-bit Windows platforms. (An independent implementation is available as C source code from the University of British Columbia.) In a comparison performed by Adam Costello, the HP encoder was tested against pnmtopng and pngcrush on the eight standard color images in the Waterloo BragZone's ColorSet. pnmtopng is of interest only for speed reasons; even though it is moderately fast, locoe was considerably faster. I have omitted its size results from the comparison since, as expected, pngcrush outperformed it in all cases, though at a considerable cost in speed.
The results were fascinating. In the five test images categorized by the University of Waterloo as “natural,” JPEG-LS beat PNG by between 5% and 11%--not a huge difference, but certainly significant. However, in the three images marked “artistic,” PNG proved superior by wide margins, with one image more than three times smaller than the corresponding JPEG-LS version. These results are summarized in
Table 9-7; once again, the byte size of the winning format for each image is highlighted in boldface type.
Table 9-7. PNG and JPEG-LS Comparison for Waterloo BragZone Color Images
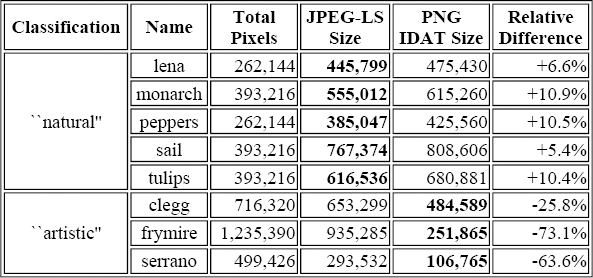
Note that in the final column I used the JPEG-LS size as the reference, which effectively works against PNG--had I used PNG instead, the frymire image, for example, would show JPEG-LS as 271.3% larger, which looks much more impressive! Also note that I used the size of the PNG IDAT data for comparison rather than the actual PNG file size; this was done because locoe appears to encode raw JPEG data, with none of the overhead of standard JPEG file formats like JFIF and SPIFF.
In any case, the results are only slightly more statistically valid than the first comparison of GIF images was. Eight samples, even if they are a carefully chosen set of standard research images, cannot tell the full story. And results as intriguing as these certainly deserve more extensive testing, which will no doubt happen in due course.
9.4. Practical Compression Tips
I could hardly end this chapter without some practical pointers on optimizing PNG compression, both for users and for programmers. Herewith are some rough guidelines, arranged in descending order of effectiveness. Note that, as with any set of rules, there will always be exceptions.
9.4.1. Tips for Users
Following is a list of tips for users of PNG-supporting software:
Use the correct image format
If you have photographic images and their quality as JPEGs is acceptable, use JPEG! JPEG will almost always be smaller than PNG, especially for color images. Conversely, if you have images with just a few colors and/or sharp edges (such as text and simple graphics), JPEG is almost never the correct solution; use PNG or GIF instead. For binary transparency, also use PNG or GIF; for partial transparency or lossless RGB, use PNG or TIFF; for animations, use MNG or GIF.
Use the correct pixel depth
For example, don't convert a GIF (which, from a practical perspective, always has a depth of 8 bits or less) to a 24-bit PNG; that will automatically boost the file size by a factor of three. Similarly, if given the option, don't save a grayscale image as RGB; save it as grayscale or, at worst, as a palette-based PNG. Likewise, don't use a full alpha channel if single-color transparency (a la GIF) would suffice; it doubles the size of grayscale images and adds 33% to the size of RGB.
Corollary: Quantize and dither truecolor images to a palette if quality is acceptable
Likewise, quantize and dither RGBA or gray+alpha PNGs to a palette, if possible. This is something that only you, the user, can judge; no reasonable image application will ever quantize (which is a lossy transformation) unless instructed to do so by you. This is not an issue for GIF, which realistically supports only colormapped images (i.e., your choice of GIF as an output format amounts to an explicit instruction to quantize) nor is it an issue for JPEG, which supports only grayscale and truecolor. Only PNG supports colormapped, grayscale, and truecolor images, as well as alpha channels.
Use interlacing with care
Interlacing is a way to transmit the useful parts of an image more quickly, particularly on the Web, so that the end user can click on a hot-linked region before the image is fully downloaded, if she so chooses. But as I saw earlier, PNG's two-dimensional interlacing scheme can degrade compression by 15% in some cases, especially for small images. Since small images are transmitted over the network fairly quickly anyway, they usually do not need to be interlaced.
Use the correct tools
In the first six chapters, I discussed a number of PNG-supporting applications and noted their limitations wherever possible; use that as a guide when choosing your tools, assuming you have a choice. Even if your program generally compresses PNG images well, consider using an optimizer such as pngcrush on everything when you're done;
[76] definitely do so if your program is not known for its compression performance. For converting GIFs to PNGs, the dedicated gif2png is the most capable solution, even given its permanently beta version number; it preserves both transparency and embedded text comments.
Don't include unnecessary information
A lengthy copyright message or other text can add 100 bytes or more, which is a lot for icons and other small images.
9.4.2. Tips for Programmers
Following is a list of tips for programmers:
Use the correct pixel depth
Count colors! Or at least do so when the compression setting is “best” and you don't know that the image is grayscale--it doesn't take that long, and computers are good at that sort of thing. If there are 256 or fewer colors, write a colormapped image; doing so will translate to a factor-of-three savings in the PNG file size relative to an RGB image.
Use the correct pixel depth II
If the image is colormapped, don't assume that the pixels must be 8 bits deep. If there are only one or two colors, write a 1-bit image. If there are three or four colors, write a 2-bit image. If there are between 5 and 16 colors, write a 4-bit image. (These are the only useful cases for PNG.) The compression engine cannot compensate for bloated pixels! Choosing the correct depth for a palette-based image will reduce the file size by a factor of anywhere from two to eight relative to an 8-bit image.
Use grayscale if possible
If you know the image is gray, see if it can be written more compactly as a grayscale PNG than as a colormapped PNG--this is automatically true if there are more than 16 shades of gray. Doing so will save up to 780 bytes by eliminating the palette. But don't assume that 16 or fewer shades automatically means the image can be written as 4-bit (or smaller) grayscale. Grayscale necessarily implies that the shades are evenly distributed from black to white. If, for example, the 16 shades are bunched up in one part of the gray spectrum, the image must be written as 8-bit grayscale or 4-bit palette-based. For larger images, the palette-based approach is almost certainly better; for small ones it depends, but the 8-bit grayscale case may end up being smaller. Try both, if possible; it's very fast for small images.
Set the compression and filtering options intelligently
For programs that use libpng (discussed at length in Part III, “Programming with PNG”), this is not a serious issue; it will automatically do the right thing if left to itself. But if you are writing custom PNG code, follow the guidelines in the PNG specification for matching filter strategies with image types. In particular, use filter type None for colormapped images and for grayscale images less than 8 bits deep. Use adaptive filtering (the “minimum sum of absolute differences” heuristic) for all other cases.
Truncate the palette
Unlike GIF, PNG's palette size is determined by the chunk size, so there is no need to include 256 entries if only 173 are used in the image. At 3 bytes per entry, wasted slots can make a big difference in icons and other small images.
Truncate the transparency chunk
It is extremely rare for every palette entry to be partially or fully transparent. If there are any opaque entries--in particular, if all but one are opaque--reorder the palette so that the opaque entries are at the end. The transparency entries corresponding to these opaque colors can then be omitted. The absolute worst possible approach is to put the single transparent entry at the end of the palette! Those 255 extra bytes are a lot for a file that would otherwise be 500 (or even 150) bytes long.
Do transparency intelligently
Understand how PNG's alpha channels and tRNS chunk work. If the alpha mask is binary (that is, either fully transparent or fully opaque), see if the transparent parts correspond to a single color or gray shade; if so, eliminate the alpha channel from the PNG file and use the tRNS chunk (“cheap transparency”) instead. Alternatively, see if the total number of color+alpha combinations is 256 or fewer; if so, write a colormapped image with a tRNS chunk. If the user requests that an RGBA image be converted to indexed color, do so intelligently. The combination of PNG's PLTE and tRNS chunks amounts to a palette whose entries are RGBA values. The exact same algorithms that quantize and dither a 24-bit RGB image down to an 8-bit palette-based image can be used to quantize and dither a 32-bit RGBA or 16-bit grayscale+alpha image down to an 8-bit RGBA palette. In particular, you cannot treat color values and transparency values as if they are separate, unrelated entities; attempting to partition the palette into a “color part” and a “transparent part” makes no more sense than attempting to partition a standard RGB palette into red, green, and blue parts. If you do cheap transparency poorly, the user will be forced to use a full alpha channel, quadrupling her file size. For grayscale, an alpha channel “merely” doubles the size. Note that the icicle image in Figure C-1 in the color insert is actually colormapped. Aside from the garish background--which was actually generated by the viewing application--the full-resolution half looks pretty darned good, doesn't it?
Don't include unnecessary chunks in small images
Gamma information (or the sRGB chunk) is always good, but a full ICC profile may quadruple the size of a small image file. Consider not including a Software text chunk or tIME chunk, or do so only for images larger than, say, 100 x 100 pixels. Include dots-per-inch information (pHYs chunk) only if it is actually relevant to the image; but the user may be the only one who can make that call.
Offer the user reasonable options
Don't overwhelm him with unnecessary detail about filters or other technical jargon. For example, offer a simple checkbox to turn on interlacing. Offer a simple dial or even just two or three choices for compression level--fastest, typical, and best, perhaps. Even though it will make the file bigger, offer to include at least a few text annotations--Author, Title, Description, and/or Copyright, for example. On the other hand, offer to omit certain optional information, such as that described in the previous item.
Warn the user about data loss
If a region is completely transparent, don't zero out the underlying color pixels in order to improve compression unless you've notified the user in some way. Make sure she understands that quantization and dithering are lossy transformations, but don't make this an overly scary issue.
[67] And as a corollary, PNG file sizes are usually considerably larger than ordinary JPEG, since the latter uses lossy compression--that is, it throws away some information. TIFF also supports JPEG compression as one of its many options, but the more common methods are lossless and based on either run-length encoding (RLE) or the same LZW algorithm used in GIF.
[68] Actually, it gets even better. The dimensions of the image were chosen for convenient web-browser scrolling, but a 4096 × 4096 version created by Paul Schmidt is half the size--a mere 59,852 bytes (841 times compression). And just wait until we get to the chapter on MNG!
[69] Yes, that adds up to the right number of pixels. (Go ahead, add it up.) Note that things may not come out quite so cleanly in cases in which one or both image dimensions are not evenly divisible by eight; the width of each pass is rounded up, if necessary.
[70] Arithmetic coding has been around for a long time and significantly outperforms deflate; the relatively recently published Burrows-Wheeler block transform coding (implemented in bzip2, for example) shows considerable promise as well; and the patented BitJazz condensation method is likewise quite impressive.
[71] Nevertheless, at least one alternative (in C++) is available as part of Colosseum Builders' Image Library, and it is also described in a book by John Miano, The Programmer's Guide to Compressed Image Files.
[72] From Section 4 of the deflate specification, Compression algorithm details: “...it is strongly recommended that the implementor of a compressor follow the general algorithm presented here, which is known not to be patented per se.”
[73] libpng is discussed at length in Chapter 13, “Reading PNG Images”, Chapter 14, “Reading PNG Images Progressively” and Chapter 15, “Writing PNG Images”, which demonstrate how to use libpng to read and write PNG images.
[74] That would be a small understatement.
[75] In December 1998 it became an ISO Draft International Standard, the final voting stage before becoming a full International Standard. It will officially be known as ISO/IEC 14495-1 upon approval. It has already been approved as International Telecommunication Union (ITU) Recommendation T.87.
[76] It is one of my favorite tools, in case that wasn't already apparent. As of April 1999, there are still a few optimization tricks it doesn't do, but its author is addressing those even as this is written.
Get PNG: The Definitive Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

